Entwickelt für offenen, intelligenten Datenspeicher
Wählen Sie Speicherort und -format selbst bei voller Kontrolle und Portabilität Ihrer Daten.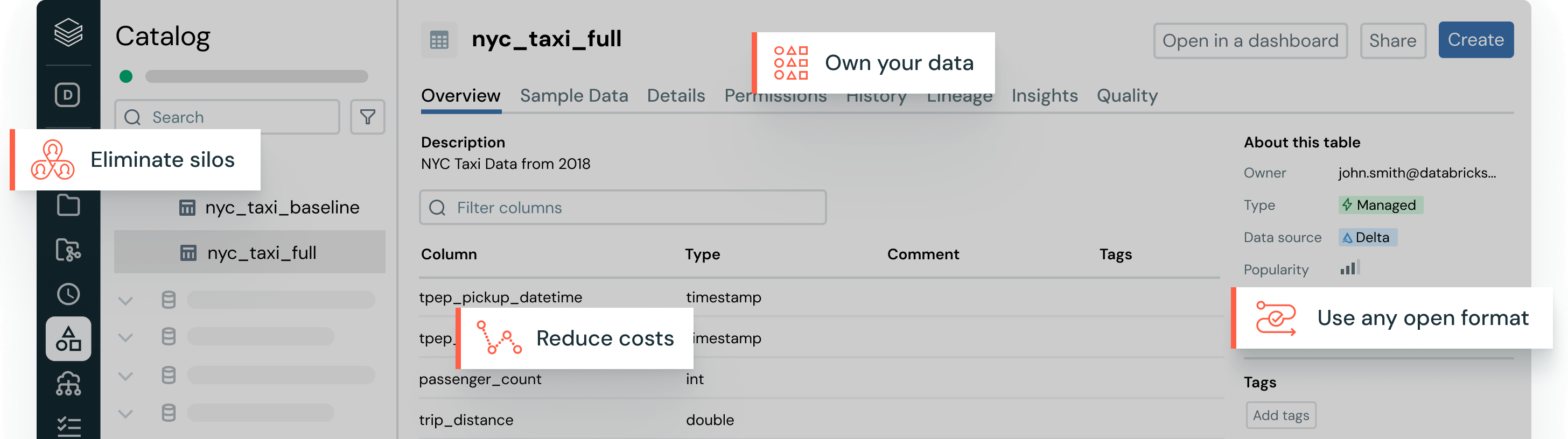
ERFOLGREICHE TEAMS NUTZEN DATA INTELLIGENCE
Lakehouse-Speicher, der flexibel und schnell ist
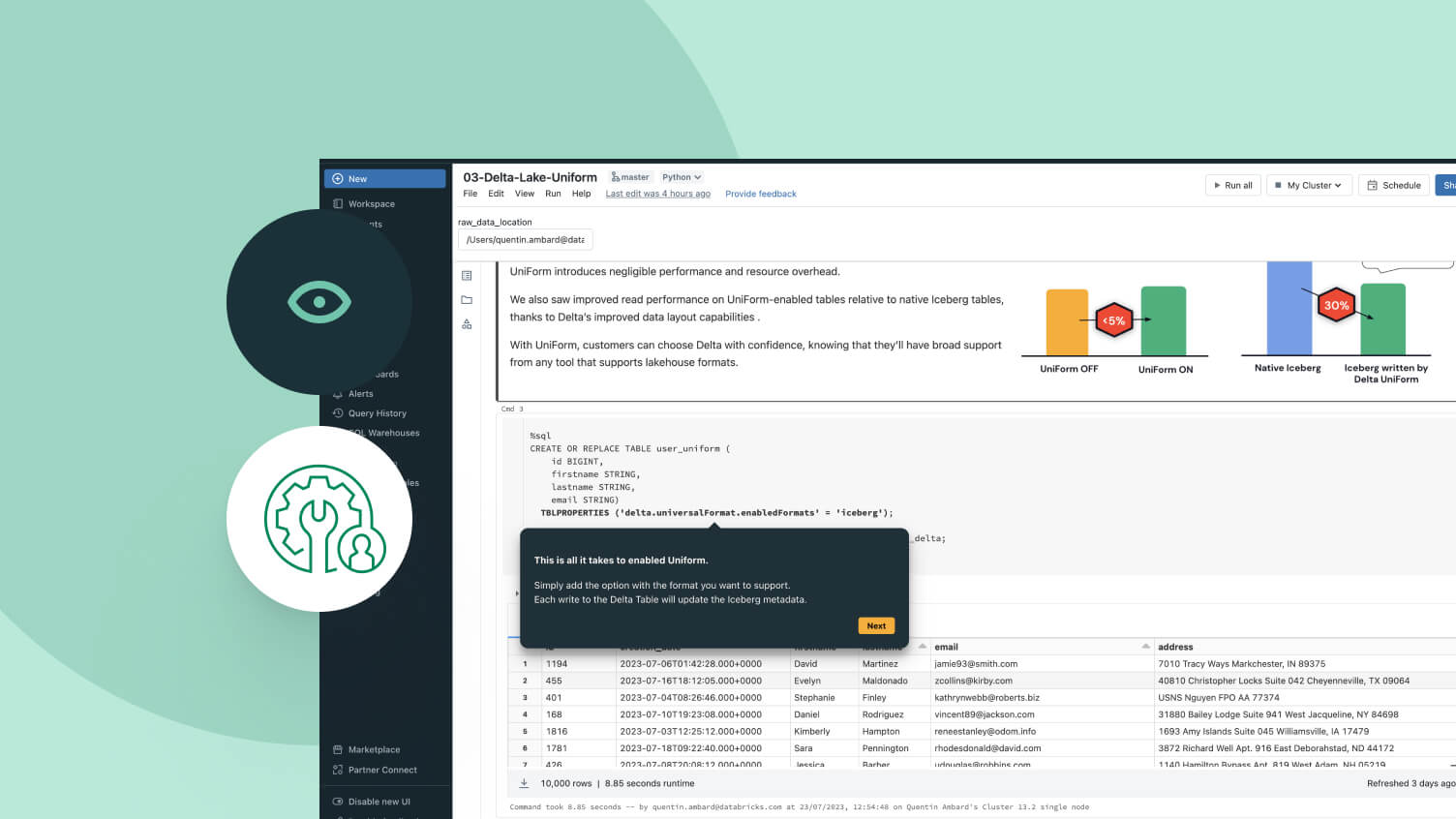
Beseitigen Sie Datenmanagement-Probleme mit offenen Tabellenformaten, zentralisierter Governance und automatischen Datenoptimierungen.Kompatible Formate
Eine einzelne Kopie der Quelldaten in Delta Lake oder Apache Iceberg™, auf die jeder Motor zugreifen kann.
Einheitliche Governance
Ein einziger Katalog für die Datenentdeckung und -steuerung, über alle Ihre Daten- und KI-Ressourcen hinweg.
KI-gestützte Leistung
KI-gesteuerte Modelle optimieren und pflegen Daten autonom für Geschwindigkeit und niedrige Kosten.
Ihre Daten, auf Ihre Weise
Wählen Sie den Speicherort und das offene Format, das für Sie funktioniert. Halten Sie Ihre Daten portabel, ohne Anbieterbindung.Best-in-Class-Lese- und Schreibperformance für Delta Lake und Apache Iceberg™-Tabellen, direkt aus der Box, mit Speicheroptimierungen, die in keinem anderen Lakehouse verfügbar sind.
