Data Governance
Ein umfassender Leitfaden zu Prozessen, Richtlinien und Technologien, die von Unternehmen eingesetzt werden, um ihre Daten zu verwalten und sie optimal zu verwerten.

Was ist Data Governance?
Data Governance ist ein umfassender Ansatz, der die Prinzipien, Praktiken und Tools zur Verwaltung der Datenbestände eines Unternehmens während des gesamten Lebenszyklus einbezieht. Durch die Abstimmung datenbezogener Anforderungen mit der Unternehmensstrategie sorgt Data Governance für bessere Datenverwaltung, Qualität, Transparenz, Sicherheit und Compliance im gesamten Unternehmen. Die Implementierung einer wirksamen Data-Governance-Strategie ermöglicht es Unternehmen, Daten für eine datengesteuerte Entscheidungsfindung bereitzustellen, sie gleichzeitig vor unbefugtem Zugriff zu schützen und die Einhaltung gesetzlicher Vorschriften zu gewährleisten.
Ähnliche Themen erkunden



Worin besteht der geschäftliche Nutzen von Data Governance?
Data Governance ist unverzichtbar, wenn es darum geht, den Mehrwert von Daten zu erschließen, die für das Unternehmen entscheidendes Kapital darstellen. Durch die Implementierung eines robusten Data-Governance-Ansatzes können Unternehmen ihre Datenbestände nutzen, Wettbewerbsvorteile erzielen und das Vertrauen ihrer Kunden gewinnen und wahren, indem sie solide Daten- und Datenschutzpraktiken anwenden.
Höhere betriebliche Effizienz bei geringeren Kosten
Mithilfe einer effektiven Data Governance können Unternehmen eine einheitliche Datengrundlage („Single Source of Truth“) für ihren Datenbestand schaffen, die Entstehung von Wildwuchs und Datensilos verhindern und Datenduplikate vermeiden. Dies führt zu höherer Effizienz, geringeren Kosten und einer einfacheren Verwaltung von Sicherheits- und Governance-Konzepten für den gesamten Bestand.
Höhere Produktivität und schnellere Entscheidungsfindung
Data Governance fördert die Datendemokratisierung, denn sie gewährleistet die Richtigkeit, Konsistenz und Vertrauenswürdigkeit der Daten. Dadurch können Datennutzer hochwertige Daten schneller finden und sowohl die Bedeutung als auch den Kontext der Daten besser verstehen, was eine höhere Produktivität und schnellere Entscheidungsfindung zur Folge hat.
Verbesserte Zusammenarbeit und Wertschöpfung
Ein solides Data-Governance-Programm bildet die Grundlage für eine verbesserte Zusammenarbeit und gemeinsame Datennutzung durch Teams, Geschäftsbereiche und Partner. Dies hilft Unternehmen, den Wissenstransfer zu fördern und eine bessere Datenkultur aufzubauen, was wiederum zu mehr Innovation, besseren Entscheidungen und einer maximalen Wertschöpfung aus den Daten führt.
Mehr Sicherheit und Datenschutz
Data Governance reduziert Sicherheits- und Datenschutzrisiken durch die Implementierung von Kontrollen und Prozessen zur Verhinderung von unbefugtem Zugriff und Missbrauch sensibler Daten. Sie fördert eine Kultur des Vertrauens und der Transparenz gegenüber den beteiligten Akteuren.
Bessere Einhaltung von Vorschriften und Standards
Eine wirksame Data Governance sorgt für verbesserte Konformität mit gesetzlichen Vorschriften wie DSGVO, HIPAA, FedRAMP oder CCPA. Dies trägt zum Schutz des Firmenimages bei, verhindert mögliche finanzielle und rechtliche Konsequenzen und stärkt das Vertrauen der Stakeholder.
