Funktionale Arbeitsbereichsorganisation auf Databricks
Databricks Admin Essentials: Blog 1/5
von Anindita Mahapatra und Greg Wood
Einleitung
Dieser Blog ist Teil eins unserer Admin Essentials-Reihe, in der wir uns auf Themen konzentrieren, die für diejenigen wichtig sind, die Databricks-Umgebungen verwalten und pflegen. Halten Sie Ausschau nach weiteren Blogs zu Data Governance, Betrieb & Automatisierung, Benutzerverwaltung & Zugänglichkeit sowie Kostenverfolgung & -verwaltung in naher Zukunft!
Im Jahr 2020 begann Databricks mit der Veröffentlichung von privaten Vorschauen mehrerer Plattformfunktionen, die kollektiv als Enterprise 2.0 (oder E2) bekannt sind; diese Funktionen stellten die nächste Iteration der Lakehouse-Plattform dar und schufen die Skalierbarkeit und Sicherheit, die der bereits auf Databricks verfügbaren Leistung und Geschwindigkeit entsprechen. Als Enterprise 2.0 öffentlich verfügbar gemacht wurde, war eine der am meisten erwarteten Ergänzungen die Möglichkeit, mehrere Workspaces von einem einzigen Konto aus zu erstellen. Diese Funktion eröffnete neue Möglichkeiten für Zusammenarbeit, organisatorische Abstimmung und Vereinfachung. Wie wir seitdem festgestellt haben, hat sie jedoch auch eine Reihe von Fragen aufgeworfen. Basierend auf unserer Erfahrung mit Unternehmenskunden jeder Größe, Form und Branche wird dieser Blog Antworten und Best Practices für die häufigsten Fragen zur Workspace-Verwaltung innerhalb von Databricks darlegen; auf fundamentaler Ebene läuft dies auf eine einfache Frage hinaus: Wann genau sollte ein neuer Workspace erstellt werden? Insbesondere werden wir die wichtigsten Strategien für die Organisation Ihrer Workspaces und die Best Practices für jede einzelne hervorheben.
Grundlagen der Workspace-Organisation
Obwohl jeder Cloud-Anbieter (AWS, Azure und GCP) eine andere zugrunde liegende Architektur hat, ist die Organisation von Databricks-Workspaces über Clouds hinweg ähnlich. Die logische oberste Konstruktion ist ein E2-Masterkonto (AWS) oder ein Abonnementobjekt (Azure Databricks/GCP). In AWS stellen wir ein einziges E2-Konto pro Organisation bereit, das eine einheitliche Sicht und Kontrolle für alle Workspaces bietet. Auf diese Weise ist Ihre Admin-Aktivität zentralisiert, mit der Möglichkeit, SSO, Audit Logs und Unity Catalog zu aktivieren. Azure hat relativ weniger Einschränkungen bei der Erstellung von Top-Level-Abonnementobjekten; wir empfehlen jedoch dennoch, die Anzahl der Top-Level-Abonnements, die zur Erstellung von Databricks-Workspaces verwendet werden, so weit wie möglich zu kontrollieren. Wir werden die Top-Level-Konstruktion in diesem Blog als Konto bezeichnen, sei es ein AWS E2-Konto oder ein GCP/Azure-Abonnement.
Innerhalb eines Top-Level-Kontos können mehrere Workspaces erstellt werden. Die empfohlene maximale Anzahl von Workspaces pro Konto liegt bei Azure zwischen 20 und 50, mit einem Hard Limit bei AWS. Dieses Limit ergibt sich aus dem administrativen Aufwand, der durch eine wachsende Anzahl von Workspaces entsteht: Die Verwaltung von Zusammenarbeit, Zugriff und Sicherheit über Hunderte von Workspaces hinweg kann zu einer äußerst schwierigen Aufgabe werden, selbst mit außergewöhnlichen Automatisierungsprozessen. Nachfolgend präsentieren wir ein High-Level-Objektmodell eines Databricks-Kontos.