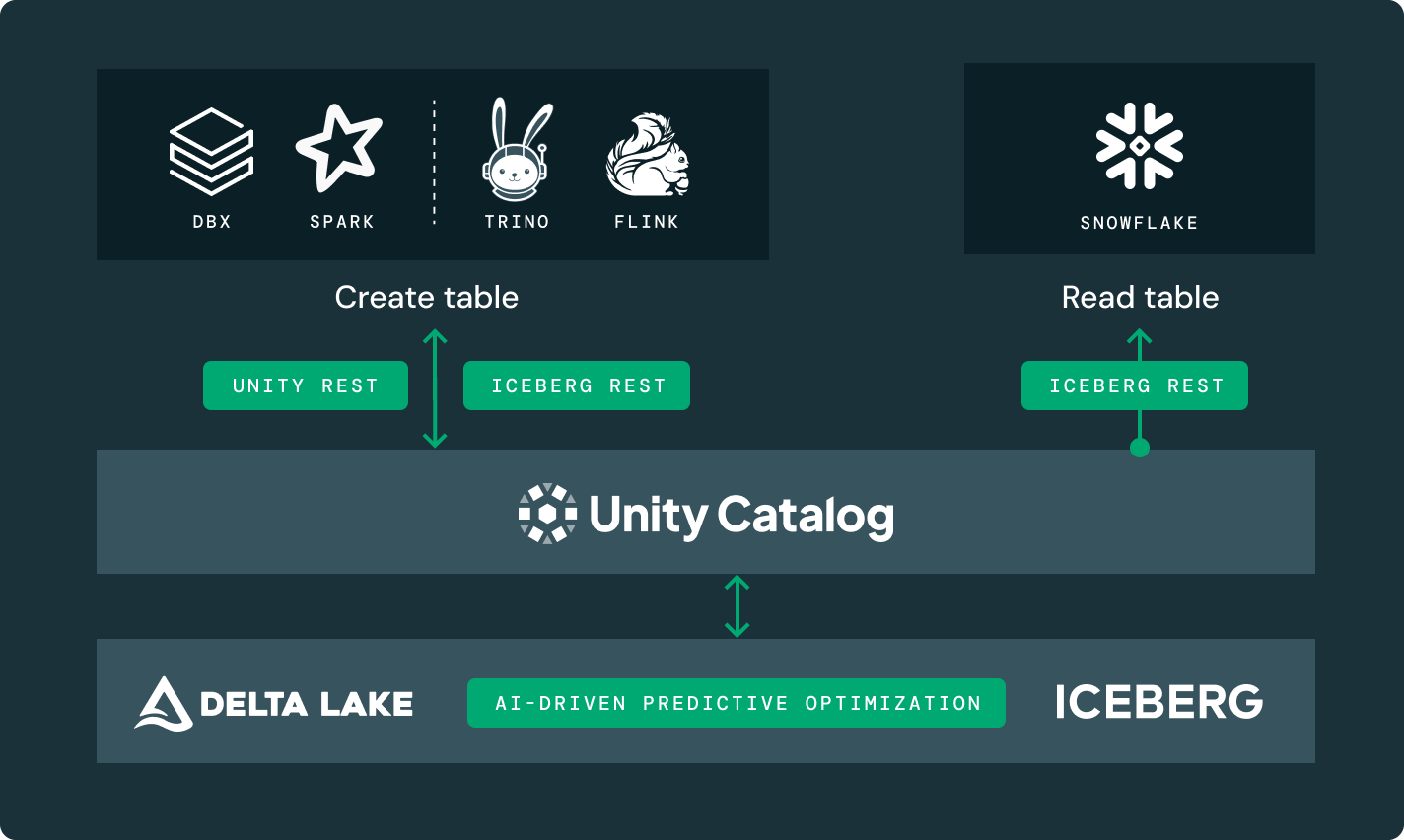
Zugriff auf Tabellen, die von externen Katalogen wie Glue, HMS und Snowflake Horizon verwaltet werden und nutzen Sie erweiterte Unity-Katalogfunktionen wie feingranulare Zugriffskontrollen.
