リアルタイムストリーミング ETL を実現するツール
スケーラブルデータ @ Databricks:Part 1

Data+AI Summit、Spark+AI Summit のアーカイブを視聴できます。こちらのサイトをご覧ください。
現在、多くの企業がビッグデータの活用を目指してデータの継続的収集に取り組んでいます。収集した膨大なデータは、その中から有用な情報をタイムリーに抽出してこそ価値を生み出します。そこで、データ収集パイプラインから行動につながる気づきをリアルタイムに引き出すための継続的アプリケーションの必要性が高まっています。
しかし、実運用に耐える継続的アプリケーションを構築するのは容易なことではなく、開発者はさまざまな課題を解決しなければなりません。その代表例を挙げてみます。
- エンドツーエンドの信頼性と正確性の確保:長期間の継続実行が期待されるデータ処理システムは、各出力とバッチ処理結果との整合性を維持することで、優れた耐障害性が確保されなければなりません。また、異常な動作(アップストリームコンポーネントの障害、トラフィックの急上昇など)を監視し、自動的に対処することで、常にリアルタイムで気づきを得られる状態を保つことも必要です。
- 複雑な変換処理への対応:さまざまな形式のデータ(CSV、JSON、Avroなど)を分析の対象とするには、再構築、変換、集約の処理が必要になります。そのためには、バッチ処理に使用する従来のツールが利用できるだけでなく、利用時の処理の遅延を防ぐ必要があります。
- データ遅延および順不同データの処理:システムの実運用に際しては、データの読み込みに遅延が発生したり、データ順が想定と異なったりということが頻繁に起こります。その結果、新しい情報が収集されるたびに、集約処理などの複雑なコンピューティングは、継続的かつ正確な修正が必要です。
- 他のシステムとの統合:Kafka、HDFS、S3 等、データソースが多様化することから、全体��を対象とするためにはそれらの統合が必要になります。
Spark SQL を基盤とする Apache Spark 構造化ストリーミングは、強力な API を使用するシームレスなクエリインターフェースを提供し、さらに、実行エンジンの最適化によって、継続的で低レイテンシなクエリ結果の更新を実現しています。このブログは、Apache Spark 2.1 の新しい機能がどのように上記の課題に対処し、独自の実運用水準のパイプラインを構築するかを解説するシリーズ最初の投稿です。
この最初の投稿では、AWS CloudTrail の未加工の監査ログを JIT データウェアハウスに変換し、アドホッククエリを高速化する ETL パイプラインに焦点を当てます。そして、データブリックスの構造化ストリーミング(streaming)を使用することで、既存の ETL バッチジョブを取得し、リアルタイムのストリーミングパイプラインとして運用することがいかに容易であるかを解説します。このパイプラインを使用した結果、私たちは 79 億件のレコードを含んだ 380 万の JSON ファイルが Parquet テーブルに変換することができました。これにより、Parquet テーブルは常に最新に更新されるうえ、アドホッククエリの実行速度が元の JSON ファイルの場合に比べ 10 倍高速になりました。
ETL とは