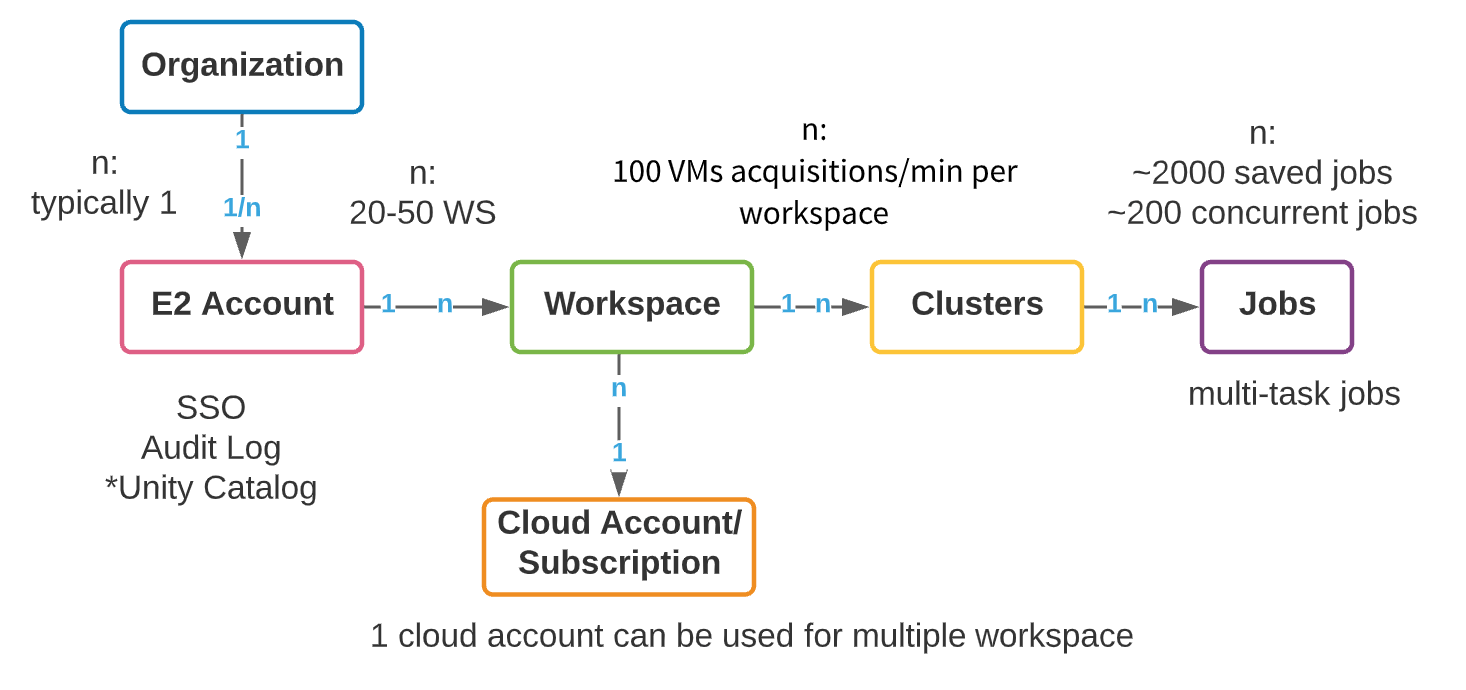
Unternehmen müssen Ressourcen in ihrem Cloud-Konto erstellen, um Multi-Tenancy-Anforderungen zu unterstützen. Die Erstellung separater Cloud-Konten und Workspaces für jeden neuen Anwendungsfall hat einige klare Vorteile: einfache Kostenverfolgung, Daten- und Benutzerisolation sowie ein geringeres Schadenspotenzial im Falle von Sicherheitsvorfällen. Die Kontenproliferation bringt jedoch ihre eigenen Komplexitäten mit sich – Governance, Metadatenverwaltung und Kollaborationsaufwand wachsen mit der Anzahl der Konten. Der Schlüssel liegt natürlich in der Balance. Im Folgenden gehen wir zunächst auf einige allgemeine Überlegungen zur Organisation von Enterprise-Workspaces ein; dann gehen wir auf zwei gängige Workspace-Isolationsstrategien ein, die wir bei unseren Kunden beobachten: LOB-basiert und produktbasiert. Jede hat Stärken, Schwächen und Komplexitäten, die wir diskutieren werden, bevor wir Best Practices geben.
Allgemeine Überlegungen zur Workspace-Organisation
Bei der Gestaltung Ihrer Workspace-Strategie springen Kunden oft zuerst zu den makro-leveligen Organisationsentscheidungen; es gibt jedoch viele Entscheidungen auf niedrigerer Ebene, die genauso wichtig sind! Wir haben die wichtigsten davon unten zusammengestellt.
Ein einfacher Drei-Workspace-Ansatz
Obwohl wir den Großteil dieses Blogs damit verbringen, darüber zu sprechen, wie Sie Ihre Workspaces für maximale Effektivität aufteilen können, gibt es eine ganze Klasse von Databricks-Kunden, für die ein einziger, einheitlicher Workspace pro Umgebung mehr als ausreichend ist! Tatsächlich ist dies mit dem Aufkommen von Funktionen wie Repos, Unity Catalog, persona-basierten Landing Pages usw. immer praktikabler geworden. In solchen Fällen empfehlen wir dennoch die Trennung von Entwicklungs-, Staging- und Produktions-Workspaces für Validierungs- und QA-Zwecke. Dies schafft eine ideale Umgebung für kleine Unternehmen oder Teams, die Agilität gegenüber Komplexität bevorzugen.