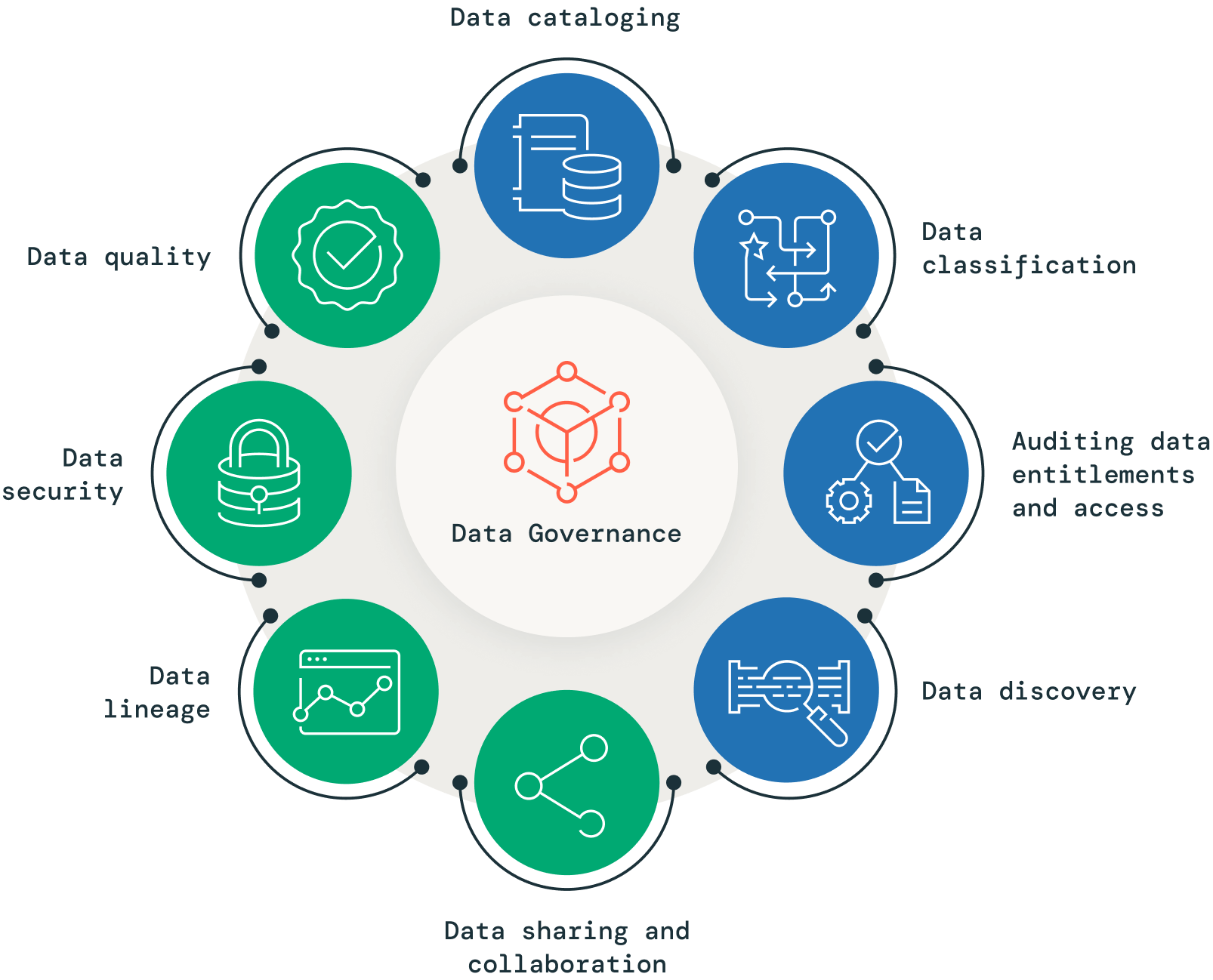
Kernelemente der Data Governance
![]()
Datenkatalogisierung
Eine wirksame Data Governance erfordert die Kenntnis der Daten, die in einem Unternehmen vorhanden sind. An diesem Punkt kommt ein Datenkatalog ins Spiel: Er stellt ein zentrales Metadaten-Repository für die Datenbestände eines Unternehmens bereit. Mit einem Datenkatalog können die Akteure benötigte Daten schnell finden, verstehen und abrufen. Dadurch werden datenbezogene Aktivitäten wie Ermittlung, Governance und Analysen verbessert. Der Datenkatalog fungiert als durchsuchbarer Index aller verfügbaren Daten. Dies schließt Angaben über Format, Struktur, Speicherort und Nutzung der Daten ein und bietet einen semantischen Mehrwert gegenüber einem ansonsten unübersichtlichen Meer von Informationen. Durch die Einbindung eines Datenkatalogs in ein Governance-Programm können Unternehmen ihre Datenverwaltung verbessern, die Zusammenarbeit fördern, Redundanzen abbauen und eine angemessene Zugriffskontrolle sowie den Abruf von Audit-Informationen sicherstellen.
