データレイクにライフサイエンスの知識グラフを構築する

公開日: January 31, 2023
によって Michael Sanky、Vishnu Vettrivel、Alex Thomas、アミール・カーマニー による投稿
本投稿はDatabricksとwisecube.aiの共同によるものです。創業者のVishnu Vettrivel、プリンシパル・データサイエンティストのAlex Thomasへの貢献に感謝します。
Original Blog : Building a Life Sciences Knowledge Graph with a Data Lake
翻訳 : motokazu.ishikawa
製薬企業は世界の最も深刻な疾患のいくつかに対して、画期的な医薬品を発見し開発し市販します。研究開発におけるデータドリブンなアプローチは創薬とともに治験での安全管理の成功率も改善します。しかしながら、この改革における主要な障害は、新しいデータが増加するペースに、科学的な情報を全て活用する能力が追いつかないということです。
研究開発のデータはしばしば何百万のデータポイントと何千のデータソースから生じます。これには、ゲノミクスやプロテオミクスのようなハイスループットな技術、利用が増加している電子健康記録(EHR)、その他のデジタルデータを含みます。これらデータの利用の増加は、生物医学の全ての分野で研究発表数を有意に加速しています。製薬組織にとって、メタアナリシスとも呼ばれるこれら文献の体系的な分析は、研究開発、治験デザインの最適化、そして新薬の市販への道を加速するエビデンスベースメディシンで主要な役割を果たしています。