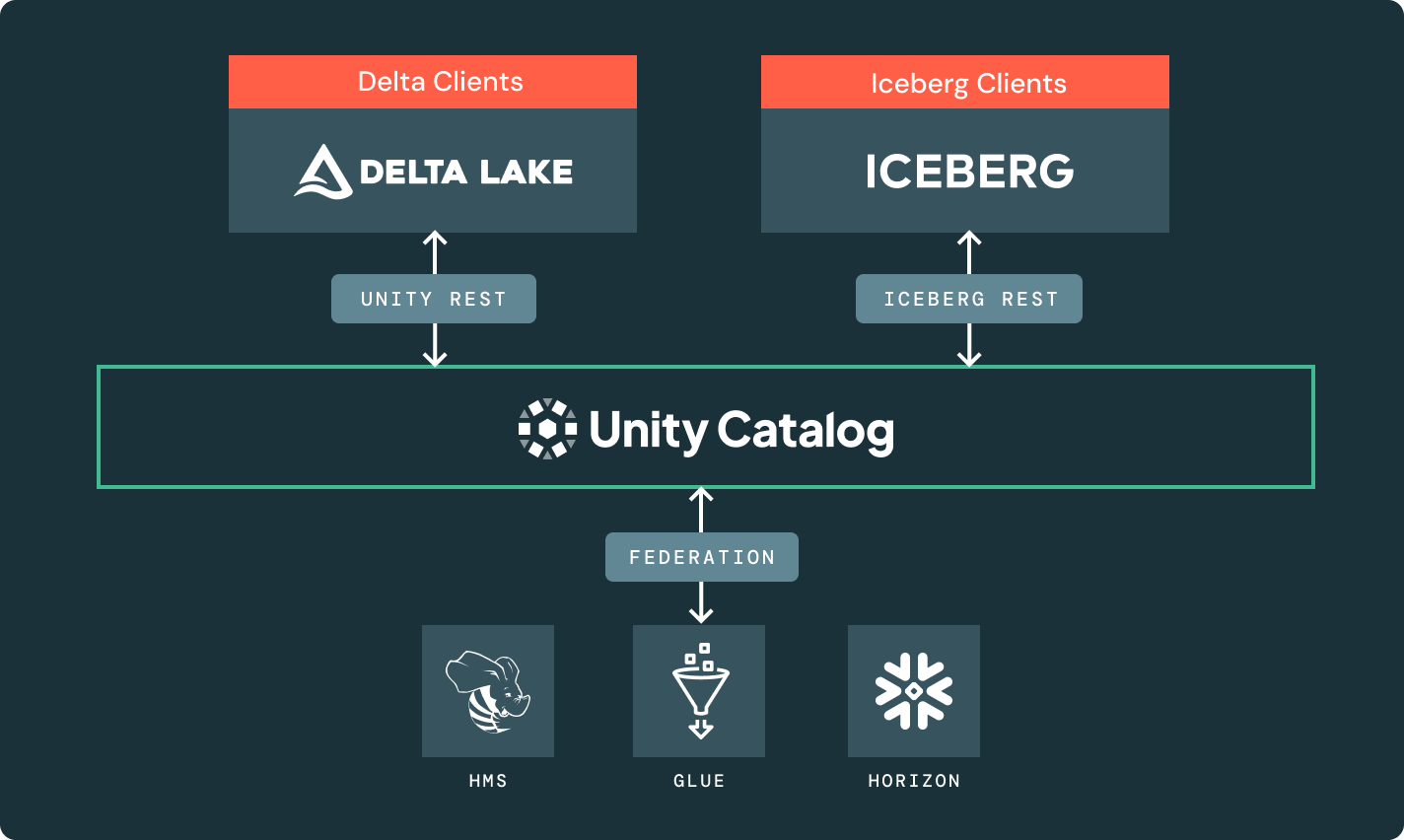
Die Unity REST- und Iceberg REST-Katalog-APIs erschließen das gesamte Lakehouse-Ökosystem, über Formate und Engines hinweg.
