TensorFlow™ auf Databricks

Verteiltes Computing mit TensorFlow
TensorFlow unterstützt verteiltes Computing, sodass Teile des Graphen in verschiedenen Prozessen berechnet werden können, die sich auf völlig unterschiedlichen Servern befinden können! Darüber hinaus kann verteiltes Computing verwendet werden, um Berechnungen auf Server mit leistungsstarken GPUs zu verteilen und andere Berechnungen auf Servern mit mehr Speicher usw. durchzuführen. Die Schnittstelle ist jedoch etwas knifflig, also erstellen wir sie von Grund auf neu.
Hier ist unser erstes Skript, das wir in einem einzelnen Prozess ausführen, bevor wir zu mehreren Prozessen übergehen.
Inzwischen sollte Sie dieses Skript nicht mehr allzu sehr entmutigen. Wir haben eine Konstante und drei grundlegende Gleichungen. Das Ergebnis (238) wird am Ende ausgegeben.
TensorFlow funktioniert ein bisschen wie ein Server-Client-Modell. Das Grundkonzept besteht darin, die komplexen Aufgaben auf mehrere Worker zu verteilen. Anschließend erstellen Sie eine Sitzung für einen dieser Worker, der den Graphen berechnet und möglicherweise Teile der dazu nötigen Datenverarbeitung an andere Cluster auf dem Server verteilt.
Dazu muss der Haupt-Worker, der Master, über die anderen Worker Bescheid wissen. Dies erfolgt durch die Erstellung einer ClusterSpec, die Sie an alle Worker weitergeben müssen. Eine ClusterSpec wird mithilfe eines Wörterbuchs erstellt, wobei der Schlüssel ein Jobname ist und jeder Job viele Worker enthält.
Unten sehen Sie ein Diagramm, wie dies aussehen würde.
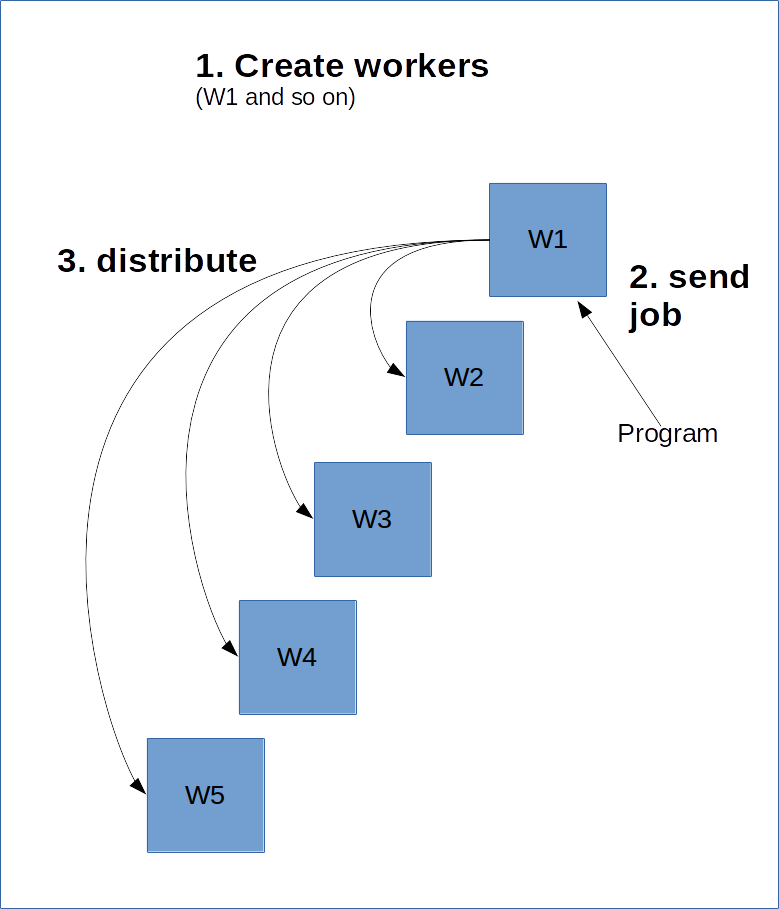
Der folgende Code erstellt eine ClusterSpec mit dem Job „local“ und zwei Worker-Prozessen.
Beachten Sie, dass diese Prozesse mit diesem Code nicht gestartet werden, sondern lediglich eine Referenz darauf erstellt wird, dass sie gestartet werden.
Als nächstes starten wir den Prozess. Dazu richten wir zuerst einen Worker ein und starten ihn:
Der obige Code startet den „localhost:2223“-Worker unter dem „local“-Job.
Nachfolgend finden Sie ein Skript, das Sie über die Befehlszeile ausführen können, um die beiden Prozesse zu starten. Speichern Sie den Code auf Ihrem Computer als create_worker.py und führen Sie ihn mit python create_worker.py 0 und dann python create_worker.py 1 aus. Dazu benötigen Sie separate Terminals, da die Skripte nicht von alleine abgeschlossen werden (sondern auf Anweisungen warten).
Anschließend werden Sie feststellen, dass die Server auf zwei Terminals ausgeführt werden. Fertig zur Verteilung!