あまり詳しくない方のために、ETL とは何かを説明しておき�ましょう。ETL とは、データ処理の際に重要な要素である、抽出(Extract)、変換(Transform)、ロード(Load)の頭文字をとったものです。近年、システムにはユーザーのアクセスログや登録情報などの大量のデータが蓄積するようになっていますが、それらは基本的に ETL 処理を行わなければ分析・活用することができません。なぜなら、データの場所やフォーマットなどがバラバラになっている状態では、単一のシステムで管理することができないからです。ETL 処理を行うことで、BI ツールで分析をするなど、蓄積したデータを利用可能な状態にすることができるのです。また、ELT 処理を自動化するためにはデータパイプラインの構築が欠かせません。データパイプラインとはその名のとおり、データを輸送する経路のようなものです。適切なデータパイプラインを構築することができれば、ELT 処理するデータを手動で選択して加工するのではなく、自動的に取得したデータをあらかじめ決めたルールに従って利用可能な形に変換し、データを利用するまでの手間を削減することができるようになります。
ストリーミング ETL の必要性
データの抽出、変換、ロードを行う ETL パイプラインでは、未加工の非構造化データを、効率的なクエリが可能な形式に変換することが必要です。具体的には次のような内容が期待されます。
- データのフィルタリング、変換、クリーニング:未加工のデータは通常は煩雑なままであり、定義済みの構造化形式に合致するようにクリーニングを行う必要があります。例えば、タイムスタンプ文字列を構文解析して日付/時刻形式に変換(比較処理の��効率を改善)、破損したデータのフィルタリング、複雑なデータ構造の整理(ネスト化、ネスト解除、平坦化により重要な列を基準とする)などを行います。
- 効率的なストレージ形式への変換:テキスト、JSON、CSV のデータは生成しやすく、人間による判読も可能です。ただし、クエリ実行時の負荷が高くなります。より効率的な、Parquet、Avro、ORCといった形式に変換することで、ファイルサイズの削減と処理速度の向上が可能になります。
- 重要な列を基準としたデータ区分:1 つないし複数の列の値を基準としてデータを区分することで、データセット全体ではなく関連する少数のデータのみを読み込めるようになり、通常のクエリに対する応答が速くなります。
従来、ETL(extract/transform/load)は、定期的なバッチジョブとして実行されてきました。例えば、未加工のデータをリアルタイムにダンプし、数時間ごとに構造化データに変換して、効率的なクエリ実行を行えるようにしていたのです。当初のシステムはこのような形で構成されていましたが、この方法では大きなレイテンシが発生します。有用な洞察が得られるまで数時間のタイムラグが発生するのです。ほとんどのユースケースでは、このような遅延は受け入れられません。アカウントで何らかの問題発生が危惧される場合、即座にクエリを実行して調査する必要があります。インシデント対応においては、数時間から数分のタイムラグが、取り返しのつかない遅延に繋がる可能性もあるのです。
構造化ストリーミングであれば、このような定期的なバッチジョブをリアルタイムのデータパイプ�ラインに容易に変換することができます。また、同一の API でストリーミングジョブとバッチデータの両方を扱うことが可能です。さらに、この構造化ストリーミングエンジンでは、定期的なバッチジョブの実行時と同様の耐障害性とデータ整合性が保証されるうえ、エンドツーエンドでのレイテンシも低下します。
ここからは、AWS CloudTrail の監査ログを、区分された Parquet のデータウェアハウスに変換して、効率的に利用する方法について解説します。AWS CloudTrail では、gzip 圧縮された JSON ログファイルを S3 バケットに配信することで、さまざまな AWS アカウントで実行されるアクションを追跡できます。このログファイルは、原価配分やセキュリティ監視に活用でき、さまざまなビジネスやミッションクリティカルなインテリジェンスを実現します。ただし、このファイルは元の形式では、Apache Spark を使用してもクエリ実行時の負荷が非常に大きくなります。そこで、有用な情報を迅速に取得するため、常時稼働アプリケーションを実行して、未加工の JSON ログファイルを最適化された Parquet テーブルに変換します。では、そのためのパイプラインの作成方法について、詳しく見てみましょう。完全なコードを確認したい場合は、Notebook を利用してください(Scala および Python)。データブリックスにインポートして実行できます。
