LLMOps
Qu’est-ce qu’un LLMOps ?
Un LLMOps (Large Language Model Ops) est un ensemble de pratiques, de techniques et d’outils utilisés pour la gestion opérationnelle des grands modèles de langage (LLM, Large Language Model) dans des environnements de production.
Les dernières avancées dans le domaine des LLM, illustrées par des versions telles GPT d’OpenAI, Bard de Google et Dolly de Databricks, expliquent pourquoi les entreprises développent et déploient de plus en plus de LLM. Il est donc nécessaire d’élaborer de bonnes pratiques sur la manière de rendre ces modèles opérationnels. Un LLMOps permet le déploiement, le monitoring et la maintenance efficaces des grands modèles de langage. Tout comme le MLOps (Machine Learning Ops) traditionnel, les solutions LLMOps nécessitent une collaboration entre les data scientists, les ingénieurs DevOps et les professionnels IT. Pour savoir comment créer votre propre LLM avec nous, cliquez ici.
Les grands modèles de langage (LLM) sont des modèles innovants dans le domaine du traitement du langage naturel (NLP). Ils surpassent les modèles précédents dans l’accomplissement de diverses tâches telles que répondre à des questions ouvertes, résumer ou suivre des instructions quasi arbitraires. Les MLOps ont des exigences opérationnelles communes avec les LLMOps. Cependant, la formation et le déploiement des LLM présentent des défis spécifiques qui exigent une approche personnalisée pour les LLMOps.
En quoi les LLMOps diffèrent-ils des MLOps ?
Pour adapter les pratiques MLOps, il est nécessaire d’étudier comment les flux de travail et les exigences de machine learning (ML) évoluent avec les LLM. Les principaux éléments à prendre en compte sont les suivants :
- Ressources de calcul : l’entraînement et l’ajustement de grands modèles de langage implique généralement des quantités de calcul supérieures de plusieurs ordres de grandeur sur de grands ensembles de données. Pour accélérer ce processus, du matériel spécialisé est utilisé, comme des GPU bien plus performants pour réaliser des opérations en parallèle. L’accès à ces ressources de calcul spécialisées devient essentiel pour l’entraînement comme pour le déploiement des grands modèles de langage. Le coût de l’inférence peut également faire de la compression des modèles et des techniques de distillation un facteur clé.
- Apprentissage par transfert : contrairement à de nombreux modèles de ML traditionnels créés et entraînés à partir de zéro, beaucoup de LLM s’appuient sur un modèle de base. Ils sont ajustés à l’aide de nouvelles données pour améliorer leurs performances dans un domaine plus spécifique. Cet ajustement permet d’atteindre des performances de pointe dans des applications spécifiques utilisant moins de données et de ressources de calcul.
- Feedback humain : l’entraînement des grands modèles de langage a connu une amélioration considérable avec l’apprentissage par renforcement qui implique un feedback humain (Reinforcement learning from human feedback / RLHF). Plus généralement, dans la mesure où les tâches LLM sont souvent très ouvertes, le feedback humain des utilisateurs finaux de votre application est essentiel pour évaluer les performances de votre modèle. L’intégration de cette boucle de feedback dans vos pipelines LLMOps simplifie l’évaluation et fournit des données permettant d’affiner votre LLM à l’avenir.
- Ajustement des hyperparamètres : avec le ML classique, l’ajustement des hyperparamètres est souvent axé sur l’amélioration de la précision ou d’autres métriques. Pour les LLM, l’ajustement est également crucial pour réduire le coût, ainsi que les besoins en puissance de calcul de l’entraînement et de l’inférence. Par exemple, de petites modifications des tailles de lot et des taux d’apprentissage peuvent considérablement affecter la vitesse et le coût de l’entraînement. Par conséquent, le ML classique comme les LLM bénéficient du suivi et de l’optimisation du processus d’ajustement, mais à différents degrés.
- Métriques de performance : les modèles ML traditionnels ont des métriques de performance très clairement définies, comme la précision, l’AUC, le score F1, etc. Ces métriques sont assez simples à calculer. Mais lorsqu’il s’agit d’évaluer les LLM, c’est un tout autre ensemble de métriques standards et de scores qui s’applique. Pensez par exemple aux métriques BLEU (Bilingual Evaluation Understudy) et ROUGE (Recall-Oriented Understudy for Gisting Evaluation), qui demandent une attention particulière lors de leur mise en œuvre.