Die einfachste Möglichkeit, den Job zu „verteilen“, besteht darin, einfach eine Sitzung für einen dieser Prozesse zu erstellen und dann den Graphen dort auszuführen. Ändern Sie dazu einfach die Zeile „session“ oben in:
Dadurch wird nicht wirklich viel verteilt, sondern der Job wird an diesen Server gesendet. TensorFlow verteilt die Verarbeitung möglicherweise auf andere Ressourcen im Cluster, vielleicht aber auch nicht. Wir können dies erzwingen, indem wir Geräte angeben (ähnlich wie wir es in den letzten Lektion mit GPUs gemacht haben):
Jetzt wird die Verarbeitung wirklich verteilt! Dies funktioniert durch die Zuweisung von Tasks an Worker, basierend auf dem Namen und der Tasknummer. Das Format ist:
/job:JOB_NAME/task:TASK_NUMBER
Bei mehreren Jobs (z. B. zur Identifizierung von Computern mit leistungsstarken GPUs) können wir die Verarbeitung auf viele verschiedene Arten verteilen.
MapReduce
MapReduce ist ein beliebtes Paradigma für die Durchführung großer Operationen. Es besteht aus zwei Hauptschritten (in der Praxis gibt es jedoch noch einige weitere).
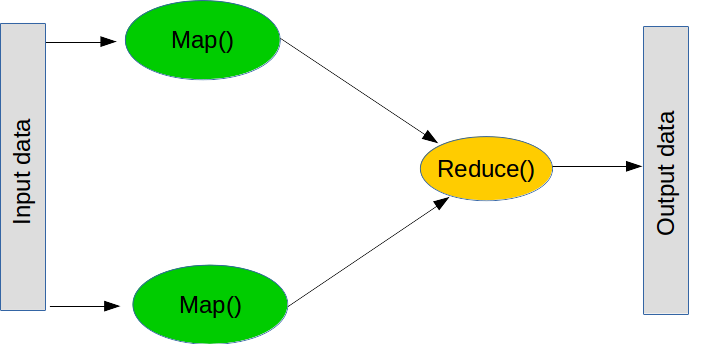
Der erste Schritt ist als Map bekannt, was bedeutet: „Nimm Liste von Dingen und wende diese Funktion auf jedes davon an“. Sie können eine Map in normalem Python wie folgt erstellen:
Der zweite Schritt ist als Reduce bekannt, was bedeutet: „Nimm diese Liste von Dingen und kombiniere sie mit dieser Funktion“. Ein üblicher Reduce-Vorgang ist „sum“ – also „nimm diese Liste von Zahlen und kombiniere sie, indem alle addiert werden“, was durch Erstellen einer Funktion durchgeführt werden kann, die zwei Zahlen addiert. Was Reduce tut, ist, die ersten beiden Werte der Liste zu nehmen, die Funktion auszuführen, das Ergebnis zu nehmen und dann die Funktion mit dem Ergebnis und dem nächsten Wert auszuführen. Bei „sum“ addieren wir die ersten beiden Zahlen, nehmen das Ergebnis, addieren es mit der nächsten Zahl und so weiter, bis wir das Ende der Liste erreichen. Auch hier ist „reduce“ Teil von normalem Python (obwohl es nicht verteilt wird):
Beachten Sie, dass Sie „reduce“ nie wirklich benötigen sollten – verwenden Sie einfach eine for-Schleife.
Zurück zum verteilten TensorFlow: Die Durchführung von Map- und Reduce-Operationen ist ein entscheidender Baustein vieler nicht trivialer Programme. Beispielsweise kann ein Ensemble-Learning einzelne Machine-Learning-Modelle an mehrere Worker senden und dann die Klassifizierungen kombinieren, um das Endergebnis zu bilden. Nachfolgend ein weiteres Prozessbeispiel.
Hier ist ein weiteres grundlegendes Skript, das wir verteilen werden:
Die Konvertierung in eine verteilte Version ist lediglich eine Änderung der vorherigen Konvertierung:
Sie werden feststellen, dass die Verteilung von Berechnungen viel einfacher ist, wenn Sie sie als MapReduce-Vorgänge betrachten. Erstens: „Wie kann ich dieses Problem in Teilprobleme aufteilen, die unabhängig voneinander gelöst werden können?“ – Das ist Ihr Map. Zweitens: „Wie kann ich die Antworten kombinieren, um ein Endergebnis zu erzielen?“ – Das ist Ihr Reduce.
Beim Machine Learning besteht die häufigste Methode für Map darin, Ihre Datasets einfach aufzuteilen. Lineare Modelle und neuronale Netze eignen sich dabei häufig recht gut, da sie einzeln trainiert und später kombiniert werden können.
1) Ändern Sie das Wort „local“ in der ClusterSpec in etwas anderes. Was müssen Sie sonst noch am Skript ändern, damit es funktioniert?
2) Das Mittelungsskript basiert derzeit auf der Tatsache, dass die Slices die gleiche Größe haben. Versuchen Sie es mit unterschiedlich großen Slices und sehen Sie sich den Fehler genau an. Beheben Sie dieses Problem, indem Sie tf.size und die folgende Formel zum Kombinieren von Durchschnittswerten aus Slices verwenden:
3) Sie können ein Gerät auf einem Remote-Computer angeben, indem Sie den Geräte-String ändern. Beispielsweise zielt „/job:local/task:0/gpu:0“ auf die GPU im lokalen Job ab. Erstellen Sie einen Job, der eine Remote-GPU nutzt. Wenn Sie einen zweiten Computer zur Hand haben, versuchen Sie, diesen Vorgang über das Netzwerk auszuführen.