VulnWatch: 취약점 우선 순위 결정을 위한 AI 강화
AI 기반 취약점 우선 순위 지정이 어떻게 Databricks의 보안을 강화하는지 살펴보세요. 이는 위협 탐지를 자동화하고, 수동 작업을 줄이며, 중요한 위험에 대한 집중을 향상시킵니다.

Summary
- Databricks가 AI를 어떻게 사용하여 자동으로 제3자 라이브러리의 취약점을 식별하고 순위를 매기는지.
- AI가 보안 팀의 수동 작업을 줄이는 영향.
- 심각성과 Databricks 인프라에 대한 관련성에 기반하여 취약점을 우선 순위로 정하는 것의 주요 이점.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
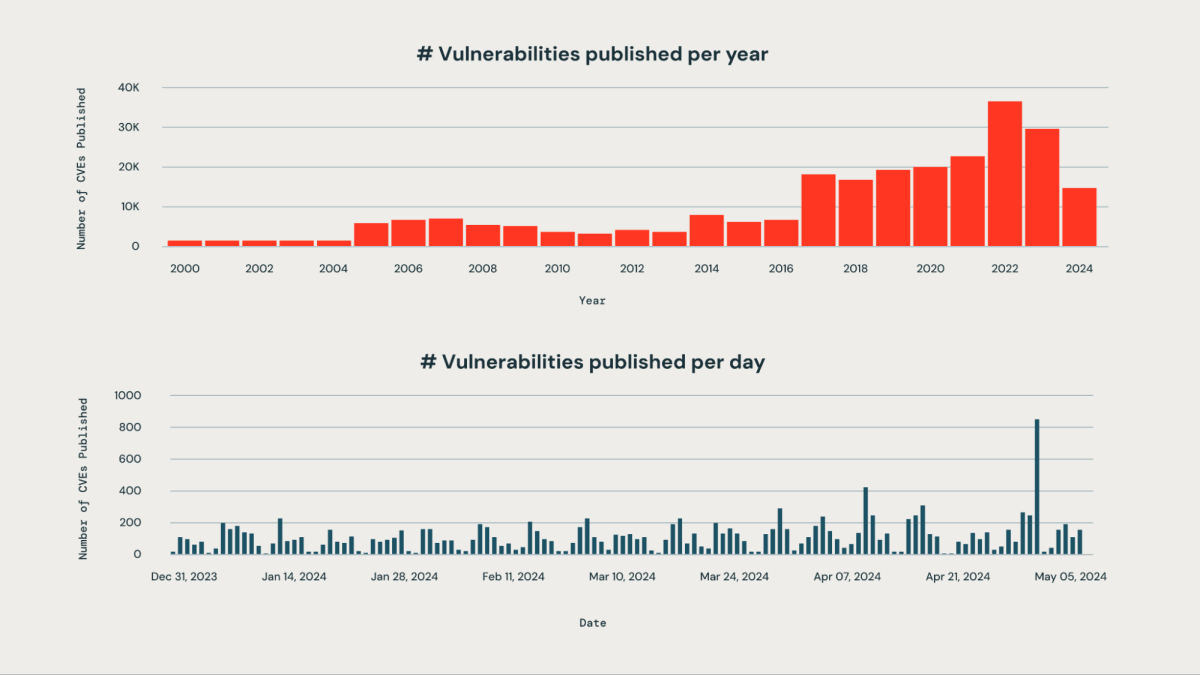
모든 조직은 그들의 조직 내에서 사용되는 대량의 제3자 라이브러리에 영향을 미치는 새로운 취약점을 올바르게 우선 순위를 정하는 것에 도전하고 있습니다. 매일 발표되는 취약점의 양이 방대하여 수동 모니터링은 비효율적이고 자원이 많이 듭니다.
Databricks에서는 회사의 목표 중 하나가 데이터 인텔리전스 플랫폼을 보호하는 것입니다. 우리의 엔지니어링 팀은 AI 기반 시스템을 설계하여 그들이 공개되자마자 취약점을 능동적으로 감지, 분류, 우선 순위를 정하며, 이는 그들의 심각성, 잠재적 영향, 그리고 Databricks 인프라에 대한 관련성에 기반합니다. 이 접근법은 중요한 취약점이 눈에 띄지 않게 되는 위험을 효과적으로 완화할 수 있게 해줍니다. 우리 시스템은 사업 중요 취약점을 약 85%의 정확도로 식별하는 데 성공했습니다. 우리의 우선 순위 알고리즘을 활용하여 보안 팀은 수동 작업량을 95% 이상 크게 줄였습니다. 이제 그들은 수백 개의 문제를 걸러내는 대신 즉시 조치가 필요한 취약점 5%에 집중할 수 있습니다.
