Vector Search
Une base de données vectorielle hautement performante avec gouvernance intégrée

Libérez tout le potentiel de l'IA générative avec Databricks Vector Search
Vector Search est une base de données vectorielle serverless étroitement intégrée à Data Intelligence Platform.
Contrairement aux autres bases de données, Databricks Vector Search prend en charge la synchronisation automatique des données entre la source et l'index, afin d'éliminer les coûts et la complexité de la maintenance des pipelines. Vector Search utilise les outils de sécurité et de gouvernance des données que les organisations ont déjà élaborés pour plus de sérénité. Grâce à sa conception serverless, Databricks Vector Search évolue aisément pour prendre en charge des milliards d'intégrations et des milliers de requêtes par seconde.
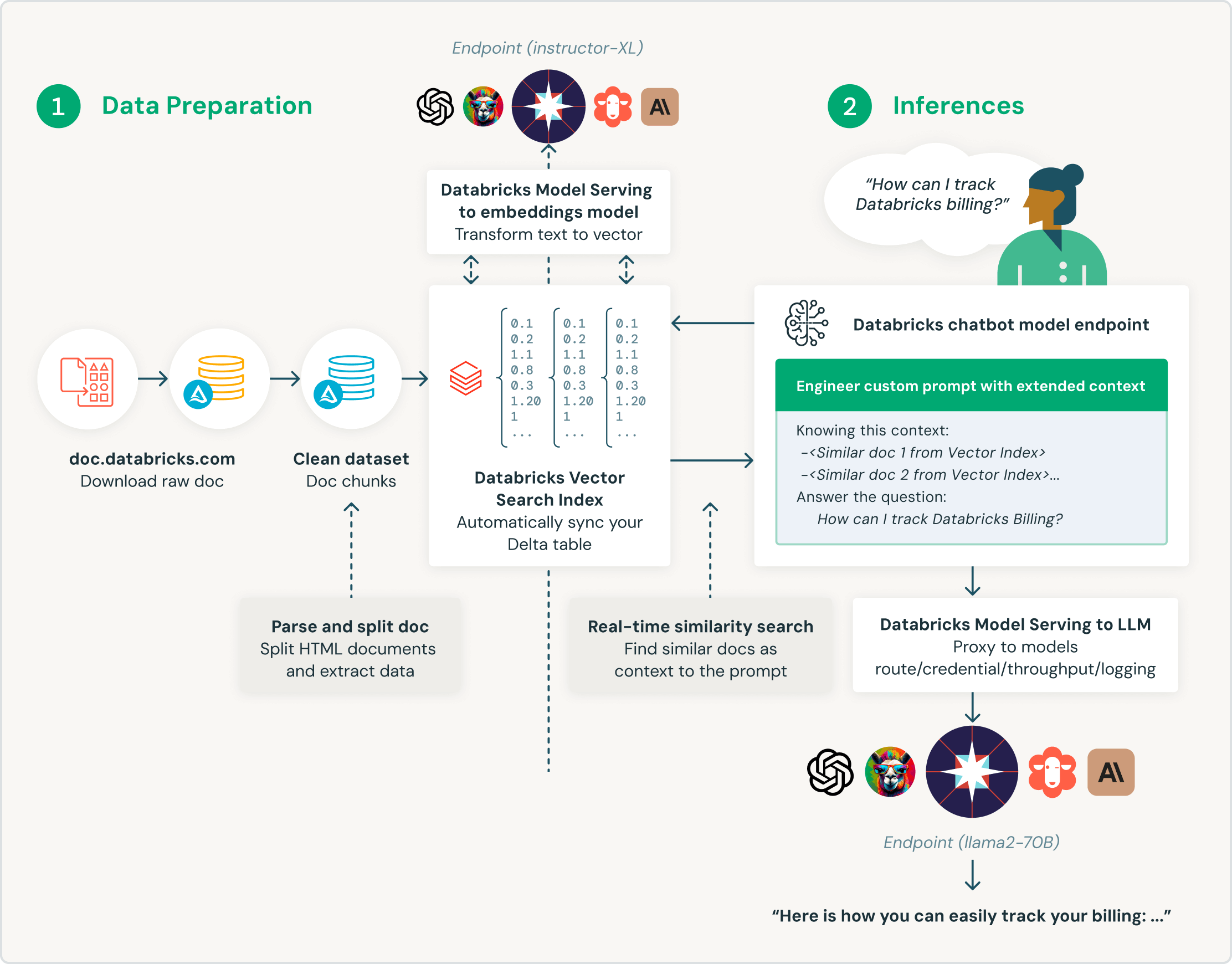
Conçue pour la génération augmentée de récupération (RAG)
Databricks Vector Search s'adresse spécifiquement aux clients souhaitant enrichir leurs grands modèles de langage (LLM) avec des données d'entreprise. Spécialement pensée pour les applications de génération augmentée de récupération (RAG), la base Databricks Vector Search délivre des résultats de recherche de similarité, apporte du contexte et des connaissances spécialisées aux requêtes de LLM, et améliore la précision et la qualité des résultats.
