
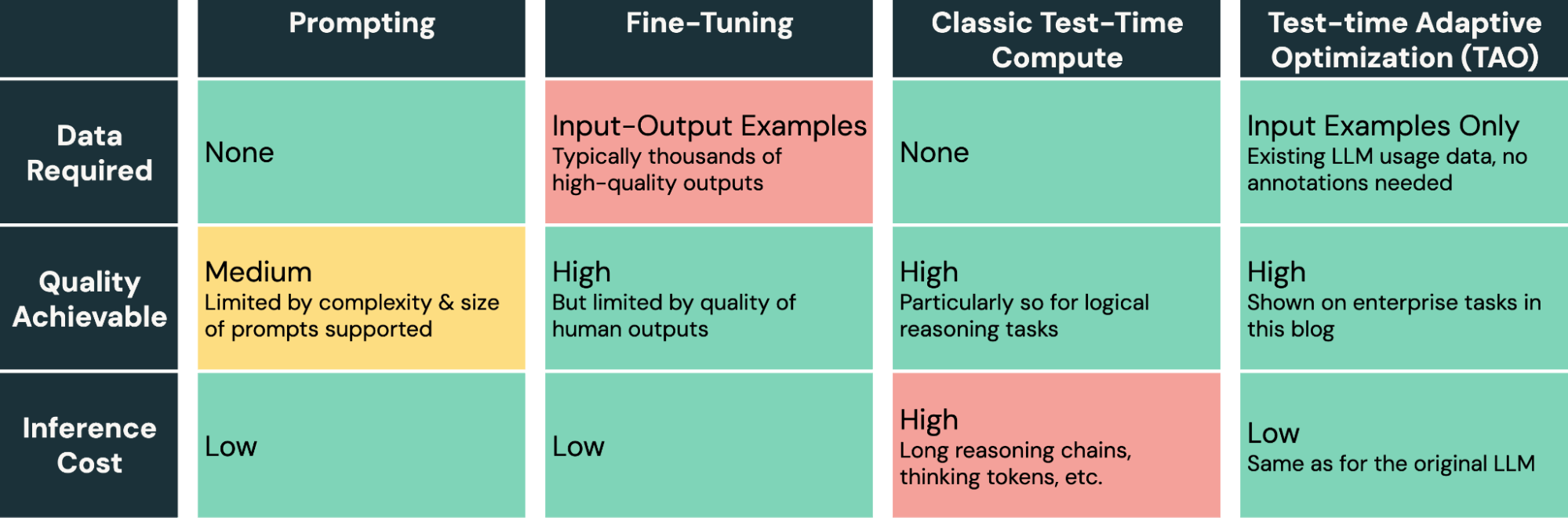
대규모 언어 모델은 새로운 기업 작업에 적용하기 어렵습니다. 프롬프팅은 오류가 발생하기 쉽고 품질 향상이 제한적이며, 파인 튜닝은 대부분의 엔터프라이즈 작업에 사용할 수 없는 대량의 인간이 라벨링한 데이터를 필요로 합니다. 오늘, 우리는 라벨이 없는 사용 데이터만 필요한 새로운 모델 튜닝 방법을 소개하고 있습니다. 이를 통해 기업들은 이미 가지고 있는 데이터만을 사용하여 AI의 품질과 비용을 개선할 수 있습니다. 우리의 방법, 테스트 시간 적응 최적화(TAO)는 테스트 시간 계산(o1과 R1에 의해 널리 알려짐)과 강화 학습(RL)을 활용하여 모델이 과거 입력 예제만을 기반으로 작업을 더 잘 수행하도록 가르칩니다. 이는 인간의 라벨링 노력이 아닌 조정 가능한 튜닝 컴퓨팅 예산에 따라 확장됩니다. 중요한 점은, TAO가 테스트 시간 계산을 사용하더라도 이를 모델을 훈련하는 과정의 일부로 사용하며, 그 모델은 그 후에 직접 작업을 수행하며 낮은 추론 비용(즉, 추론 시간에 추가 계산이 필요하지 않음)을 요구합니다. 놀랍게도, 레이블이 없어도 TAO는 전통적인 미세 조정보다 더 나은 모델 품질을 달성할 수 있으며, 비용이 적은 오픈 소스 모델인 Llama를 비싼 독점 모델인 GPT-4o와 o3-mini와 같은 품질로 만들 수 있습니다.
