
요약: LLM은 프로그래머의 생산성을 향상시키며 소프트웨어 개발을 혁신하였습니다. 그러나, 상당한 양의 코드로 훈련된 판매용 LLM이 완벽하지는 않습니다. 우리 기업 고객들에게 주요한 도전 과제 중 하나는 데이터 인텔리전스를 수행해야 한다는 것입니다, 즉, 자체 조직의 데이터를 사용하여 적응하고 추론하는 �것입니다. 이것은 조직 특유의 코딩 개념, 지식, 선호도를 사용할 수 있는 능력을 포함합니다. 동시에, 우리는 지연 시간과 비용을 낮게 유지하고 싶습니다. 이 블로그에서는 작은 오픈소스 LLM을 상호작용 데이터에 미세 조정함으로써 최첨단의 정확도, 낮은 비용, 최소한의 지연 시간을 달성하는 방법을 보여줍니다.
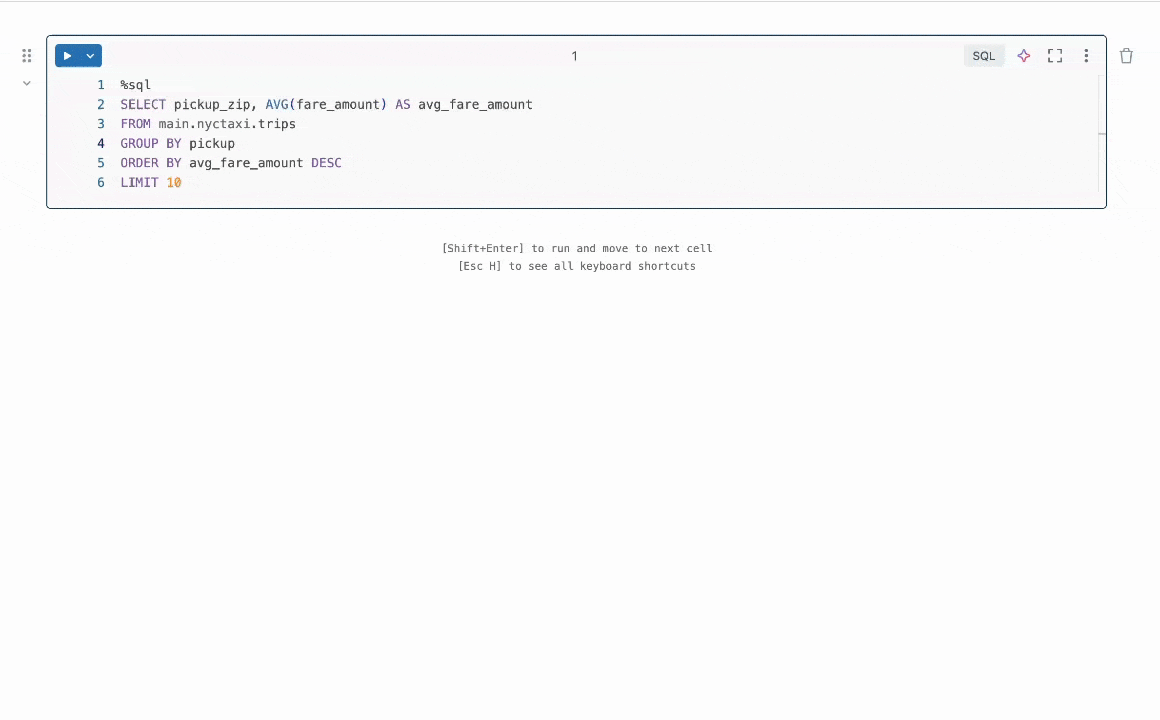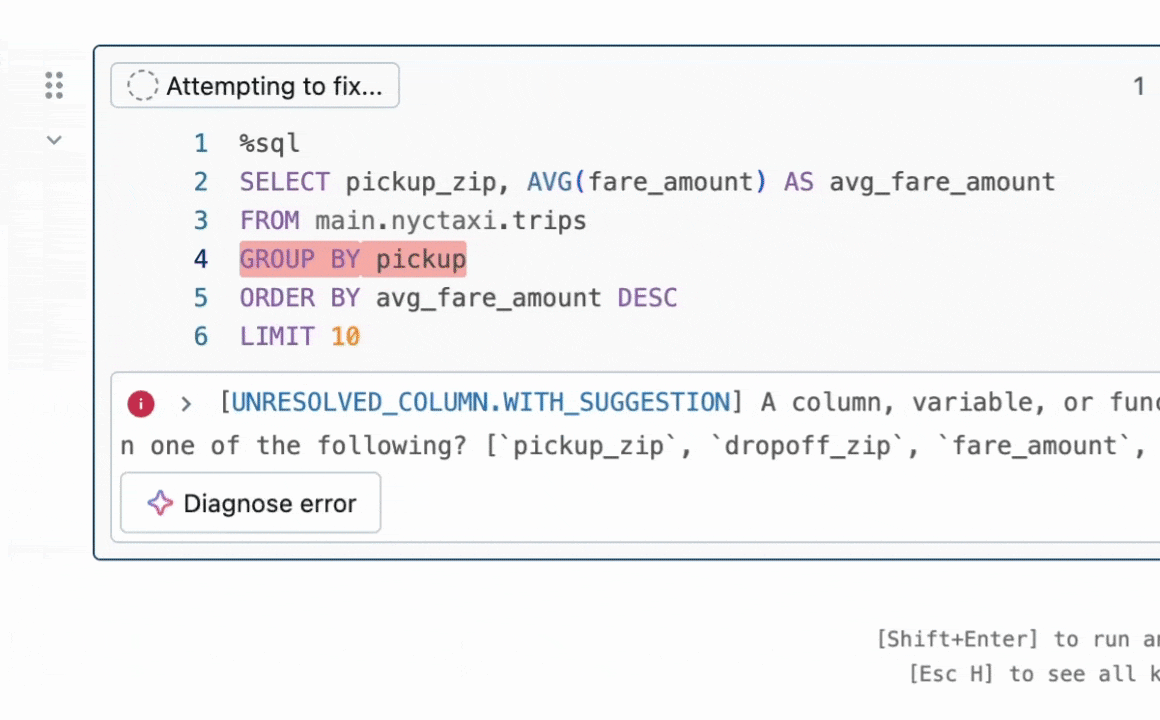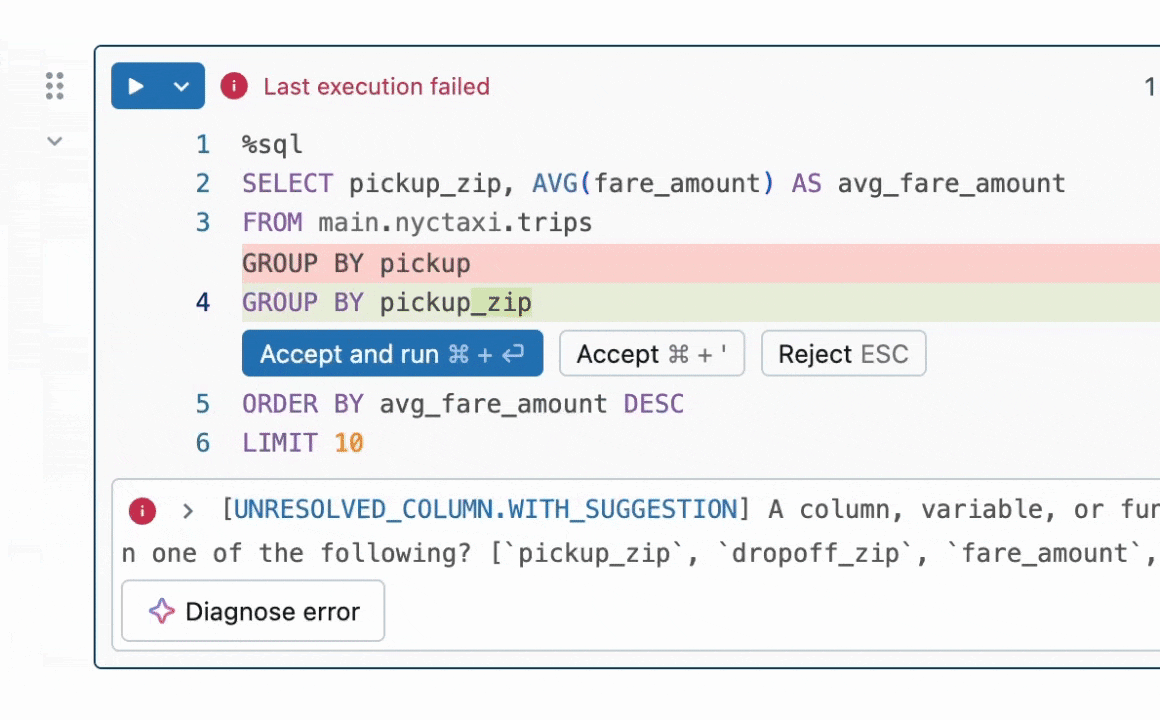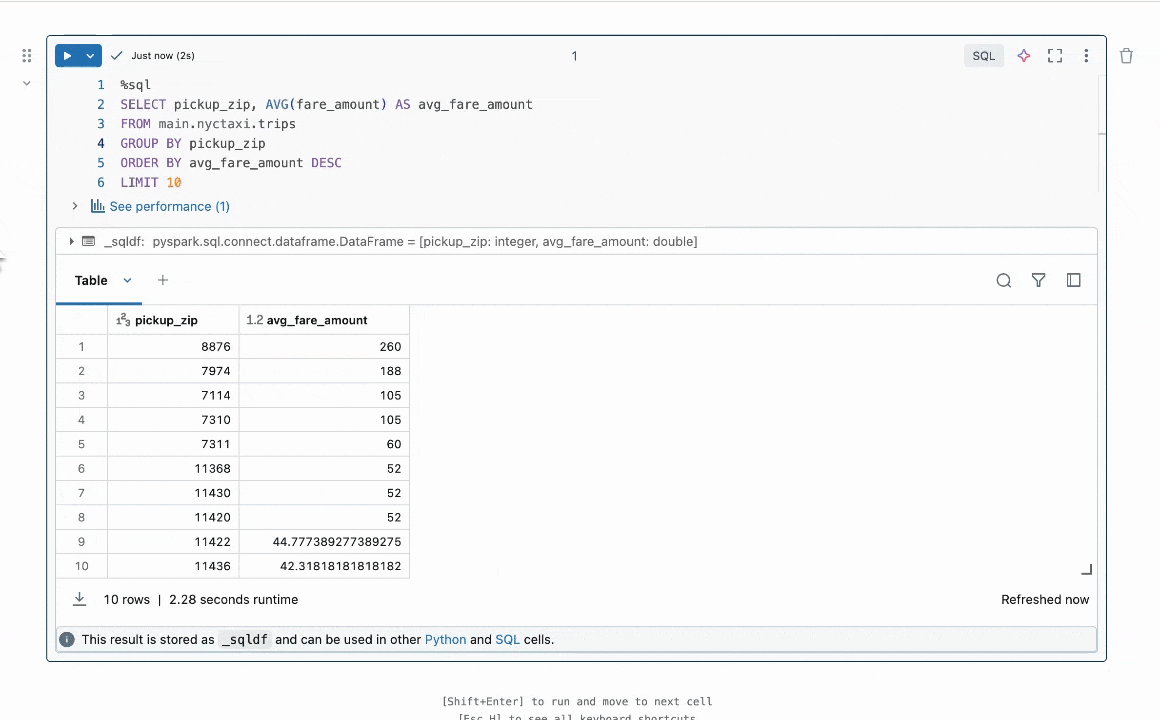
그림 1: Quick Fix는 사용자가 코드 수정을 제안하여 오류를 해결하도록 돕습니다.
결과 요약: 우리는 코드의 버그를 수정하는 프로그램 수정 작업에 초점을 맞춥니다. 이 문제는 LLMs 없이 [1, 2] 그리고 최근에는 LLMs와 함께 [3, 4] 널리 연구되었습니다. 산업에서는 Databricks의 Quick Fix 와 같은 실용적인 LLM 에이전트가 사용 가능합니다. 그림 1은 Databricks 노트북 환경에서 작동하는 Quick Fix 에이전트를 보여줍니다. 이 프로젝트에서는 텔레메트리 분석을 위해 Databricks 직원이 작성한 내부 코드에 Llama 3.1 8b Instruct 모델을 미세 조정했습니다. 미세 조정된 Llama 모델은 내부 사용자에 대한 실시간 A/B 테스트를 통해 다른 LLMs와 비교 평가됩니다. Figure 2 에서 보여주는 결과는 미세 조정된 Llama가 GPT-4o에 비해 수용률이 1.4배 향상되면서 추론 지연 시간이 2배 줄어든 것을 보여줍니다.
