MLflow の概要:機械学習ライフサイクル管理のためのオープンソースプラットフォームとは

MLflow とは、実験の追跡、モデルの管理やデプロイメントといった、機械学習におけるライフサイクルを管理するためのオープンソースのプラットフォームです。機械学習(ML)の開発を経験した人は誰でも、その複雑さを知っています。ソフトウェア開発における通常の懸念事項に加えて、機械学習開発には、複数の新たな懸念が伴います。データブリックスの数百社のお客様に共通する課題として、次のような事柄が挙げられます。
- ツールの種類が多すぎる:データ準備からモデルトレーニングまで、数百のオープンソースツールが機械学習(ML)ライフサイクルの各フェーズに対応しています。しかし、部門が各フェーズで 1 つのツールを選択する従来のソフトウェア開発とは異なり、機械学習では、通常、利用可能な全てのツール(アルゴリズムなど)を試し��て、結果が改善されるかどうかを確認します。そのため、機械学習開発者は数十のライブラリを使用し、本番環境に導入する必要があります。
- 実験の追跡が困難:機械学習アルゴリズムには多数の設定可能なパラメータがあり、単独でも、チームでの作業でも、どのパラメータ、コード、データが各実験に投入されてモデルが作成されたのかを追跡するのは困難です。
- 結果が再現できない:詳細な追跡がないため、同じコードを再び機能させるのに苦労する場面が頻繁に生じます。データサイエンティストがエンジニアにトレーニングコードを渡して本番環境で使用する場合も、過去の作業に遡って問題をデバッグする場合も、機械学習ワークフローの手順を再現することが重要です。
- 機械学習の展開が困難:モデルの本番環境への移行は、実行が必要なデプロイツールや環境が多いため困難な作業です(REST サービス、バッチ推論、モバイルアプリなど)。モデルをライブラリからこれらのツールに移行する標準的な方法はなく、新しくデプロイするごとに新たなリスクが生じます。
機械学習開発のこれらの課題を解決し、従来のソフトウェア開発のように堅牢で、予測可能となり、広く普及するためには、多くの進化を遂げなくてはならないことは明らかです。またこの目的を達成するため、多くの組織が機械学習(ML)ライフサイクルを管理し、簡素化するための社内機械学習プラットフォームの開発を始めました。たとえば、Facebook、Google、Uber は、データの準備、モデルのトレーニング、デプロイを管理するために FBLearner Flow、TFX、Michelangelo を開発してきました。しかし、これらの社内プラットフォームでさえ、制限があります。一般的な機械学習プラットフォームは、少数の組み込みアルゴリズムや単一の機械学習ライブラリしかサポートせず、社内のインフラストラクチャに縛られています。そのためユーザーは、新しい機械学習ライブラリを簡単に活用したり、より広いコミュニティで作業を共有したりすることはできません。
データブリックスは、機械学習ライフサイクルを管理するより良い方法があるという信念のもとに、モジュラープラットフォームとして、MLflow:オープンソースの機械学習プラットフォームを開発しました。MLflow は、本日現在アルファ版としてリリースされています。
MLflow:オープンソースの機械学習プラットフォーム
MLflow は、既存の機械学習プラットフォームにインスパイアされているオープンソースのモジュラープラットフォームであり、次の 2 つの意味でオープンであるように設計されています。
