CrowdStrike Falconのイベントに向けてサイバーセキュリティのレイクハウスの構築

翻訳: Masahiko Kitamura
オリジナル記事: Building a Cybersecurity Lakehouse for CrowdStrike Falcon Events
今すぐDatabricksを導入して、こちらのノートブックを実行してみてください。
エンドポイントデータは、セキュリティチームが脅威の検出、脅威の狩猟、インシデント調査、およびコンプライアンス要件を満たすために必要です。データ量は、1日あたりテラバイト、1年あたりペタバイトになることもあります。ほとんどの組織がエンドポイントログの収集、保存、分析に苦労しているのは、このような大容量のデータに関連するコストと複雑さのためです。しかし、こうである必��要はありません。
この2部構成のブログシリーズでは、Databricksを使用してペタバイトのエンドポイントデータを運用し、高度な分析によってセキュリティ体制を向上させる方法を、コスト効率の良い方法でご紹介します。第1部(このブログ)では、データ収集のアーキテクチャとSIEM(Splunk)との統合について説明します。このブログの最後には、ノートブックが提供され、データを分析に使用する準備が整います。パート2では、具体的なユースケース、MLモデルの作成方法、自動エンリッチメントと分析について説明します。パート2の終わりには、エンドポイントデータを使用して脅威を検出し調査するためにノートブックを実装できるようになります。
ここでは、CrowdstrikeのFalconログを例にして説明します。Falconログにアクセスするには、Falcon Data Replicator(FDR)を使用して、生のイベントデータをCrowdStrikeのプラットフォームからAmazon S3などのクラウドストレージにプッシュすることができます。このデータは、Databricks Lakehouse Platformを使用して、残りのセキュリティ遠隔測定と一緒に取り込み、変換、分析、保存することができます。お客様は、CrowdStrike Falconデータの取り込み、Pythonベースのリアルタイム検知の適用、Databricks SQLによる履歴データの検索、Databricks Add-on for SplunkによるSplunkなどのSIEMツールからのクエリなどが可能です。
Crowdstrikeデータ運用の課題
Crowdstrike Falconのデータは包括的なイベントロギングの詳細を提供しますが、複雑で大量のサイバーセキュリティデータをほぼリアルタイムで取り込み、処理し、費用対効果の高い方法で運用するのは大変な作業です。これらは、よく知られている課題の一部です:
- 大規模なリアルタイムのデータインジェスト: FDRによってクラウドストレージ上にほぼリアルタイムで書き込まれる、処理済みの生データファイルと未処理の生データファイルを追跡することは困難である。
- 複雑な変換: データ形式は半構造化されています。各ログファイルの各行には、管理上異なる種類のペイロードが数百個含まれており、イベントデータの構造は時間の経過とともに変化する可能性があります。
- データガバナンス: この種のデータは機密性が高いため、必要なユーザーだけにアクセスを制限する必要があります。
- セキュリティ分析のエンドツーエンドのシンプル化: 動きの速い大量のデータセットに対して、データエンジニアリング、ML、分析を行うには、スケーラブルなツールが必要です。