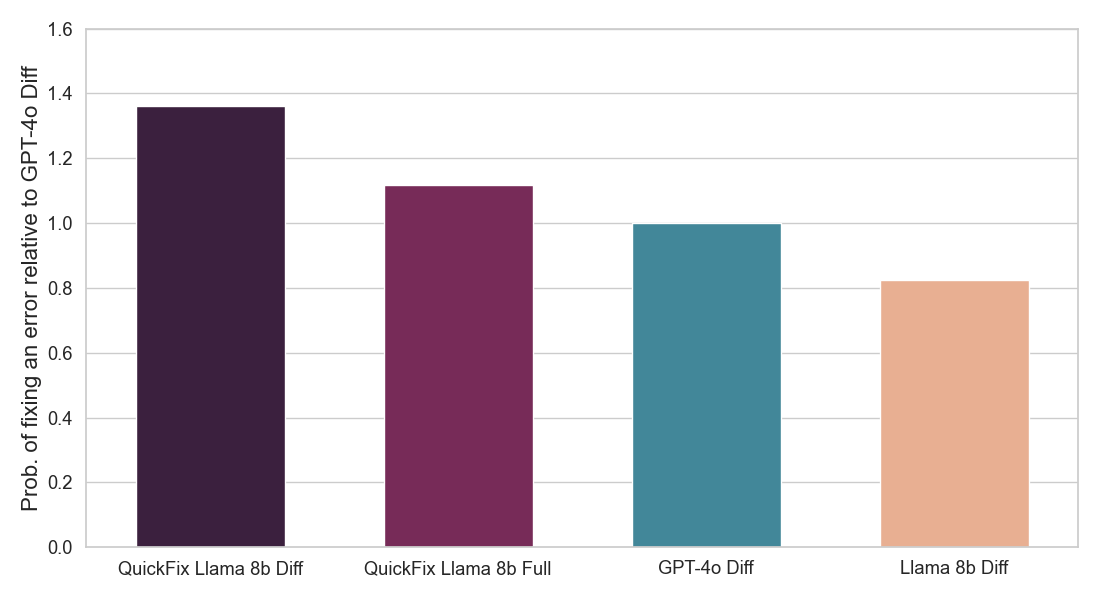
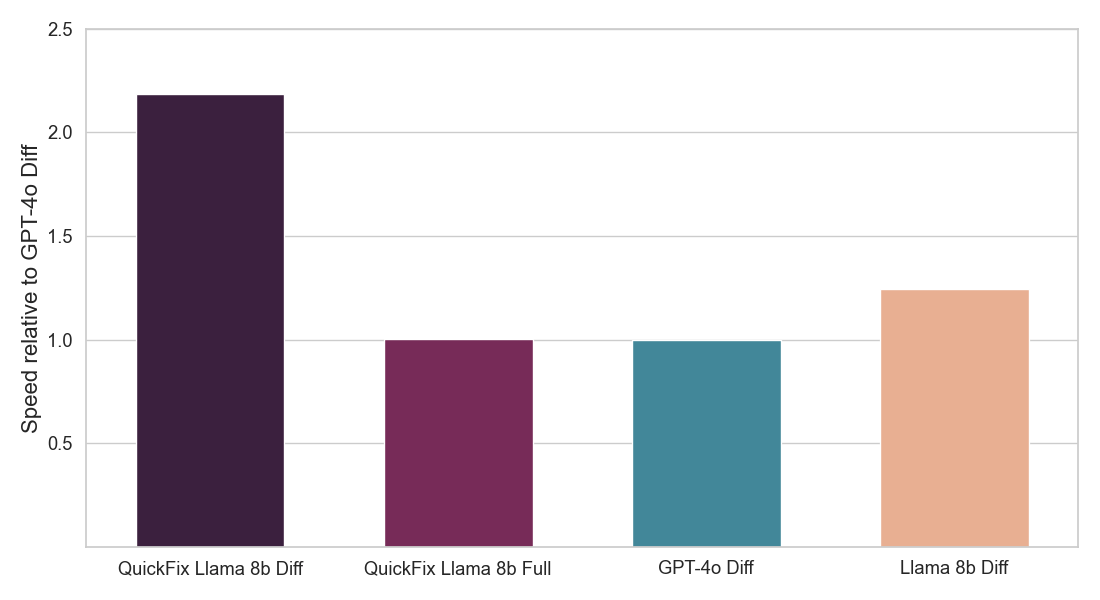
그림 2: 사용자가 수용한 제안된 LLM 수정의 비율을 보여줍니다 (위) 그리고 각 Quick Fix LLM 에이전트의 추론 속도를 보여줍니다 (아래). 두 숫자 모두 GPT-4o 에이전트에 대해 정규화됩니다(아래 세부 사항 참조). 우리의 모델 (QuickFix Llama 8b Diff)은 가장 높은 정확도와 가장 낮은 대기 시간을 모두 달성합니다. diff 접미사가 있는 모델은 버그가 있는 코드에 수정을 생성하고, full 접미사가 있는 모델은 전체 코드를 생성합니다.