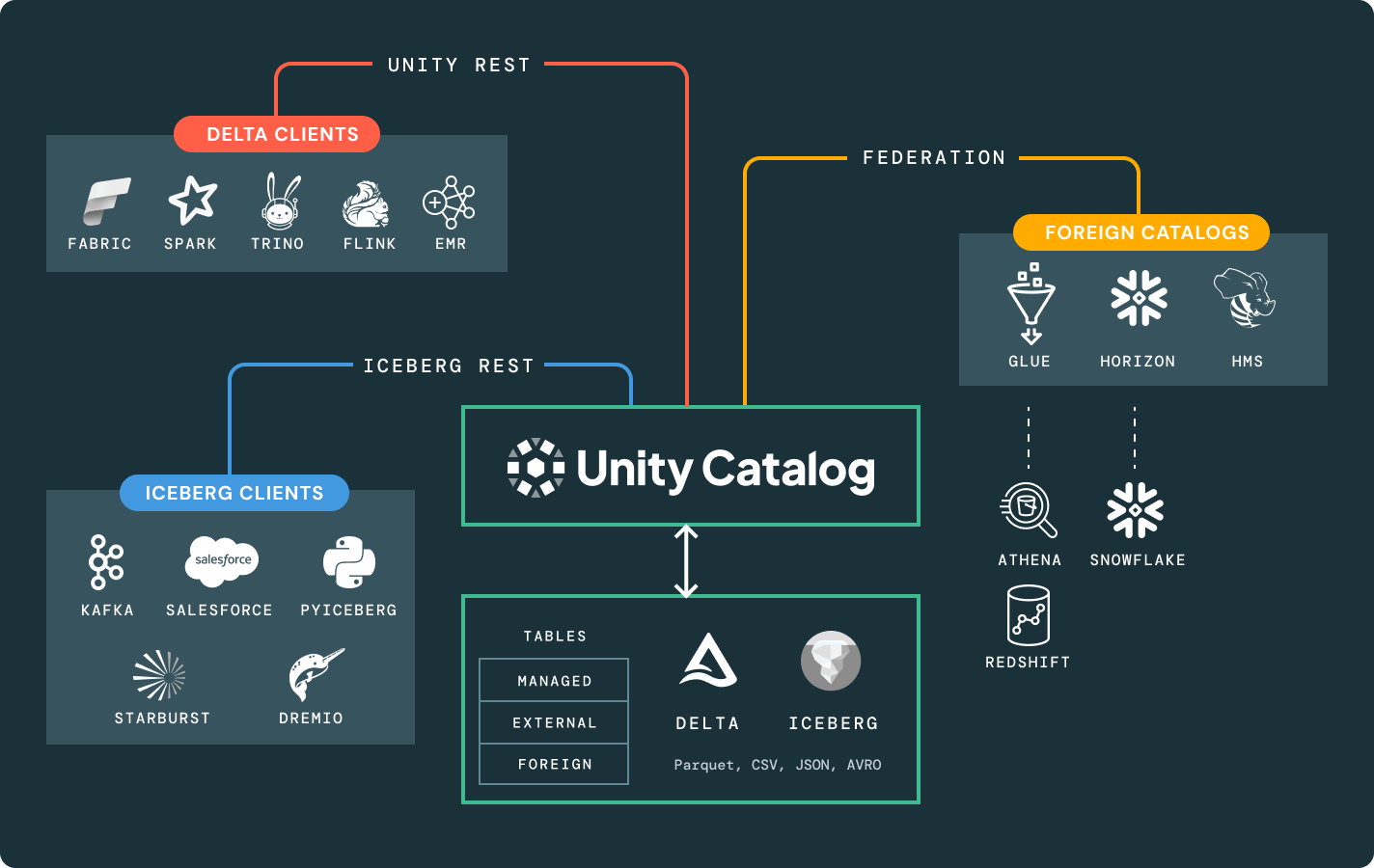
Weitere Funktionen
Für alle Ihre Analyse- und KI-Workloads

Erstellen und verwalten Sie zuverlässige Datenpipelines
Verwaltete Tabellen fungieren sowohl als Batch-Tabellen als auch als Streaming-Quelle und -Senke. Ob Erfassung von Streaming-Daten, zeitlich versetzter Batch-Abgleich oder interaktive Abfragen: Alles funktioniert von Anfang an erwartungsgemäß und mit direkter Integration in Spark Structured Streaming.