다음 몇 단계에서는 AI 기반 접근 방식이 어떻게 취약점을 식별하고, 분류하고, 순위를 매기는 데 도움이 되는지 살펴볼 것입니다.
우리 시스템이 어떻게 지속적으로 취약점을 표시하는지
이 시스템은 정기적으로 중요한 취약점을 식별하고 플래그를 지정합니다. 이 과정은 몇 가지 주요 단계를 포함합니다:
- 데이터 수집 및 처리
- 관련 특징 생성
- AI를 사용하여 일반적인 취약점 및 노출(CVEs)에 대한 정보를 추출
- 그들의 심각성에 따라 취약점을 평가하고 점수를 매깁니다.
- 추가 조치를 위한 Jira 티켓 생성.
아래 그림은 전체 작업 흐름을 보여줍니다.
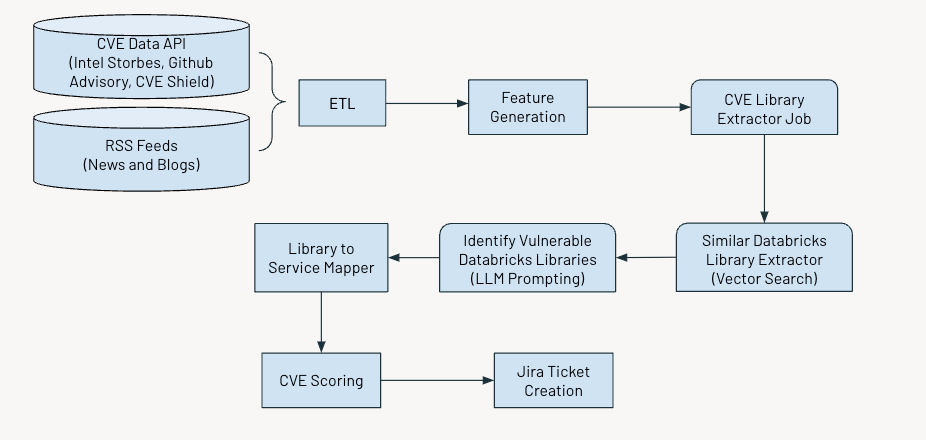
Data Ingestion
우리는 공개적으로 공개된 사이버 보안 취약점을 식별하는 Common Vulnerabilities and Exposures (CVE) 데이터를 수집하며, 이는 다음과 같은 여러 출처에서 얻습니다:
- Intel Strobes API: 이는 소프트웨어 패키지와 버전에 대한 정보와 세부 사항을 제공합니다.
- GitHub Advisory Database: 대부분의 경우, 취약점이 CVE로 기록되지 않을 때, Github 고지사항으로 나타납니다.
- CVE Shield: 이것은 최근 소셜 미디어 피드에서 트렌드를 보이는 취약성 데이터를 제공합니다.
또한, securityaffairs와 hackernews 등의 소스에서 RSS 피드를 수집하고 사이버 보안 취약점에 대해 언급하는 다른 뉴스 기사와 블로그를 모읍니다.
피처 생성
다음으로, 우리는 각 CVE에 대해 다음의 특징을 추출할 것입니다:
- 설명
- CVE의 연령
- CVSS 점수 (Common Vulnerability Scoring System)
- EPSS 점수 (Exploit Prediction Scoring System)
- 영향 점수
- 취약점 이용 가능성
- 패치의 가용성
- X에서의 트렌드 상태
- 고지서의 수
CVSS 와 EPSS 점수는 취약점의 심각성과 이용 가능성에 대한 중요한 통찰력을 제공하지만, 특정 상황에서의 우선 순위 결정에 완전히 적용되지 않을 수 있습니다.
CVSS 점수는 조직의 특정 맥락이나 환경을 완전히 포착하지 못하므로, 높은 CVSS 점수를 가진 취약점이 사용되지 않거나 다른 보안 조치에 의해 적절히 완화된 경우에는 그렇게 중요하지 않을 수 있습니다.