構造化ストリーミングによる未加工ログの変換
まず、CloudTrail のドキュメントに基づいて、JSON レコードのスキーマ定義から始めます。
スキーマ全体については、添付の Notebook を確認してください。このコードにより、S3 バケット上に作成された CloudTrail ファイルのデータストリームを示すストリーミング DataFrame を定義できます。
rawRecords DataFrame について理解するには、まず構造化ストリーミングのプログラミングモデルについて確認するのがよいでしょう。把握しておくべきポイントは、データストリームが無限に追加されるテーブルとして扱われているという点です。つまり、ストリームにレコードが新たに追加されると、テーブルに行が追加されたものとしてとらえられます。
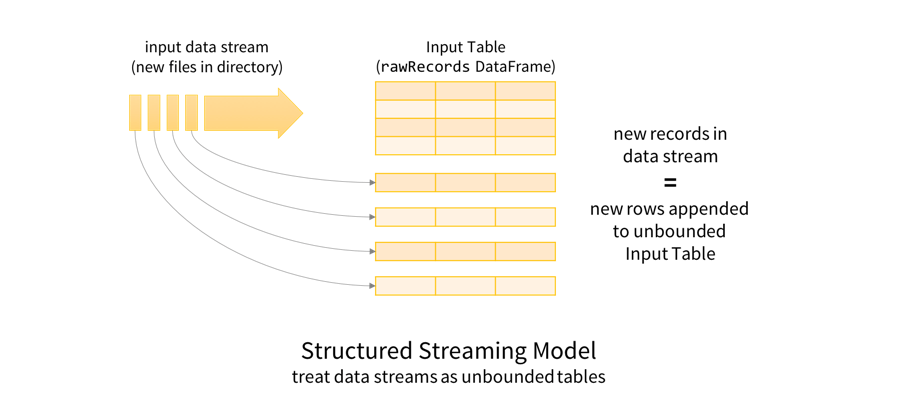
このような仕組みにより、バッチデータとストリーミングデータの両方をテーブルとして扱うことが可能になります。このテーブルと、DataFrame / Dataset は意味的に同義のため、DataFrame や Dataset でバッチ処理と同様のクエリを実行する際にも、バッチデータとストリーミングデータの両方を対象とすることができます。この場合であれば、未加工の JSON データを Spark SQLのネスト化された複雑なスキーマを操作する機能のビルトインサポートを使用して、クエリを実行しやすい形式に変換します。変換処理の要点は、下に示すとおりです。
ここでは、各ファイルから読み込まれたレコードの配列を複数のレコードにexplode(分割)します。また、各レコードのイベントタイム文字列を構文解析して Spark のタイムスタンプ型に変換し、ネスト化された列を平坦化してクエリを実行しやすくしています。なお、cloudtrailEvents がファイルの固定セットに基づいた DataFrame のバッチ処理である場合は、同じクエリを書いたことになるので、結果を一度だけparsed.write.parquet("/cloudtrail") として書き込んでいたことに注意してください。ここでは代わりに、新規データを継続的に順次変換が実行される、StreamingQuery を開始します。
StreamingQuery の開始に際しては、あらかじめ次の内容を設定します。
- タイムスタンプ列から日付を取得する
- 10 秒おきに新しいファイルを確認する(トリガー間隔の設定)
- DataFrame の構文解析から得られたデータを変換し、Parquet 形式のテーブルとして書き出す。書き出し先のパス:
/cloudtrail - Parquet テーブルを日付単位で区分し、データの日付を単位とした効率的なクエリが行えるようにする(アプリケーションの監視を行う際に必須)
- 耐障害性を確保するため、チェックポイント情報を保存する(詳細はブログ後半にて説明します)保存先のパス:
/checkpoints/cloudtrail
以上のクエリ実行の仕組みを、構造化ストリーミングモデルに沿って示すと、下図のようになります。
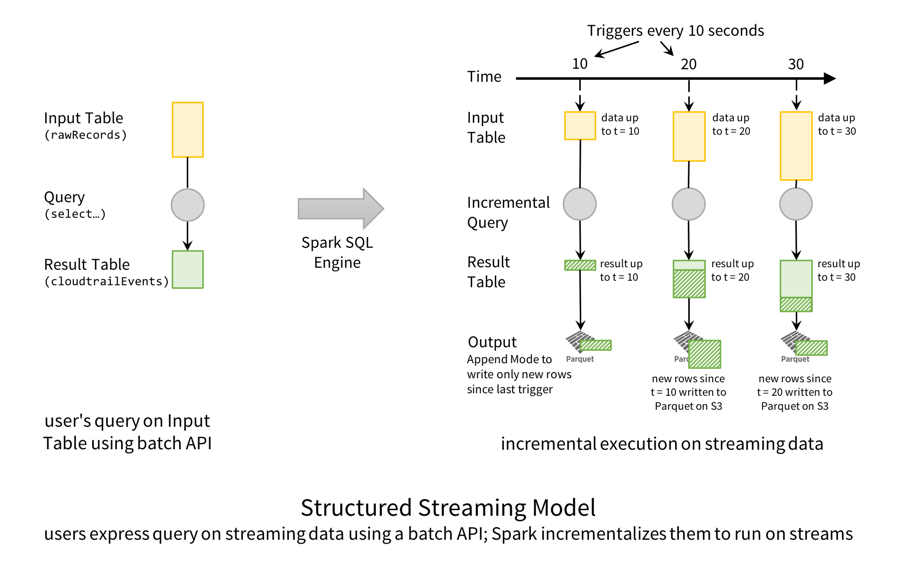
