データ×AIプロジェクトに携わる人々はどのようにDatabricksを活用するのか
Databricksレイクハウスプラットフォームを通じたコラボレーション

数多くの企業が、競争優位性を確保し、イノベーションを促進するためにデータとAIを活用しようとしている。データとAI活用のユースケースやプロジェクトは多岐にわたるが、そのようなプロジェクトに従事する人々のペルソナやスキルセットは共通している。本稿では、データ×AIプロジェクトに従事するのはどのような人たちなのか、彼らはどのような課題を抱えているのかを説明し、Databricksレイクハウスプラットフォームを活用することでどのような価値を得ているのかをサンプルシナリオを通じてデモンストレーションする。
データ×AIプロジェクトとは
ビッグデータというキーワードが出現した2010年代以降、データは減るどころか指数関数的に増加しており、その重要性も増していると言える。しかし、一方でそれらのデータを全ての企業が有効に活用できているのかというと、そういう訳でもないのが実情である。2021年のMIT Tech Reviewによると、データ戦略に成功している企業は全体の13%である。
このような状況を打破しようと、ここ数年での技術的進歩が著しい機械学習(ML)・人工知能(AI)に注目が集まっている。これまでは、購買履歴、CRMデータなどの構造化データをデータウェアハウスで集計、加工し、BIダッシュボードに表示することでビジネスの意思決定に役立てるというのが、データ活用の主なユースケースであった。しかし、競争優位性を高めるために、過去にのみ目を向けるのではなく、データとAIを活用することで将来を見通そうというニーズが高まっている。
このため、購買履歴やCRMのような構造化データだけではなく、Webサイトの利用履歴、ソーシャルメディアへの投稿、電話の通話記録などの半構造化データ、非構造化データにも着目し、これらのデータに機械学習・人工知能を適用することで、これまでとは比較にならないビジネス価値を生み出すことをゴールとして多くの企業でデータ×AIプロジェクトが推進されている。このような取り組みに関してはこちらのウェビナーでも説明しているので参照願いたい。そして、このような取り組みでは、多くの場合、データウェアハウスやデータレイクのようなデータ管理プラットフォームが活用されている。

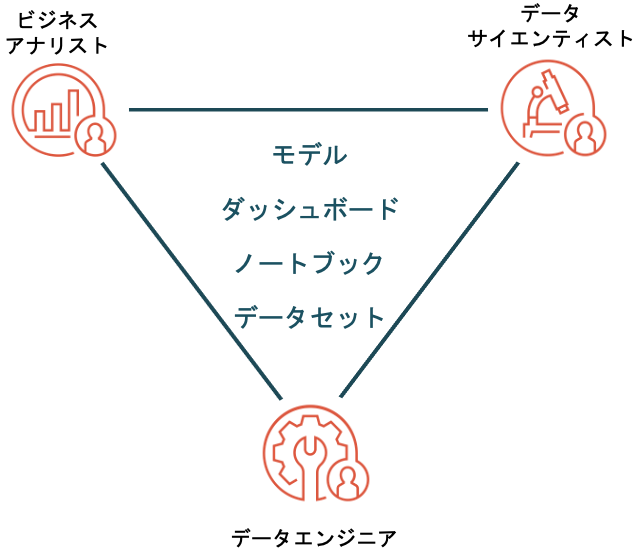
データ×AIプロジェクトに携わる人々
このようなデータ×AIプロジェクトを成功させるためには、様々なバックグラウンド・スキルセットを備えた人材が不可欠である。以下にデータ×AIプロジェクトの推進に不可欠な人々のペルソナを示す。これ以外にもプロジェクトマネージャ、MLエンジニアなどが関与することになるが、本稿では割愛する。
- データエンジニア:データ分析に至るデータパイプラインを構築し、質の高いデータを提供する。
- データサイエンティスト:分析データを理解し、適切な機械学習モデルを構築・選択する。
- ビジネスアナリスト:分析データや機械学習モデルのアウトプットの可視化を通じてビジネス示唆を抽出する。
これらの人々がデータウェアハウス、データレイクを利用するに際に直面することになる、データのサイロ化、データの重複などの課題はこちらの記事でまとめられているが、ここ�ではさらにこれらの人々の「コラボレーション」の課題にフォーカスする。
パンデミックが続く中、これらの人々がリモートワークを行うケースは当面減ることはないだろう。しかし、ビジネス要件に応えるためには各人が連携を行いつつ、円滑にデータ×AIプロジェクトを推進していかなくてはならない。しかし、従来型のツール・プラットフォームにおいては、データエンジニアはETLツールなどデータエンジニアリングのためのツール、データサイエンティストは分析ノートブックなどのデータサイエンスのためのツール、ビジネスアナリストはBIダッシュボードというように、各自が得意とするツールを活用するケースがほとんどであり、リモートワークを行いながら迅速なコラボレーションを行うことは困難である。結果として、データサイエンティストが期待していたデータが用意されていない、データサイエンティストが構築したモデルが他の人にとってブラックボックスになっている、ビジネスアナリストが可視化に使用したデータが古くなっていた等の問題を引き起こすことになる。
このようなコラボレーションの課題も解決するのがDatabricksレイクハウスプラットフォームである。以降では、サンプルシナリオに沿って、これらの人々がどのようにレイクハウスでコラボレーションするのかを説明する。
サンプルシナリオ - 需要予測
ここでは、データ×AIプロジェクトの例として需要予測を取り上げ、上述したペルソナたちがどのようにレイクハウスを活用するのかを説明する。
まず、データエンジニアが需要予測に必要なデータをロードする。この際、データサイエンティストに使用するデータが正しいのかを確認したいのだが、メールやチャットのやり取りでは本当に正しくデータが設定されているのかを確認するのが困難である。この場合、Databricksレイクハウスプラットフォームにおいては、データロードを行うノートブックを複数人が同時に参照・編集することが可能となっている。これによって、認識の齟齬を排除し、スムーズに作業を進めることができる。ここでは、データサイエンティストがノートブックに直接アクセスできるように読み取り権限を付与している。なお、さらなる権限を与えることで、ノートブックを同時に編集したり、プログラムを実行したりすることも可能である。

そして、データサイエンティストがデータエンジニアが作成したノートブックを参照し、問題がないことを確認したらノートブックに直接コメントを残せるので、円滑にコミュニケーションを行うことができる。

また、データの中身に関してビジネスアナリストの知見を得たい場合においても、同じノートブックで直接データの可視化を実施してもらい、その内容の妥当性についてアドバイスを得ることも可能である。Databricksのノートブックではビルトインの可視化機能を活用できるので、グラフをベースとしたコミュニケーションも容易である。

この後、データサイエンティストはこのデータを用いて需要予測モデルを構築する。Databricksレイクハウスプラットフォームでは、このモデルをチームで容易に連携できる仕組みも提供しているが、詳細は次回以降の記事で説明する。



