Delta Lake で Databricks にスタースキーマを実装するための簡単な 5 ステップ
Delta Lake を使用して DWH やデータマートに利用されるスタースキーマのデータベースからベストパフォーマンスを常に引き出す方法

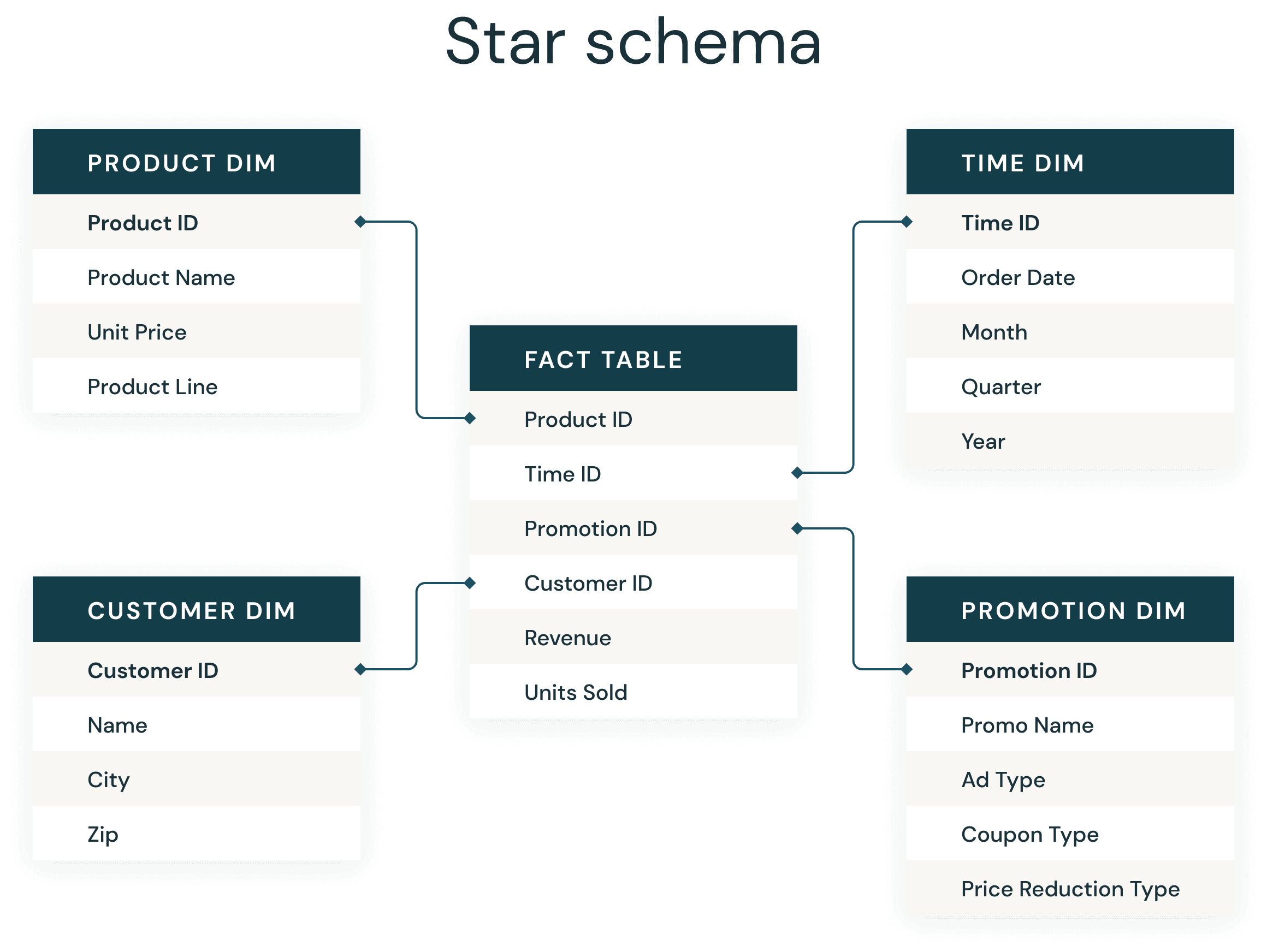
データウェアハウスの開発者の多くは、常に存在するスタースキーマに精通しています。1990 年代にラルフ・キンボールによって紹介されたスタースキーマは、ビジネスデータをディメンション(時間や商品など)とファクト(金額や数量のトランザクション)に非正規化するために使用されます。スタースキーマは、反復的なビジネス定義の重複を減らすことで、データの保存、履歴の維持、更新を効率的に行い、集計とフィルタリングを高速化します。
ビジネスインテリジェンス(BI)アプリケーションをサポートするスタースキーマの一般的な実装は、慣例化し成功しているため、多くのデータモデルの設計者にとってその実装は極めて容易なものになっています。Databricks では、非常に多くのデータアプリケーションを作成しており、経験則によるベストプラクティスのアプローチ、成果につながることを保証する基本的な実装を常に探求しています。
従来のデータウェアハウスと同様に、Delta Lake でもいくつかの簡単な経験則に従うことで、Delta スタースキーマの結合を大幅に改善できます。
ここでは、スタースキーマの実装を成功に導くための基本的なステップをご紹介します。
- Delta テーブルを使用してファクトテーブルとディメンションテーブルを作成する
- 高速なファイルプルーニングのためにファイルサイズを最適化す��る
- ファクトテーブルに Z オーダーを作成する
- ディメンションキーフィールドと最も可能性の高い述語で Z オーダーを作成する
- テーブルを分析して適応型クエリ実行オプティマイザーの統計を収集する
1. Delta テーブルを使用してファクトテーブルとディメンションテーブルを作成する
Delta Lake は、データレイクのテーブルに対して挿入、更新、削除、ACID トランザクションの追加を容易にし、メンテナンスと履歴管理を簡素化するオープンなストレージ形式レイヤーです。Delta Lake は、動的ファイルプルーニングを実行して、より高速な SQL クエリに最適化する機能も提供しています。
Databricks Runtimes 8.x 以降のバージョンでは、Delta Lake がデフォルトのテーブル形式であるため、構文はシンプルです。SQL を使用して Delta テーブルを作成するには、次のようにします。
Databricks Runtime 8.x 以前のバージョンでは、USING DELTA 構文を指定してテーブルを作成する必要がありました。