メタアナリシスにより、治療効果や疾患のリスク因子のより正確な予測が可能となります。また、複雑でたまに矛盾をしていることもある研究体系に、包括的で定量的なレビューのため��のフレームワークを提供します。メタアナリシスに加えて、膨大な文献に対する先端的な分析を適用することは新しい知見の発見に繋がります。例えば、統合された知識ベースに予測手法を用いることにより、既存の手法では見逃されてきたような有益な遺伝変異の同定に至ることがあります。
製薬企業が彼らのメタアナリシスで既存の研究を同定し統合することに失敗したら重大なことになります。それは異なる結論を導き、規制のある研究環境での研究開発の進捗を妨げ、上市が遠のくでしょう。レガシーなデータプラットフォームにしがみついていてはスケールしませんし、データサイロはしばしばその原因となります。
スケールに関する障害を取り除くことで、組織は意味のある発見ができ、人々がより健康は生活を送る手助けとなるような新薬に辿り着けるでしょう。このブログ投稿では、生物��医学研究での知識発見の文脈でのこれらの朝鮮のうちいくつかについて触れ、また、統合されたデータと分析のアプローチがこれらの挑戦を解決するかを述べます。
挑戦 #1 (つなげる): バラバラのデータセットから意味づけをする
ライフサイエンスにおけるデータ量の爆発的な増加を示す典型的な例として、生物医学研究と臨床試験が挙げられるでしょう。2004年から2013年の間に、PubMedには730万以上の雑誌記事が追加され、2003年から48.9%増加しました。
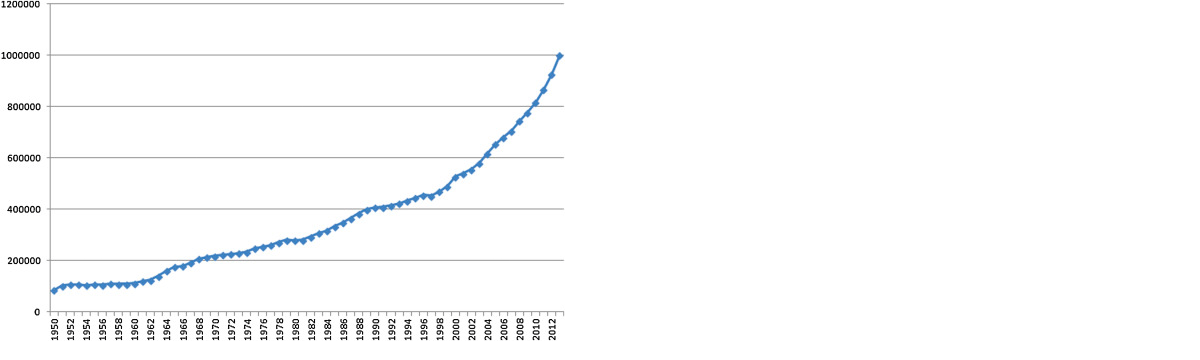