- コラボレーション: 効果的なコラボレーションにより、データエンジニア、サイバーセキュリティアナリスト、MLエンジニアの専門知識を活用することができます。このように、コラボレーション・プラットフォームを持つことで、サイバーセキュリティの分析および対応ワークロードの効率が向上します。
その結果、企業内のセキュリティ・エンジニアは、コストと運用効率を管理するのに苦労する難しい状況に陥っています。高価なプロプライエタリ・システムに縛られることを受け入れるか、スケーラビリティとパフォーマンスを追求しながら、膨大な労力をかけて独自のエンドポイント・セキュリティ・ツールを構築するしかない。
Databricks サイバーセキュリティ レイクハウス
Databricksは、セキュリティチームやデータサイエンティストが効率的かつ効果的に業務を遂行するための新たな希望と、ビッグデータや高度な脅威といった増大する課題に対処するための一連のツールを提供します。
データレイクとデータウェアハウスの優れた要素を組み合わせたオープンアーキテクチャであるLakehouseは、データに徐々に構造を追加していくマルチホップのデータエンジニアリングパイプラインの構築を簡素化します。マルチホップアーキテクチャの利点は、データエンジニアが生データから始まるパイプラインを構築できることで、そこからすべてが流れる「単一の真実のソース」となります。Crowstrikeの半構造化された生データは何年も保存することができ、その後の変換や集約はエンドツーエンドのストリーミング方式で行い、データを洗練させてコンテキスト固有の構造を導入し、さまざまなシナリオでセキュリティリスクを分析・検出することができます。
- データのインジェスト: Autoloader (AWS | Azure | GCP) - Crowdstrike FDRによって新しいファイルが生データストレージに書き込まれると、すぐにデータを読み込むのに役立ちます。クラウド通知サービスを活用し、新しいファイルがクラウド上に到着するとインクリメンタルに処理します。Autoloaderはまた、新しいファイルのための通知サービスを自動的に構成してリッスンし、1秒間に数百万ファイルまでスケールアップすることができます。
- ストリームとバッチの統合処理: Delta Lake - データレイクにデータ管理とガバナンスをもたらすオープンなアプローチで、膨大な量のデータとメタデータに対してApache Sparkの™分散計算能力を活用します。DatabricksのDelta Engineは、1秒間に数百万件のレコードを処理できる高度に最適化されたエンジンです。
- データガバナンス: Databircksのテーブルアクセス制御 (AWS | Azure | GCP) - 管理者はユーザーのビジネス機能に基づいてデルタテーブルへの異なるレベルのアクセス権を付与することができます。
- セキュリティ解析ツール: Databricks SQL - 異常なパターンが検出された場合に自動的にアラートを出すインタラクティブなダッシュボードを作成するのに役立ちます。また、Tableau、Microsoft Power BI、LookerなどのBIツールとも簡単に統合することができます。
- Databricksノートブックでの共同作業: Databricksのコラボレーティブノートブックにより、セキュリティチームはリアルタイムでコラボレーションを行うことができます。複数のユーザーが同じワークスペース内で複数の言語でクエリーを実行し、ビジュアライゼーションを共有し、コメントすることで、調査を円滑に進めることができます。
ガートナー®: Databricks、クラウドデータベースのリーダー