- オープンインターフェイス:MLflow は、任意の機械学習ライブラリ、アルゴリズム、デプロイツール、または言語で機能するように設計されてます。REST API �とシンプルなデータ形式(たとえば、モデルはラムダ関数として表示可能)を中心に構築され、小数の組み込み機能のみを提供するのではなく、さまざまなツールから使用できます。これにより、既存の機械学習コードにMLflowを追加することも簡単になるので、すぐにその恩恵を受けたり、組織内の他のユーザーが実行できる機械学習ライブラリを使用してコードを共有したりすることも簡単にできます。
- オープンソース:データブリックスは、MLflow をユーザーとライブラリ開発者が拡張できるオープンソースプロジェクトとしてリリースしました。さらに、コードをオープンソース化する場合、MLflow のオープンフォーマットを使用すると、ワークフローのステップとモデルを組織間で簡単に共有できます。
MLflow は、現時点ではまだアルファ版ですが、すでに機械学習コードを扱う便利なフレームワークを提供しています。お客様のフィードバックをぜひお聞せください。このブログ投稿では、MLflow の詳細を紹介し、そのコンポーネントについて説明します。
MLflow アルファ版コンポーネント
この最初の MLflow のアルファ版には次の 3 つのコンポーネントがあります。
MLflow Tracking
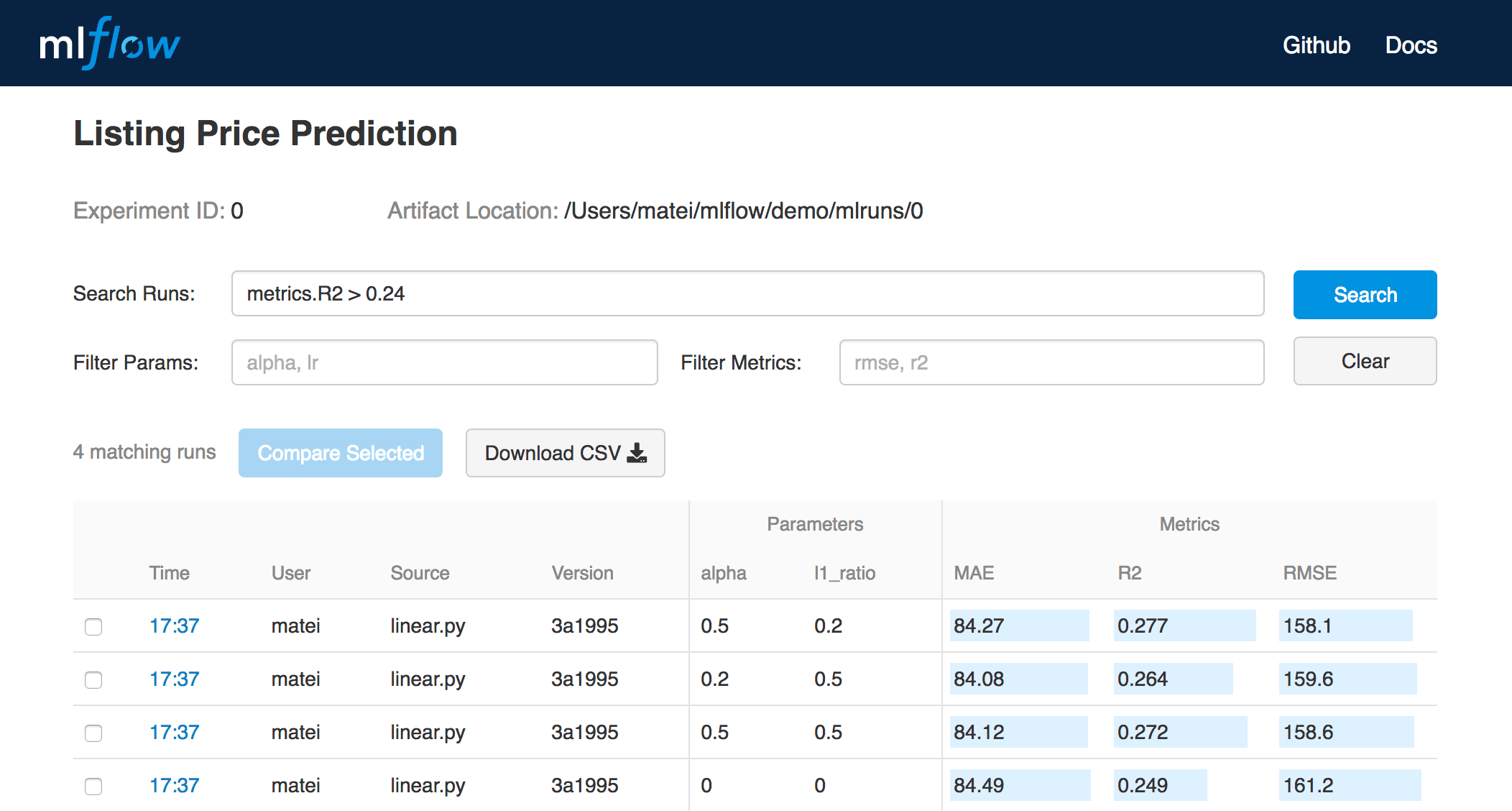
MLflow Tracking 機能は、機械学習コードの実行時にパラメータ、�コードバージョン、メトリック、結果ファイルを記録するための API と UI を提供し、実験の追跡・可視化を支援します。シンプルな数行のコードで、パラメータ、メトリック、アーティファクトを追跡できます。
MLflow Tracking を使用することで、さまざまな環境(スタンドアロンスクリプトやノートブックなど)で、結果をローカルファイルまたはサーバーにログとして記録し、複数の実行を比較できます。また、Web UI を使用して、複数の実行の結果を表示および比較したり、部門内でツールを使用して、異なるユーザーの結果を比較したりすることも可能です。
MLflow プロジェクト
MLflow プロジェクトは、再利用可能なデータサイエンスコードをパッケージ化する標準形式を提供します。各プロジェクトは、コードまたは Git リポジトリを含むディレクトリであり、ファイル記述子を使用して、その依存関係とコードの実行方法を指定します。MLflow プロジェクトは、MLproject と呼ばれるシンプルな YAML ファイルによって定義されます。
プロジェクトは、Conda 環境を介して依存関係を指定できます。また、プロジェクトは名前付きパラメータを使用して、実行を呼び出すた�めの複数のエントリポイントを持つことも可能です。mlflow run コマンドラインツールを使用して、ローカルファイルまたは Git リポジトリからプロジェクトを実行できます。
MLflow は、プロジェクトに適した環境を自動的に設定し、実行します。さらに、プロジェクトで MLflow Tracking API を使用すると、MLflow は実行されたプロジェクトのバージョン(すなわち Git commit)とパラメータを記憶するため、その後、同じコードを簡単に再実行できます。