TAO는 우리 연구팀의 데이터 인텔리전스 프로그램의 일부로, 기업이 이미 가지고 있는 데이터를 사용하여 AI가 특정 도메인에서 뛰어나게 하는 문제에 대해 연구하고 있습니다. TAO를 통해 우리는 세 가지 흥미로운 결과를 얻었습니다:
- 문서 질문 응답 및 SQL 생성과 같은 특수한 엔터프라이즈 작업에서 TAO는 수천 개의 라벨링된 예제에서 전통적인 파인 튜닝을 능가합니다. 레이블이 필요 없이 Llama 8B와 70B와 같은 효율적인 오픈 소스 모델을 GPT-4o와 o3-mini와 같은 비싼 모델과 비슷한 품질로 만듭니다.1
- 또한 다중 작업 TAO를 사용하여 LLM을 여러 작업에 걸쳐 넓게 개선할 수 있습니다. 라벨이 없는 상태에서, TAO는 Llama 3.3 70B의 성능을 광범위한 기업 벤치마크에서 2.4% 향상시킵니다.
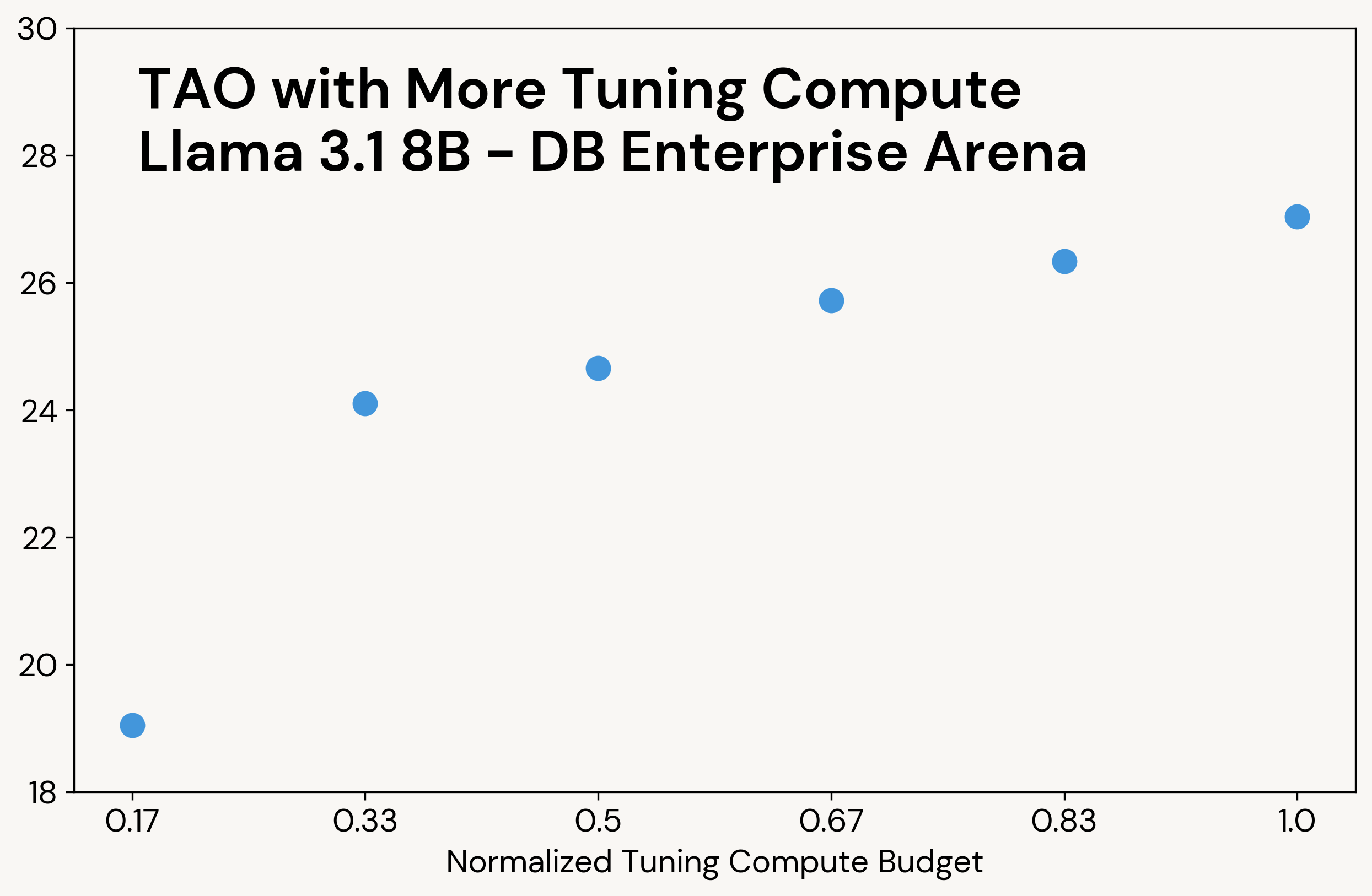
- TAO의 계산 예산을 조정 시간에 늘리면 같은 데이터로 더 나은 모델 품질을 얻을 수 있으며, 조정된 모델의 추론 비용은 동일하게 유지됩니다.