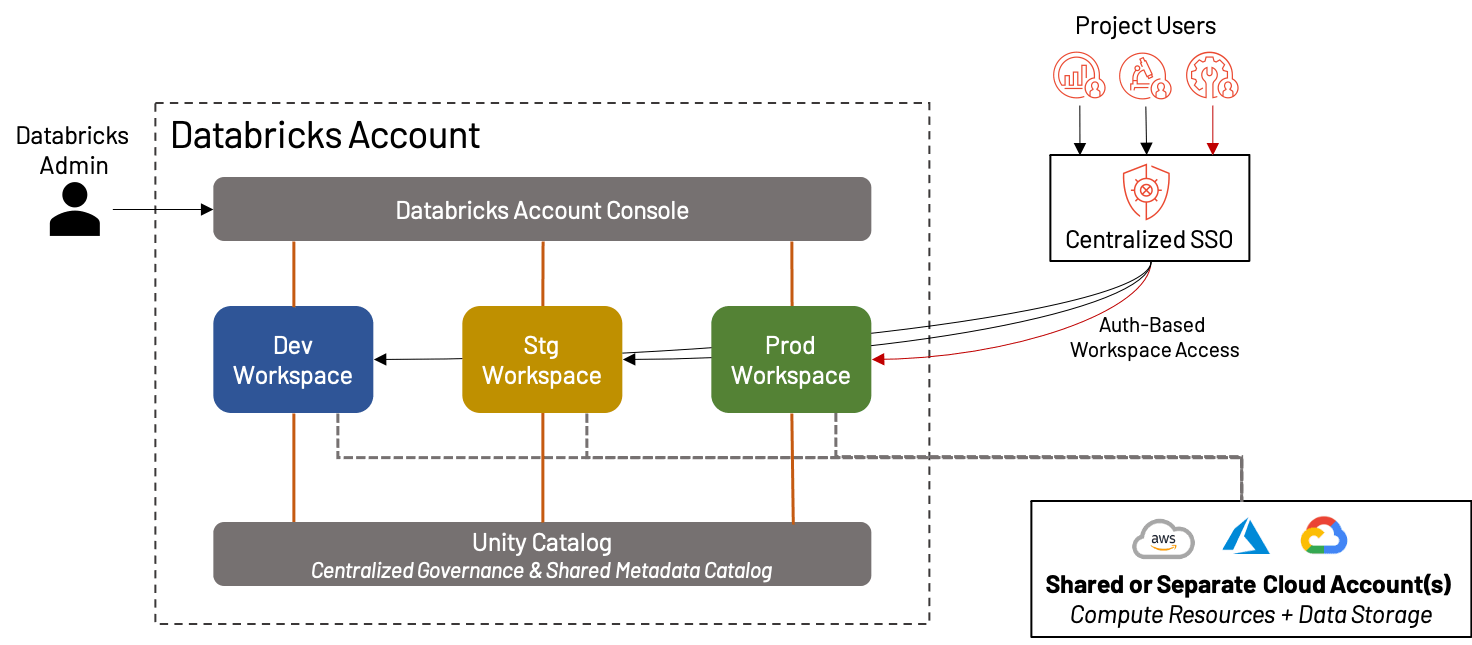
Die Vorteile und Nachteile der Erstellung eines einzigen Satzes von Workspaces sind:
+ Es gibt keine Bedenken, den Workspace intern zu überladen, Assets zu mischen oder Kosten/Nutzung über mehrere Projekte/Teams zu verteilen; alles befindet sich in derselben Umgebung
+ Die Einfachheit der Organisation bedeutet reduzierten administrativen Aufwand
- Für größere Organisationen ist ein einziger Dev/Stg/Prod-Workspace aufgrund von Plattformlimits, Überladung, mangelnder Datenisolation und Governance-Bedenken nicht praktikabel
Wenn ein einziger Satz von Workspaces der richtige Ansatz für Sie zu sein scheint, helfen Ihnen die folgenden Best Practices, Ihr Lakehouse reibungslos zu betreiben:
- Definieren Sie einen standardisierten Prozess für die Übertragung von Code zwischen den verschiedenen Umgebungen; da es nur einen Satz von Umgebungen gibt, kann dies einfacher sein als bei anderen Ansätzen. Nutzen Sie Funktionen wie Repos und Secrets sowie externe Tools, die gute CI/CD-Prozesse fördern, um sicherzustellen, dass Ihre Übergänge automatisch und reibungslos erfolgen.
- Richten Sie Identity Provider-Gruppen ein und überprüfen Sie diese regelmäßig, die auf Databricks-Assets abgebildet sind; da diese Gruppen der primäre Treiber für die Benutzerautorisierung in dieser Strategie sind, ist es entscheidend, dass sie korrekt sind und den entsprechenden zugrunde liegenden Daten- und Compute-Ressourcen zugeordnet sind. Zum Beispiel benötigen die meisten Benutzer wahrscheinlich keinen Zugriff auf den Produktions-Workspace; nur eine kleine Handvoll von Ingenieuren oder Administratoren hat möglicherweise die Berechtigungen.
- Behalten Sie Ihre Nutzung im Auge und kennen Sie die Databricks Ressourcengrenzen. Wenn Ihre Workspace-Nutzung oder Benutzeranzahl zu wachsen beginnt, müssen Sie möglicherweise eine umfassendere Strategie zur Organisation von Workspaces in Betracht ziehen, um die grenzen pro Workspace zu vermeiden. Nutzen Sie Ressourcen-Tagging, wo immer möglich, um Kosten und Nutzungsmetriken zu verfolgen.
Sandbox-Workspaces nutzen
Bei jeder der in diesem Artikel erwähnten Strategien ist eine Sandbox-Umgebung eine gute Praxis, um Benutzern die Möglichkeit zu geben, weniger formelle, aber dennoch potenziell wertvolle Arbeiten zu entwickeln und auszubauen. Entscheidend ist, dass diese Sandbox-Umgebungen die Freiheit, reale Daten zu erkunden, mit dem Schutz vor unbeabsichtigten (oder beabsichtigten) Auswirkungen auf Produktions-Workloads in Einklang bringen. Eine gängige Best Practice für solche Workspaces ist die Unterbringung in einem völlig separaten Cloud-Konto; dies begrenzt den potenziellen Schaden durch Benutzer im Workspace erheblich. Gleichzeitig bedeutet die Einrichtung einfacher Leitplanken (wie z. B. Cluster-Richtlinien, die Beschränkung des Datenzugriffs auf „Spiel“- oder bereinigte Datensätze und die Schließung der ausgehenden Konnektivität, wo immer möglich), dass Benutzer relative Freiheit haben, (fast) alles zu tun, was sie wollen, ohne ständige Administratoraufsicht. Schließlich ist die interne Kommunikation ebenso wichtig; wenn Benutzer unwissentlich eine erstaunliche Anwendung in der Sandbox erstellen, die Tausende von Benutzern anzieht, oder Produktionsunterstützung für ihre Arbeit in dieser Umgebung erwarten, werden diese administrativen Einsparungen schnell schwinden.