- L’ingénierie de prompts : les modèles de suivi des instructions peuvent prendre en compte des prompts complexes, ou des ensembles d’instructions. Il est primordial de bien concevoir ces templates de prompt pour obtenir des réponses précises et fiables de la part des LLM. L’ingénierie de prompts peut réduire le risque d’hallucination de modèle et de piratage (dont l’injection de prompts), la fuite de données sensibles et le jailbreaking.
- Construction de chaînes LLM ou de pipelines LLM : les pipelines LLM, construits à l’aide d’outils tels que LangChain ou LlamaIndex, enchaînent plusieurs appels LLM et/ou des appels à des systèmes externes tels que des bases de données vectorielles ou des recherches sur le Web. Ces pipelines permettent aux LLM d’être utilisés pour des tâches complexes telles que des questions-réponses dans les bases de connaissances ou l’assistance aux utilisateurs en se basant sur des ensembles de documents. Le développement d’applications LLM se concentre souvent sur la construction de ces pipelines, plutôt que sur la construction de nouveaux LLM.
Pourquoi avons-nous besoin des LLMOps ?
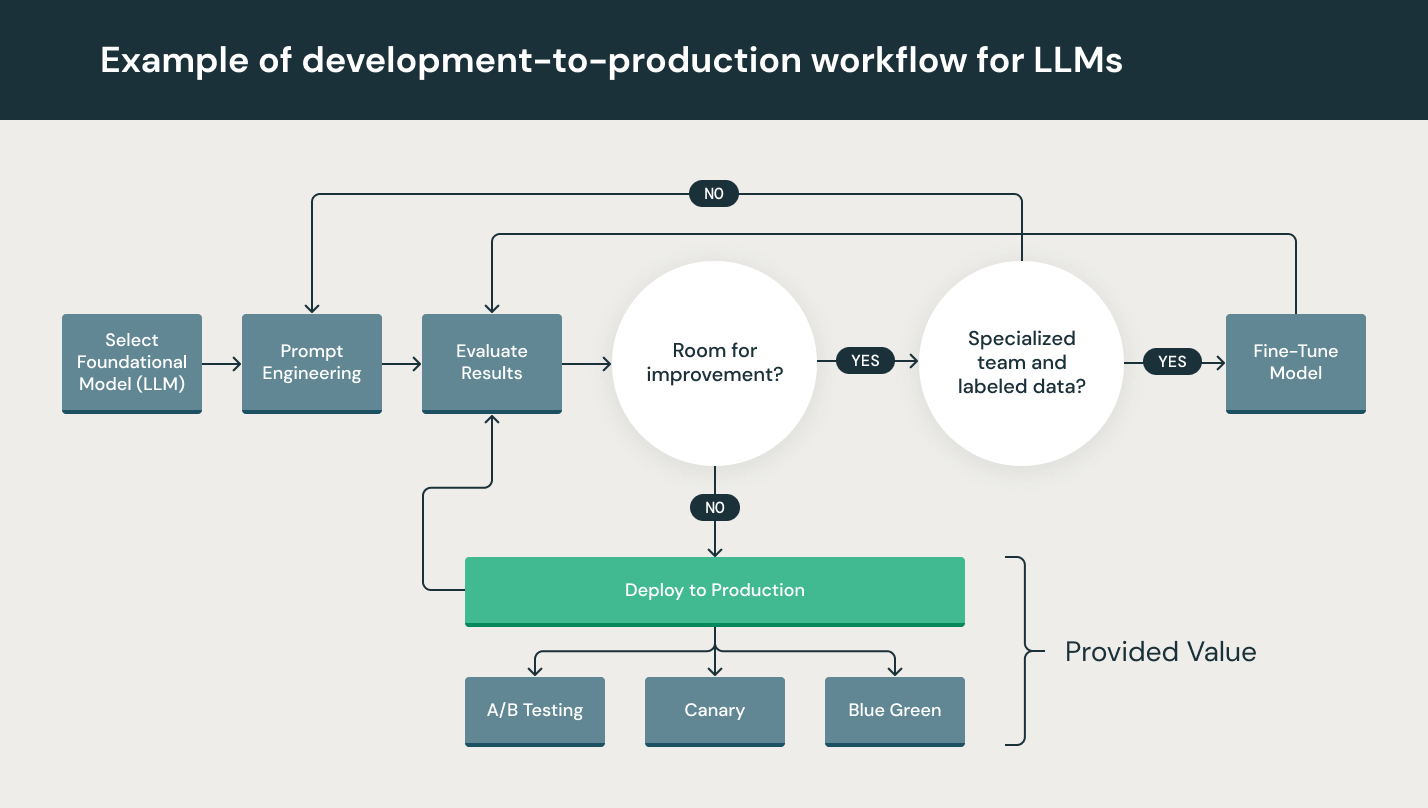
Bien que les LLM soient particulièrement simples à utiliser pour le prototypage, l’utilisation d’un LLM dans un produit commercial présente encore des difficultés. Le cycle de développement d’un LLM comprend de nombreux composants complexes tels que l’ingestion des données, la préparation des données, l’ingénierie de prompts, l’affinage du modèle, son déploiement et sa surveillance, et bien d’autres encore. Il nécessite également une collaboration et des transferts entre différentes équipes : data engineering, data science et ingénierie ML. Tous ces processus doivent être synchronisés et coordonnés avec la plus grande rigueur opérationnelle. Les LLMOps englobent l’expérimentation, l’itération, le déploiement et l’amélioration continue du cycle de vie du développement LLM.