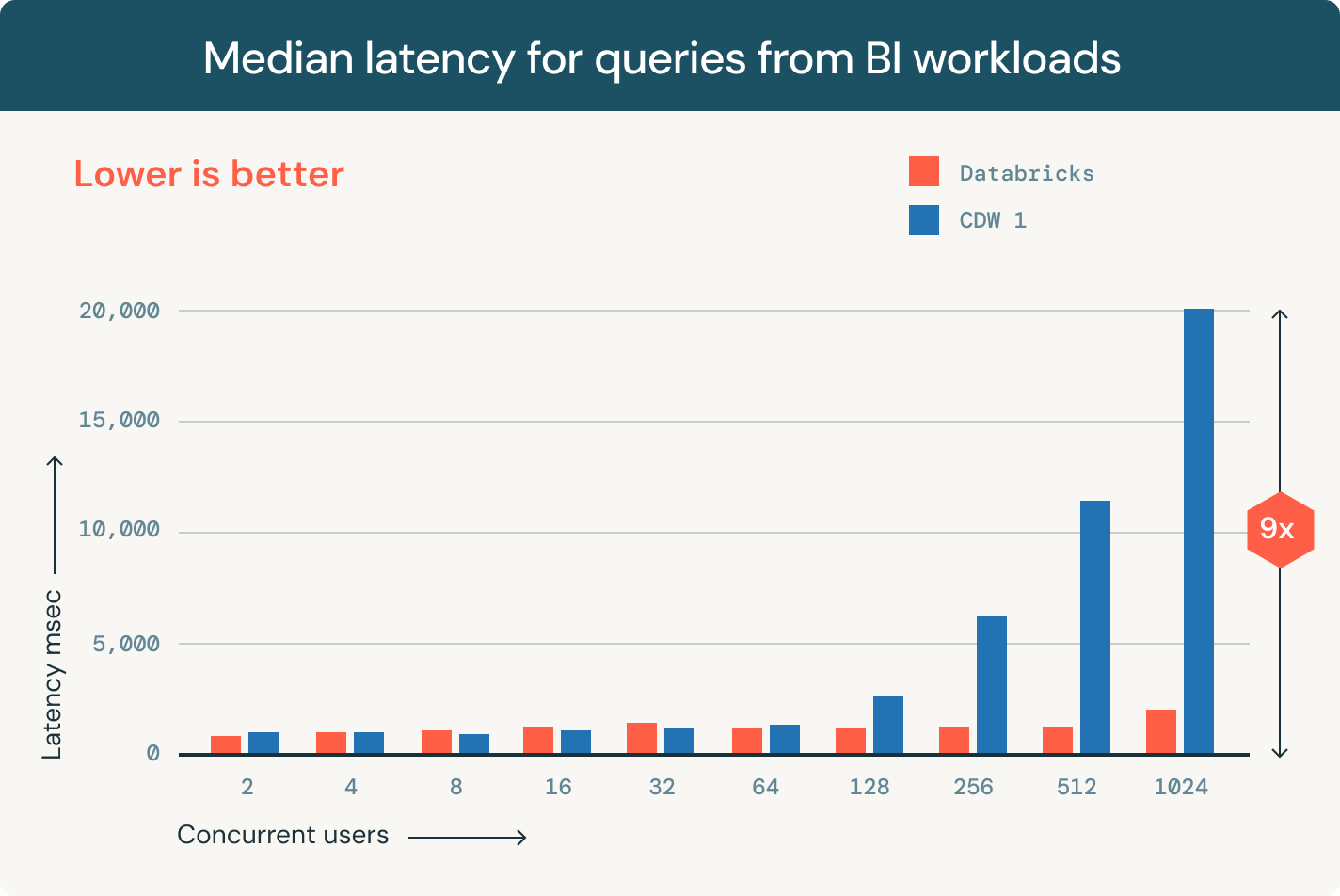

Entdecken, verwalten und teilen Sie Ihre Daten- und KI-Ressourcen
Erfahren Sie mehr darüber, wie die Databricks Data Intelligence Platform Ihre Datenteams bei all Ihren Daten- und KI-Workloads unterstützt.
Unity Catalog
Die einzige einheitliche und offene Governance-Lösung der Branche für Daten und KI, integriert in die Databricks Data Intelligence Platform.