Zu den Best Practices für Sandbox-Workspaces gehören:
- Verwenden Sie ein separates Cloud-Konto, das keine sensiblen oder Produktionsdaten enthält.
- Richten Sie einfache Leitplanken ein, damit Benutzer relative Freiheit über die Umgebung haben, ohne Admin-Überwachung zu benötigen.
- Kommunizieren Sie klar, dass die Sandbox-Umgebung „Self-Service“ ist.
Datenisolation & Sensibilität
Sensible Daten gewinnen bei unseren Kunden in allen Branchen zunehmend an Bedeutung. Daten, die einst auf Gesundheitsdienstleister oder Kreditkartenverarbeiter beschränkt waren, werden nun zur Grundlage für die Analyse von Kundensentimenten, die Analyse aufstrebender Märkte, die Positionierung neuer Produkte und fast alles andere, was Sie sich vorstellen können. Dieser Datenreichtum birgt hohe Risiken, mit ständig wachsenden Bedrohungen durch Datenpannen. Aus diesem Grund ist die Trennung und der Schutz sensibler Daten wichtig, unabhängig von der gewählten Organisationsstrategie. Databricks bietet verschiedene Möglichkeiten, sensible Daten zu schützen (wie ACLs und sicheres Teilen), und in Kombination mit den Tools des Cloud-Anbieters kann der Lakehouse, den Sie aufbauen, so risikoarm wie möglich gestaltet werden. Einige der Best Practices für Datenisolation & Sensibilität sind:
- Verstehen Sie Ihre individuellen Datensicherheitsanforderungen; dies ist der wichtigste Punkt. Jedes Unternehmen hat unterschiedliche Daten, und Ihre Daten bestimmen Ihre Governance.
- Wenden Sie Richtlinien und Kontrollen sowohl auf der Speicherebene als auch auf dem Metastore an. S3-Richtlinien und ADLS-ACLs sollten immer nach dem Prinzip der geringsten Rechte angewendet werden. Nutzen Sie Unity Catalog, um eine zusätzliche Kontrolle über den Datenzugriff zu ermöglichen.
- Trennen Sie Ihre sensiblen Daten von nicht-sensiblen Daten sowohl logisch als auch physisch; viele Kunden verwenden völlig getrennte Cloud-Konten (und Databricks-Workspaces) für sensible und nicht-sensible Daten.
DR und regionale Sicherung
Disaster Recovery (DR) ist ein breites Thema, das wichtig ist, unabhängig davon, ob Sie AWS, Azure oder GCP verwenden. Wir werden nicht alles in diesem Blog behandeln, sondern uns darauf konzentrieren, wie DR und regionale Überlegungen in das Workspace-Design einfließen. In diesem Zusammenhang impliziert DR die Erstellung und Wartung eines Workspaces in einer separaten Region vom Standard-Produktions-Workspace.
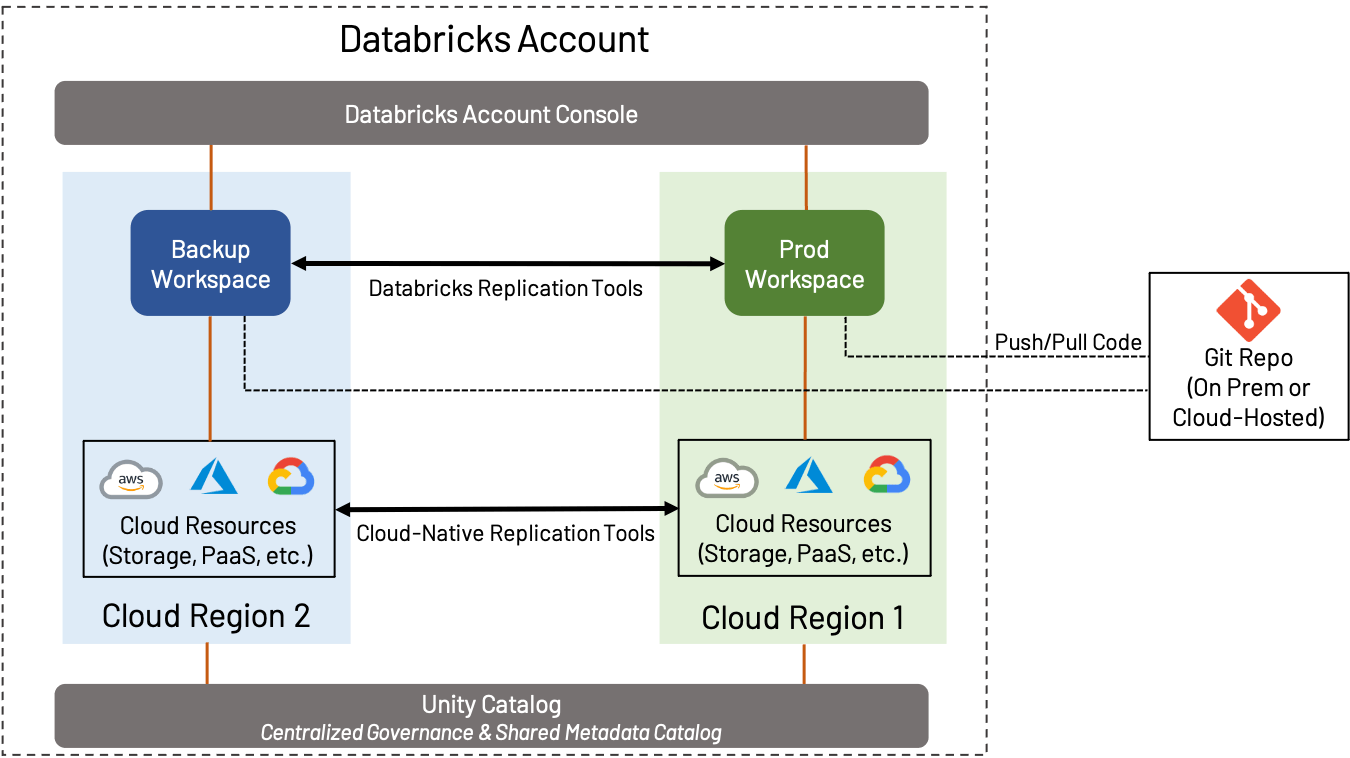
DR-Strategien können stark variieren, abhängig von den Bedürfnissen des Unternehmens. Zum Beispiel bevorzugen einige Kunden die Aufrechterhaltung einer Active-Active-Konfiguration, bei der alle Assets von einem Workspace ständig in einen sekundären Workspace repliziert werden; dies bietet ein Höchstmaß an Redundanz, impliziert aber auch Komplexität und Kosten (ständige Datenübertragung über Regionen hinweg und Durchführung von Objektreplikation und Deduplizierung ist ein komplizierter Prozess). Auf der anderen Seite bevorzugen einige Kunden, das Nötigste zu tun, um die Geschäftskontinuität zu gewährleisten; ein sekundärer Workspace kann sehr wenig enthalten, bis ein Failover auftritt, oder nur gelegentlich gesichert werden. Die Bestimmung des richtigen Failover-Levels ist entscheidend.