왜 중요한가요? 많은 조직들, 특히 기존의 Databricks 고객들은 내부 지식, 개념, 선호도를 포함하는 코딩 사용 데이터를 가지고 있습니다. 우리의 결과에 따르면, 이러한 조직들은 더 나은 코드 품질과 추론 속도를 달성하는 작은 오픈 소스 LLM들을 미세 조정할 수 있습니다. 이러한 모델은 비용, 신뢰성, 준수 이점을 위해 조직 또는 신뢰할 수 있는 제3자에 의해 호스팅될 수 있습니다.
우리는 상호작용 데이터에 대한 훈련이 특히 효과적인 세 가지 이유를 강조합니다. 첫째로, 이는 자연스럽게 생성되므로 주석 처리가 필요하지 않습니다. 둘째로, 이것은 실제로 만나게 되는 예시들을 포함하고 있으므로, 적당한 양에서도 미세 �조정에 특히 유용합니다. 마지막으로, LLM 에이전트와의 상호작용으로 계속해서 상호작용 데이터가 생성되므로, 새롭게 생성된 상호작용 데이터를 반복적으로 사용하여 우리의 LLM을 더욱 미세 조정할 수 있습니다. 이를 통해 Never Ending Learning (NEL)이 가능해집니다.
다음은 무엇인가요? 우리는 이러한 교훈이 다른 엔터프라이즈 애플리케이션에도 적용될 수 있다고 믿습니다. 조직은 Databricks의 미세 조정 서비스를 사용하여 Llama와 같은 LLMs를 프로그램 수정 또는 다른 작업에 대해 미세 조정하고 모델을 단 한 번의 클릭으로 제공할 수 있습니다. 시작하려면 여기를 클릭하세요. 또한 고객이 자신의 데이터를 사용하여 Quick Fix를 개인화할 수 있는 기능을 제공하는 것을 탐색하고 있습니다.
우리의 연구 세부사항
Databricks 워크스페이스 는 생산성 향상을 위한 다양한 LLM 에이전트를 제공합니다. 이에는 코드 자동완성을 위한 LLM 에이전트, 사용자를 돕기 위해 대화에 참여할 수 있는 AI 어시스턴트, 그리고 프로그램 수정을 위한 Quick Fix 에이전트가 포함됩니다. 이 블로그 게시물에서는 Quick Fix 에이전트 (그림 1)에 초점을 맞춥니다.
프로그램 수정은 실제로 어려운 문제입니다. 오류는 구문 오류에서 잘못된 열 이름, 미묘한 의미적 문제에 이르기까지 다양할 수 있습니다. 또한, 개인화 측면이나 제약 조건들이 항상 판매용 LLMs에��서 잘 처리되지 않습니다. 예를 들어, Databricks 사용자들은 일반적으로 표준 ANSI 또는 Spark SQL을 작성하며, PL/SQL 스크립트가 아닙니다. 하지만 다른 조직에서는 다른 형식을 선호할 수 있습니다. 마찬가지로, 코드를 수정할 때 제안된 수정이 올바르더라도 코딩 스타일을 변경하고 싶지 않습니다. GPT-4, o1, 또는 Claude 3.5와 같은 독점 모델을 사용하고 프롬프트 엔지니어링을 통해 이러한 제한 사항을 해결하려고 시도할 수 있습니다. 그러나, 적시에 엔지니어링을 하는 것은 미세 조정만큼 효과적이지 않을 수 있습니다. 또한, 이러한 모델들은 비용이 많이 들고, 지연 시간은 중요한 요소입니다. 왜냐하면 사용자가 코드를 스스로 수정하기 전에 수정 사항을 제안하고 싶기 때문입니다. 컨텍스트 학습 [5] 또는 자기 반성 [6]과 같은 프롬프트 엔지니어링 접근법은 지연 시간을 더욱 늘릴 수 있습니다. 마지막으로, 일부 고객들은 다른 곳에서 호스팅되는 독점적인 모델을 사용하는 것을 주저할 수 있습니다.