그림 1은 TAO가 FinanceBench, DB Enterprise Arena, 그리고 BIRD-SQL (Databricks SQL 방언을 사용)²와 같은 세 가지 엔터프라이즈 작업에서 Llama 모델을 어떻게 개선하는지 보여줍니다. LLM 입력만 접근할 수 있음에도 불구하고, TAO는 수천 개의 라벨이 있는 예제를 가진 전통적인 미세 조정(FT)을 능가하고, Llama를 비싼 독점 모델과 같은 범위로 가져옵니다.


그림 1: 세 가지 기업 벤치마크에서 Llama 3.1 8B와 Llama 3.3 70B에 대한 TAO. TAO는 품질을 크게 향상시켜 미세 조정을 능가하고 비싼 독점 LLM에 도전합니다.
TAO는 이제 Databricks 고객들이 Llama를 튜닝하고 싶어하는 사람들에게 미리보기로 제공되며, 앞으로 출시될 여러 제품에 적용될 예정입니다. 이 양식 을 작성하여 개인 미리보기의 일환으로 작업에 시도해 보고 싶다는 의사를 표현하세요. 이 게시물에서는 TAO가 어떻게 작동하는지와 우리의 결과에 대해 더 자세히 설명합니다.
TAO는 어떻게 작동합니까? 테스트 시간 계산과 강화 학습을 사용하여 모델을 튜닝합니다
인간이 주석을 단 출력 데이터를 필요로 하는 대신, TAO의 핵심 아이디어는 테스트 시간 계산을 사용하여 모델이 작업에 대한 가능성 있는 응답을 탐색하게 하고, 이러한 응답을 평가하여 LLM을 업데이트하는 강화 학습을 사용하는 것입니다. 이 파이프라인은 비싼 인간의 노력 대신 테스트 시간 계산을 사용하여 확장되어 품질을 향상시킬 수 있습니다. 또한, 과제별 통찰력(예: 사��용자 정의 규칙)을 사용하여 쉽게 맞춤화할 수 있습니다. 놀랍게도, 이런 방식의 스케일링을 고품질의 오픈 소스 모델에 적용하면, 많은 경우에 인간의 라벨보다 더 좋은 결과를 얻을 수 있습니다.

구체적으로, TAO는 네 단계로 구성됩니다:
- 응답 생성: 이 단계는 작업에 대한 예제 입력 프롬프트 또는 쿼리를 수집하는 것으로 시작합니다. Databricks에서는 이러한 프롬프트를 우리의 AI 게이트웨이를 사용하여 어떤 AI 애플리케이션에서든 자동으로 수집할 수 있습니다. 각 프롬프트는 다양한 후보 응답을 생성하는 데 사용됩니다. 여기에는 단순한 사슬 생각 프롬프팅부터 정교한 추론 및 구조화된 프롬프팅 기법에 이르기까지 다양한 생성 전략이 적용될 수 있습니다.
- 응답 점수 매기기: 이 단계에서는 생성된 응답이 체계적으로 평가됩니다. 점수 매기기 방법론에는 보상 모델링, 선호도 기반 점수 매기기, LLM 판사 또는 사용자 정의 규칙을 활용한 작업 특정 검증 등 다양한 전략이 포함됩니다. 이 단계는 각 생성된 응답이 품질과 기준과의 일치성에 대해 정량적으로 평가되도록 보장합니다.
- 강화 학습 (RL) 훈련: 마지막 단계에서는 RL 기반 접근법이 적용되어 LLM을 업데이트하며, 모델이 이전 단계에서 확인한 고점수 응답과 밀접하게 일치하는 출력을 생성하도록 안내합니다. 이 적응형 학습 과정을 통해 모델은 예측을 개선하여 품질을 향상시킵니다.