마찬가지로, EPSS 점수는 활용 가능성을 추정하지만, 특정 조직의 인프라나 보안 상태를 고려하지는 않습니다. 따라서 높은 EPSS 점수는 일반적으로 이용될 가능성이 있는 취약점을 나타낼 수 있습니다. 그러나, 영향을 받는 시스템이 조직의 인터넷 공격 표면의 일부가 아니라면 여전히 관련성이 없을 수 있습니다.
CVSS와 EPSS 점수에만 의존하면, 우선 순위가 높은 경고가 쏟아져 나와, 이를 관리하고 우선 순위를 정하는 것이 어려워집니다.
취약점 점수화
우리는 위의 특징에 기반한 점수의 앙상블을 개발하였습니다 - 심각성 점수, 구성 요소 점수 및 주제 점수 - 이는 CVE들을 우선 순위로 정하는데 사용되며, 그 세부 사항은 아래에 제공됩니다.
심각도 점수
이 점수는 CVE의 중요성을 커뮤니티에 양적으로 나타내는 데 도움이 됩니다. 우리는 CVSS, EPSS, 그리고 영향 점수의 가중 평균으로 점수를 계산합니다. CVE Shield 및 기타 뉴스 피드로부터의 데이터 입력은 보안 커뮤니티와 우리의 동료 회사들이 주어진 CVE의 영향을 어떻게 인식하는지를 판단하는 데 도움이 됩니다. 이 점수의 높은 값은 커뮤니티와 우리 조직에 중요하다고 판단된 CVE에 해당합니다.
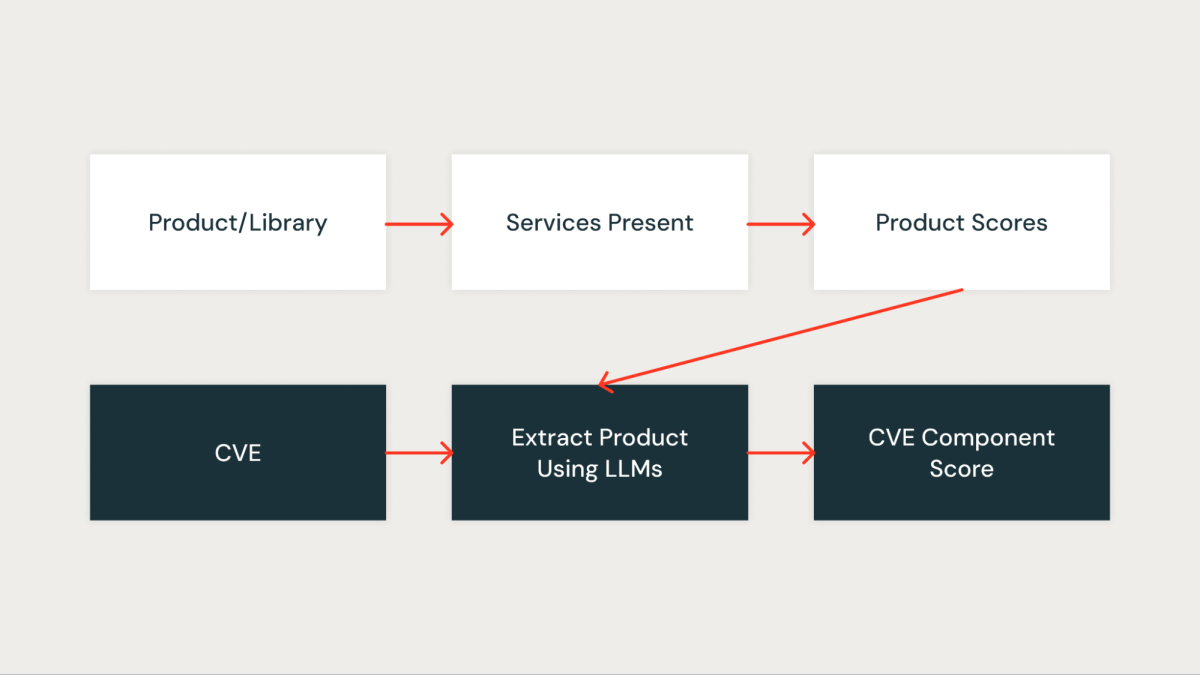
컴포넌트 점수
이 점수는 CVE가 우리 조직에 얼마나 중요한지를 정량적으로 측정합니다. 조직 내의 모든 라이브러리는 먼저 라이브러리에 의해 영향을 받는 서비스에 기반하여 점수가 부여됩니다. 중요한 서비스에 존재하는 라이브러리는 더 높은 점수를 받고, 비중요 서비스에 존재하는 라이브러리는 더 낮은 점수를 받습니다.