Llama 8b, Gemma 4b, R1 Distill Llama 8b 및 Qwen 7b와 같은 작은 오픈소스 모델들은 다른 트레이드오프를 제공하는 대안을 제공합니다. 이러한 모델은 저렴하고 빠르며, 조직 또는 신뢰할 수 있는 제3자에 의해 훈련되고 호스팅될 수 있어 더 나은 준수를 위해 사용될 수 있습니다. 그러나, 그들은 위에 나열된 일부 독점 모델들보다 훨씬 더 나쁜 성능을 보이는 경향이 있습니다. 그림 1에서 볼 수 있듯이, Llama 3.1 8b 지시 모델은 테스트된 모델 중에서 가장 성능이 나쁩니다. 이것은 질문을 던지게 합니다:
우리는 작고 오픈 소스 모델을 적용하면서도 정확도, 비용, 속도에서 상용 모델을 능가할 수 있을까요?
즉��각적인 엔지니어링이 일부 이익을 제공하긴 하지만(아래 결과 참조), LLM을 미세 조정하는 것보다 효과가 덜하며, 특히 작은 모델에 대해서는 그렇습니다. 그러나 효과적인 미세 조정을 위해서는 적절한 도메인 데이터가 필요합니다. 우리는 이것을 어디서 얻나요?
귀하의 상호작용 데이터를 사용하여 Llama 8b를 미세 조정하기
프로그램 수정 작업의 경우, 사용자가 생성하는 유기적인 상호작용 데이터를 사용하여 미세 조정을 수행할 수 있습니다. 이것은 다음과 같이 작동합니다 (그림 3):
 그림 3: LLM의 끝없는 미세 조정을 위해 배포 로그를 사용하여 LLM을 미세 조정합니다.
그림 3: LLM의 끝없는 미세 조정을 위해 배포 로그를 사용하여 LLM을 미세 조정합니다.
- 우리는 버그가 있는 코드 y, 를 사용자가 코드 셀을 처음 실행하여 오류가 발생하는 시점에 기록합니다. 또한 오류 메시지, 주변 코드 셀, 메타데이터(예: 사용 가능한 테이블과 API의 목록).
- 그런 다음 사용자가 원래 버그가 있는 셀에서 코드를 성공적으로 실행할 때마다 코드를 로그에 기록합니다. 이 응답은 Quick Fix Llama 에이전트, 사용자 자신, 또는 둘 다에 의해 생성될 수 있습니다.
- 우리는 (x, y, y') 를 미세 조정을 위한 데이터셋에 저장합니다.
우리는 두 가지 극단적인 경우를 필터링합니다: 예상되는 수정된 코드 y' 가 �실제 코드 y와 동일한 경우, 이는 외부 이유로 인한 버그 수정을 나타내며(예: 다른 곳에서 설정을 변경하여 권한 문제 수정), y' 가 y와 상당히 다른 경우, 이는 목표 지향적인 수정보다 재작성 가능성을 나타냅니다. 이 데이터를 사용하여 주어진 컨텍스트 x 와 버그가 있는 코드 y 를 학습하여 y' 를 생성하는 방법을 배우는 데 사용할 수 있습니다.
우리는 위에서 설명한 대로 처리된 Databricks의 자체 내부 상호작용 데이터를 사용하여 Llama 3.1 8b Instruct 모델을 미세 조정합니다. 우리는 두 가지 유형의 모델을 훈련시킵니다 - 하나는 전체 수정된 코드를 생성하는 모델(전체 모델)이고, 다른 하나는 버그가 있는 코드를 수정하는 데 필요한 코드 차이만을 생성하는 모델(diff 모델)입니다. 후자는 더 적은 토큰을 생성해야 하므로 더 빠르지만, 더 어려운 작업을 해결해야 합니다. 우리는 Databricks의 미세 조정 서비스를 사용하고 다른 학습률과 훈련 반복에 대해 스윕을 수행했습니다. 우리의 A/B 테스트 결과인 그림 2 는 우리의 미세 조정된 Llama 모델이 상용 LLM보다 버그 수정에 훨씬 더 효과적이며 또한 훨씬 빠르다는 것을 보여줍니다.
우리는 상호작용 데이터의 보류된 부분집합에서 정확한 일치 정확도를 측정하는 오프라인 평가를 사용하여 최적의 하이퍼파라미터를 선택합니다. 정확한 일치 정확도는 우리의 LLM이 버그가 있는 코드 y와 컨텍스트 x 를 주어진 수정된 코드 y' 를 생성할 수 있는지를 측정하는 0-1 점수입니다. 이는 A/B 테스팅보다 더 노이즈가 많은 지표이지만, 하이퍼파라미터 선택에 유용한 신호를 제공할 수 있습니다. 우리는 그림 4에서 오프라인 평가 결과를 보여줍니다. 원래의 Llama 모델은 GPT-4o 모델보다 훨씬 나쁘게 수행되지만, 우리의 세밀하게 조정된 Llama 모델은 전체적으로 가장 잘 수행됩니다. 더욱이, 인-컨텍스트 학습(ICL)을 통한 프롬프트 엔지니어링은 상당한 향상을 제공하지만, 여전히 파인 튜닝을 수행하는 것만큼 효과적이지는 않습니다.
