Delta Live Tablesで10億レコードのETLを1ドル未満で実行した方法
次元データウェアハウスのETLベンチマークの利用について

Original: How We Performed ETL on One Billion Records For Under $1 With Delta Live Tables
翻訳: junichi.maruyama
今日、DatabricksはETL(Extract、Transform、Load)の価格とパフォーマンスの新しい標準を打ち立てました。お客様は10年以上前からDatabricksをETLパイプラインに使用していますが、従来のETL技術を使用してEDW(Enterprise Data Warehouse)のディメンションモデルにデータを取り込む場合、クラス最高の価格とパフォーマンスを公式に実証しています。
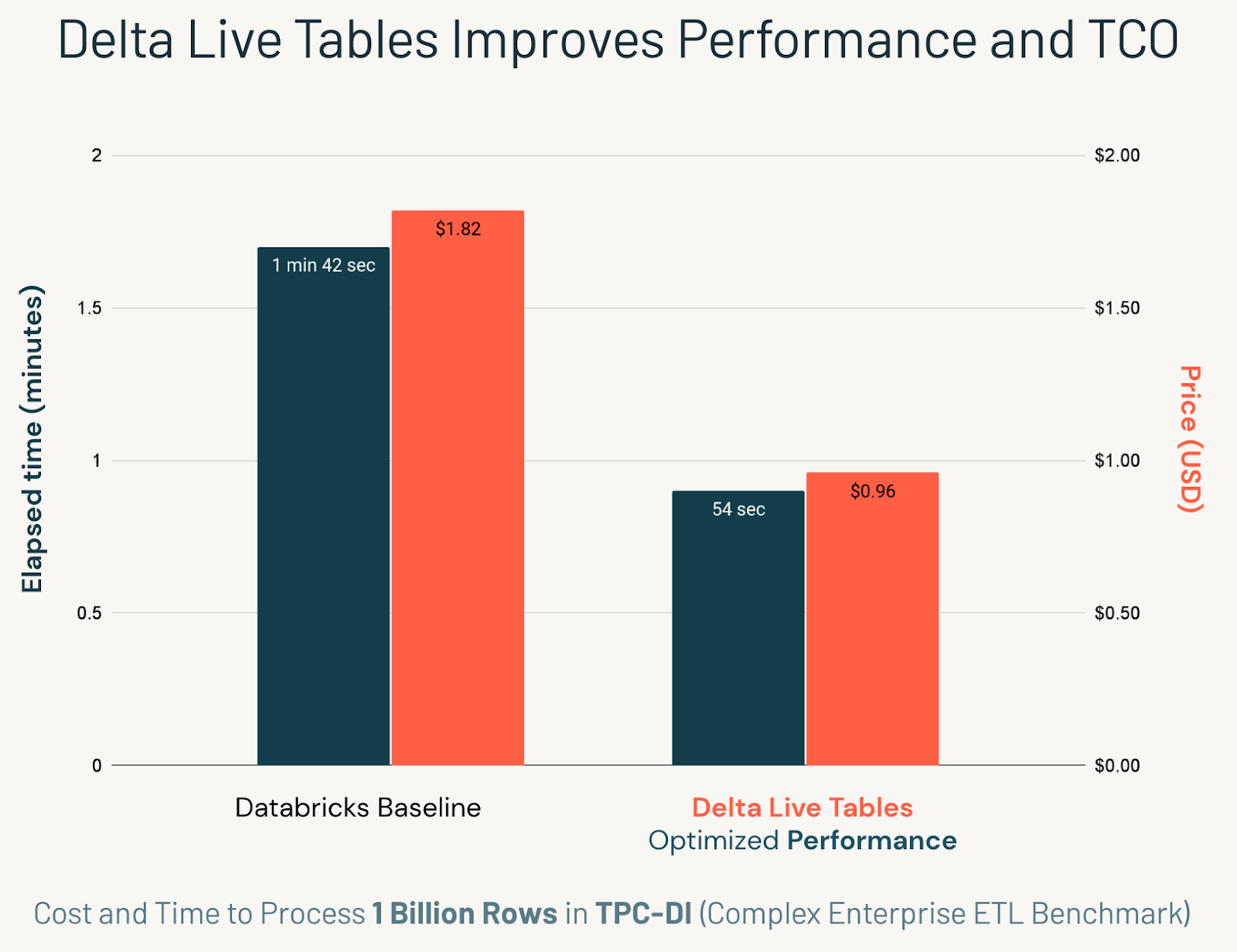
そのために、データ統合、つまり一般にETLと呼ばれるもののための最初の業界標準ベンチマークであるTPC-DIを使用しました。Databricksは、大規模で複雑なEDWスタイルのETLパイプラインを、クラス最高のパフォーマンスで効率的に管理することができることを示しました。また、Delta Live Tables(DLT)を使ってDelta Lakeのテーブルに「生命を吹き込む」ことで、パフォーマンス、コスト、シンプルさが大幅に改善されることも分かりました。DLTの自動オーケストレーションを使って、10億レコードを次元データウェアハウススキーマに取り込みましたが、総費用は1ドル未満でした。
Databricks は Lakehouse のビジョンを実現するために、データウェアハウスの機能を急速に開発してきました。最近発表された多くの内容は、ビジネスインテリジェンスクエリを提供する際にクラス最高の体験を提供するためのサービングレイヤーの画期的な改良に焦点を当てています。しかし、これらのベンチマークは、データウェアハウスのもう一つの重要な構成要素であるETLには対応していません。そこで私たちは、業界初、そして私たちの知る限り唯一の、従来のEDW ETLのベンチマークであるTPC-DIで、記録的な速さを証明することにしたのです。
