Crossing Bridges: RStudio 및 데이터브릭스를 이용하여 뉴욕 택시 데이터로 보고서 만들기

데이터를 좋아하는 저희는 데이터 세트에서 스토리를 발견하는 것을 항상 즐깁니다. Posit의 RStudio Desktop과 데이터브릭스를 사용하면 데이터브릭스에 저장된 데이터를 사용하여 dplyr로 데이터를 분석하고, ggplot2로 인상적인 그래프를 만들고, Quarto로 데이터 내러티브를 엮을 수 있습니다.
Posit과 데이터브릭스는 최근 전략적 파트너십을 체결하여 Posit과 데이터브릭스 사용자에게 간소화된 경험을 제공한다고 발표했습니다. Posit의 RStudio와 데이터브릭스를 결합하면 소규모 데이터 세트부터 대규모 스트리밍 데이터에 이르기까지 데이터브릭스의 레이크하우스 플랫폼에 저장된 모든 데이터를 심층적으로 분석할 수 있습니다. Posit은 데이터 과학자에게 데이터 작업과 코드 작성을 위한 사용자 친화적인 코드 우선 환경과 도구를 제공합니다. 데이터브릭스는 데이터 스토리지, 컴퓨팅, AI 및 거버넌스를 위한 확장 가능한 엔드투엔드 아키텍처를 제공합니다.
이번 파트너십의 한 가지 목표는 sparklyr를 통해 R에서 Spark Connect에 대한 지원을 개선하고, Databricks Connect를 통해 Databricks 클러스터에 연결하는 프로세스를 간소화하는 것입니다. 앞으로 Posit과 데이터브릭스는 간소화된 통합을 통해 이러한 단계 중 많은 부분을 자동화할 예정입니다.
오늘은 10,000,000개 이상의 행과 총 파일 크기가 37기가바이트에 달하는 뉴욕시 택시 운행 기록 데이터를 통해 향상된 sparklyr 환경을 살펴보겠습니다.
환경 셋업하기
시작하려면 RStudio와 데이터브릭 간의 연결을 설정해야 합니다.
환경 변수 저장하기
Databricks Connect를 사용하려면 세 가지 구성 항목이 필요합니다. Databricks 계정에 로그인하여 다음을 얻습니다:
- 워크스페이스 인스턴스 URL (예를들어, https://databricks-instance.cloud.databricks.com/?o=12345678910111213 처럼 생겼어요)
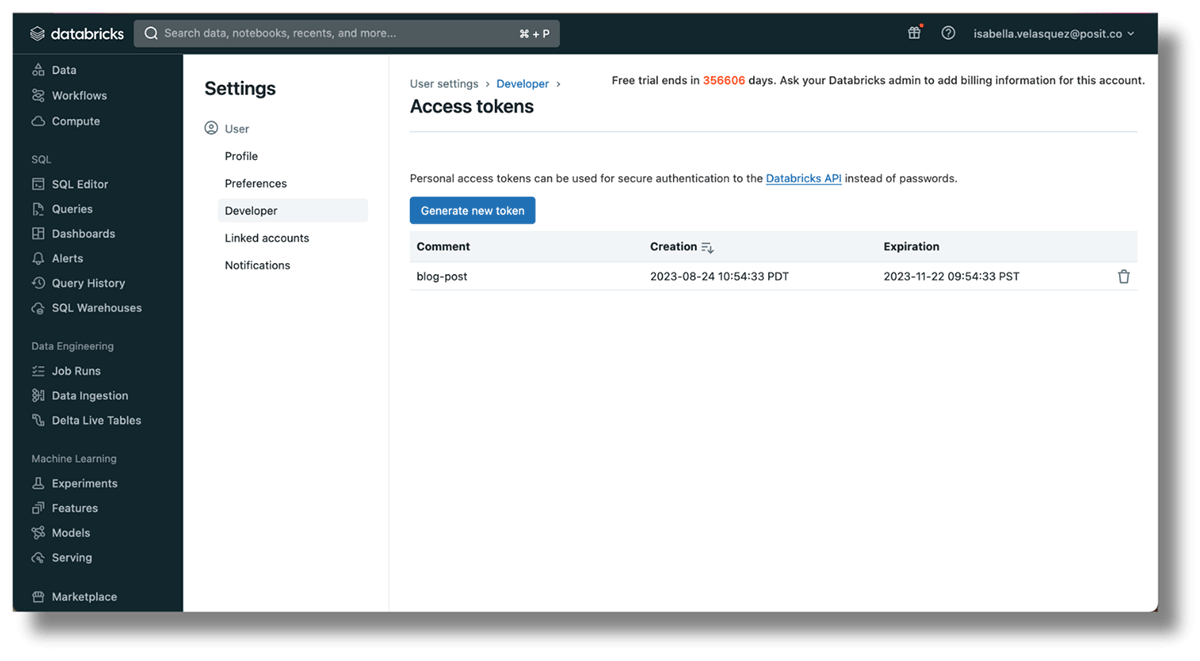
- 계정을 인증하기 위한 액세스 토큰. 오른쪽 상단 모서리에 있는 사용자 이름을 클릭하고 "User Settings"을 선택한 다음 "Developer"를 선택합니다. 'Access Tokens' 옆의 'Manage'를 클릭한 다음 'Generate new token'을 클릭합니다. 토큰은 다시 표시되지 않으므로 복사해 둡니다.