Unabhängig davon, welches DR-Level Sie implementieren, empfehlen wir Folgendes:
- Speichern Sie Code in einem Git-Repository Ihrer Wahl, entweder On-Premises oder in der Cloud, und nutzen Sie Funktionen wie Repos, um ihn nach Möglichkeit mit Databricks zu synchronisieren.
- Verwenden Sie nach Möglichkeit Delta Lake in Verbindung mit Deep Clone, um Daten zu replizieren; dies bietet eine einfache, Open-Source-Möglichkeit, Daten effizient zu sichern.
- Verwenden Sie die Cloud-nativen Tools Ihres Cloud-Anbieters, um Sicherungen von Dingen wie Daten, die nicht in Delta Lake gespeichert sind, externen Datenbanken, Konfigurationen usw. durchzuführen.
- Verwenden Sie Tools wie Terraform, um Objekte wie Notebooks, Jobs, Geheimnisse, Cluster und andere Workspace-Objekte zu sichern.
Denken Sie daran: Databricks ist für die Wartung der regionalen Workspace-Infrastruktur in der Control Plane verantwortlich, aber Sie sind für Ihre Workspace-spezifischen Assets sowie die Cloud-Infrastruktur verantwortlich, auf die Ihre Produktionsjobs angewiesen sind.
Isolation nach Geschäftsbereich (LOB)
Nun tauchen wir in die tatsächliche Organisation von Workspaces im Unternehmenskontext ein. Die Isolation von Projekten nach Geschäftsbereichen (LOB) ergibt sich aus der traditionellen, unternehmenszentrierten Betrachtung von IT-Ressourcen – sie birgt auch viele traditionelle Stärken (und Schwächen) der LOB-zentrierten Ausrichtung. Daher wird dieser Ansatz der Workspace-Verwaltung für viele große Unternehmen natürlich kommen.
In einer LOB-basierten Workspace-Strategie erhält jede funktionale Einheit eines Unternehmens eine Reihe von Workspaces; traditionell umfasst dies Entwicklungs-, Staging- und Produktions-Workspaces, obwohl wir Kunden mit bis zu 10 Zwischenstufen gesehen haben, die jeweils potenziell ihren eigenen Workspace haben (nicht empfohlen)! Code wird in DEV geschrieben und getestet, dann (via CI/CD-Automatisierung) nach STG befördert und landet schließlich in PRD, wo er als geplanter Job läuft, bis er veraltet ist. Der Umgebungs-Typ und der unabhängige LOB sind die Hauptgründe, einen neuen Workspace in diesem Modell zu initiieren; dies für jeden Anwendungsfall oder jedes Datenprodukt zu tun, kann übertrieben sein.