そこで、DLTでTPC-DIベンチマークを実施することで得られた知見について説明します。DLTはコストとパフォーマンスを大幅に改善しただけでなく、開発の複雑さを軽減し、多くのデータ品質のバグをプロセスの早い段階で発見することができました。最終的に、DLTは非DLTベースラインと比較して開発時間を短縮し、生産性コストとクラウドコストの両方を改善しながら、パイプラインをより早く本番に導入することを可能にしました。
DLTの実装を追ったり、ベンチマークを自分で検証したい場合は、このリポジトリですべてのコードにアクセスすることができます。
なぜTPC-DIが重要なのか
TPC-DIは、典型的なデータウェアハウスのETLに関する業界初の標準的なベンチマークです。複雑な次元スキーマに対して、あらゆる操作の標準を徹底的にテストします。TPCでは「factitious」スキーマを使用しています。つまり、データは偽物であっても、スキーマやデータの特性は、実際のリテール証券会社のデータウェアハウスに非常に近い、次のようなものです:
- Change Data Captureのデータをインクリメンタルに取り込む。
- SCD Type IIを含むSlowly Changing Dimensions (CDC)
- 完全なデータダンプ、構造化(CSV)、半構造化(XML)、非構造化テキストなど、さまざまなフラットファイルを取り込むことができます。
- 参照整合性を確保しながら、次元モデル(図参照)を充実させる。
- ウィンドウ計算など高度な変換が可能
- すべての変換は監査ログを取得する必要がある
- テラバイト単位のデータ
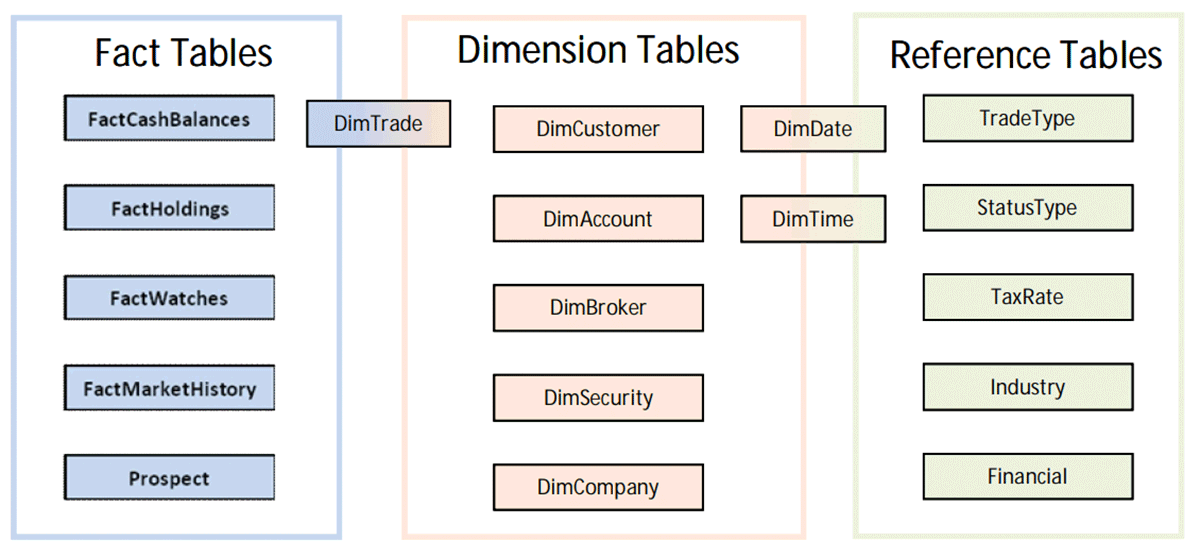