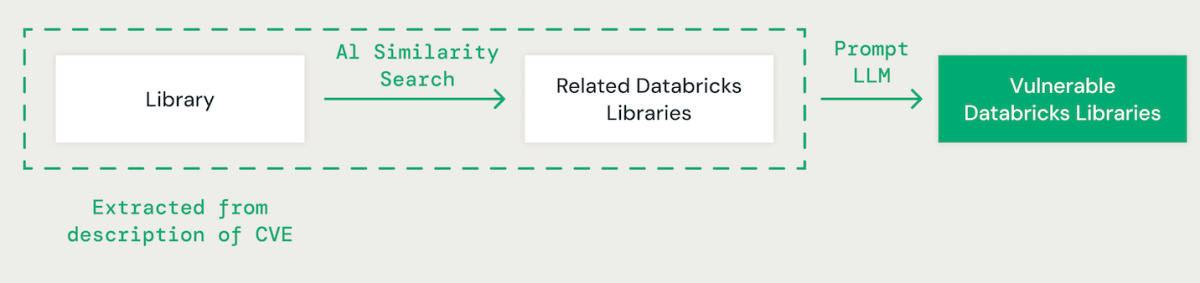
AI 기반 라이브러리 매칭
대형 언어 모델(LLM)을 사용한 few-shot 프롬프팅을 활용하여, 각 CVE의 설명에서 관련 라이브러리를 추출합니다. 그 후, 우리는 AI 기반 벡터 유사성 접근법을 사용하여 식별된 라이브러리를 기존 Databricks 라이브러리와 매칭합니다. 이는 라이브러리 이름의 각 단어를 비교를 위한 임베딩으로 변환하는 것을 포함합니다.
Databricks 라이브러리와 CVE 라이브러리를 매칭할 때, 다른 라이브러리 간의 종속성을 이해하는 것이 중요합니다. 예를 들어, IPython의 취약점이 CPython에 직접적인 영향을 미치지 않을 수 있지만, CPython의 문제는 IPython에 영향을 줄 수 있습니다. 또한, "scikit-learn", "scikitlearn", "sklearn" 또는 "pysklearn"과 같은 라이브러�리 명명 규칙의 변형은 라이브러리를 식별하고 매칭할 때 고려해야 합니다. 더욱이, 버전별 취약점을 고려해야 합니다. 예를 들어, OpenSSL 버전 1.0.1에서 1.0.1f까지 취약할 수 있지만, 1.0.1g에서 1.1.1로의 후속 버전에서의 패치는 이러한 보안 위험을 해결할 수 있습니다.
LLM은 고급 추론 및 업계 전문 지식을 활용하여 라이브러리 매칭 과정을 향상시킵니다. 우리는 취약한 종속 패키지를 식별하는 데 있어 정확도를 향상시키기 위해 실제 데이터 세트를 사용하여 다양한 모델을 미세 조정했습니다.
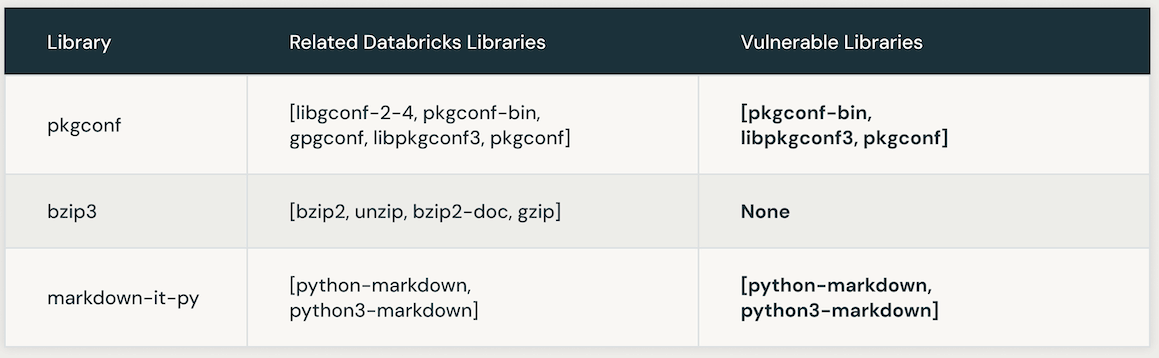
다음 표는 특정 CVE에 연결된 취약한 Databricks 라이브러리의 인스턴스를 보여줍니다. 초기에는 AI 유사성 검색이 CVE 라이브러리와 밀접하게 연관된 라이브러리를 찾아내는 데 사용됩니다. 그 후, LLM이 Databricks 내의 유사한 라이브러리의 취약성을 확인하는 데 사용됩니다.