これがPubmedがMeSHのような統制された語彙を採用した主な理由の一つです。MEDLINE/PubMedでは、すべてのジャーナル論文に約10〜15個の主題見出し、副標目、補足用語がインデックスされ、そのうちのいくつかは主要なものとして指定され、その論文の主要な話題を示すアスタリスクが付けられています。
ClinicalTrials.govでは、各治験にその治験を説明するキーワードが設定されています。ClinicalTrials.govチームは、各治験に2組のMeSH用語を割り当てています。一つは、その治験で研究される条件、もう一つは、その治験で使用される介入策のセットです。
これにより、研究者は異なるデータソース間で共通の理解とセマンティクスを持つ共通言語を話すことができます。残念ながら、このセマンティックレイヤーは現代のデータレイクでは無視されることが多く、後回しにされることがほとんどです。
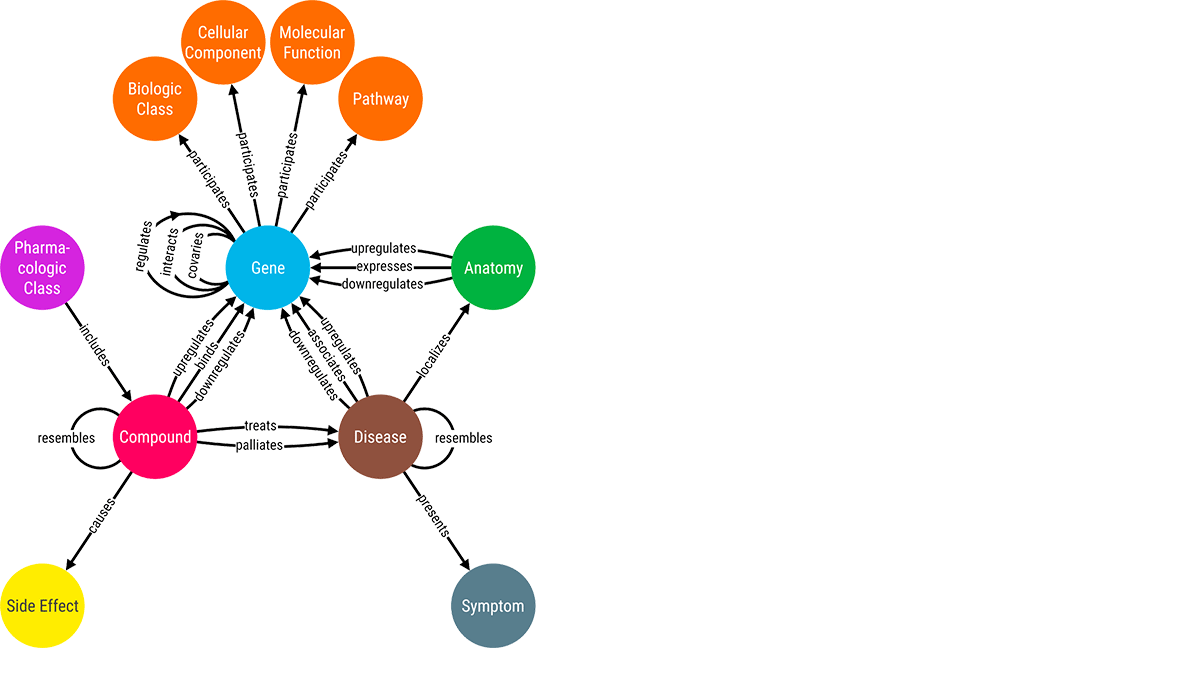
挑戦 #2 (エンリッチ): 接続されたデータから隠された知識を補強し、解き放つ
生物医学データを連結して統合することで、隠れた洞察を素早く取り出すことができます。また、これらの意味論的なネットワークは、エラーを減らし、費用対効果の高い方法で発見をする可能性を高めるのに役立ちます。医療データ間の隠れた相関関係を明らかにするために、アナリストはリンク予測などのさまざまなテクニックを使用します。医療データ間の相関関係を視覚的に探索することで、科学者は繊細な治療の選択肢についてタイムリーに判断することができます。
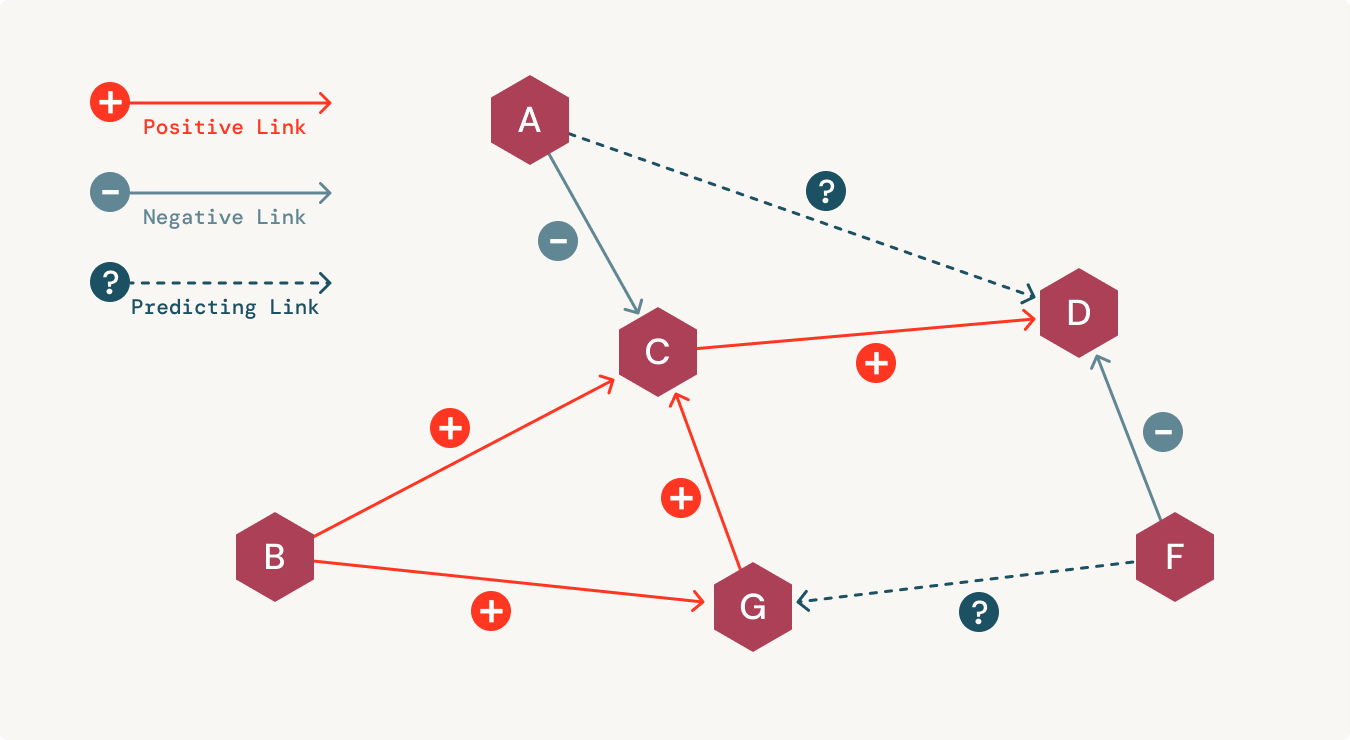