TPC-DIでは、これらすべての動作の性能とコストをテストするだけではありません。 また整合性をとることで信頼性の高いシステムであることが要求されます。、システムの信頼性も要求されます。TPC-DIに合格したプラットフォームは、EDWに必要なETL計算をすべて行うことができます。Databricksは、Delta LakeのACIDプロパティとStructured Streamingのフォールトトレランス保証を利用することで、すべての監査に合格しました。これらは、Delta Live Tables (DLT)の構成要素です。
DLTによるコストとマネジメントの改善方法
Delta Live Tables(DLT)は、バッチとストリーミングの両方のパイプラインの開発を劇的に簡素化するETLプラットフォームです。DLTで開発する場合、ユーザーはSQLまたはPythonで宣言文を書き、CDCデータの取り込み、SCD Type2出力の生成、変換されたデータに対するデータ品質保証の実行などのインクリメンタルな操作を実行します。
このブログの残りの部分では、DLTの機能を使用してTPC-DIの開発を簡素化し、非DLTのDatabricksベースラインと比較してコストと性能を大幅に向上させた方法について説明します。
自動オーケストレーション
TPC-DIは、非DLTのDatabricksベースラインと比較して、DLTでは2倍以上速くなりました。これは、DLTが人間よりもタスクをオーケストレーションすることに長けているためです。
一見すると複雑ですが、以下のDAGは、TPC-DIの各レイヤー��を定義するために使用した宣言的なSQL文によって自動生成されたものです。私たちはTPC-DIの仕様に沿ったSQL文を書くだけで、DLTがすべてのオーケストレーションを代行してくれるのです。
DLTは、すべてのテーブルの依存関係を自動的に判断し、独自に管理します。DLTを使わずにベンチマークを実施した場合、各ETLステップが適切な順序でコミットするように、オーケストレーターでこの複雑なDAGをゼロから作成する必要がありました。