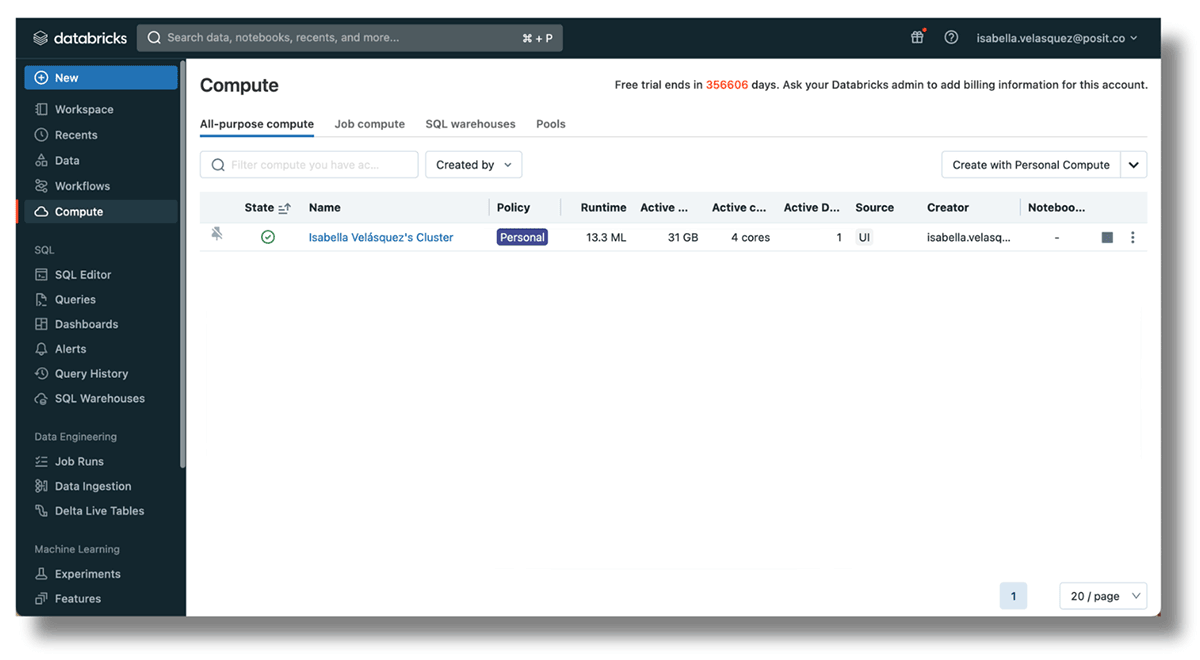
- 클러스터 ID는 현재 워크스페이스 내에서 실행 중인 클러스터입니다. https://<databricks-instance>/#/setting/clusters/로 이동하여 설정하세요. 자세한 내용은 데이터브릭스 문서에서 확인할 수 있습니다. 다른 방법으로는, 사이드바에 있는 "Compute"로 이동하여 새 클러스터를 추가할 수 있습니다.
이제 RStudio로 이동합니다.
Databricks와 RStudio 계정을 안전하게 연결하려면 Databricks 작업 공간, 액세스 토큰 및 클러스터 ID를 환경 변수로 설정하세요. 환경 변수는 민감한 정보를 코드 외부에 보관하여 스크립트에서 기밀 데이터가 노출될 위험을 줄여줍니다.