![]()
Datenqualität
In der modernen datengesteuerten Welt ist es entscheidend, eine hohe Datenqualität sicherzustellen, um präzise Analysen, fundierte Entscheidungen und Kosteneffizienz zu gewährleisten. Die Datenqualität hat direkte Auswirkungen auf die Verlässlichkeit datengestützter Entscheidungen und ist ein zentraler Aspekt der Data Governance. Unternehmen; die eine effektive Data Governance gewährleisten wollen, müssen der Auswertung der wichtigsten Datenqualitätsattribute – wie Korrektheit, Vollständigkeit, Aktualität und Einhaltung der Datenqualitätsregeln – Vorrang einräumen. Daher ist eine ausgeprägte Fokussierung auf die Datenqualität für jede Data-Governance-Strategie unerlässlich, denn sie trägt dazu bei, die Datenherkunft zu ermitteln, Datenqualitätsregeln umzusetzen und Änderungen zu erfassen. Lassen Sie nicht zu, dass Ihre geschäftlichen Entscheidungen und die Ressourcenzuweisung durch eine schlechte Datenqualität beeinträchtigt werden: Stellen Sie die Datenqualität als wichtigen Bestandteil Ihrer Data-Governance-Maßnahmen in den Vordergrund, um bessere Ergebnisse zu erzielen.
![]()
Datenklassifizierung
Die Datenklassifizierung ist eine wichtige Komponente der Data Governance. Sie umfasst die Organisation und Kategorisierung von Daten auf der Grundlage ihrer Sensibilität, ihres Werts und ihrer Wichtigkeit. Angesichts des exponentiellen Datenwachstums sorgen sich die Unternehmen zunehmend um den Schutz sensibler Daten, die Risikominderung und die Sicherstellung der Datenqualität. Die Klassifizierung ermöglicht es Unternehmen, Daten auf Basis ihrer Risikostufe und Relevanz zu identifizieren und einzustufen, sodass sie jeweils geeignete Sicherheitsmaßnahmen und Richtlinien anwenden können. Ein robustes Datenklassifizierungssystem verbessert die Data Governance, senkt die Risiken und gewährleistet umfassend Datenqualität und Schutz.
![]()
Datensicherheit
Unternehmen ist durchaus bewusst, wie wichtig es ist, ihren Teams Zugriff auf hochwertige Daten zu ermöglichen, um Erkenntnisse zu gewinnen und den geschäftlichen Nutzen zu steigern. Gleichzeitig muss aber auch der Schutz sensibler Daten vor unbefugtem Zugriff unbedingte Priorität erhalten. Eine wirksame Datenzugriffsverwaltung ist für Datensicherheit und Data Governance entscheidend. Daher sollte ein gutes Governance-Programm für die Datensicherheit Zugriffskontrollen enthalten, die festlegen, welche Gruppen oder Personen auf welche Daten zugreifen dürfen. Diese Kontrollen können sehr spezifisch sein – bis hinab auf die Ebene einzelner Datensätze oder Dateien. Da durch Datenschutzverstöße und Vorschriften wie die DSGVO und den CCPA erhöhte Risiken entstehen, müssen Unternehmen klare Governance-Richtlinien aufstellen, die festlegen, wer auf sensible Datasets zugreifen darf und wie jeglicher Missbrauch verfolgt wird. Ein Zugriff auf private oder sensible Informationen durch Unbefugte ist unbedingt zu vermeiden: Die Implementierung wirksamer Zugriffsverwaltungsstrategien ist entscheidend, um Daten zu schützen und das Kundenvertrauen zu erhalten.