さらに、人工知能(AI)や機械学習(ML)を臨床現場に持ち込む場合、組織はガバナンスをモデル化できる必要があります。残念ながら、ほとんどの組織では、データウェアハウスから切り離されたデータサイエンスワークフローのための個別のプラットフォームを持っています。このため、AIを活用したアプリケーションで信頼性と再現性を築こうとすると、深刻な問題が発生します。そこで、データを説明可能でかつ透明性のある表現で持つことが役立ちます。

挑戦#3(発見): コネクテッドグラフにアクセスし、洞察とアプリケーションを構築する。
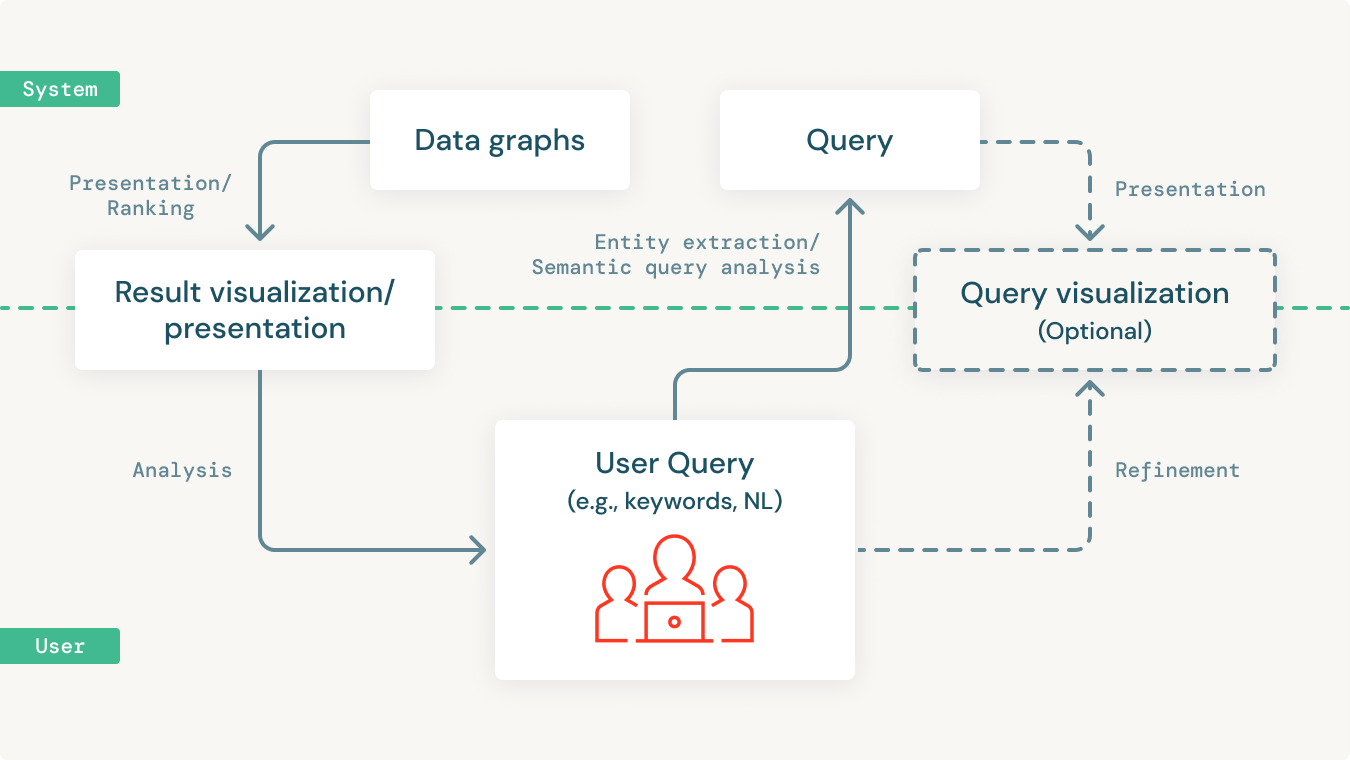
データが知識グラフに一元化されれば、グラフ上で直接、強力なネットワーク分析や予測モデルを構築できるようになるはずです。
さらに重要なことは、組織内の大多数の人がこのデータすべてにアクセスできるようにすることです。どんな組織でも、大多数の人はデータの実務家ではありません。つまり、SQLやSPARQLなどのデータクエリ言語に精通しているわけではありません。このことを考えると、SPARQLのようなオープンスタンダードを使用したクエリや分析機能を提供することが不可欠です。しかし、それ以上に重要なのは、データに詳しくないエンドユーザーがシンプルかつ直感的な方法でこれらのインサイトにアクセスできるようにすることです。
ユーザーが簡単なクエリから始めて、より具体的なニーズに合わせて段階的に複雑にしていく反復プロセスであることが多いです。また、自然言語のキーワードと意味的なエンティティを組み合わせて、強力な方法で知識グラフをクエリしたい場合もあります。