이 패키지에는 R 환경을 열기 위한 편리한 기능이 있습니다. 콘솔에서 아래 코드를 실행하여 .Renviron 파일에 액세스합니다:
이 기능은 편집할 수 있는 .Renviron 파일을 자동으로 엽니다. .Renviron 파일에 다음 이름으로 Databricks Workspace URL, 액세스 토큰 및 클러스터 ID를 설정합니다: URL은 DATABRICKS_HOST, 액세스 토큰은 DATABRICKS_TOKEN, 클러스터 ID는 DATABRICKS_CLUSTER_ID로 설정합니다. 예를 들��어:
여러분의 RStudio는 이렇게 보일겁니다:

.Renviron 파일을 저장하고 R 세션을 다시 시작합니다. 이제 데이터브릭스에 연결할 수 있는 환경이 설정되었습니다!
필요한 패키지 설치하기
sparklyr 패키지는 데이터 처리, SQL 및 고급 분석 API 모음인 Apache Spark로 작업할 수 있는 강력한 R 패키지입니다. sparklyr를 사용하면 R 환경 내에서 바로 Spark의 기능을 활용할 수 있습니다. 또한, 사용자 친화적인 방식으로 데이터를 탐색하고 볼 수 있는 '연결 창'을 활용할 수 있습니다.
Posit은 sparklyr 패키지를 업데이트하고 개선하기 위해 노력해 왔습니다. 스파크 커넥트를 사용하려면 gRPC라는 도구가 필요합니다. 스파크 팀은 이 도구를 사용하는 두 가지 방법을 제공합니다. 하나는 Scala, 다른 하나는 Python입니다. 개발 버전에서는 reticulate를 사용하여 dplyr, DBI 지원 및 RStudio의 연결 창과의 통합과 같은 기능을 Python API에 추가합니다. 개선 및 수정 작업을 더 빠르게 진행하기 위해 Python 부분을 자체 패키지인 pysparklyr로 분리했습니다.
RStudio에 sparklyr 및 pysparklyr의 개발 버전을 설치하여 sparklyr의 새로운 기능에 액세스하세요:
sparklyr 패키지는 Databricks Connect와 통신하기 위해 특정 Python 구성 요소가 필요합니다. 이러한 구성 요소를 설정하려면 다음 helper function을 실행하세요:
이제 여러분은 sparklyr 패키지를 로딩할 수 있습니다. Sparklyr는 위에서 구성한 사전 설정 환경 변수를 인식합니다.
다음으로, spark_connect()를 사용하여 데이터브릭에 대한 연결을 오픈합니다. method = "databricks_connect"를 설정하여 스파크 클러스터에 연결 중임을 sparklyr에게 알릴 수 있습니다.
만약 다음 에러가 발생한다면:
필요한 Python 패키지를 설치하기 위해서, 제공되는 스크립트를 실행합니다:
그러면 RStudio의 오른쪽 상단에 있는 연결 패널에 데이터가 표시됩니다.

축하합니다, 데이터브릭스와 세션을 연결하셨습니다!
데이터를 읽어와서 분석하기
RStudio는 한 번에 여러 데이터베이스에 연결할 수 있습니다. RStudio 연결 창을 사용하여 연결된 데이터베이스를 확인하고 현재 사용 중인 데이터베이스를 확인할 수 있습니다.

Spark와의 새로운 통합을 통해 Unity 카탈로그에서 관리되는 데이터를 탐색할 수 있으며, 연결 창을 Databricks Data Explorer에서 볼 수 있는 것과 동일한 구조로 채울 수 있습니다.