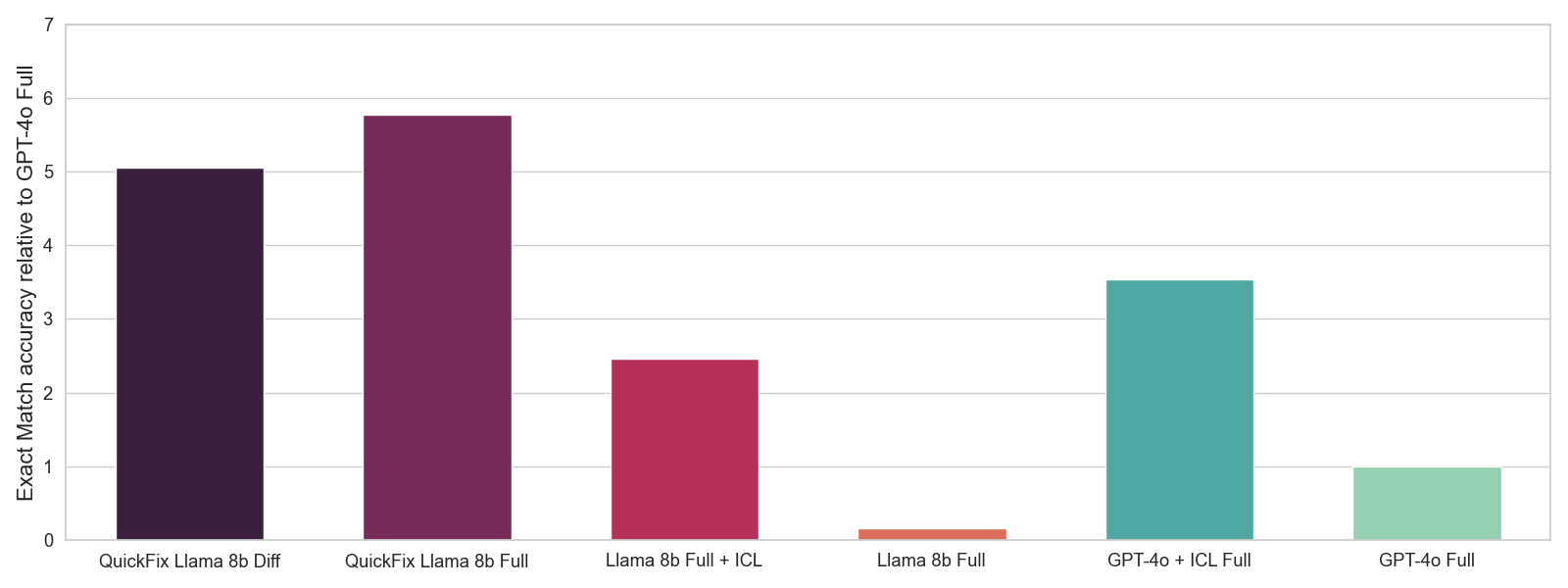 그림 4: 다른 LLM들과의 오프라인 평가. 우리는 ICL에 대해 5개의 예를 사용합니다. 생성된 수정이 실제 수정과 일치하는지 여부에 따라 0-1 정확도의 평균을 보고합니다. 우리는 GPT-4o의 정확도에 비해 정확도를 정규화��합니다.
그림 4: 다른 LLM들과의 오프라인 평가. 우리는 ICL에 대해 5개의 예를 사용합니다. 생성된 수정이 실제 수정과 일치하는지 여부에 따라 0-1 정확도의 평균을 보고합니다. 우리는 GPT-4o의 정확도에 비해 정확도를 정규화��합니다.
마지막으로, 우리의 Quick Fix Llama 모델은 무엇을 배우는가? 아래에 두 가지 예시를 제공하여 이점을 설명합니다.
 예제 1: GPT-4o와 QuickFix Llama 모델을 사용한 예측. 실제 테이블 이름과 상수는 삭제되었습니다.
예제 1: GPT-4o와 QuickFix Llama 모델을 사용한 예측. 실제 테이블 이름과 상수는 삭제되었습니다.