概念としては、rawRecords DataFrame は、追加だけが行われる入力テーブルであり、cloudtrailEvents DataFrame は変換結果が格納される結果テーブルです。別の言い方をすれば、新しい行が入力(rawRecords)に追加されると、結果テーブル(cloudtrailEvents)の新しい行として格納されるということになります。今回取り上げたケースでは、10 秒ごとに Spark SQL エンジンが新しいファイルの確認動作をトリガーし、新しいデータが見つかる(入力テーブルに新しい行がある)と、データを変換して結果テーブルに新しい行を作成します。そして、Parquet ファイルとして出力します。
なお、このストリーミングクエリの実行中にも、Spark SQL を使用して Parquet テーブルに対してクエリを実行できます。ストリーミングクエリでは Parquet データがトランザクションとして生成され、双方向のクエリ処理が並列実行されるようにして、最新のデータが常に整合性を保った形で表示されるようにします。この整合性を確保する仕組みは、プリフィックスの整合性 と呼ばれ、大規模データを扱う常時稼働アプリケーションにおいて、構造化ストリーミングパイプラインとの整合性を確保します。
構造化ストリーミングモデルの詳細と、他のストリーミングエンジンと比較については、こちらの以前のブログをご覧ください。
実運用時の課題の解決
このブログの冒頭で、ストリーミング(streaming)ETL パイプラインの実運用時の課題について取り上げました。ここでは、データブリックスのプラットフォームで構造化ストリーミングを使用することで、それらの課題がどのように解決されるかを確認します。
「厳密に 1 回」の処理で耐障害性をサポート
長時間継続的に実行されるパイプラインについては、耐障害性を確保する必要があります。構造化ストリーミングを使用すれば、クエリのチェックポイ��ントを指定するだけで容易に一定の耐障害性を実現できます。先に紹介したコードスニペットでは、下のコードでチェックポイントを指定しています。
このチェックポイントディレクトリはクエリごとにあり、クエリがアクティブな間はSparkは処理されたデータのメタデータをチェックポイントディレクトリに継続的に書き込みます。仮にクラスタ全体に障害が発生したとしても、同じチェックポイントディレクトリを使用して、新しいクラスタでクエリを再起動し、整合性を損なうことなく復旧できます。すなわち、Spark は、新たなクラスタで、メタデータをもとに、中断した箇所から新たなクエリを開始して、エンドツーエンドの「厳密に1回」の処理の保証とデータの整合性を確保します。(耐障害性について詳しくはこちらのブログで解説しています。)
さらに、同じ仕組みにより、入力ソースと出力スキーマが同じである限り、再起動の間にクエリをアップグレードすることができます。Spark 2.1 以降では、将来に渡って互換性を維持するために、チェックポイントデータをJSON でエンコードしています。したがって、Spark のバージョンを更新した後でも、クエリを再開することが可能です。更新の状況にかかわらず、耐障害性と整合性が維持されます。
なお、データブリックスを使用することで、自動復元の設定が簡単に行えます。詳細については、次の項目であらためて説明します。
モニタリング、アラート、アップグレード
継�続的に使用するアプリケーションの正常な実行を維持するには、個々のマシンの不具合やクラスタ全体の障害による影響を最低限に抑える必要があります。データブリックスでは、構造化ストリーミングとの緊密な統合を開発しました。ストリーミングクエリを継続的に監視し、障害時には自動的に再起動することが可能です。新しいジョブの作成後、再試行ポリシーを設定するだけでこのような機能が利用できます。また、障害時に通知を送るように設定することもできます。
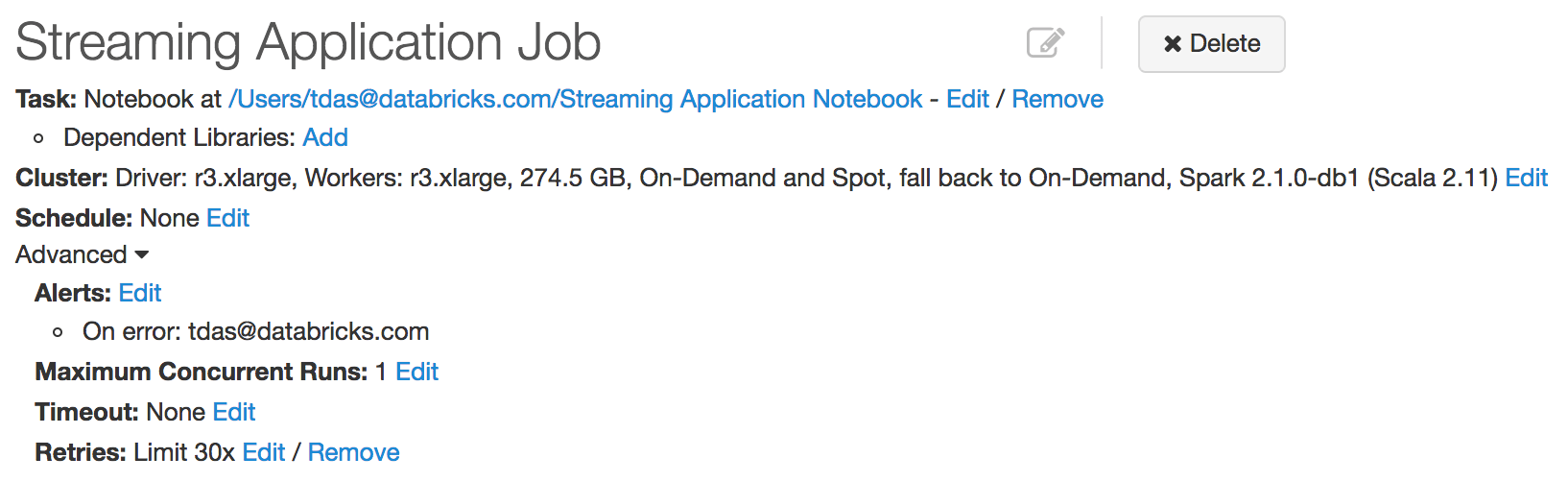