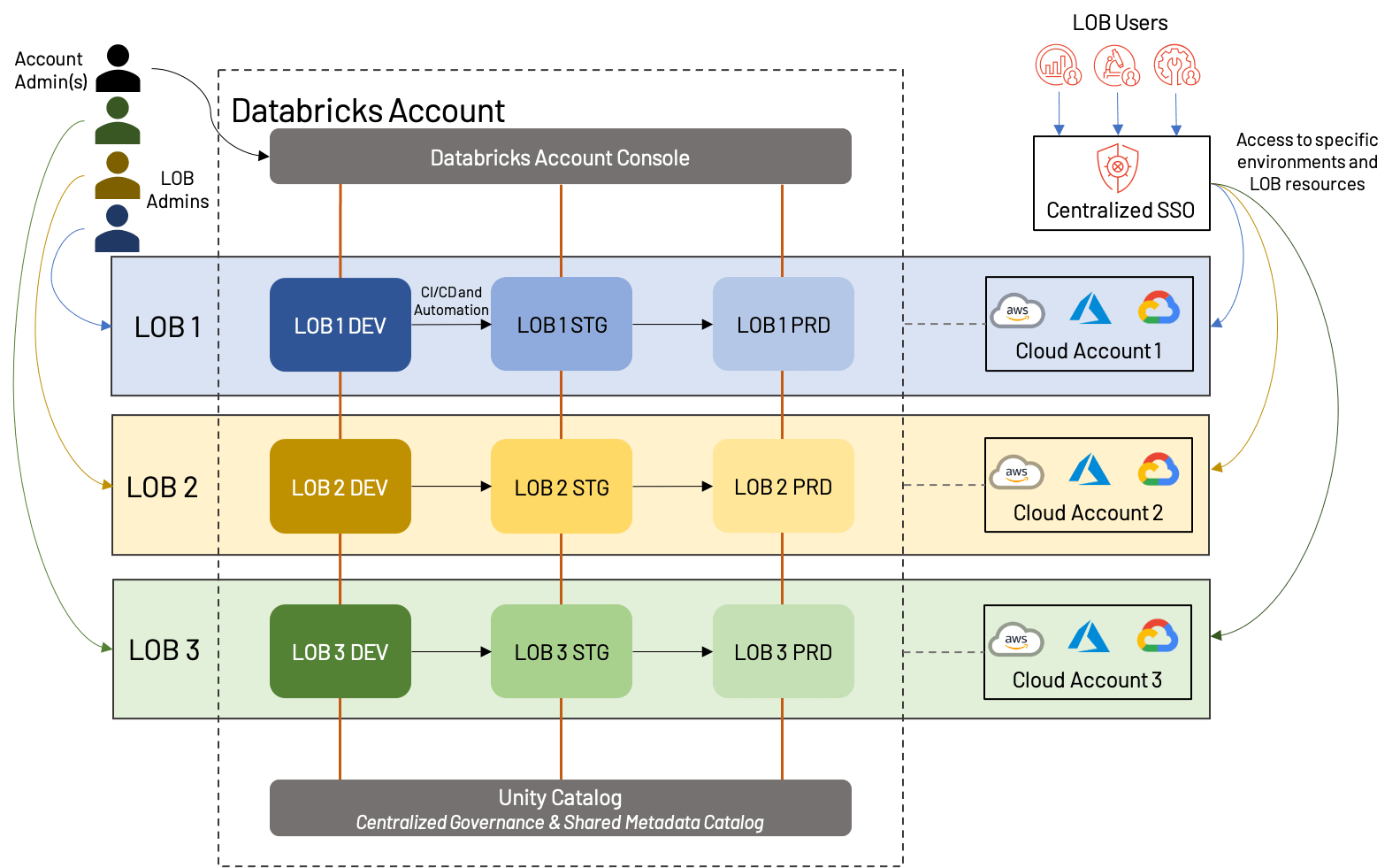
Das obige Diagramm zeigt eine mögliche Struktur für LOB-basierte Workspaces; in diesem Fall hat jeder LOB ein separates Cloud-Konto mit einem Workspace in jeder Umgebung (dev/stg/prd) und auch einen dedizierten Administrator. Wichtig ist, dass all diese Workspaces unter demselben Databricks-Konto fallen und dasselbe Unity Catalog nutzen. Einige Variationen würden das Teilen von Cloud-Konten (und potenziell zugrunde liegenden Ressourcen wie VPCs und Cloud-Diensten), die Verwendung eines separaten Dev/Stg/Prd-Cloud-Kontos oder die Erstellung separater externer Metastore für jeden LOB umfassen. Dies sind alles vernünftige Ansätze, die stark von den Geschäftsanforderungen abhängen.
Insgesamt gibt es eine Reihe von Vorteilen sowie einige Nachteile des LOB-Ansatzes:
+Assets für jede LOB können isoliert werden, sowohl aus Cloud-Sicht als auch aus Workspace-Sicht; dies ermöglicht eine einfache Berichterstellung/Kostenanalyse sowie einen übersichtlicheren Workspace.
+Klare Trennung von Benutzern und Rollen verbessert die Gesamtverwaltung des Lakehouse und reduziert das Gesamtrisiko.
+Automatisierung der Promotion zwischen Umgebungen schafft einen effizienten Prozess mit geringem Overhead.
-Eine Vorausplanung ist erforderlich, um sicherzustellen, dass LOB-übergreifende Prozesse standardisiert sind und das gesamte Databricks-Konto keine Plattformlimits erreicht.
-Automatisierung und administrative Prozesse erfordern Spezialisten für Einrichtung und Wartung.
Als Best Practices empfehlen wir den folgenden Personen, die LOB-basierte Lakehouses erstellen:
- Verwenden Sie ein Modell mit minimalen Berechtigungen (Least Privilege) mit feingranularer Zugriffskontrolle für Benutzer und Umgebungen; im Allgemeinen sollten nur sehr wenige Benutzer Produktionszugriff haben, und Interaktionen mit dieser Umgebung sollten automatisiert und streng kontrolliert werden. Erfassen Sie diese Benutzer und Gruppen in Ihrem Identitätsanbieter und synchronisieren Sie sie mit dem Lakehouse.
- Verstehen und planen Sie sowohl die Limits des Cloud-Anbieters als auch die Databricks-Plattform; dazu gehören beispielsweise die Anzahl der Workspaces, API-Ratenbegrenzungen für ADLS, Drosselung von Kinesis-Streams usw.
- Verwenden Sie nach Möglichkeit einen standardisierten Metastore/Katalog mit strengen Zugriffskontrollen; dies ermöglicht die Wiederverwendung von Assets, ohne die Isolation zu beeinträchtigen. Unity Catalog ermöglicht feingranulare Kontrollen über Tabellen und Workspace-Assets, einschließlich Objekten wie MLflow-Experimenten.