첫 번째 예에서, GPT-4o 에이전트는 버그가 있는 SQL 코드를 PySpark SQL로 잘못 변환했지만, 미세 조정된 QuickFix Llama 모델은 원래의 코드 스타일을 유지했습니다. GPT-4o의 수정은 사용자가 불필요한 차이를 되돌리는 데 시간을 보내게 하여 버그 수정 에이전트의 이점을 감소시킬 수 있습니다.
 예시 2: GPT-4o와 QuickFix Llama 모델을 이용한 예측. 우리는 간결함을 위해 컨텍스트를 보여주지 않지만, 이 경우의 컨텍스트에는 테이블 table2 에 대한 열 _partition_date 가 포함되어 있습니다. 실제 테이블 이름과 상수는 삭제되었습니다.
예시 2: GPT-4o와 QuickFix Llama 모델을 이용한 예측. 우리는 간결함을 위해 컨텍스트를 보여주지 않지만, 이 경우의 컨텍스트에는 테이블 table2 에 대한 열 _partition_date 가 포함되어 있습니다. 실제 테이블 이름과 상수는 삭제되었습니다.
두 ��번째 예에서, 우리는 GPT-4o 에이전트가 오류 메시지에서 주어진 힌트에 과도하게 의존하여 날짜 열을 _event_time 으로 잘못 대체했다는 것을 발견했습니다. 그러나, 올바른 수정은 사용자와 QuickFix Llama가 모두 하는 것처럼 컨텍스트에서 _partition_date 라는 열을 사용하는 것입니다. GPT-4o의 수정은 SQL 엔진이 제안하는 시간 변수를 사용하여 표면적으로는 올바르게 보입니다. 그러나, 이 제안은 도메인 특정 지식의 부족을 보여주며, 이는 미세 조정을 통해 수정될 수 있습니다.
결론
조직들은 맞춤형 LLM 에이전트가 가장 잘 처리할 수 있는 특정 코딩 요구 사항을 가지고 있습니다. 우리는 LLM들을 세밀하게 조정하면 코딩 제안의 품질을 크게 향상시킬 수 있음을 발견했으며, 이는 프롬프트 엔지니어링 접근법을 능가합니다. 특히, 우리가 미세 조정한 작은 Llama 8B 모델들은 훨씬 큰 독점적인 모델들보다 더 빠르고, 저렴하며, 정확했습니다. 마지막으로, 추가적인 주석 비용 없이 상호작용 데이터를 사용하여 훈련 예제를 생성할 수 있습니다. 우리는 이러한 발견들이 프로그램 수리 작업을 넘어서 일반화된다고 믿습니다.
Mosaic AI Model Training을 사용하면 고객들은 Llama와 같은 모델을 쉽게 미세 조정할 수 있습니다. Databricks에서 오픈소스 LLMs를 미세 조정하고 배포하는 방법에 대해 자세히 알아보려면 여기를 클릭하세요. 귀사에 맞춤형 Quick Fix 모델에 관심이 있으신가요? 더 자세히 알아보려면 Databricks 계정 팀에 문의하세요.
감사의 글: 우리는 Michael Piatek, Matt Samuels, Shant Hovsepian, Charles Gong, Ted Tomlinson, Phil Eichmann, Sean Owen, Andy Zhang, Beishao Cao, David Lin, Yi Liu, Sudarshan Seshadri 의 소중한 조언, 도움, 그리고 주석에 감사드립니다.
참조
- 자동 프로그램 수정, Goues 등, 2019. ACM 62.12 (2019) 통신: 56-65.
- Semfix: 의미 분석을 통한 프로그램 수정, Nguyen 등, 2013. 제 35회 국제 소프트웨어 공학 회의(ICSE)에서. IEEE, 2013.
- Inferfix: LLM을 이용한 종단간 프로그램 수정, Jin 등, 2023. 제 31회 ACM 유럽 소프트웨어 공학 회의 및 소프트웨어 공학 기초 심포지엄의 발표문에서.
- RepairAgent: 자율적인, LLM 기반의 프로그램 수정을 위한 에이전트, Bouzenia 외, 2024. arXiv에서 확인 가능 https://arxiv.org/abs/2403.17134.
- 언어 모델은 소수의 학습자들이며, Brown 등, 2020. 신경 정보 처리 시스템의 발전 (NeurIPS).
- 대형 언어 모델 자동 수정: 다양한 자체 수정 전략의 풍경 조사, Pan 등, 2024. 계산 언어학 협회의 트랜잭션(TACL)에서.
*저자들은 알파벳 순으로 나열되어 있습니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)