- 지속적인 개선: TAO가 필요로 하는 유일한 데이터는 LLM 입력 예제입니다. 사용자는 LLM과 상호 작용함으로써 이 데이터를 자연스럽게 생성합니다. LLM이 배포되자마자, 다음 라운드의 TAO를 위한 훈련 데이터를 생성하기 시작합니다. Databricks에서는, LLM이 더 많이 사용될수록 TAO 덕분에 더 좋아질 수 있습니다.
중요한 것은, TAO가 테스트 시간 계산을 사용하지만, 이를 사용하여 작업을 직접 실행하는 모델을 훈련 합니다. 이는 TAO가 생성하는 모델이 원래 모델과 동일한 추론 비용과 속도를 가지며, o1, o3 및 R1과 같은 테스트 시간 계산 모델보다 훨씬 적다는 것을 의미합니다. 우리의 결과가 보여주듯이, TAO로 훈련된 효율적인 오픈 소스 모델은 품질에서 선도적인 독점 모델에 도전할 수 있습니다.
TAO는 AI 모델을 튜닝하기 위한 툴킷에서 강력한 새로운 방법을 제공합니다. 느리고 오류가 발생하기 쉬운 프롬프트 엔지니어링과 비싼 고품질 인간 라벨을 생성하는 데 필요한 파인 튜닝과 달리, TAO는 AI 엔지니어가 작업의 대표적인 입력 예제를 단순히 제공함으로써 훌륭한 결과를 얻을 수 있게 합니다.
TAO는 필요에 따라 맞춤화할 수 있는 매우 유연한 방법이지만, Databricks에서의 기본 구현은 다양한 엔터프라이즈 작업에서 상자를 벗어나도 잘 작동합니다. 우리의 구현의 핵심은 우리 팀이 개발한 새로운 강화 학습 및 보상 모델링 기법으로, TAO가 탐색을 통해 학습하고 그런 다음 RL을 사용하여 기본 모델을 튜닝할 수 있게 합니다. 예를 들어, TAO를 구동하는 요소 중 하나는 우리가 엔터프라이즈 작업을 위해 훈련시킨 맞춤형 보상 모델인 DBRM으로, 다양한 작업 범위에서 정확한 점수 신호를 생성할 수 있습니다.
TAO를 사용하여 작업 성능 향상
이 섹션에서는 우리가 TAO를 사용하여 특수한 엔터프라이즈 작업에서 LLM을 튜닝하는 방법에 대해 더 깊이 들어가 보겠습니다. 우리는 인기 있는 오픈 소스 벤치마크와 우리가 도메인 인텔리전스 벤치마크 스위트 (DIBS)의 일부로 개발한 내부 벤치마크를 포함한 세 가지 대표적인 벤치마크를 선택했습니다.

각 작업에 대해, 우리는 여러 접근법을 평가했습니다:
- 오픈 소스 Llama 모델 (Llama 3.1-8B 또는 Llama 3.3-70B)을 그대로 사용합니다.
- Llama에서의 파인 튜닝. 이를 위해, 우리는 수천 개의 예제가 있는 크고 현실적인 입력-출력 데이터셋을 사용하거나 생성했습니다. 이는 일반적으로 미세 조정으로 좋은 성능을 달성하기 위해 필요한 것입니다. 이에는 다음이 포함됩니다:
- FinanceBench를 위한 SEC 문서에 대한 7200개의 합성 질문.
- DB Enterprise Arena에 대한 4800개의 인간이 작성한 입력.
- Databricks SQL 방언에 맞게 수정된 BIRD-SQL 훈련 세트에서 8137개의 예제.
- 우리의 미세 조정 데이터셋에서 예제 입력만을 사용하고 출력은 사용하지 않고, 우리의 DBRM 기업 중심 보상 모델을 사용하여 Llama에서 TAO를 사용합니다. DBRM 자체는 이러한 벤치마크에서 훈련되지 않습니다.
- 고품질의 독점 LLMs - GPT 4o-mini, GPT 4o 및 o3-mini.