Quels sont les avantages des LLMOps ?
Les principaux atouts des LLMOps sont l’efficacité, l’évolutivité et la réduction des risques.
- Efficacité : les LLMOps permettent aux équipes chargées des données d’accélérer le développement des modèles et des pipelines, de fournir des modèles de meilleure qualité et de les déployer plus rapidement en production.
- Évolutivité : les LLMOps offrent des possibilités de gestion à très grande échelle. Des milliers de modèles peuvent ainsi être supervisés, contrôlés, gérés et surveillés à des fins d’intégration, de livraison et de déploiement continus. Spécifiquement, les LLMOps permettent la reproductibilité des pipelines LLM et facilitent une collaboration plus étroite entre les équipes chargées des données. Ils réduisent ainsi les conflits avec les DevOps et l’IT, ce qui a pour effet de réduire le délai de publication.
- Réduction des risques : les LLM doivent souvent faire l’objet d’examens réglementaires. Les LLMOps apportent davantage de transparence et de réactivité vis-à-vis de ces obligations. C’est l’assurance d’une conformité plus grande aux politiques de l’entreprise ou du secteur d’activité.
Quels sont les composants des LLMOps ?
Dans un projet de machine learning, le périmètre d’action des LLMOps peut être aussi ciblé ou large qu’il le faut. Dans certains cas, les LLMOps peuvent englober l’intégralité des étapes allant de la préparation des données à la production du pipeline. D’autres projets peuvent nécessiter la mise en œuvre du seul processus de déploiement du modèle. Une majorité d’entreprises applique les principes LLMOps aux activités suivantes :
- Analyse exploratoire des données (EDA)
- Préparation des données et ingénierie de prompts
- Mise au point du modèle
- Examen et gouvernance des modèles
- Inférence et mise à disposition des modèles
- Supervision des modèles et feedback humain
Quelles sont les bonnes pratiques des LLMOps ?
Les bonnes pratiques des LLMOps dépendent du stade auquel les principes LLMOps sont appliqués.
- Analyse exploratoire des données (EDA) : explorez, partagez et préparez les données par itération pour le cycle de vie du machine learning en créant des ensembles de données, des tables et des visualisations que vous pourrez ensuite reproduire, éditer et partager.
- Préparation des données et ingénierie de prompts : transformez, agrégez et dédupliquez les données. Ensuite, mettez-les à disposition des équipes chargées des données. Développez itérativement des prompts pour des requêtes structurées et fiables vers les LLM.
- Ajustement du modèle : utilisez des bibliothèques open source populaires telles que Hugging Face Transformers, DeepSpeed, PyTorch, TensorFlow et JAX pour ajuster et améliorer les performances du modèle.
- Examen et gouvernance des modèles : suivez l’évolution des modèles et des pipelines ainsi que leurs versions. Gérez également les artefacts et les transitions tout au long de leur cycle de vie. Découvrez et partagez des modèles ML pour collaborer entre équipes à l’aide d’une plateforme MLOps open source comme MLflow.
- Inférence et mise à disposition des modèles : gérez la fréquence d’actualisation des modèles, le délai des requêtes d’inférence et d’autres spécificités de production du même type en phase de test et de QA. Utilisez des outils CI/CD comme les dépôts et les orchestrateurs pour automatiser le pipeline de préproduction en vous inspirant des principes DevOps. Activez des endpoints du modèle de l’API REST, avec l’accélération GPU.
- Monitoring des modèles avec feedback humain : créez des pipelines de monitoring des modèles et des données avec des alertes pour le drift de modèle et les utilisateurs ayant un comportement suspect.
Qu’est-ce qu’une plateforme LLMOps ?