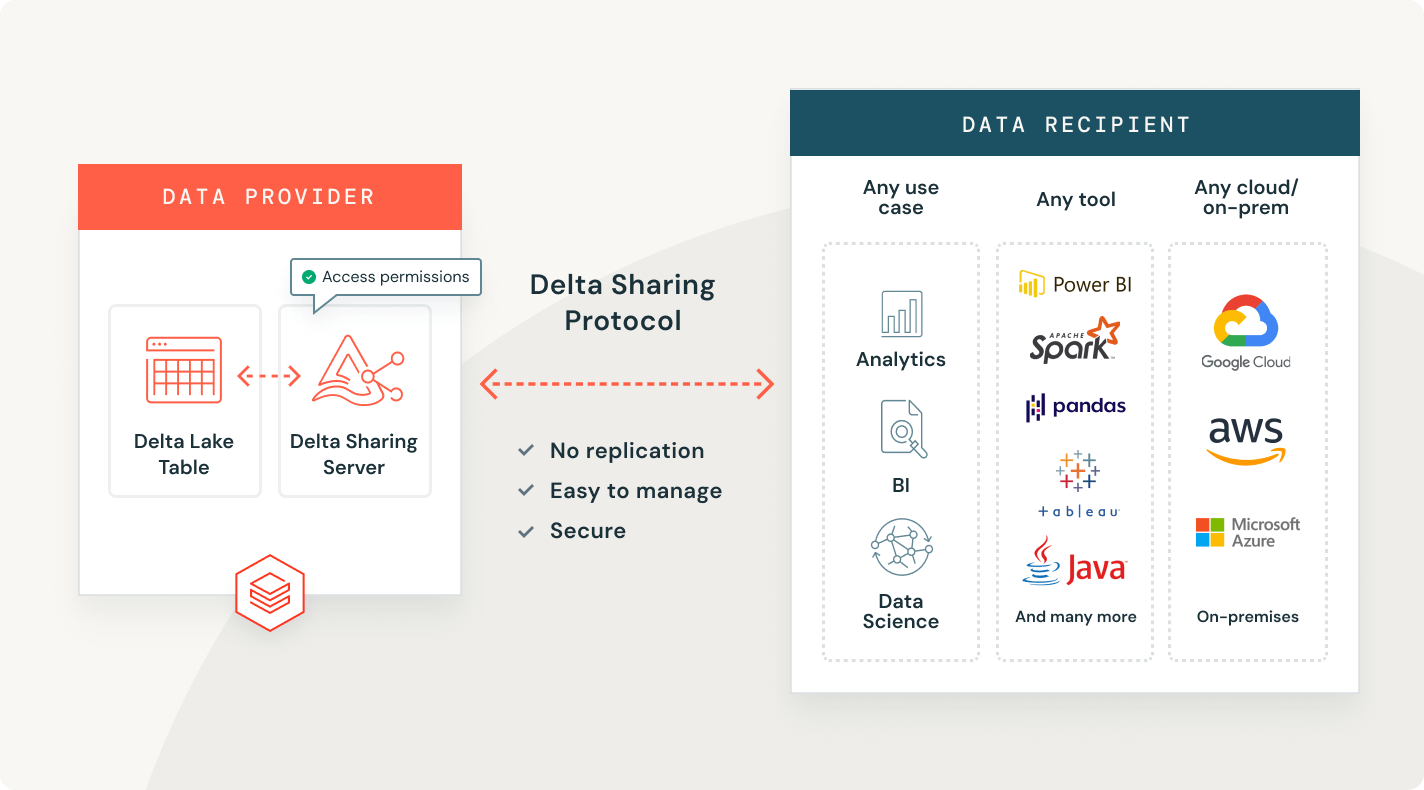
Delta-Freigabe
Der erste Open-Source-Ansatz zum Datenaustausch über Daten, Analytik und KI. Teilen Sie Live-Daten sicher über Plattformen, Clouds und Regionen hinweg.

Data Intelligence Platform
Entdecken Sie die gesamte Bandbreite der auf der Databricks Data Intelligence Platform verfügbaren Tools zur nahtlosen Integration von Daten und KI in Ihrem Unternehmen.
Mehr Informationen




FAQ zur Lakehouse-Speicherung
Möchten Sie ein Daten- und KI-Unternehmen werden?
Machen Sie die ersten Schritte Ihrer Transformation