![]()
Prüfen von Datenberechtigungen und Zugriff
Eine wirksame Überprüfung des Datenzugriffs ist insbesondere in regulierten Branchen ein entscheidender Aspekt von Data-Governance- und Security-Governance-Programmen. Wenn Unternehmen wissen, wer Zugriff auf welche Daten hat, und die jüngsten Zugriffe verfolgen, können sie proaktiv übermäßig berechtigte Benutzer oder Gruppen ermitteln und deren Zugriff entsprechend anpassen, um das Risiko eines Datenmissbrauchs zu minimieren. Ohne angemessene Audit-Mechanismen hat ein Unternehmen unter Umständen keinen Überblick über seine Risikobereiche und ist dann anfällig für Datenschutzverletzungen und Gesetzesverstöße. Aus diesem Grund spielt ein gut konzipiertes Audit-Team innerhalb einer Data-Governance- oder Security-Governance-Organisation eine Schlüsselrolle bei der Gewährleistung der Datensicherheit und der Einhaltung von Vorschriften wie der DSGVO und dem CCPA. Durch die Implementierung wirkungsvoller Strategien zur Überprüfung des Datenzugriffs können Unternehmen das Vertrauen ihrer Kunden aufrechterhalten und ihre Daten vor unberechtigtem Zugriff oder Missbrauch schützen.
![]()
Datenherkunft
Die Ermittlung der Datenherkunft ist ein leistungsfähiges Werkzeug, das Unternehmen dabei hilft, die Qualität und Glaubwürdigkeit von Daten dadurch zu gewährleisten, dass sie ein besseres Verständnis der Datenquellen und der Datennutzung ermöglicht. Hierbei werden relevante Metadaten und Ereignisse während des gesamten Datenlebenszyklus erfasst, sodass Sie einen lückenlosen Einblick in den Datenfluss innerhalb des Datenbestands des Unternehmens erhalten. Als wesentliche Säule einer pragmatischen Data-Governance-Strategie können Unternehmen dank Datenherkunft Compliance und Revisionssicherheit erzielen, gleichzeitig den operativen Aufwand für die manuelle Erstellung von Prüfpfaden reduzieren und vertrauenswürdige Quellen für Prüfberichte bereitstellen. Darüber hinaus ermöglicht die Datenherkunft den Datennutzern bessere Analysen und hilft den Datenteams bei der Untersuchung von Fehlerursachen, wodurch das Debugging erheblich beschleunigt wird.
![]()
Data Discovery
Gerade weil Unternehmen immer umfangreichere Datenmengen aus den unterschiedlichsten Quellen erfassen, wird es zunehmend wichtig, die leichte Auffindbarkeit dieser Daten für Analyse-, KI- oder ML-Anwendungsfälle zu gewährleisten. Kritisch ist dies vor allem, um die Datendemokratisierung zu beschleunigen und den tatsächlichen Mehrwert der Daten zu erschließen. Zudem ist die Data Discovery mit dem Aufkommen moderner Datenbestände wie Dashboards, Machine-Learning-Modellen, Abfragen, Bibliotheken und Notebooks zu einer tragenden Säule einer soliden Data-Governance-Strategie geworden. Unternehmen sollten die Data Discovery als grundlegenden Aspekt ihrer Data-Governance-Strategie betrachten. Sie ermöglicht es Datenteams, Datenbestände im gesamten Unternehmen mühelos aufzufinden, an verschiedenen Projekten zusammenzuarbeiten und schnell und effizient Innovationen zu entwickeln. Dies trägt dazu bei, die Duplizierung von Daten zu verhindern, die problematisch sein kann, da das Vorhalten von Daten Kosten verursacht und hierdurch außerdem Governance-Probleme auf verschiedenen Sicherheitsebenen entstehen können.