クエリツールは、このような複雑な反復クエリプロセスをサポートし、ドメインエキスパートが知識グラフを段階的にクエリして分析し、洞察を導き出せるようにする必要があります。しかし、今日、多くはこのようなことを行いません。
Delta Lakeを使用して知識グラフを構築する
医療機関やライフサイエンス企業が上記のような課題を解決するために、知識グラフは優れたソリューションとなり得ます。しかし、刻々と変化するデータや、データのバージョン管理、スナップショット、再現性、ガバナンスなどの問題を処理しながら、拡張性、柔軟性、性能に優れたエンタープライズグレードの知識グラフを、主要なデータレイクハウスとして本当に導入するには、新たに克服すべきさまざまな障害が存在します。
そのため、サイロ化されたナレッジグラフデータベースを新たに構築するのではなく、データレイク上に構築することが答えになると強く信じています。この方がコスト効率が良く、データチームが構築、維持、管理するためのオーバーヘッドが少ないだけでなく、データの遅延や同期の問題など、複数のデータソースが持つ典型的な問題を回避できるので、エンドユーザーにとっても良いことだからです。
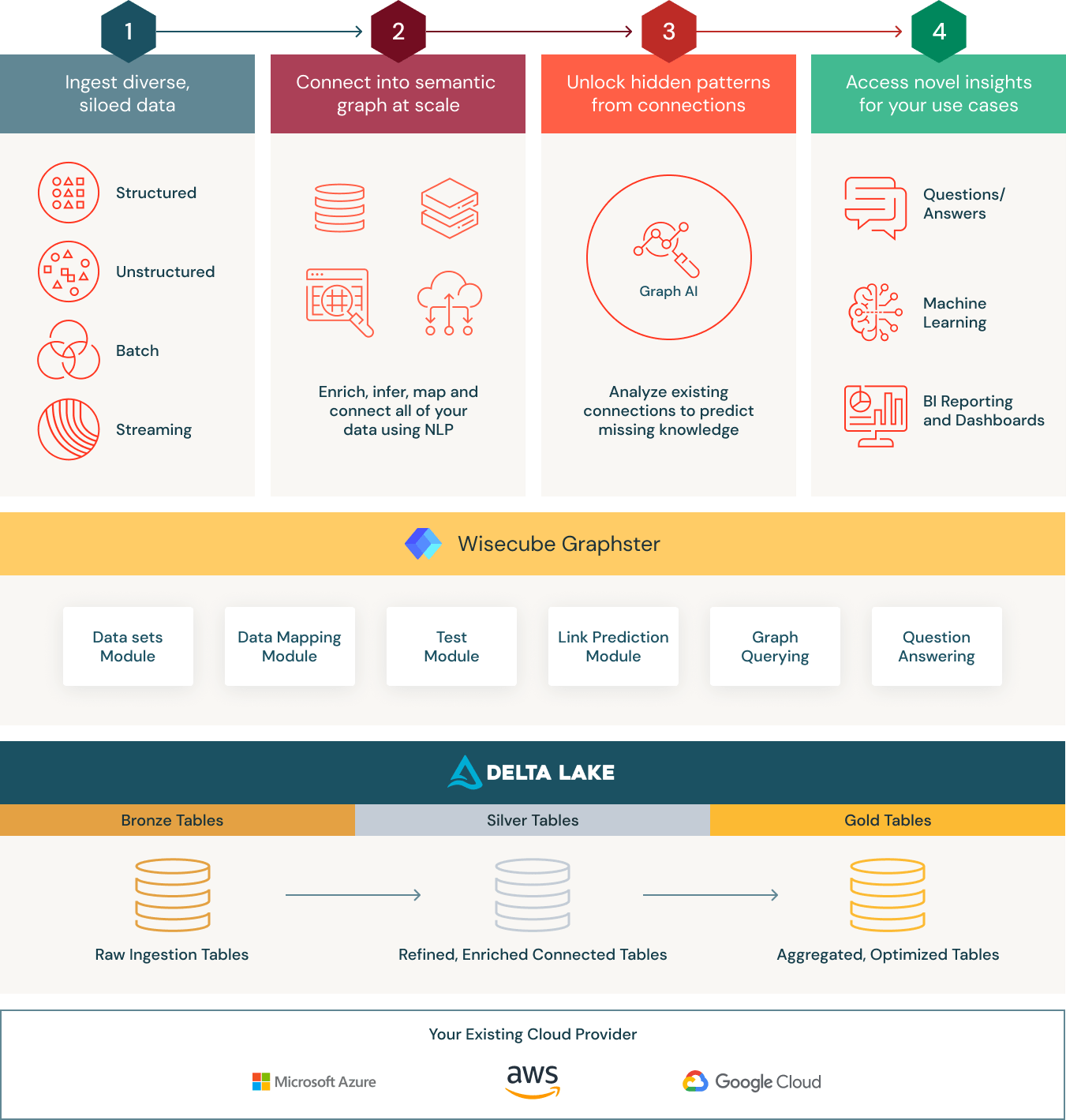
Databricks Lakehouseプラットフォームは、データウェアハウスの優れた要素と、クラウドデータレイクの低コスト、柔軟性、スケールを組み合わせた最新のデータアーキテクチャで、その基盤として機能します。このシ�ンプルでスケーラブルなアーキテクチャにより、医療機関は構造化、半構造化、非構造化といったすべてのデータを、従来のアナリティクスとデータサイエンスのための単一の高性能プラットフォームに集約することができます。