정확성과 효율성을 위한 LLM 명령 최적화 자동화
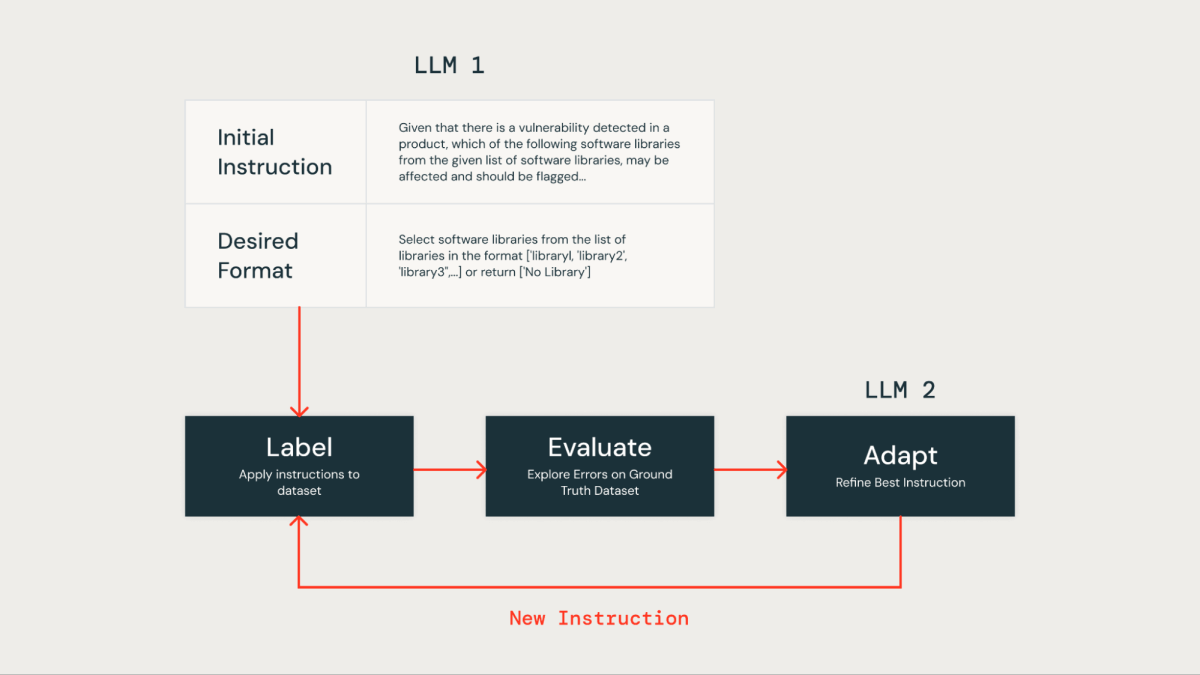
LLM 프롬프트에서 수동으로 명령어를 최적화하는 것은 노동 집약적이며 오류가 발생하기 쉽습니다. 보다 효율적인 접근법은 반복적인 방법을 사용하여 자동으로 여러 세트의 지시사항을 생성하고 이를 실제 데이터 세트에서 우수한 성능을 위해 최적화하는 것입니다. 이 방법은 인간의 오류를 최소화하고 시간이 지남에 따라 명령어의 향상을 더 효과적이고 정확하게 보장합니다.
우리는 이 자동 명령어 최적화 기법 을 우리 자체의 LLM 기반 솔루션을 개선하기 위해 적용하였습니다. 처음에는 데이터셋 라벨링을 위해 LLM에 지시사항과 원하는 출력 형식을 제공했습니다. 그 결과는 그라운드 트루스 데이터셋과 비교되었으며, 이는 우리의 제품 보안 팀에서 제공한 인간이 라벨링한 데이터를 포함하고 있습니다.
그 후, "Instruction Tuner"라는 두 번째 LLM을 사용했습니다. 우리는 초기 프롬프트와 실제 평가에서 식별된 오류를 입력했습니다. 이 LLM은 반복적으로 개선된 프롬프트를 생성합니다. 옵션을 검토한 후, 우리는 정확도를 최적화하기 위해 가장 잘 수행되는 프롬프트를 선택했습니다.