Crowdstrike Falconのデータを扱うLakehouseアーキテクチャ
CrowdstrikeのFalconデータなどのサイバーセキュリティのワークロードには、以下のレイクハウ�スアーキテクチャを推奨します。AutoloaderとDelta Lakeは、クラウドストレージから生データを読み込んでデルタテーブルに書き込むプロセスを、低コストかつ最小限のDevOps作業で簡素化します。
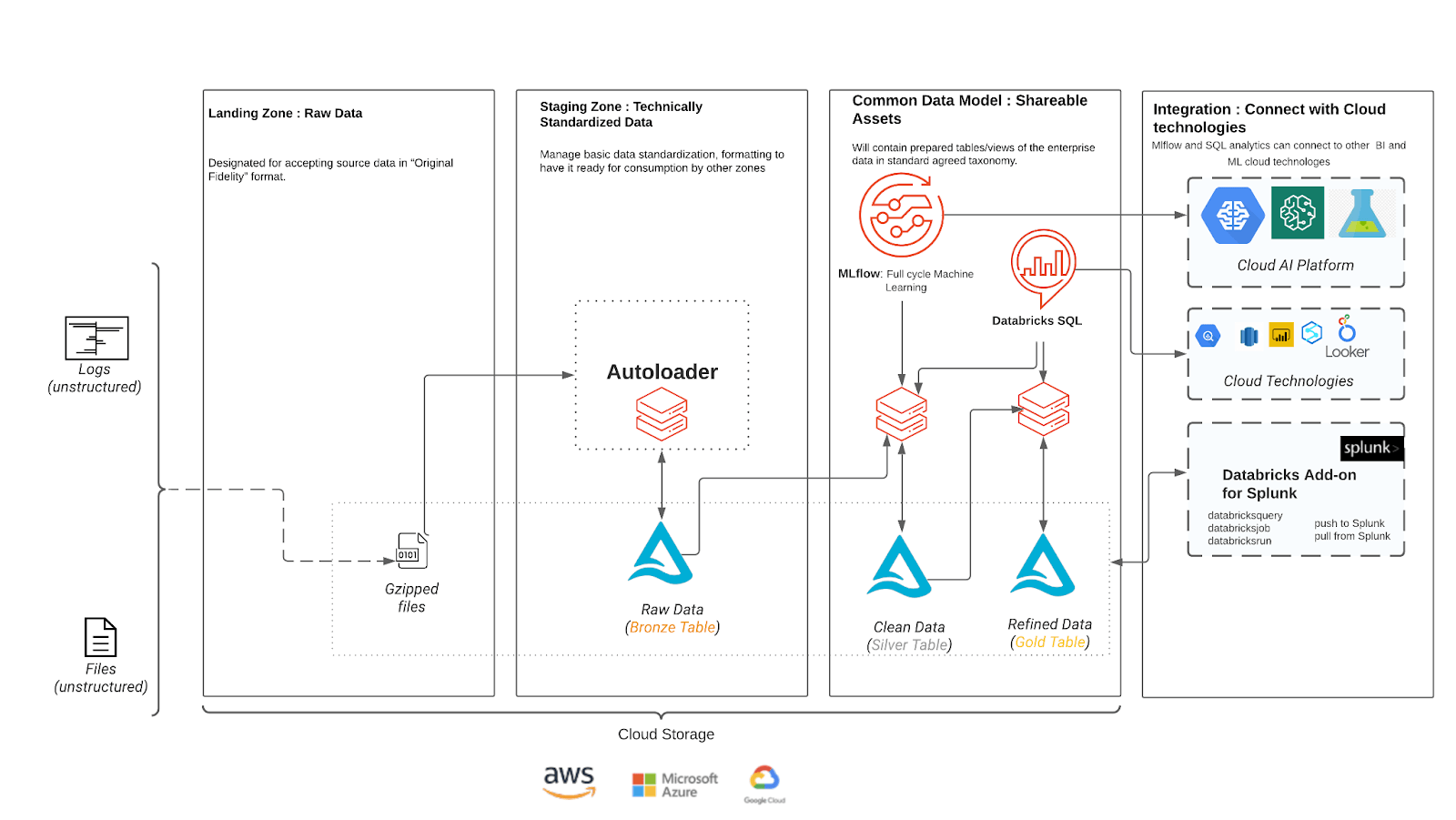
このアーキテクチャでは、半構造化されたCrowdstrikeのデータは、ランディングゾーンで顧客のクラウドストレージにロードされます。その後、Autoloaderはクラウド通知サービスを利用して、新しいファイルの処理と顧客のブロンズテーブルへの取り込みを自動的に開始します。このテーブルは、すべての下流ジョブの単一真実源として機能します。Autoloaderは、データの重複処理を防ぐために、チェックポイントを使用して処理済みファイルと未処理ファイルを追跡します。
ブロンズからシルバーの段階に進むと、データに構造を持たせるためにスキーマが追加されます。単一の真実のソースから読み取るので、異なるイベントタイプをすべて処理し、それぞれのテーブルに書き込まれるときに正しいスキーマを強制することができます。Silver層でスキーマを強制する機能は、MLや分析ワークロードを構築するための強固な基盤を提供します。
ダッシュボードやBIツールでの迅速なクエリやパフォーマンスのためにデータを集約するゴールドステージは、ユースケースやデータ量に応じてオプションで選択できます。アラートは、予期せぬトレンドが観��察されたときに発動するように設定することができます。
もう一つのオプション機能は、セキュリティチームがSplunkの快適さを離れることなく、Databricksの費用対効果の高いモデルとAIのパワーを活用できるようにするSplunk用Databricksアドオンです。お客様は、アドオンにより、Splunkのダッシュボードや検索バー内からDatabricksに対してアドホッククエリを実行することができます。また、SplunkのダッシュボードやSplunkの検索に対応して、Databricksのノートブックやジョブを起動することができます。Databricks の統合は双方向で、ノイズの多いデータを要約したり、Splunk Enterprise Security に表示される検出を Databricks で実行することができます。Databricks のノートブックから Splunk の検索を実行することも可能で、データの重複を防ぐことができます。
SplunkとDatabricksの統合により、お客様はスタッフが日々使用しているツールを変更することなく、コストの削減、分析するデータソースの拡大、より堅牢な分析エンジンの結果を提供することができます。
実際のコードで解説
Autoloaderはファイルベースのデータ取り込みの最も複雑な部分を抽象化しているので、数行のコードで生からブロンズまでの取り込みパイプラインを作成することができます。以下は、DeltaインジェストパイプラインのScalaコード例です。Crowdstrike Falconのイベントレコードは、"event_simpleName "という1つの共通フィールド名を持っています。
raw-to-bronze層では、イベント名のみが生�データから抽出されます。ロードタイムスタンプと日付のカラムを追加することで、ユーザーはブロンズテーブルに生データを保存します。ブロンズテーブルは、イベント名とロード日付によってパーティショニングされており、特に限られた数のイベント日付範囲に関心がある場合、ブロンズからシルバーへのジョブがより高いパフォーマンスを発揮するのに役立ちます。