具体的には、Delta Lake上に構築された知識グラフは、ヘルスケアおよびライフサイエンス企業にとって、以下の3つの主なメリットを提供します:
- つなげる: ドメイン固有でありながら柔軟なオントロジーを使用して、すべての研究開発データを整理します。Wisecube Knowledge Graphの中核をなすのは、クラウドデータレイクの信頼性とパフォーマンスを提供するデータ管理レイヤーであるDelta Lakeです。従来のデータウェアハウスとは異なり、Delta Lakeはあらゆる種類の構造化データおよび非構造化データをサポートします。データの取り込みをさらに簡単にするため、ワイズキューブでは臨床試験やMeSHなど、研究開発特有のデータセットに対応したコネクタを構築しています。さらに、WisecubeはグラフクエリとAIのための最適化を内蔵しており、グラフベースの分析を大幅に高速化します。これらの機能により、チームはすべての生データを一箇所に集め、それをキュレーションして、すべての生物医学データの全体像を把握することができます。
- エンリッチ: Wisecube Knowledge Graphは、構造化データおよび非構造化データのための統一されたアーキテクチャを提供します。また、リンク予測などの高度なネットワーク分析によって新たなインサイトを合成できるモジュールも備えています。さらに、ナレッジグラフをすべてDatabricks上で実行することで、組織は処理量に応じた自動スケールを実現できます。
- 発見: SPARQLのようなオープンスタンダードとDatabricksの機能を組み合わせることで、組織は創薬から慢性疾患管理プログラムに至るまで、非常にインパクトのある幅広いユースケースをサポートすることができます。そのため、Wisecube Knowledge Graphはヘルスケアやライフサイエンスのデータを管理するための理想的なデータストアとなっています。
