Sparklyr
Was ist Sparklyr?
Sparklyr ist ein Open-Source-Paket, das eine Schnittstelle zwischen R und Apache Spark bereitstellt. Dank der Fähigkeit von Spark, mit verteilten Daten mit geringer Latenz zu interagieren, können Sie jetzt die Funktionen von Spark in einer modernen R-Umgebung nutzen. Sparklyr ist ein effektives Werkzeug für die Interaktion mit großen Datensätzen in einer interaktiven Umgebung. Auf diese Weise können Sie von den vertrauten Tools in R profitieren, um Daten in Spark zu analysieren, und erhalten so das Beste aus beiden Welten. 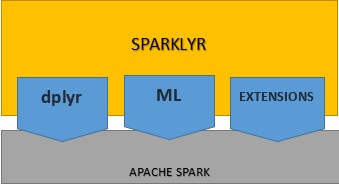 Durch Sparklyr können Sie Spark als Backend für dplyr nutzen, ein beliebtes Paket zur Datenmanipulation Sparklyr bietet eine Reihe von Funktionen, mit denen wir auf die Spark-Tools zur Transformation/Vorverarbeitung von Daten zugreifen können. Darüber hinaus bietet es auch Schnittstellen zu den verteilten Machine-Learning-Algorithmen von Spark und vieles mehr Sparklyr ist auch erweiterbar. Es können R-Pakete erstellt werden, die von Sparklyr abhängig sind, um die vollständige Spark-API aufzurufen. Eine solche Erweiterung ist Rsparkling von H2O, ein R-Paket, das mit dem ML-Algorithmus von H2O kompatibel ist.
Durch Sparklyr können Sie Spark als Backend für dplyr nutzen, ein beliebtes Paket zur Datenmanipulation Sparklyr bietet eine Reihe von Funktionen, mit denen wir auf die Spark-Tools zur Transformation/Vorverarbeitung von Daten zugreifen können. Darüber hinaus bietet es auch Schnittstellen zu den verteilten Machine-Learning-Algorithmen von Spark und vieles mehr Sparklyr ist auch erweiterbar. Es können R-Pakete erstellt werden, die von Sparklyr abhängig sind, um die vollständige Spark-API aufzurufen. Eine solche Erweiterung ist Rsparkling von H2O, ein R-Paket, das mit dem ML-Algorithmus von H2O kompatibel ist.
Hier die interessantesten Funktionen von Sparklyr:
- Benutzer können Spark-Daten interaktiv mit dplyr und SQL (über DBI) ändern.
- Spark-Datasets können gefiltert und aggregiert und anschließend zur Analyse in R übertragen werden.
- Benutzer können verteiltes Machine Learning aus R mithilfe von Spark MLlib oder H2O Sparkling Water orchestrieren.
- Sparklyr-Benutzer können Erweiterungen generieren, die die vollständige Spark-API aufrufen und Schnittstellen zum Spark-Paket bereitstellen.
- Sparklyr-Tools bieten ein umfassendes dplyr-Backend, das bei Datenänderung, Datenanalyse und Datenvisualisierung nützlich ist
- Lädt Daten von verschiedenen Speicherorten in Spark DataFrames, z. B. von lokalen R-DataFrames, Hive-Tabellen, CSV-, JSON- und Parquet-Dateien.
- Sparklyr kann sowohl eine Verbindung zu lokalen Spark-Instanzen als auch zu Remote-Spark-Clustern herstellen.