![]()
Data Sharing und Zusammenarbeit
Data Sharing und Zusammenarbeit sind in der modernen Geschäftswelt unverzichtbar. Unternehmen tauschen Daten mit internen Teams, externen Partnern und Kunden über mehrere Clouds, Datenplattformen und Regionen hinweg aus. Da die Nachfrage nach externen Daten weiter steigt, müssen die Unternehmen Daten sicher austauschen und gleichzeitig die Kontrolle und den Überblick über die Nutzung ihrer sensiblen Daten behalten können. Datenreinräume spielen eine entscheidende Rolle bei der sicheren und strukturierten Zusammenarbeit mit Daten, denn sie gewährleisten, dass die Datenschutzbestimmungen eingehalten werden. Für Unternehmen ist es unerlässlich, in formatoffene und interoperable Multi-Cloud-Technologien für das Data Sharing zu investieren, um ihre datengesteuerten Innovationsanforderungen zu erfüllen. Darüber hinaus dienen Daten-Marketplaces als Brücke zwischen Datenanbietern und Datennutzern, denn sie erleichtern die Erkennung und Verbreitung von Datasets. Daher ist es von entscheidender Bedeutung, das Data Sharing als geschäftliche Notwendigkeit und tragende Säule einer soliden Data-Governance-Strategie zu begreifen.
Wie sieht eine gute Data-Governance-Lösung aus?
Datenorientierte Unternehmen räumen Daten, Analysen und künstlicher Intelligenz (KI) Vorrang ein, um bessere Geschäftsergebnisse zu erzielen. Dazu bauen sie ihre Datenstrategien auf einer Data-Lakehouse-Architektur auf, die Daten, Analysen und KI auf einer einzigen Plattform zusammenführt. Eine solche Architektur kombiniert die besten Eigenschaften von Data Warehouses und Data Lakes und bewältigt so alle Anwendungsfälle in den Bereichen Daten, Analysen und KI. Alle Daten werden in einem Cloud Data Lake gespeichert und über eine einheitliche Ebene verwaltet, sodass Analysen direkt an der einzigen Datenkopie durchgeführt werden können. Dieser Ansatz vereinfacht Data Governance und Sicherheit, reduziert funktionale Silos und begünstigt die Zusammenarbeit. Durch die Schaffung von hohem Vertrauen in Daten können Unternehmen souverän operieren und verstehen gleichzeitig besser, wie Daten bei allen Analysevorgängen erfasst, geändert, genutzt und beeinflusst werden.
Eine Data-Governance-Lösung für ein Data Lakehouse bietet eine Reihe wesentlicher Funktionen:
- Zentralisierter Datenkatalog: Ein zentralisierter Datenkatalog speichert alle Ihre Daten, ML-Modelle und Analyseartefakte sowie die Metadaten für jedes Objekt. Zudem fügt der einheitliche Katalog Daten aus anderen Katalogen hinzu, z. B. aus einem vorhandenen Hive-Metaspeicher.
- Einheitliche Steuerelemente für den Datenzugriff: Ein zentrales und einheitliches Berechtigungsmodell für alle Assets und alle Clouds. Hierzu gehört auch die attributbasierte Zugriffssteuerung (Attribute-based Access Control, ABAC) für persönlich identifizierbare Informationen (PII).
- Daten-Auditing: Der Datenzugriff wird zentral mit Warnmeldungen und Überwachungsfunktionen geprüft, um Rechenschaftspflicht und Sicherheitsanforderungen gerecht zu werden.