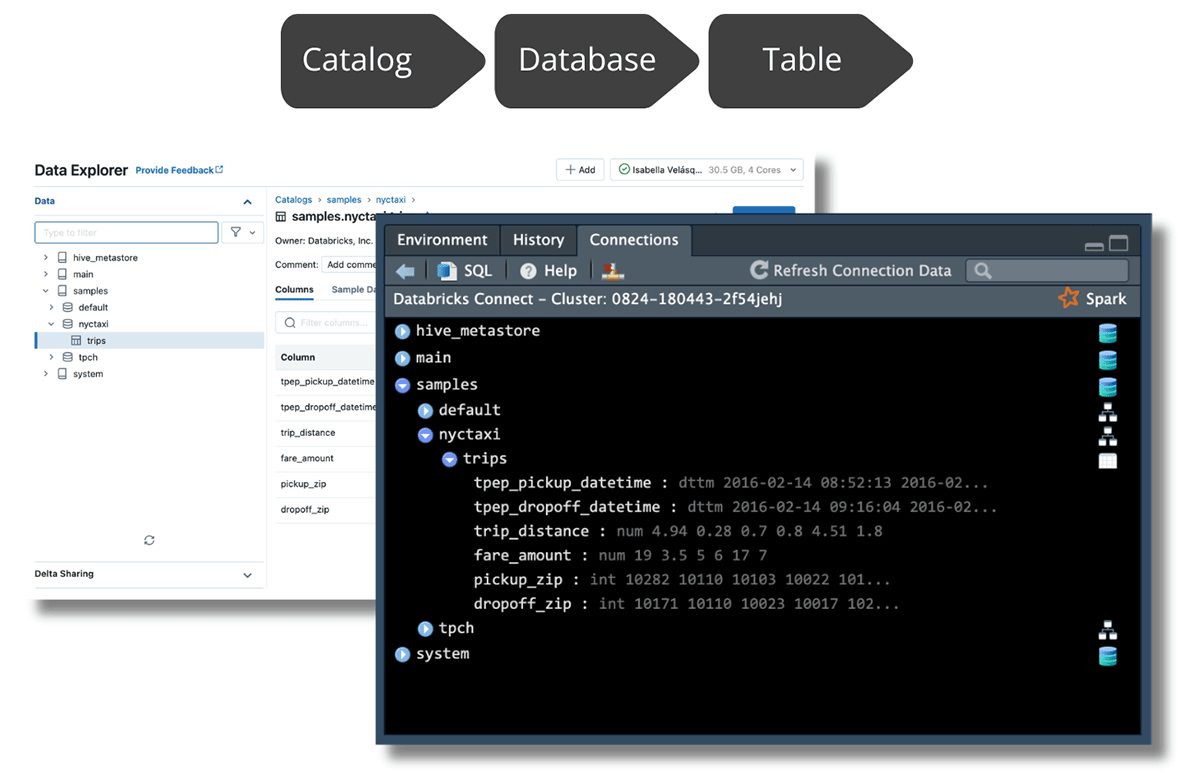
RStudio에서는 최상위 수준에서 탐색하려는 테이블까지 확장하여 데이터를 탐색할 수 있습니다. 테이블을 확장하면 해당 열과 데이터 유형을 볼 수 있습니다. 테이블 이름 오른쪽에 있는 테이블 아이콘을 클릭하여 데이터의 처음 1,000개 행을 볼 수도 있습니다:

Databricks 연결을 사용하여 데이터 엑세스하기
dbplyr 패키지는 원격 데이터베이스 테이블을 마치 인메모리 데이터 프레임처럼 액세스할 수 있게 함으로써 R과 데이터베이스를 연결합니다. 또한, dplyr 구문을 SQL 쿼리로 변환하여 익숙한 R 구문을 사용하여 데이터베이스 데이터로 쉽게 작업할 수 있도록 해줍니다.
데이터브릭에 대한 연결이 설정되면 dbplyr의 tbl() 및 in_catalog() 함수를 사용하여 카탈로그의 레벨 순서에 따라 모든 테이블에 액세스할 수 있습니다 (카탈로그, 데이터베이스 및 테이블의 순서).
아래 예에서 "samples"는 카탈로그, "nytaxi"는 데이터베이스, "trips"는 테이블입니다. 개체 trip에 테이블 참조를 저장합니다.
이제 trips 데이터로 작업을 진행할 수 있습니다!
데이터를 쿼리하고 결과를 받아오기
dplyr을 통해 데이터에 액세스했으므로 즐겨 사용하는 dplyr 함수를 사용하여 데이터 조작을 수행할 수 있습니다. 아래에서는 R 4.1에 도입된 ��새로운 네이티브 R 파이프 |>를 사용합니다. 또한, magrittr 파이프 %>%를 dplyr 연산에 사용할 수도 있습니다. 이 네이티브 R 파이프에 대해 자세히 알아보고 magrittr 파이프와 어떻게 다른지 알아보려면 tidyverse 블로그를 방문하세요.
taxi 개체에서 dplyr 명령을 사용하여 데이터 집합을 정리하고 탐색할 수 있습니다. 뉴욕시 택시 및 리무진 위원회에 따르면 택시의 초기 택시 요금은 3달러입니다. 3달러 미만의 데이터 포인트를 제거하려면 filter()를 사용하면 됩니다. 택시 요금에 대해 자세히 알아보려면 summarize()를 사용하여 최소, 평균 및 최대 요금을 계산할 수 있습니다.