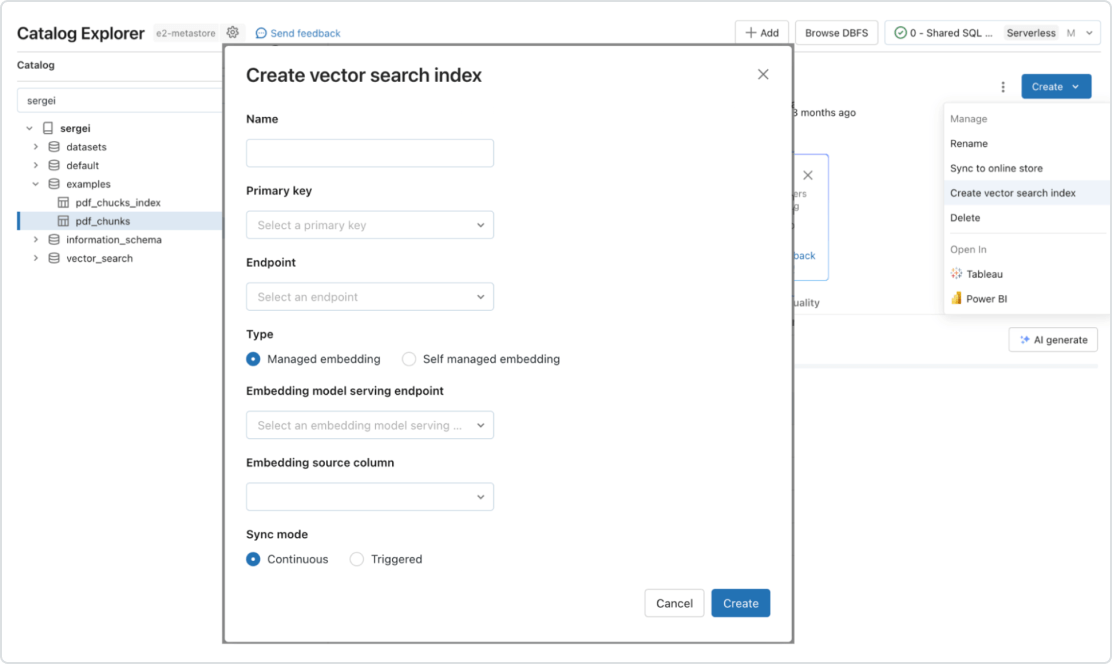
Pipelines temps réel automatisés
Synchronisation en temps réel des données sources par la mise à jour automatique de l'index vectoriel correspondant, à mesure que de nouvelles données sont introduites, modifiées ou supprimées. En coulisses, Databricks se charge de nombreuses opérations : génération et gestion des vecteurs d'intégration, gestion automatique des échecs et des nouvelles tentatives, optimisation du débit et ajustement automatique des tailles des batches. Le tout, sans aucune intervention extérieure.