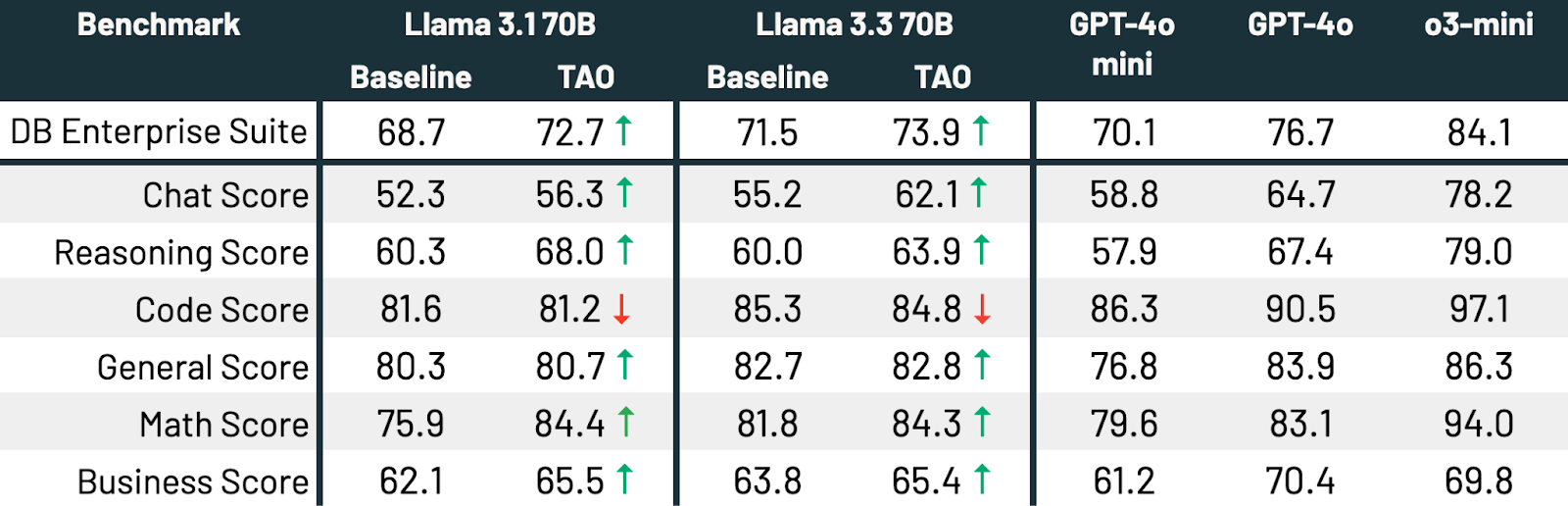
표 3에서 보듯이, 모든 세 가지 벤치마크와 두 가지 Llama 모델에서 TAO는 기본 Llama 성능을 크게 향상시키며, 미세 조정을 넘어섭니다.

클래식 테스트 시간 계산과 마찬가지로, TAO는 더 많은 계산을 할 수 있을 때 더 높은 품질의 결과를 생성합니다(예를 들어, 그림 3 참조). 그러나 테스트 시간 계산과는 달리, 이 추가 계산은 조정 단계 동안에만 사용되며; 최종 LLM은 원래 LLM과 동일한 추론 비용을 가집니다. 예를 들어, o3-mini는 우리의 작업에서 다른 모델보다 5-10배 더 많은 출력 토큰을 생성하여 비례적으로 더 높은 추론 비용을 초래하는 반면, TAO는 원래 Llama 모델과 동일한 추론 비용을 가집니다.
다중 작업 지능 향상을 위한 TAO
지금까지, 우리는 SQL 생성과 같은 개별적인 좁은 작업에서 LLM을 개선하기 위해 TAO를 사용했습니다. 그러나, 에이전트가 더 복잡해짐에 따라, 기업들은 하나 이상의 작업을 수행할 수 있는 LLM이 점점 더 필요해집니다. 이 섹션에서는 TAO가 기업 작업의 범위에서 모델 성능을 어떻게 넓게 개선할 수 있는지 보여줍니다.
이 실험에서는 코딩, 수학, 질문 응답, 문서 이해, 채팅 등 다양한 엔터프라이즈 작업을 반영하는 175,000개의 프롬프트를 모았습니다. 그런 다음 우리는 Llama 3.1 70B와 Llama 3.3 70B에서 TAO를 실행했습니다. 마지막으로, 우리는 인기 있는 LLM 벤치마크 (예: Arena Hard, LiveBench, GPQA Diamond, MMLU Pro, HumanEval, MATH) 및 엔터프라이즈에 관련된 여러 영역에서 내부 벤치마크를 포함하는 엔터프라이즈 관련 작업 스위트를 테스트했습니다.