- Nutzen Sie Data Sharing, wo immer möglich, um Daten sicher zwischen LOBs zu teilen, ohne Anstrengungen zu duplizieren.
Datenproduktisolation
Was tun wir, wenn LOBs funktionsübergreifend zusammenarbeiten müssen oder wenn ein einfaches Dev/Stg/Prd-Modell nicht zu den Anwendungsfällen unserer LOB passt? Wir können etwas von der Formalität einer strengen LOB-basierten Lakehouse-Struktur ablegen und einen etwas moderneren Ansatz verfolgen; wir nennen dies Workspace-Isolation nach Datenprodukt. Das Konzept besteht darin, dass wir anstatt streng nach LOB zu isolieren, stattdessen nach übergeordneten Projekten isolieren und jedem eine Produktionsumgebung geben. Wir mischen auch gemeinsam genutzte Entwicklungsumgebungen ein, um die Verbreitung von Workspaces zu vermeiden und die Wiederverwendung von Assets zu vereinfachen.
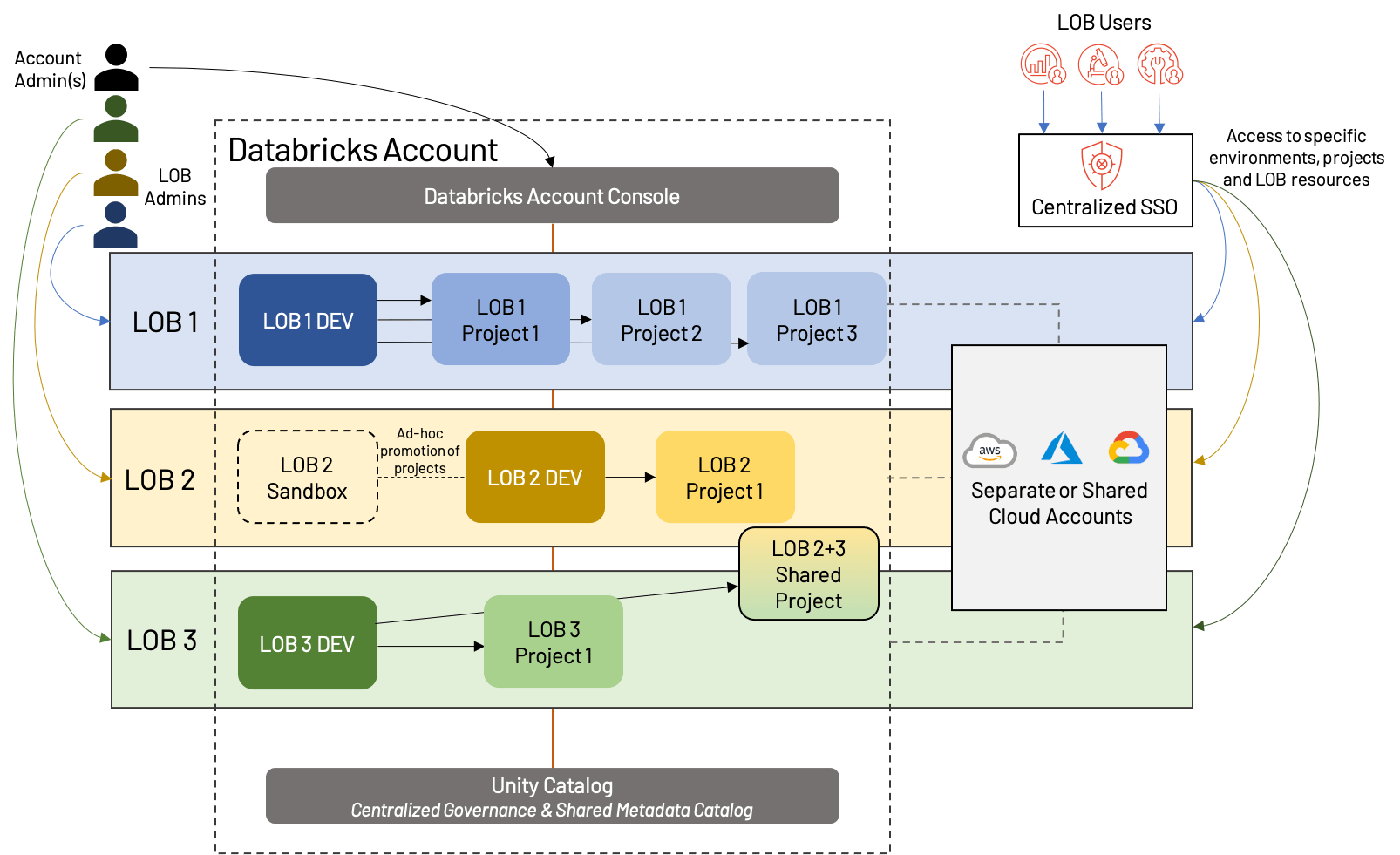
Auf den ersten Blick sieht dies ähnlich aus wie die LOB-basierte Isolation von oben, aber es gibt einige wichtige Unterschiede:
- Ein gemeinsam genutzter Dev-Workspace mit separaten Workspaces für jedes übergeordnete Projekt (was bedeutet, dass jede LOB insgesamt eine unterschiedliche Anzahl von Workspaces haben kann)
- Das Vorhandensein von Sandbox-Workspaces, die spezifisch für eine LOB sind und mehr Freiheit und weniger Automatisierung bieten als herkömmliche Dev-Workspaces
- Gemeinsame Nutzung von Ressourcen und/oder Workspaces; dies ist auch in LOB-basierten Architekturen möglich, wird aber oft durch eine strengere Trennung erschwert
Dieser Ansatz teilt viele der gleichen Stärken und Schwächen wie die LOB-basierte Isolation, bietet aber mehr Flexibilität und betont den Wert von Projekten im modernen Lakehouse. Immer mehr sehen wir dies als den „Goldstandard“ für die Workspace-Organisation, was mit der Verlagerung von Technologie von einem reinen Kostentreiber zu einem Wertschöpfer übereinstimmt. Wie immer können geschäftliche Anforderungen leichte Abweichungen von dieser Beispielarchitektur bedingen, wie z. B. dedizierte Dev/Stg/Prd für besonders große Projekte, LOB-übergreifende Projekte, mehr oder weniger Trennung von Cloud-Ressourcen usw. Unabhängig von der genauen Struktur empfehlen wir die folgenden Best Practices:
- Teilen Sie Daten und Ressourcen, wann immer möglich; obwohl die Trennung von Infrastruktur und Workspaces für Governance und Nachverfolgung nützlich ist, wird die Verbreitung von Ressourcen schnell zu einer Belastung. Eine sorgfältige Analyse im Voraus hilft, Bereiche für die Wiederverwendung zu identifizieren.