LLM 지시사항 최적화 기법을 적용한 후, 다음과 같은 세밀한 프롬프트를 개발했습니다:
적절한 LLM 선택하기
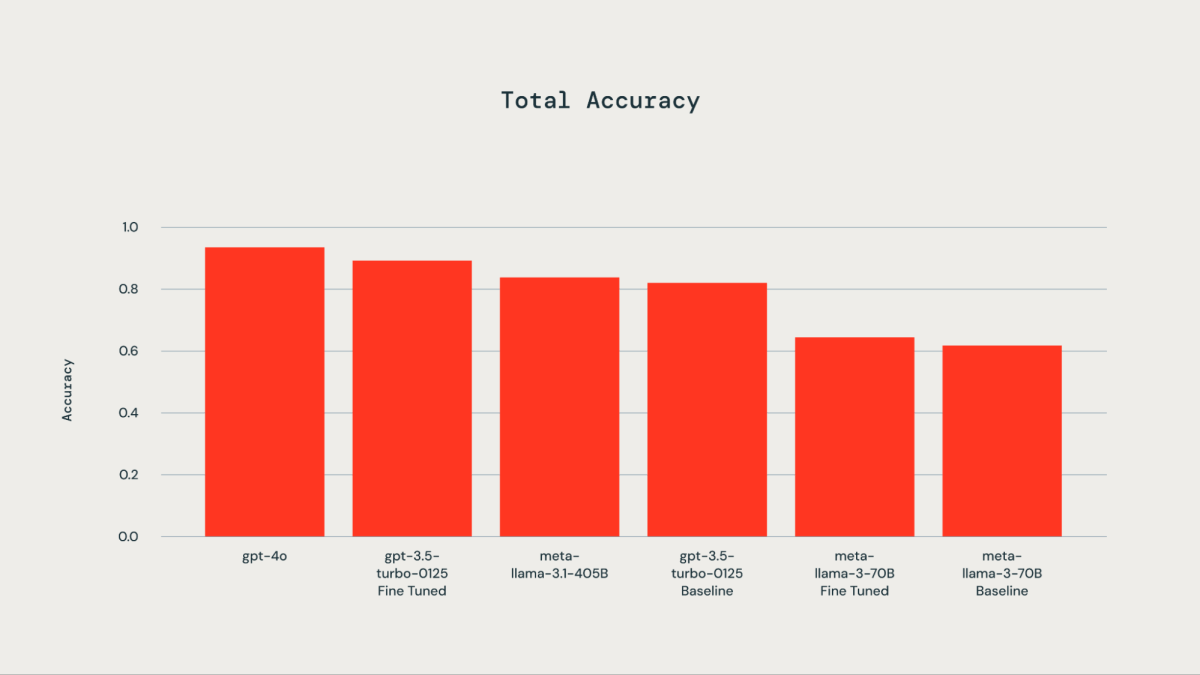
300개의 수동으로 레이블링된 예제로 구성된 실제 데이터 세트가 미세 조정 목적으로 사용되었습니다. 테스트된 LLM에는 gpt-4o, gpt-3.5-Turbo가 포함되었습니다. llama3-70B, 그리고 llama-3.1-405b-instruct. 동반하는 그래프에서 볼 수 있듯이, 기본 데이터 세트를 세밀하게 조정함으로써 gpt-3.5-turbo-0125 기본 모델에 비해. Databricks 미세 조정 API 를 사용하여 llama3-70B를 미세 조정하면 기본 모델에 비해 약간의 개선만을 가져왔습니다. gpt-3.5-turbo-0125의 정확도는 fine-tuned 모델이 gpt-4o와 비교하여 비슷하거나 약간 낮았습니다. 마찬가지로, llama-3.1-405b-instruct의 정확성 gpt-3.5-turbo-0125의 결과와 비교하여 약간 낮았습니다. 세밀하게 조정된 모델의 정확도가 향상되었습니다.
CVE에 있는 Databricks 라이브러리가 한 번 식별되면, 해당 라이브러리의 점수(library_score 라고 위에서 설명함)가 CVE의 구성 요소 점수로 할당됩니다.