プロジェクト形式を利用することにより、社内でもオープンソースコミュニティでも、再現可能なデータサイエンスコードを容易に共有できます。MLflow プロジェクトは MLflow Tracking と組み合わせることで、機械学習の構築を効率化し、再現性、拡張性、実験において優れたツールを提供します。
MLflow モデル
MLflow モデルは、「フレーバー」と呼ばれる複数の形式で機械学習モデルをパッケージ化するための規則です。MLflow には、異なるモデルのフレーバーをデプロイするのに役立つさまざまなツールが用意されています。各 MLflow モデルは、任意のファイルと MLmodel で使用できるフレーバーをリストしたファイル記述子を含むディレクトリとして保存されます。
この例では、モデルは sklearn または python_function のいずれかをサポートするツールで使用できます。
MLflow は、多数の一般的なモデルタイプをさまざまなプラットフォームにデプロイするためのツールを提供します。たとえば、python_function フレーバーをサポ��ートするモデルは、Docke rベースの REST サーバー、Azure ML や Amazon SageMaker などのクラウドプラットフォームに対して、Apache Spark のユーザー定義関数としてバッチやストリーミング推論にデプロイできます。Tracking API を使用し、MLflow モデルをアーティファクトとして出力すると、MLflow は、どのプロジェクトから派生したプロジェクトであるのかを自動的に記憶し、実行します。
MLflow の使用を開始する
MLflow は、mlflow.org でインストール、または Github のアルファ版コードから使用を開始できます。是非、コンセプトやコードに関するご意見をお聞かせください。
データブリックスによるマネージド MLflow
If you would like to run a hosted version of MLflow, we are also now accepting signups at databricks.com/product/managed-mlflow. MLflow on Databricks integrates with the complete Databricks Unified Analytics Platform, including Notebooks, Jobs, Databricks Delta, and the Databricks security model, enabling you to run your existing MLflow jobs at scale in a secure, production-ready manner.
次のステップ
MLflow はまだ始まったばかりで、今後さらに展開していきます。まずは、プロジェクトのアップデート以外にも、主要な新しいコンポ�ーネント(監視など)、ライブラリの統合、および既にリリースしたコンポーネントへの拡張機能(たとえば、より多くの環境の種類のサポート)を導入する予定です。今後の MLflow の更新の詳細は、ブログで紹介していく予定です。どうぞご期待ください。
Databricksの投稿を見逃さないようにしましょう
次は何ですか?


データサイエンス・ML
October 30, 2024/1分未満