TAO는 �두 모델의 성능을 의미있게 향상시킵니다[t][u]. Llama 3.3 70B와 Llama 3.1 70B는 각각 2.4 백분율점과 4.0 백분율점으로 향상됩니다. TAO는 Llama 3.3 70B를 엔터프라이즈 작업에서 GPT-4o에 상당히 가깝게 만듭니다.[v][w]. 이 모든 것은 인간의 레이블링 비용 없이, 대표적인 LLM 사용 데이터와 우리의 TAO 생산 구현만으로 달성됩니다. 품질은 코딩을 제외한 모든 하위 점수에서 향상되며, 성능은 고정됩니다.
실제로 TAO 사용하기
TAO는 테스트 시간 계산을 활용하여 많은 작업에서 놀랍게도 잘 작동하는 강력한 튜닝 방법입니다. 자신의 작업에서 성공적으로 사용하려면 다음이 필요합니다:
- 작업에 대한 충분한 예제 입력 (수천 개), 배포된 AI 애플리케이션 (예: 에이전트에게 보낸 질문)에서 수집하거나 합성적으로 생성합니다.
- 충분히 정확한 점수 매기기 방법: Databricks 고객들에게는 여기서 우리의 맞춤 보상 모델인 DBRM이 TAO의 구현을 지원하는 강력한 도구가 있지만, 작업에 적합한 사용자 정의 점수 규칙이나 검증기를 DBRM에 추가할 수 있습니다.
TAO와 다른 모델 개선 방법을 가능하게 하는 베스트 프랙티스 중 하나는 AI 애��플리케이션에 대한 데이터 플라이휠을 생성하는 것입니다. AI 애플리케이션을 배포하자마자, Databricks Inference Tables와 같은 서비스를 통해 입력, 모델 출력, 그리고 다른 이벤트를 수집할 수 있습니다. 그런 다음 입력만 사용하여 TAO를 실행할 수 있습니다. 애플리케이션을 사용하는 사람이 많을수록, 튜닝에 사용할 데이터가 더 많이 생기고 - TAO 덕분에 - LLM이 더 좋아집니다.
결론 및 Databricks에서 시작하기
이 블로그에서는 라벨링된 데이터가 필요 없는 고품질 결과를 달성하는 새로운 모델 튜닝 기법인 테스트 시간 적응 최적화 (TAO)를 소개했습니다. 우리는 기업 고객들이 표준 미세 조정에 필요한 라벨이 있는 데이터가 부족한 주요 도전 과제를 해결하기 위해 TAO를 개발했습니다. TAO는 테스트 시간 계산과 강화 학습을 사용하여 기업이 이미 가지고 있는 데이터, 예를 들어 입력 예제를 사용하여 모델을 개선하고, 더 작은 모델을 사용하여 비용을 줄이는 것이 간단하게 어떤 배포된 AI 애플리케이션의 품질을 개선합니다. TAO는 테스트 시간 계산의 힘을 보여주는 매우 유연한 방법이며, 우리는 이것이 개발자들에게 강력하고 간단한 새로운 도구를 제공할 것이라고 믿습니다. 이 도구는 프롬프팅과 미세 조정과 함께 사용할 수 있습니다.
Databricks 고객들은 이미 Llama에서 TAO를 사적인 미리보기로 사용하고 있습니다. 이 양식 을 작성하여 개인 미리보기의 일환으로 작업에 시도해 보고 싶다는 의사를 표현하세요. TAO는 우리의 다가오는 AI 제품 업데이트와 출시에도 많이 통합되고 있습니다 - 계속 주목해 주세요!
¹ 저자: Raj Ammanabrolu, Ashutosh Baheti, Jonathan Chang, Xing Chen, Ta-Chung Chi, Brian Chu, Brandon Cui, Erich Elsen, Jonathan Frankle, Ali Ghodsi, Pallavi Koppol, Sean Kulinski, Jonathan Li, Dipendra Misra, Jose Javier Gonzalez Ortiz, Sean Owen, Mihir Patel, Mansheej Paul, Cory Stephenson, Alex Trott, Ziyi Yang, Matei Zaharia, Andy Zhang, Ivan Zhou
² 이 블로그에서는 o3-mini-medium을 사용합니다.
³ 이것은 Databricks의 SQL 방언과 제품에 맞게 수정된 BIRD-SQL 벤치마크입니다.