Hadoop-Ökosystem
Was ist das Hadoop-Ökosystem?
Als Apache Hadoop-Ökosystem werden die verschiedenen Komponenten der Apache Hadoop-Softwarebibliothek bezeichnet. Es umfasst sowohl Open-Source-Projekte als auch eine ganze Reihe ergänzender Tools. Einige der bekannteren Tools aus dem Hadoop-Ökosystem sind u. a. HDFS, Hive, Pig, YARN, MapReduce, Spark, HBase, Oozie, Sqoop, und Zookeeper. Hier sind die wichtigsten Komponenten des Hadoop-Ökosystems, die häufig von Entwicklern genutzt werden:
Was ist HDFS?
Das Hadoop Distributed File System (HDFS) gehört zu den größten Apache-Projekten und ist das primäre Speichersystem von Hadoop. Es nutzt eine Architektur mit NameNodes und DataNodes. Dabei handelt es sich um ein verteiltes Dateisystem, das in der Lage ist, große Dateien zu speichern, und dazu einen aus Standardhardware aufgebauten Cluster nutzt.
Was ist Hive?
Hive ist ein ETL- und Data-Warehousing-Tool, das zur Abfrage und Analyse großer, im Hadoop-Ökosystem gespeicherter Datasets verwendet wird. Hive hat drei Hauptfunktionen: Zusammenfassung, Abfrage und Analyse unstrukturierter und halbstrukturierter Daten in Hadoop. Es stellt ein SQL-artiges Interface zur Verfügung: die Sprache HQL, die ähnlich wie SQL funktioniert und Abfragen automatisch in MapReduce-Jobs umwandelt.
Was ist Apache Pig?
Apache Pig ist eine höherentwickelte Skriptsprache zur Ausführung von Abfragen für größere Datasets, wie sie in Hadoop verwendet werden. Die einfache SQL-ähnliche Skriptsprache von Pig ist als Pig Latin bekannt. Ihr wesentlicher Zweck besteht darin, die erforderlichen Operationen durchzuführen und die endgültige Ausgabe wie gewünscht zu formatieren.
Was ist MapReduce?

Es handelt sich hierbei um eine weitere Datenverarbeitungsschicht von Hadoop. Sie ist in der Lage, umfangreiche strukturierte und unstrukturierte Daten zu verarbeiten und sehr große Datendateien parallel zu verwalten. Zu diesem Zweck werden Jobs jeweils in eine Reihe unabhängiger Tasks (oder Subjobs) unterteilt.
Was ist YARN?
YARN steht zwar für „Yet Another Resource Negotiator“, wird aber im Allgemeinen nur mit dem Akronym bezeichnet. Es ist eine der Kernkomponenten im quelloffenen Apache Hadoop und eignet sich zur Ressourcenverwaltung. YARN ist für die Verwaltung von Workloads, die Überwachung und die Implementierung von Sicherheitskontrollen zuständig. Außerdem weist es den verschiedenen Anwendungen, die in einem Hadoop-Cluster ausgeführt werden, Systemressourcen zu und legt fest, welche Aufgaben von den einzelnen Clusterknoten ausgeführt werden sollen. YARN umfasst zwei Hauptkomponenten:
- Resource Manager
- Node Manager
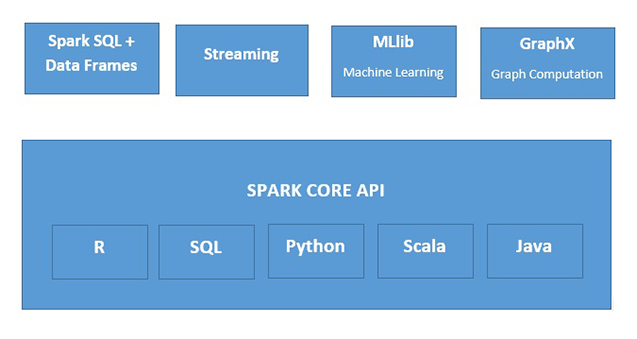
Was ist Apache Spark?
Apache Spark ist eine schnelle In-Memory-Datenverarbeitungs-Engine, die sich für eine Vielzahl von Anwendungsfällen eignet. Es kann auf unterschiedliche Weise implementiert werden, unterstützt die Programmiersprachen Java, Python, Scala und R sowie SQL, Streamingdaten, maschinelles Lernen und die Graphverarbeitung, die alle gemeinsam innerhalb einer Anwendung genutzt werden können.