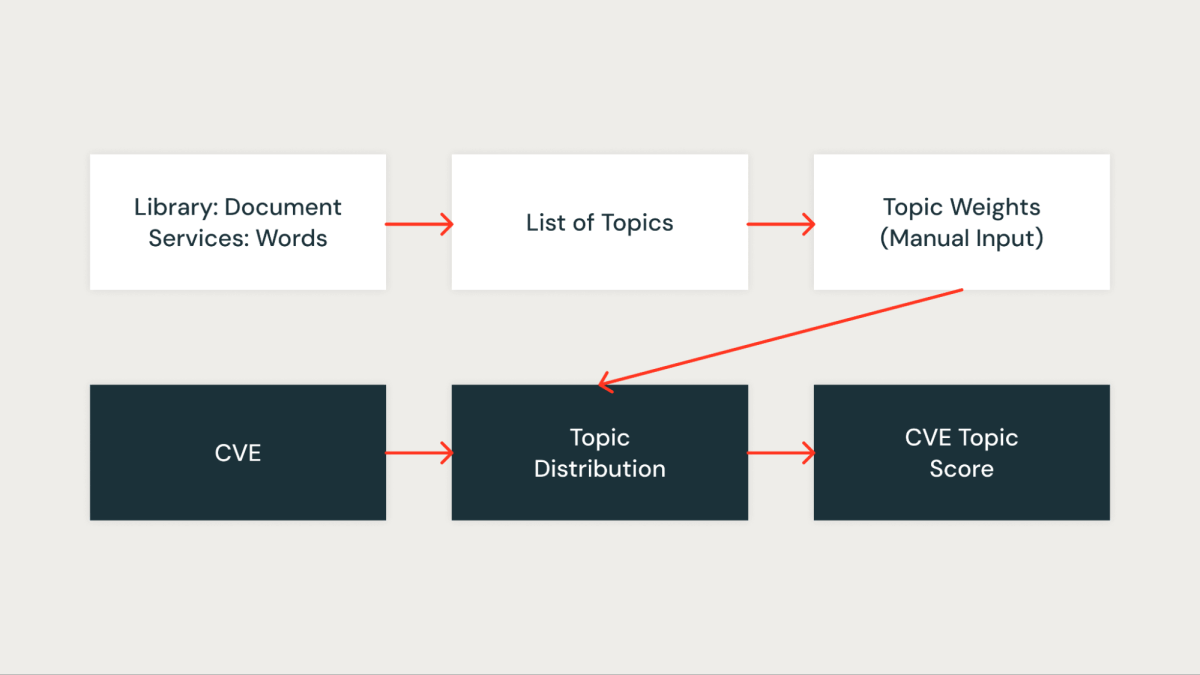
주제 점수
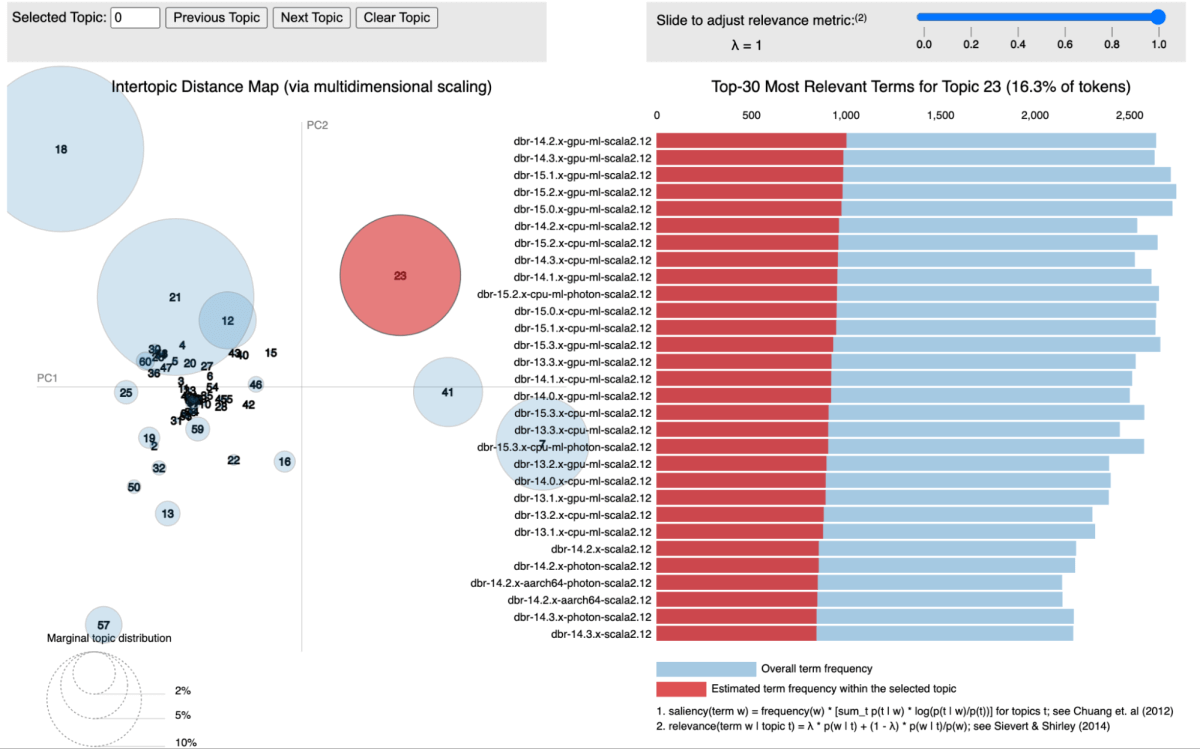
저희의 접근법에서는 토픽 모델링, 특히 잠재 디리클레 할당(LDA)을 사용하여 라이브러리를 연관된 서비스에 따라 클러스터링했습니다. 각 라이브러리는 문서로 취급되며, 그것이 나타나는 서비스는 해당 문서 내의 단어로 작용합니다. 이 방법을 통해 우리는 라이브러리를 효과적으로 공유 서비스 컨텍스트를 나타내는 주제로 그룹화할 수 있습니다.
아래 그림은 모든 Databricks Runtime (DBR) 서비스가 함께 클러스터링되어 pyLDAvis를 사용하여 시각화된 특정 주제를 보여줍니다.
각각의 식별된 주제에 대해, 우리는 그것이 우리 인프라 내에서의 중요성을 반영하는 점수를 부여합니다. 이 점수 부여는 우리가 관련 라이브러리의 주제 점수와 각 CVE를 연결함으로써 취약점을 더 정확하게 우선 순위로 정할 수 있게 합니다. 예를 들어, 라이브러리가 여러 중요한 서비스에 존재한다고 가정해 봅시다. 그 경우, 그 라이브러리에 대한 주제 점수는 더 높을 것이며, 따라서 그것에 영향을 미치는 CVE는 더 높은 우선 순위를 받게 될 것입니다.
영향과 결과
위에서 언급한 점수를 통합하기 위해 다양한 집계 기법을 사용했습니다. 우리의 모델은 CVE 데이터 3개월치를 사용하여 테스트를 거쳤고, 이 과정에서 우리 사업과 관련된 CVE를 약 85%의 높은 참 양성률로 식별하는 데 성공했습니다. 이 모델은 발표된 당일(day 0)에 중요한 취약점을 성공적으로 찾아냈으며, 보안 조사가 필요한 취약점을 강조하였습니다.