최소 요금은 $3.50, 평균 택시 요금은 $12.40, 최대 요금은 $275였습니다!
데이터를 시각화하여 요금 금액의 분포를 파악할 수 있습니다:
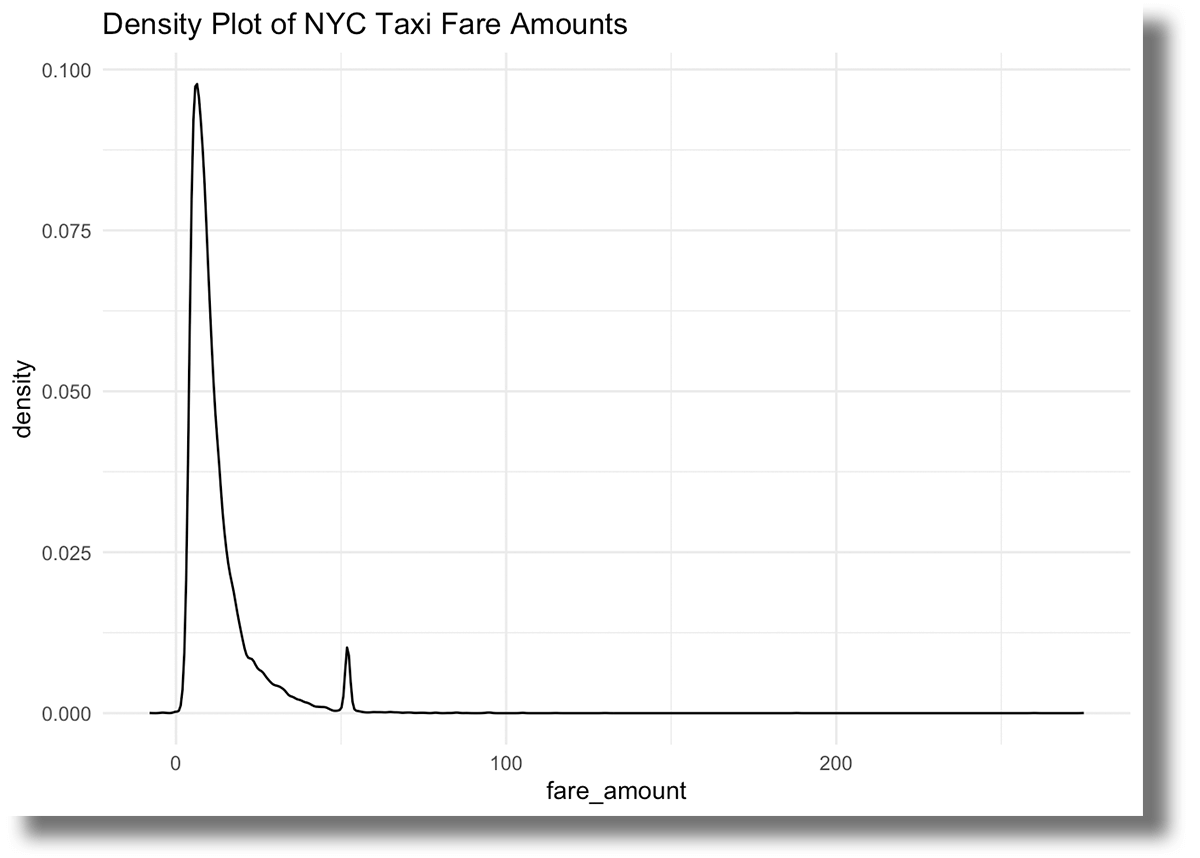
대부분의 trip 요금은 25달러 미만이지만, 50달러가 조금 넘는 요금도 많이 볼 수 있습니다. 이는 공항에서 시내로 이동하는 차량 서비스의 고정 요금 때문일 수 있습니다.
이제 요금 금액의 분포를 파악했으므로 다른 시각화 차트를 만들어 보겠습니다. 다음 예에서는 시간이라는 새 열을 만들어 각 택시 승차 시간을 표시합니다. 그런 다음 ggplot2를 사용하여 하루 중 다른 시간대에 요금이 어떻게 분포되어 있는지 표시하는 커스텀 시각화 차트을 만들 수 있습니다.