Une plateforme LLMOps offre aux data scientists et aux ingénieurs logiciels un environnement de collaboration qui facilite l’exploration des données par itération, offre des capacités de collaboration en temps réel à des fins de suivi expérimental, d’ingénierie de prompts et de gestion des pipelines. Elle permet également de contrôler la transition, le déploiement et le monitoring des modèles pour les LLM. Une plateforme LLMOps automatise les aspects opérationnels, le monitoring et la synchronisation du cycle de vie du machine learning.
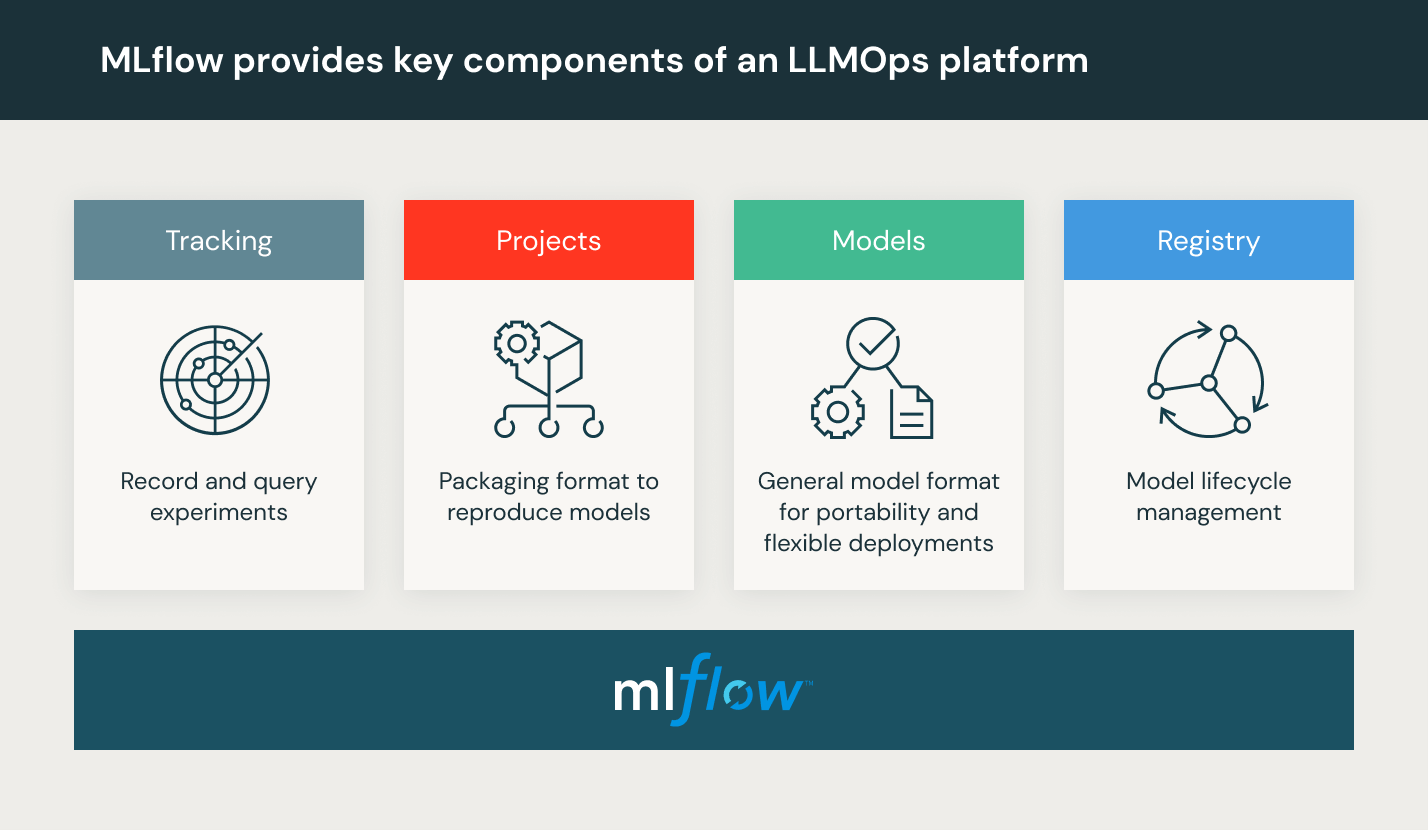
Databricks fournit un environnement entièrement géré comprenant MLflow : la plateforme MLOps ouverte numéro 1. Essayez Databricks Machine Learning