GraphsterとDelta Lakeを使用したヘルスケアおよびライフサイエンス向けの知識グラフの構築を開始しましょう
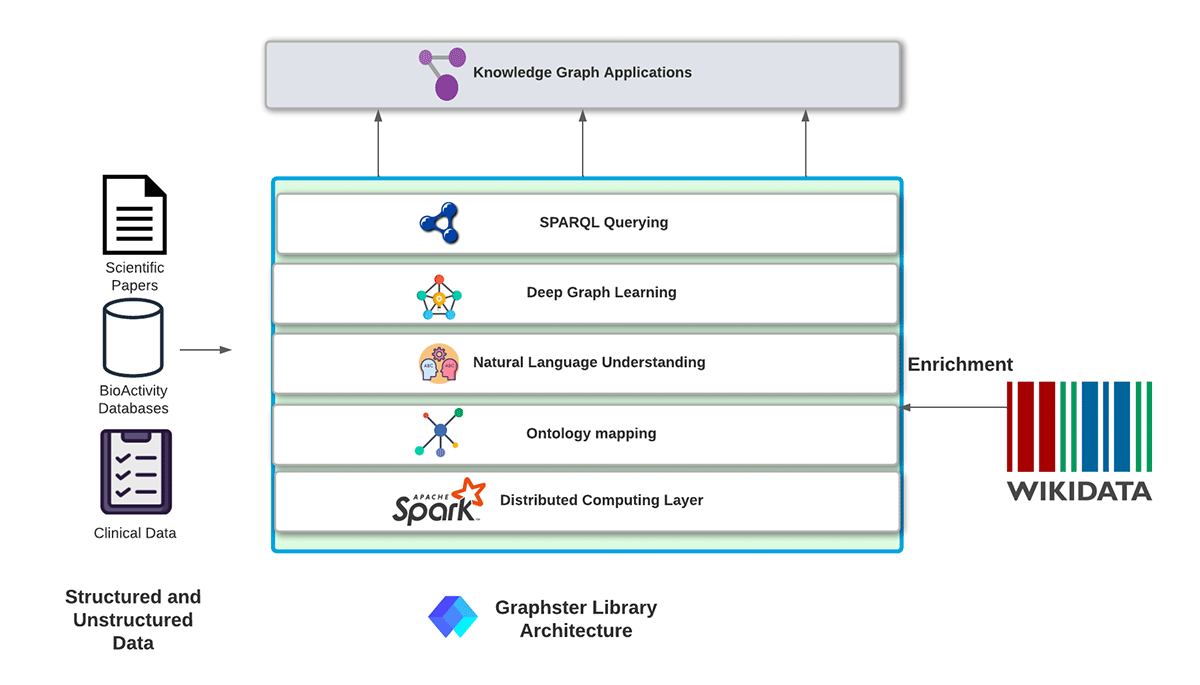
新しいApache Sparkベースのオープンソースライブラリを紹介します: Graphsterは、非構�造化データおよび構造化データから、スケーラブルでエンドツーエンドの知識グラフの構築、分析、クエリを行うことを目的として構築されたものです。Graphsterライブラリは、ドキュメントのコレクションを受け取り、メンションとリレーションを抽出して生の知識グラフを作成し、Wikidataからのファクトで知識グラフをエンリッチします。知識グラフが構築されると、GraphsterはSPARQLを使った知識グラフのネイティブクエリも支援することができます。
また、ライフサイエンス企業がそれぞれのニーズに合った知識グラフの構築を開始できるよう、ソリューションアクセラレーターとして「臨床試験を利用した知識グラフの構築」を提供できることを嬉しく思います。ソリューションアクセラレーターには、サンプルデータ、ビ�ルド済みコード、Databricksノートブック内のステップバイステップの手順が含まれています。臨床試験データを取り込み、MeSHオントロジーを使用してデータを構造化することで意味付けを行い、SPARQLクエリーを使用して大規模に分析する方法が紹介されています。まずは、こちらからアクセラレータをご覧ください。