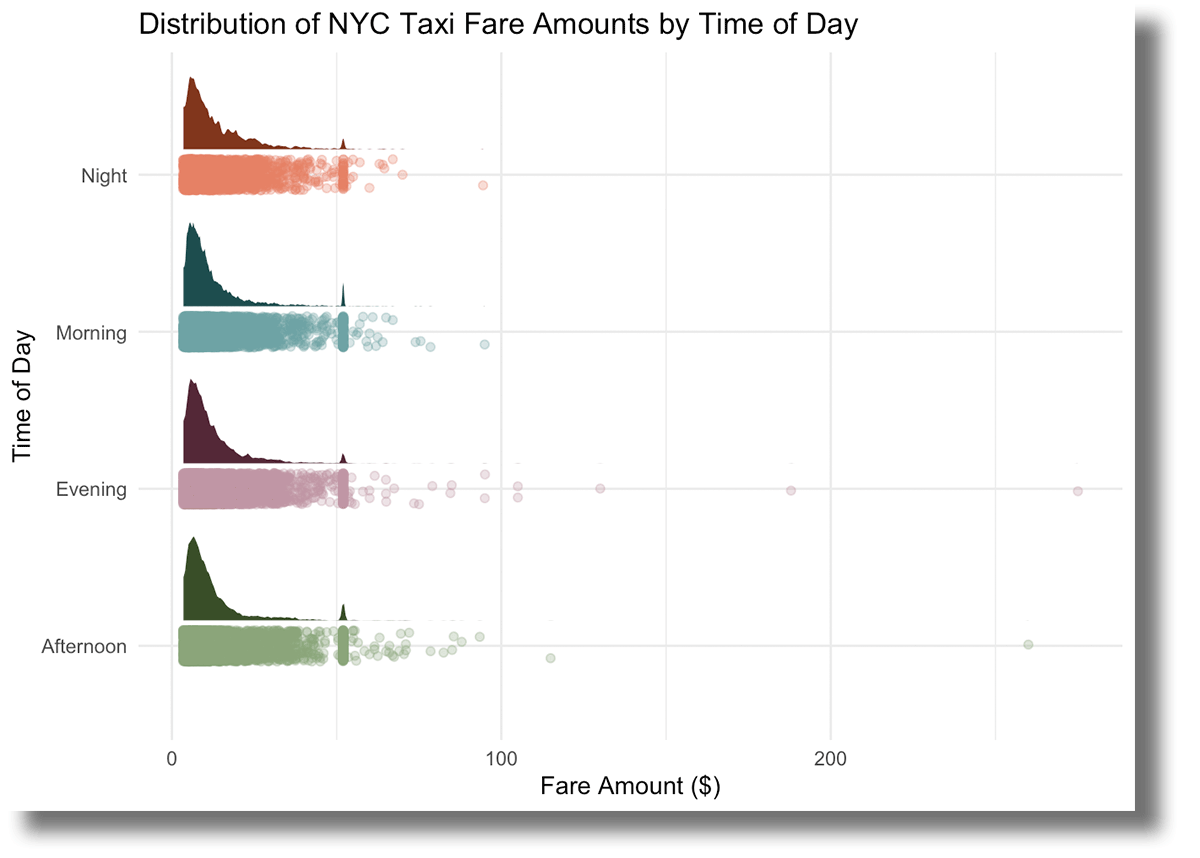
시간대별 요금 분포는 매우 비슷해 보이며, 50달러의 최고 요금은 모든 시간대에 걸쳐 일관되게 나타납니다. 또한 오후와 저녁에는 요금이 더 극단적인 반면, 아침과 심야에는 일반적으로 100달러 미만으로 유지된다는 점이 눈에 띕니다.
이제 데이터 집합을 파헤쳤습니다. 이제 게시할 콘텐츠를 만들 차례입니다!
컨텐츠를 게시하고 여러분의 인사이트를 공유하세요
세상과 공유할 수 없다면 멋진 스토리를 발굴할 이유가 없겠죠? 이제 여정의 마지막 장인 콘텐츠 게시로 넘어갑니다.
sparklyr 업그레이드를 통해 데이터브릭의 처리 능력을 사용하여 RStudio에서 포괄적이고 시각적으로 매력적인 보고서를 만들 수 있습니다. 데이터를 쿼리하고 전달하고자 하는 스토리를 추가한 후에는 Quarto를 사용하여 보고서를 만들 수 있습니다:
.qmd 파일을 렌더링하면 시각적으로 매력적인 보고서를 출력으로 생성할 수 있습니다:

��이 보고서를 게시하려면 몇 가지 옵션이 있습니다. Posit은 R 및 Python 데이터 제품을 배포하기 위한 엔터프라이즈급 플랫폼인 Posit Connect를 제공합니다. 데이터 과학자들은 Posit Connect를 사용하여 시간이 많이 걸리는 작업을 코드로 자동화하고, 맞춤형 도구와 솔루션을 팀 전체에 배포하고, 의사 결정권자와 안전하게 인사이트를 공유합니다.