2. 高速なファイルプルーニングのためにファイ��ルサイズを最適化する
Apache Spark™ のクエリで最も時間がかかるのは、クラウドストレージからのデータ読み込みと、基盤となるファイルを全て読み込む必要があることです。Delta Lake のデータスキッピングにより、クエリは関連データを含む Delta ファイルのみを選択的に読み込み、時間を大幅に節約できます。データスキッピングは、静的ファイルプルーニング、動的ファイルプルーニング、静的パーティションプルーニング、動的パーティションプルーニングに有効です。
データスキッピングを設定する際にまず考慮すべきことの 1 つは、理想的なデータファイルサイズです。データファイルサイズが小さすぎるとファイル数が多くなりすぎ(よく知られている「スモールファイル問題」)、大きすぎると十分なデータをスキップできなくなります。
ファイルサイズの目安は、32 ~ 128 MB(もちろん 32 MB は 1,024x1,024x32 = 33,554,432)です。繰り返しになりますが、ファイルサイズが大きすぎる場合、動的ファイルプルーニングは正しいファイルまたは複数のファイルにスキップしますが、ファイル自体が非常に大きいため、依然として多くの処理が必要になるという考え方です。より小さなファイルを作成することで、ファイルプルーニングの恩恵を受け、結合に必要なデータを取得する I/O を最小限に抑えることができます。
Python でノートブック全体のファイル�サイズ値を設定できます。
あるいは、SQL で。
また、特定のテーブルにのみ設定することも可能です。
もし、既にテーブルを作成した後にこの記事を読んでいる場合でも、ファイルサイズをテーブルのプロパティに設定すれば、最適化と Z オーダー作成時に、ファイルは新しいファイルサイズに比例して作成されます。既に Z オーダーを追加している場合は、最終的な Z オーダーの設定に至る前に、列の追加や削除を行い、強制的に書き直すことができます。Z オーダーについては、ステップ 3 で詳しく説明します。
ファイルサイズについての詳細は、こちらからご覧ください。SQL に加えて Python や Scala を使用される方のために、完全な構文はこちらに掲載されています。
Databricks の機能追加に伴い、テーブルサイズに応じたファイルサイズの自動調整も可能です。小規模なデータベースでは、上記の設定がより良いパフォーマンスを提供すると思われますが、大規模なテーブルやよりシンプルにするためには、こちらのガイダンスに従って、テーブルプロパティ delta.tuneFileSizesForRewrites を実装できます。
3. ファクトテーブルに Z オーダーを作成する