- Datenqualitätsmanagement: Robustes Datenqualitätsmanagement mit integrierten Qualitätskontrollen, Tests, Überwachungs- und Durchsetzungsfunktionen, um sicherzustellen, dass korrekte und nutzbringende Daten bereitstehen.
- Datenherkunft: Dank Datenherkunft erhalten Sie einen lückenlosen Einblick in den Datenfluss im Lakehouse – von der Quelle bis zum Konsumenten und bis hinab auf die Spaltenebene.
- Data Discovery: Die einfache Erkennung von Daten sorgt dafür, dass Data Scientists, Analysten, Engineers und weitere Betroffene relevante Daten schnell finden und referenzieren können und die Time-to-Value verkürzen.
- Data Sharing und Zusammenarbeit: Daten können – mithilfe detailliert differenzierender Zugriffskontrollen – cloud-, regions- und plattformübergreifend freigegeben werden, wodurch die Silobildung unterbunden wird.
- Datenreinräume für eine datenschutzgerechte Zusammenarbeit: Arbeiten Sie mit internen oder externen Beteiligten an sensiblen Daten in einem Umfeld, in dem der Datenschutz gewahrt bleibt.
- Offener Marketplace für Daten, Analytics und KI: Hier finden Sie Datasets sowie KI- und Analyseressourcen – wie ML-Modelle, Notebooks, Anwendungen und Dashboards – ohne Abhängigkeiten von proprietären Plattformen, kompliziertes ETL oder eine kostspielige Replikation.
Wer beaufsichtigt die Data Governance?
Chief Data Officer
Ihr Chief Data Officer (CDO) ist die ranghöchste Führungskraft in Ihrem Governance-Team. Er ist in letzter Konsequenz verantwortlich für die Sicherheit, Zugänglichkeit und Nutzbarkeit Ihrer Daten.
Zu den Aufgaben eines CDO gehören die Einrichtung des Systems, die Sicherstellung von Finanzierung und Personalausstattung für den Betrieb (und auch für damit verbundene Aspekte, etwa Tools zur Automatisierung bestimmter Prozesse) sowie die regelmäßige Überprüfung des Gesamtstatus.
Dateneigentümer
Dateneigentümer sind Personen oder Teams, die für die technische Administration Ihrer Datasets verantwortlich sind. Hier werden Entscheidungen darüber getroffen, welche Teammitglieder Zugriff auf welche Informationen haben sollen. Wenn die von ihnen aufgestellten Richtlinien (bzw. deren Fehlen) zu einem Datenschutzverstoß führen, können sie zur Rechenschaft gezogen werden.
Damit sie diese Rolle und die damit verbundenen zahlreichen Aufgaben erfüllen können, sind auch die Dateneigentümer in der Regel hochrangige Führungskräfte in Ihrem Unternehmen.
Data Stewards
Zur Unterstützung der täglichen Arbeitsabläufe im Rahmen der Data Governance benennen die Dateneigentümer und CDOs Data Stewards. Beim Data Stewardship geht es im Wesentlichen darum, das für die Data Stewards aufgestellte Programm umzusetzen und dafür zu sorgen, dass sowohl alte als auch neue Daten ordnungsgemäß verwaltet werden. Die Data Stewards sind dafür verantwortlich, die Compliance aufseiten von Mitarbeitern und Kunden zu kontrollieren und etwaige Probleme zu eskalieren.
Data-Governance-Gremien
Ein solches Gremium ist das Hauptinstrument für die Aufstellung der einschlägigen Richtlinien in Ihrer Organisation.
Häufig setzt es sich aus Führungskräften und Dateneigentümern zusammen, die ein ausgeprägtes Interesse an der Sicherheit und Nutzbarkeit der Daten haben. Nachdem ihre Richtlinien genehmigt wurden, können solche Gremien Verfahren festlegen, die die Stewards befolgen müssen. Auch für das Schlichten von Streitigkeiten zwischen Parteien sind sie zuständig.