Apache Spark
Qu'est-ce qu'Apache Spark ?
Apache Spark est un moteur d'analytique open source utilisé dans le traitement du big data. Il est capable de traiter aussi bien des données en batch que des charges d'analytique et de traitement des données en temps réel. Apache Spark était au départ un projet de recherche à l'Université de Californie à Berkeley. Les chercheurs voulaient accélérer les tâches de traitement dans les systèmes Hadoop. Apache Spark repose sur le modèle MapReduce d'Hadoop qu'il prolonge pour le mettre au service de types de calcul plus nombreux, dont les requêtes interactives et le traitement de flux. Spark fournit des liaisons natives pour les langages de programmation Java, Scala, Python et R. Il inclut également plusieurs bibliothèques pour soutenir le développement d'applications de machine learning (MLlib), le traitement de flux (Spark Streaming) et le traitement graphique (GraphX). Apache Spark se compose de Spark Core et d'un ensemble de bibliothèques. Spark Core forme le cœur d'Apache Spark : c'est lui qui se charge de la transmission des tâches distribuées, de la planification et de la fonctionnalité E/S. Le moteur Spark Core utilise le concept de Resilient Distributed Dataset (dataset résilient distribué, ou RDD) comme type de données de base. La conception RDD a pour but de soustraire l'essentiel de la complexité computationnelle au regard de l'utilisateur. Spark a une approche intelligente des opérations sur les données : les données et les partitions sont agrégées sur un cluster de serveurs, où elles peuvent être calculées puis déplacées vers un autre magasin de données ou exploitées par un modèle analytique. Vous n'aurez pas besoin de spécifier la destination des fichiers, ni les ressources de calcul à utiliser pour stocker ou récupérer des fichiers. 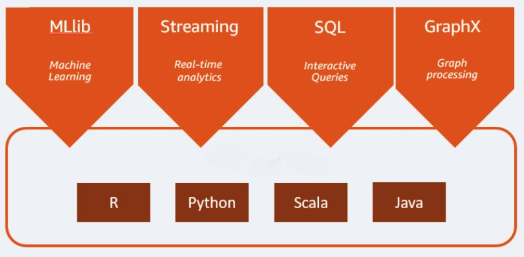
Poursuivez votre exploration



Quels sont les avantages d'Apache Spark ?
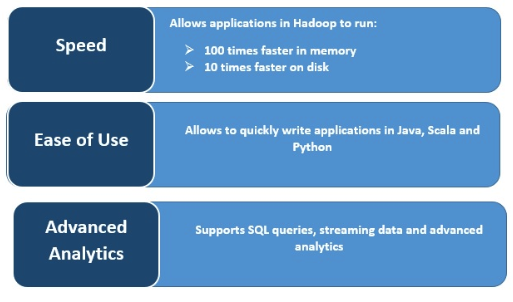
Rapidité
Spark est extrêmement rapide parce qu'il met les données en cache et ce, sur plusieurs opérations en parallèle. Le principal atout de Spark réside dans son moteur in-memory qui accroît la vitesse de traitement. Il est jusqu'à 100 fois plus rapide que MapReduce dans le cas du traitement en mémoire, et 10 fois plus rapide sur disque, pour le traitement des données à grande échelle. Spark parvient à ces résultats en réduisant le nombre d'opérations de lecture/écriture sur le disque.
Traitement de flux en temps réel
Apache Spark peut gérer le streaming en temps réel ainsi que l'intégration d'autres frameworks. Spark importe les données en petits lots et leur applique des transformations RDD.
Prise en charge de plusieurs charges de travail
Apache Spark peut exécuter de multiples charges : requêtes interactives, analytique en temps réel, machine learning et traitement graphique. Une même application peut combiner plusieurs charges de travail en toute transparence.
Une utilisation plus simple
La prise en charge de différents langages de programmation donne du dynamisme à Apache Spark. Vous pouvez rapidement écrire des applications en Java, Scala, Python et R – l'éventail du choix est large.
Analytique avancée
Spark prend en charge les requêtes SQL, le machine learning, le traitement de flux et le traitement graphique.