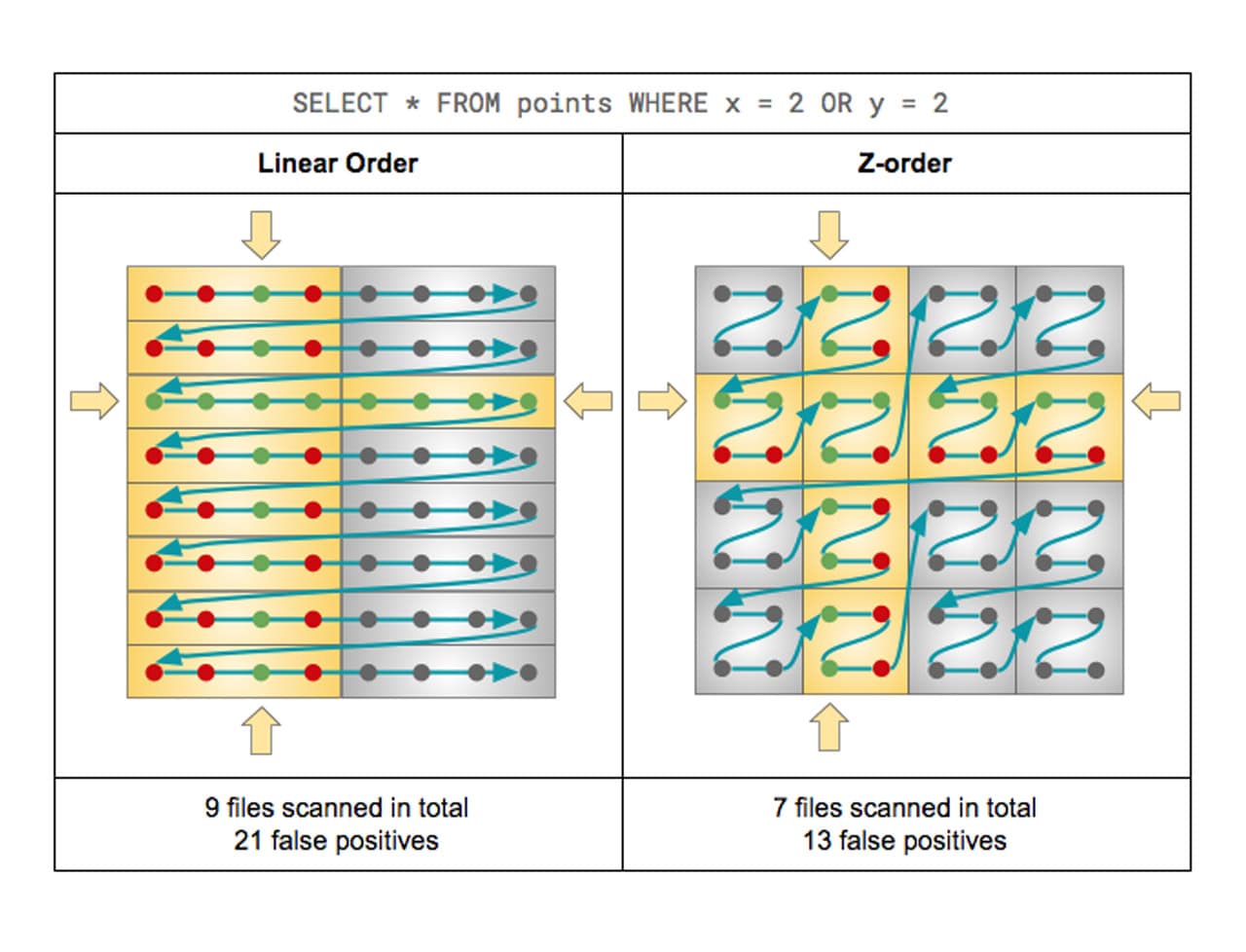 Delta Lake は、クエリ速度を向上させるために、マルチディメンションクラスタリングとしても知られる Z オーダーを使用してクラウドストレージに保存されたデータのレイアウトを最適化する機能をサポートしています。Z オーダーは、データベースの世界ではクラスタ化インデックスと同じような場面で使用されますが、実際には補助構造ではありません。Z オーダーは、Z オーダー定義のデータをクラスタリングし、Z オーダー定義の列値のような行ができるだけ少ないファイルに配置されるようにします。
Delta Lake は、クエリ速度を向上させるために、マルチディメンションクラスタリングとしても知られる Z オーダーを使用してクラウドストレージに保存されたデータのレイアウトを最適化する機能をサポートしています。Z オーダーは、データベースの世界ではクラスタ化インデックスと同じような場面で使用されますが、実際には補助構造ではありません。Z オーダーは、Z オーダー定義のデータをクラスタリングし、Z オーダー定義の列値のような行ができるだけ少ないファイルに配置されるようにします。
ほとんどのデータベースシステムは、クエリのパフォーマンスを向上させる方法として、インデックスを導入しています。インデックスはファイルであるため、データのサイズが大きくなると、インデックス自体が解決すべき別のビッグデータ問題になりかねません。一方、Delta Lake では、Parquet ファイル内のデータを順序付けして、オブジェクトストレージ上での範囲選択をより効率的に行います。統計情報の収集プロセスとデータスキッピングを組み合わせることで、インデックス��が解決したデータベースにおけるシーク操作とスキャン操作と同様に、Z オーダーはクエリが探しているデータを見つけるために別の計算ボトルネックを作ることはありません。
Z オーダーの場合、ベストプラクティスは、Z オーダーの列数をベスト 1 ~ 4 に制限することです。ワーカーノードにブロードキャストするには大きすぎる 3 つの最大のディメンションの外部キー(使用する外部キーであり、実際に強制された外部キーではない)を選択しました。
また、ファクトテーブルのデータが数千億行やペタバイトと非常に大規模な場合は、ファイルスキッピングをさらに向上させるためにパーティショニングを検討する必要があります。パーティションは、パーティショニングされたフィールドでアクティブにフィルタリングを行う場合に有効です。
4. ディメンションキーフィールドと最も可能性の高い述語で Z オーダーを作成する
Databricks は Delta テーブルに主キーを強制しませんが、ディメンションに整数型や多倍長整数型の検証済みでユニークであることが期待されるサロゲートキーが存在していることもあるでしょう。