- Auch wenn nicht umfassend zwischen Projekten geteilt wird, verwenden Sie nach Möglichkeit einen gemeinsamen Metastore wie Unity Catalog und gemeinsame Codebasen (z. B. über Repos).
- Verwenden Sie Terraform (oder ähnliche Tools), um den Prozess der Erstellung, Verwaltung und Löschung von Workspaces und Cloud-Infrastruktur zu automatisieren.
- Bieten Sie Benutzern Flexibilität durch Sandbox-Umgebungen, stellen Sie jedoch sicher, dass diese über geeignete Leitplanken verfügen, um Clustergrößen, Datenzugriff usw. zu begrenzen.
Zusammenfassung
Um alle Vorteile des Lakehouse voll auszuschöpfen und zukünftiges Wachstum und Verwaltbarkeit zu unterstützen, sollte bei der Planung des Workspace-Layouts sorgfältig vorgegangen werden. Weitere zu berücksichtigende zugehörige Artefakte sind ein zentrales Model Registry, Codebasis und Katalog, um die Zusammenarbeit zu erleichtern, ohne die Sicherheit zu beeinträchtigen. Um einige der in diesem Artikel hervorgehobenen Best Practices zusammenzufassen, sind hier unsere wichtigsten Erkenntnisse aufgeführt:
Best Practice #1: Minimieren Sie die Anzahl der Top-Level-Konten (sowohl auf der Ebene des Cloud-Anbieters als auch auf Databricks-Ebene), wo immer möglich, und erstellen Sie einen Workspace nur dann, wenn eine Trennung aus Compliance-, Isolations- oder geografischen Gründen erforderlich ist. Im Zweifelsfall halten Sie es einfach!
Best Practice #2: Entscheiden Sie sich für eine Isolationsstrategie, die Ihnen langfristige Flexibilität ohne unnötige Komplexität bietet. Seien Sie realistisch in Bezug auf Ihre Bedürfnisse und implementieren Sie strenge Richtlinien, bevor Sie Workloads in Ihr Lakehouse aufnehmen. Mit anderen Worten: Zweimal messen, einmal schneiden!
Best Practice #3: Automatisieren Sie Ihre Cloud-Prozesse. Dies umfasst jeden Aspekt Ihrer Infrastruktur (von denen viele in folgenden Blogs behandelt werden!), einschließlich SSO/SCIM, Infrastructure-as-Code mit einem Tool wie Terraform, CI/CD-Pipelines und Repos, Cloud-Backup und Überwachung (mit Cloud-nativen und Drittanbieter-Tools).
Best Practice #4: Erwägen Sie die Einrichtung eines COE-Teams (Center of Excellence) für die zentrale Steuerung einer unternehmensweiten Strategie, bei der wiederholbare Aspekte einer Daten- und Machine-Learning-Pipeline als Vorlagen erstellt und automatisiert werden, sodass verschiedene Datenteams Self-Service-Funktionen mit ausreichenden Leitplanken nutzen können. Das COE-Team ist oft eine schlanke, aber kritische Drehscheibe für Datenteams und sollte sich selbst als Ermöglicher betrachten, der Dokumentation, SOPs, Anleitungen und FAQs pflegt, um andere Benutzer zu schulen.
Best Practice #5: Das Lakehouse bietet ein Maß an Governance, das der Data Lake nicht bietet; nutzen Sie dies! Bewerten Sie Ihre Compliance- und Governance-Anforderungen als einer der ersten Schritte bei der Einrichtung Ihres Lakehouse und nutzen Sie die von Databricks bereitgestellten Funktionen, um sicherzustellen, dass das Risiko minimiert wird. Dazu gehören die Bereitstellung von Audit-Logs, HIPAA und PCI (wo zutreffend), ordnungsgemäße Exfiltrationskontrollen, die Verwendung von ACLs und Benutzerkontrollen sowie die regelmäßige Überprüfung all dessen.
Wir werden in naher Zukunft weitere Blogs zu Admin Best Practices veröffentlichen, zu Themen von Data Governance bis hin zu Benutzerverwaltung. Wenden Sie sich in der Zwischenzeit an Ihr Databricks-Account-Team, wenn Sie Fragen zur Workspace-Verwaltung haben oder mehr über Best Practices auf der Databricks Lakehouse Platform erfahren möchten!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.