데이터브릭스를 통해 보고서를 게시하려면 노트북 작업으로 예약하고 이해관계자에게 출력물 링크를 이메일로 보낼 수 있습니다.
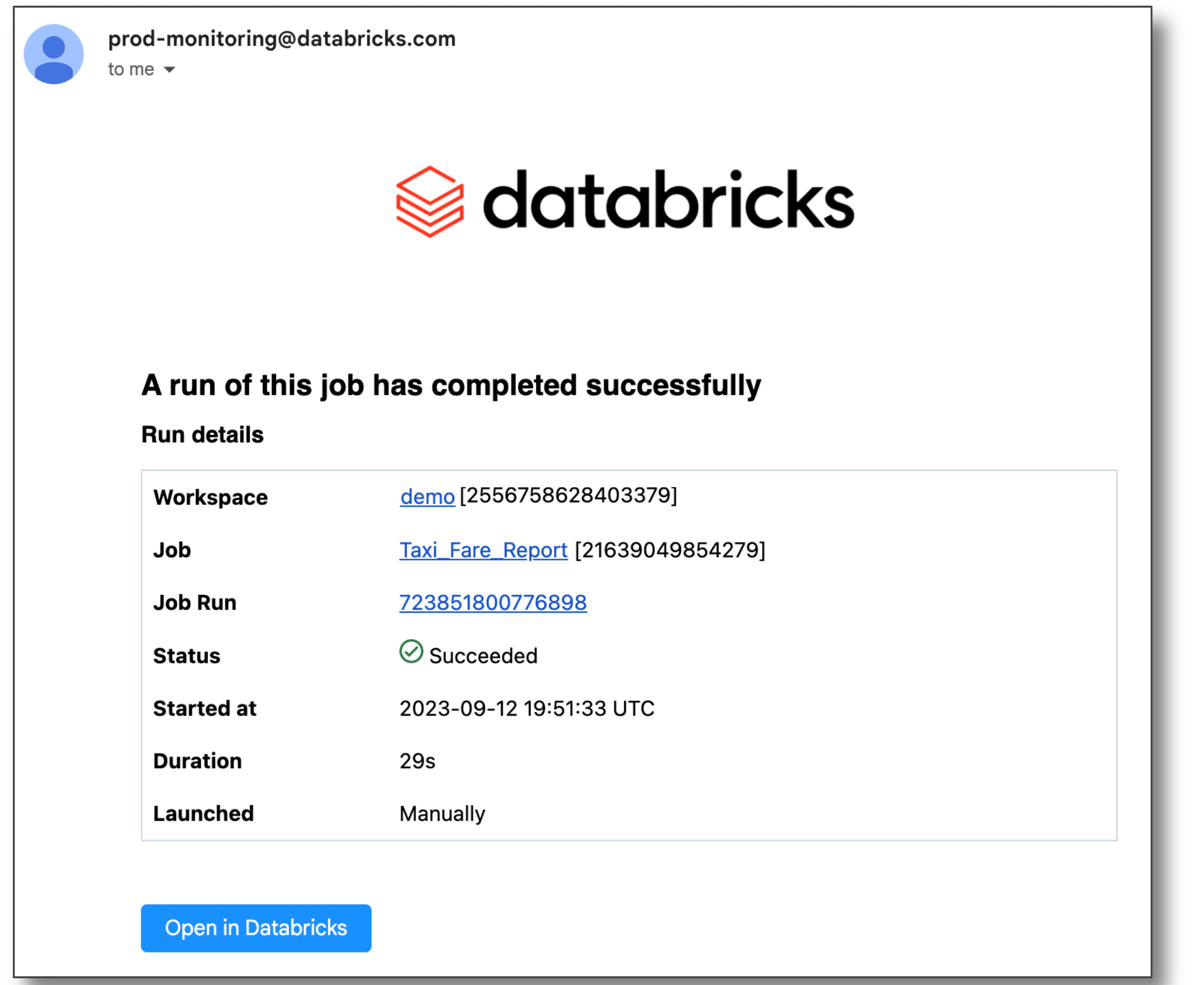
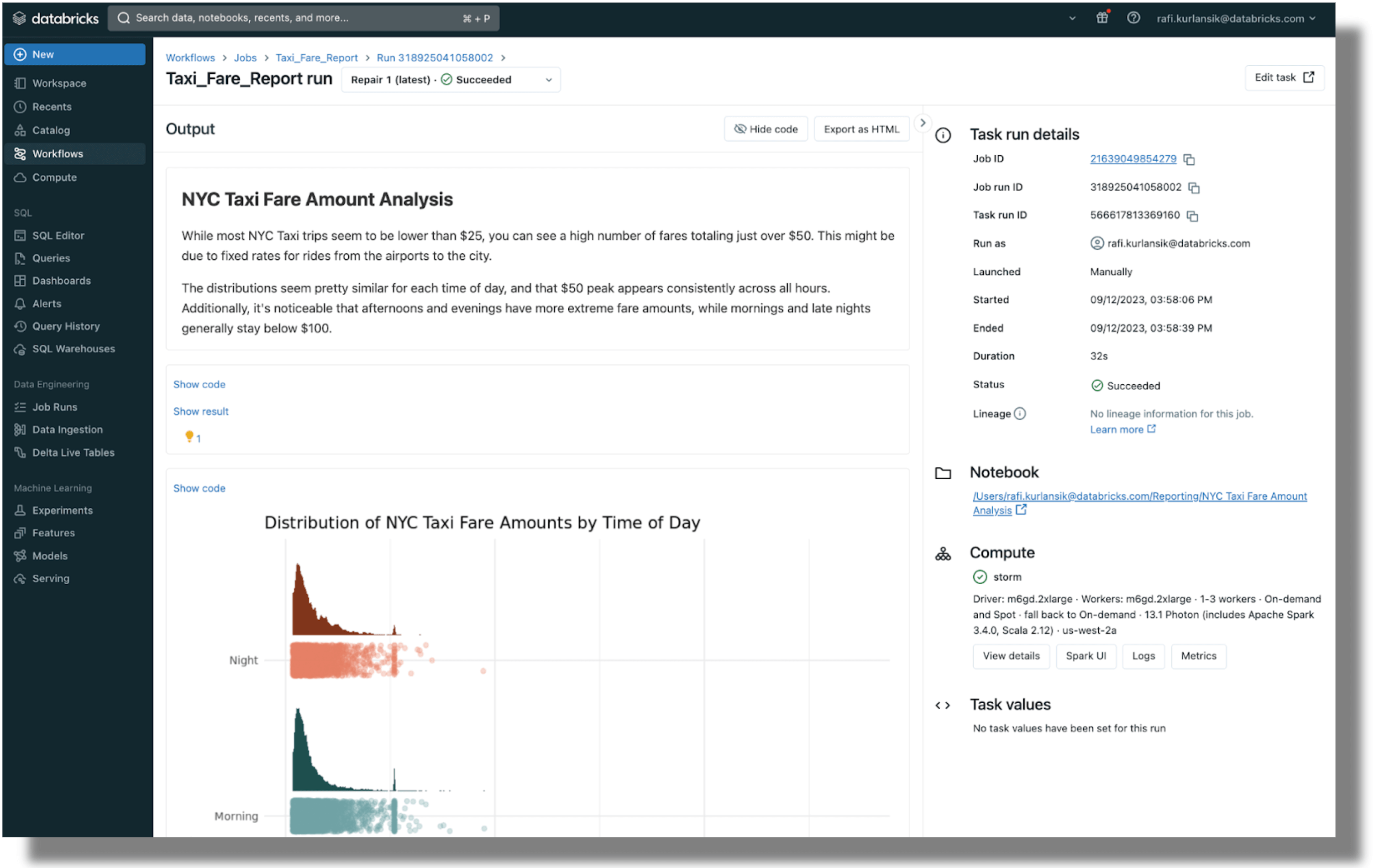
또한 Quarto Pub 및 GitHub 페이지에 Quarto 문서를 게시할 수도 있습니다. 자세한 내용은 Quarto의 게시 가이드에서 확인하세요.
You can also publish Quarto documents on Quarto Pub and GitHub Pages. Find out more on Quarto's publishing guide.
서버 연결 해제하기
분석이 끝나면 Spark Connect에서 연결을 해제합니다.
RStudio를 데이터브릭스와 함께 사용해보기
RStudio와 데이터브릭스의 통합을 통해 사용자는 간소화된 개발자 경험을 얻으면서 두 가지의 이점을 모두 누릴 수 있습니다. 이 설명서를 통해 직접 사용해 보세요.