あるディメンションは 10 億行を超えていましたが、Z オーダーに述語を追加した後、ファイルスキッピングと動的ファイルプルーニングの恩恵を受けました。また、小さいディメンションにもディメンションキーフィールドに Z オーダーがあり、ファクトへの結合でブロードキャストされました。ファクトテーブルに Z オーダーを作成する際と同�様に、Z オーダーの列数は、キーに加えてフィルターに含まれる可能性が最も高いディメンションの 1 ~ 4 フィールドに制限してください。
5. テーブルを分析して適応型クエリ実行オプティマイザーの統計を収集する
Apache Spark™ 3.0 の大きな改善の 1 つが、適応型クエリ実行(AQE:Adaptive Query Execution)です。Spark 3.0 における AQE の主要な機能には、シャッフル後のパーティションの統合、ソートマージ結合のブロードキャスト結合への変換、スキュー結合の最適化が含まれます。これらの機能を組み合わせることで、Spark でのディメンションモデルの高速化が可能になります。
AQE がどのプランを選択するかを知るには、テーブルに関する統計情報を収集する必要があります。これを行うには、ANALYZE TABLE コマンドを発行します。お客様からは、テーブルの統計情報を収集することで、複雑な結合を含むディメンションモデルのクエリ実行が大幅に減少したとのご報告をいただいています。
まとめ
上述のガイドラインに従うことで、企業はクエリ時間を短縮できます。ある例では、同じクラスタ上で 90 秒から 10 秒に短縮できました。この最適化により I/O が大幅に削減され、正しいコンテンツのみが処理されるようになりました。また、Delta Lake の柔軟な構造は、BI ツールからアドホックに送信されるクエリの種類に対応し、拡張性も高いという利点があります。
今回ご紹介したファイルスキッピングの最適化に加え、Databricks は Databricks Photon による Spark SQL クエリのパフォーマンス向上にも多大な投��資を行っています。Photon の詳細と、Databricks を使用した Spark SQL クエリのパフォーマンス向上については、こちらをご覧ください。
Databricks Runtime で Photon を有効にすることにより、ETL/ELT や SQL クエリのパフォーマンス向上が期待できます。ここでご紹介したベストプラクティスと Photon 対応の Databricks Runtime を組み合わせることで、最高のクラウドデータウェアハウスを凌駕する低レイテンシのクエリパフォーマンスを実現することが期待できます。