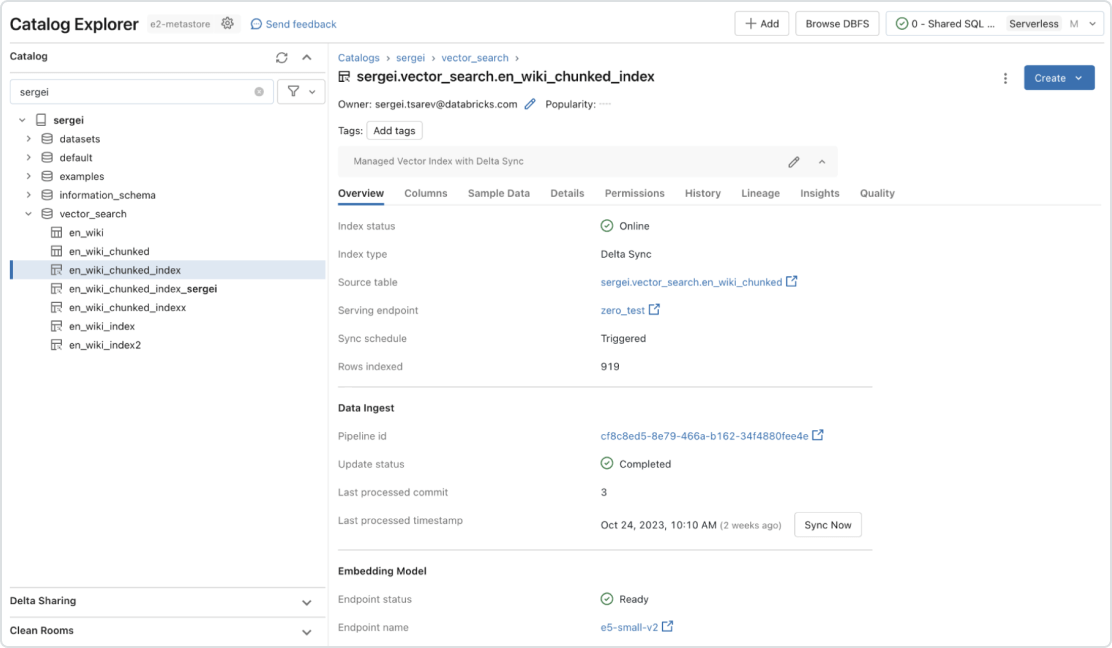
Gouvernance intégrée
L'interface unifiée applique des politiques aux données ainsi qu'un contrôle d'accès granulaire sur les intégrations. Grâce à une liaison native avec le Unity Catalog, Vector Search affiche automatiquement le data lineage et son suivi sans outil ni politique de sécurité supplémentaire. Cette approche empêche toute exposition de données confidentielles par les LLM à des utilisateurs non autorisés.
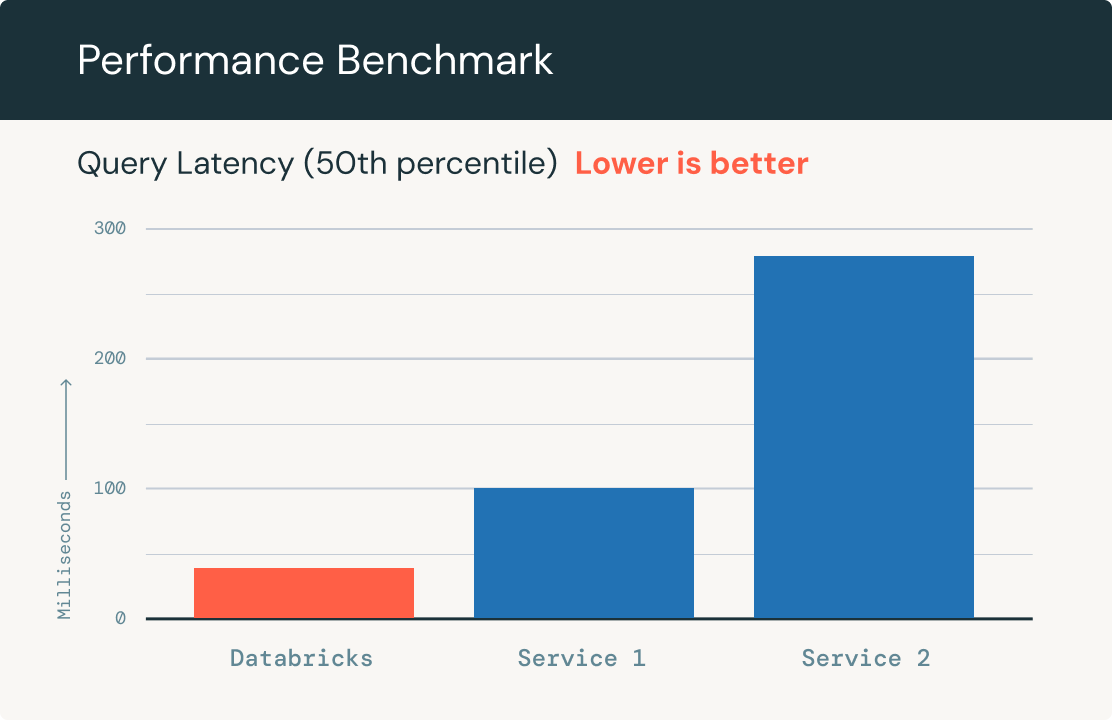
Des requêtes rapides et performantes
Évolue automatiquement pour traiter des milliards d'intégrations dans un index, ainsi que des milliers de requêtes par seconde. Elle délivre ainsi des performances jusqu'à 5 fois supérieures à celles des autres bases de données vectorielles sur des datasets contenant jusqu'à 1 million d'intégrations OpenAI.