모델이 감지하지 못한 보안 팀이 수동으로 식별하거나 외부 소스에서 플래그된 취약점을 비교하여 모델이 생성한 거짓 부정을 측정했습니다. 이를 통해 우리는 놓친 중요한 취약점의 비율을 계산할 수 있었습니다. 뒤돌아보니, 테스트 데이터에는 거짓 음성이 없었습니다. 그러나, 이 영역에서 지속적인 모니터링과 평가의 필요성을 인식하고 있습니다.
우리 시스템은 효과적으로 우리의 작업 흐름을 간소화하였으며, 취약점 관리 과정을 더 효율적이고 집중된 보안 트리아지 단계로 변환하였습니다. 이는 직접 고객에게 영향을 미치는 CVE를 간과하는 위험을 크게 줄였으며, 수동 작업량을 95% 이상 줄였습니다. 이 효율성 향상은 우리의 보안 팀이 매일 발표되는 수백 개의 취약점을 걸러내는 대신, 선택된 몇 가지 취약점�에 집중할 수 있게 해주었습니다.
감사의 말씀
이 작업은 데이터 과학 팀과 제품 보안 팀간의 협업입니다. 제품 보안 팀의 Mrityunjay Gautam Aaron Kobayashi Anurag Srivastava 그리고 Ricardo Ungureanu, 보안 데이터 과학 팀의 Anirudh Kondaveeti Benjamin Ebanks Jeremy Stober 그리고 Chenda Zhang 에게 감사드립니다.