アプリケーションのアップグレードも容易です。コードまたは Spark のバージョンを更新し、ジョブを再起動するだけです。詳細については、実運用時の構造化ストリーミングの実行に関するガイドを参照してください。
安定した処理の確保が求められるのは、マシン障害などの場面だけではありません。トラフィックの急激な増加やアップストリームの問題も監視する必要があります。詳細については、今後のブログ投稿で取り上げます。
ライブデータと履歴/バッチデータの統合
アプリケーションによっては、ライブデータを履歴データやバッチデータと組み合わせる必要があります。例えば、変換処理が行われていないログが大量に残っており、そこに新しい監査ログが入ってくる場合などです。最新データに対しては双方向のクエリが可能で、将来的な分析に備えて履歴データにもアクセスできる状態が理想ですが、そのようなパイプラインを用意するのは簡単なことではありません。既存のほとんどのシステムでは、履歴データを変換するバッチジョブ、ライブデータを変換するストリーミングパイプラインなど、複数のプロセスが必要になります。それぞれのデータを組み合わせるには、さらに別の手順も必要になるかも知れません。
構造化ストリーミングを使用すれば、このような問題が解消できます。上記のクエリを構成して、新しいデータファイルは都度優先的に処理し、クラスタの空き容量を使って既存のファイルを処理することができます。まず、ファイルソースに対して latestFirstオプションを true に設定し、新しいファイルが優先的に処理されるようにします。次に、maxFilesPerTrigger に処理されるファイル数の上限を指定しますこのように設定することで、ダウンストリームのデータウェアハウスがより頻繁に更新されるようになり、クエリの実行に対して常に最新データが利用できるようになります。さらに、次のようにして rawLogsDataFrame を定義します。
以上で、ライブデータと履歴データを簡単に統合できる単体のクエリが作成できます。レイテンシが低く、効率性とデータ整合性も維持できます。
まとめ
Apache Spark の構造化ストリーミングは、ストリーミング ETL パイプラインを作成するうえで最適なフレームワークです。そして、データブリックスとい�うツールを活用することで、大規模環境での運用を容易に実現できます。このブログでは、ストリーミング ETL パイプラインを用意して実運用を行う際のETL(抽出、変換、書き込み)、クエリ実行の手順について概要を説明しました。また、大規模ストリーミングパイプラインにおいて遅延を抑えながら運用する際の課題を、構造化ストリーミングによって解決する方法についても取り上げました。
今後のブログ投稿では、次のような他の課題に対処する方法についても説明する予定です。
- ネストされた JSON データに対する複雑な変換処理
- Apache Spark 2.2 の構造化ストリーミングを使用した Apache Kafka でのデータ処理
- ストリーミングアプリケーションの監視
- 構造化ストリーミングと Apache Kafka の統合
- 構造化ストリーミングを使用したイベントタイムの集計
- 1 日 1 回のストリーミングジョブ実行でコストを 10 分の 1 に削減する方法
構造化ストリーミングについてさらに詳細を確認したい場合は、下のリンクをご覧ください。
- 構造化ストリーミングの狙いと概念について説明した過去のブログ記事
- Apache Spark 2.1 構造化ストリーミングプログラミングガイド
- Spark Summit 2016 トーク:構造化ストリーミングを掘り下げる
次のステップ
AWS CloudTrail ログで次の Notebook を試用できます。データブリックスへの Notebook のインポートは、こちらから行えます。