次に、ブロンズからシルバーへのストリーミングジョブは、ブロンズテーブルからイベントを読み込み、スキーマを実施し、イベント名に基づいて数百のイベントテーブルに書き込みます。以下は、Scalaのコード例です:
各イベントスキーマは、スキーマレジストリや、スキーマを複数のデータドリブンサービス間で共有する必要がある場合に備えて Delta テーブルに保存することができます。上記のコードでは、ブロンズテーブルから読み込んだサンプルのjson文字列を使用しており、スキーマはschema_of_json()を使用してjsonから推論されることに留意してください。その後、from_json()を使ってjson文字列を構造体に変換しています。そして、構造体を平坦化し、タイムスタンプ列を追加する。これらの手順により、イベントテーブルに追加するために必要なすべてのカラムを持つデータフレームができあがります。最後に�、この構造化データを append モードでイベント テーブルに書き込みます。
また、マイクロバッチを処理する関数を定義することにより、foreachBatchで1つのストリームで複数のテーブルにイベントをファンアウトすることが可能です。foreachBatch()を使えば、既存のバッチデータソースを再利用して、複数のテーブルへのフィルタリングや書き込みを行うことが可能である。しかし、foreachBatch()は、最低1回の書き込み保証しか提供しない。そのため、actly-onceセマンティクスを強制するためには、手動での実装が必要となる。
この段階で、構造化されたデータは、Databricksのノートブックやジョブでサポートされているどの言語でもクエリできます: Python、R、Scala、SQLなどです。シルバーレイヤーデータは、MLやサイバー攻撃解析に利用するのに便利です。
次のストリーミングパイプラインは、シルバーからゴールドになります。この段階では、ダッシュボードやアラートのためにデータを集約することが可能です。このブログシリーズの第2部では、Databricks SQLを使ってダッシュボードを構築する方法について、もう少し詳しく説明します。
What’s next
MLを適用し、Databricks SQLを使用することで、このユースケースにさらなる価値を構築するブログ記事にご期待ください。
これらのnotebooks は、ご自身のDatabricksのデプロイメントで使用することができます。ノートブックの各セクションにはコメントがあります。ぜひ、[email protected] までメールをお寄せください。このノートブックをより理解しやすく、展開しやすくするためのご質問やご提案をお待ちしています。
では、ご自身のDatabricksアカウントにログインして、これらのノートブックを実行してみてください。皆様のフィードバックとご意見をお待ちしております。
実行するノートブックのインポートの詳しい方法は、ドキュメントを参照してください。
Acknowledgments
We would like to thank Bricksters who supported this blog, and special thanks to Monzy Merza, Andrew Hutchinson, Anand Ladda for their insightful discussion and contributions.