Apache Kylin
Was ist Apache Kylin?
Apache Kylin ist eine verteilte Open-Source-OLAP-Engine (Online Analytical Engine) für interaktive Analysen von Big Data. Apache Kylin wurde entwickelt, um eine SQL-Schnittstelle und mehrdimensionale Analyse (OLAP) auf Hadoop/Spark bereitzustellen. Zudem lässt sich Apache Kylin einfach mit BI-Tools integrieren – über ODBC- und JDBC-Treiber sowie über eine REST API. Die Engine wurde 2014 von eBay entwickelt und bereits ein Jahr später, 2015, als Top-Level-Projekt in die Apache Software Foundation aufgenommen. Sowohl 2015 als auch 2016 wurde Apache Kylin als Best Open Source Big Data Tool ausgezeichnet. Heute setzen Tausende von Unternehmen weltweit Apache Kylin als strategische Analyseplattform für Big Data ein. Während andere OLAP-Engines bei dem großen Datenvolumen an ihre Grenzen stoßen, kann Kylin innerhalb von Millisekunden Antworten auf Abfragen liefern. Die Abfragelatenz liegt im Sub-Sekunden-Bereich, selbst bei Datensätzen im Petabyte-Umfang. Erreicht wird diese beeindruckende Geschwindigkeit durch Vorberechnung erreicht: Über Hive-Abfragen ermittelt Kylin verschiedene dimensionale Kombinationen und Maßaggregationen und speichert die Ergebnisse in HBase. 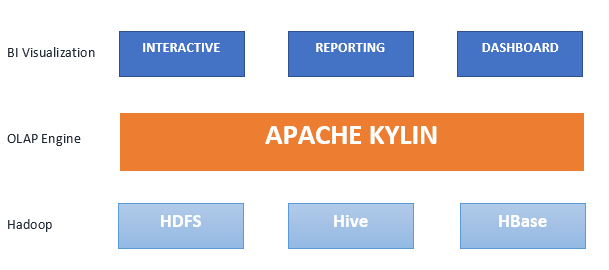
Wie funktioniert Apache Kylin?
Die Kylin-Abfrage-Engine kann über eine benutzerfreundliche UI, eine API oder über JDBC genutzt werden. Sie setzen auf den Apache Calcite-Abfrageprozessor auf und nutzt HBase für ultraschnelle Datenabfragen. Kylin stützt sich auf das Hadoop-Ökosystem:
- Hive – Eingabequelle, Vorverknüpfung von Sternschemas während des Cube-Building-Prozesses
- MapReduce – Aggregation von Metriken während des Cube-Buildings
- HDFS – Speicherung von Zwischendateien während des Cube-Buildings
- HBase – Speicherung und Abfrage der Data Cubes
- Calcite – SQL-Parsing, Codegenerierung, Optimierung Wie kann Apache Kylin Ihrer Organisation helfen?
- Ultraschnelle OLAP-Engine für große Datenvolumen – Kylin wurde entwickelt, um die Abfragelatenz auf Hadoop für Datensätze mit mehr als 10 Milliarden Zeilen auf Sekunden zu senken.
- ANSI SQL-Schnittstelle auf Hadoop – Kylin bietet ANSI SQL auf Hadoop und unterstützt die meisten ANSI SQL-Abfragefunktionen. Analysten und Engineers können es ganz mühelos verwenden, da keine Programmierung erforderlich ist.
- Nahtlose Integration mit BI-Tools – Kylin bietet derzeit Integrationsmöglichkeiten mit BI-Tools wie Tableau, JDBC/ODBC/Rest API.
- Interaktive Abfragen – Benutzer können über Kylin mit einer Latenz im Sub-Sekundenbereich mit Hadoop-Daten interagieren.
- MOLAP-Cube-Abfrage auf Milliarden von Zeilen – Benutzer haben die Möglichkeit, ein Datenmodell zu definieren und in Kylin vorzubauen, auch wenn es mehr als 10+ Milliarden Rohdatensätze hat.
Open-Source-ODBC-Treiber – Der ODBC-Treiber von Kylin wurde von Grund auf neu entwickelt und läuft sehr gut mit Tableau.