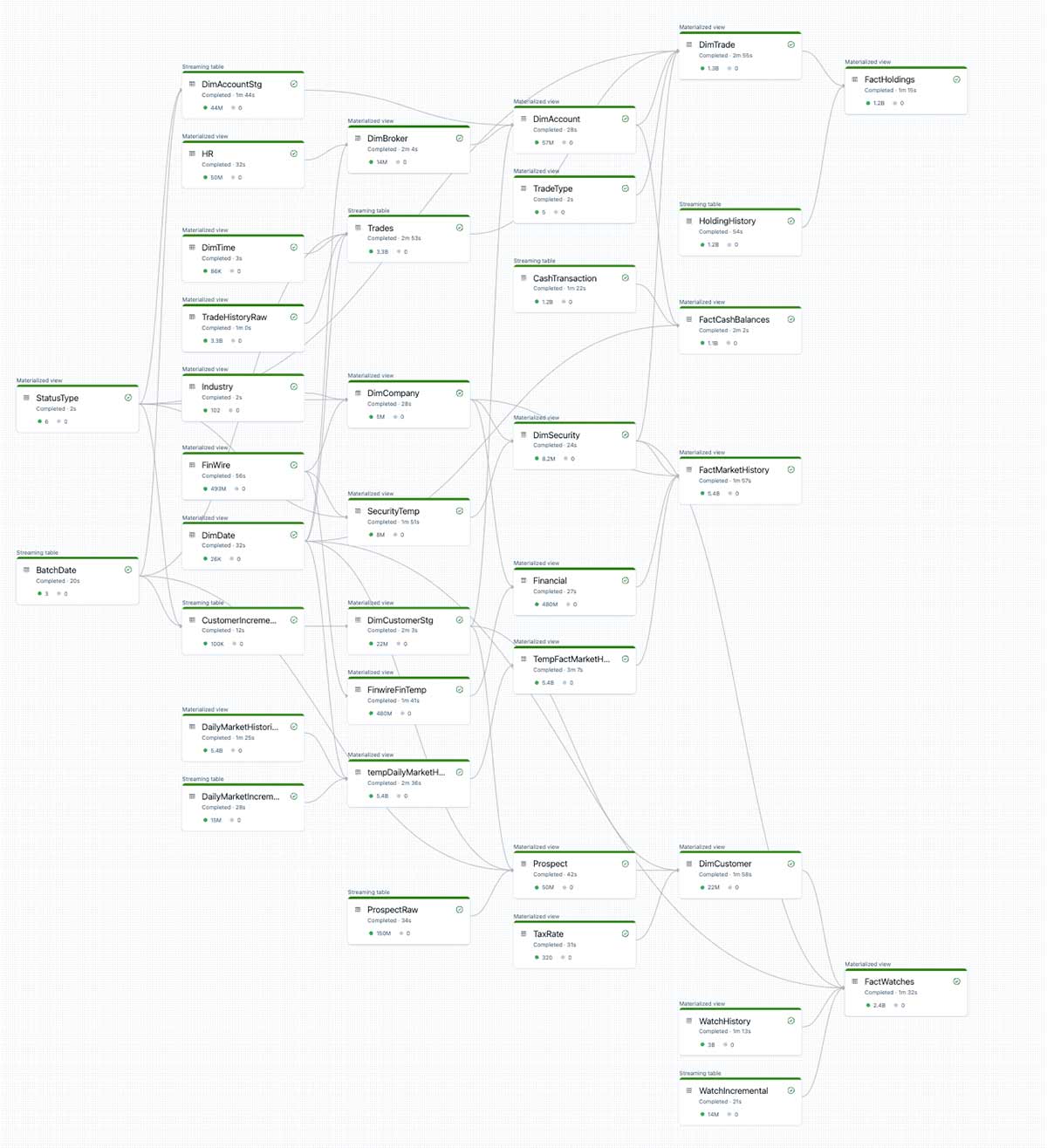
この自動オーケストレーションは、DAG管理に費やす人間の時間を削減するだけではありません。自動オーケストレーションはリソース管理も大幅に改善し、クラスタ全体で作業が完璧に並列化されることを保証します。この効率性が、DLTで観測された2倍のスピードアップの主な要因です。
下のGanglia Monitoringのスクリーンショットは、DLTでTPC-DIを実行した際に使用した36台のワーカーノードにおけるサーバーの負荷分散を示しています。DLTの自動オーケストレーションにより、パイプラインの実行中に同時にスナップショットされた場合、すべての計算リソースでほぼ完璧に作業を並列化できることがわかります:

SCD Type 2
Slowly changing dimensions (SCD) は、多くの次元データウェアハウスで一般的でありながら困難な側面を持っています。バッチ処理のSCDタイプ1は、1つのMERGEで実装できることが多いですが、ストリーミングでこれを実行するには、多くの反復的でエラーが発生しやすいコーディングが必要です。SCD Type 2 は、バッチ処理でもより複雑であり、開発者は複雑なカスタマイズされたロジックを作成し、順不同の更新の適切な順序を決定する必要があるため、より複雑です。SCD Type 2 のエッジケースをすべてパフォーマンスよく処理するには、通常、数百行のコードが必要で、チューニングが非常に困難な場合があります。このような「価値の低い作業」は、EDWチームがより価値のあるビジネスロジックやチューニングから目をそらし、消費者に適切なタイミングでデータを提供するためのコストをより高くしてしまうことがよくあります。
Delta Live Tablesは、SCD Type 1とType 2の両方を保証されたフォールトトレランスでリアルタ�イムに自動的に処理する「Apply Changes」メソッドを導入しています。DLTは、追加のチューニングや設定なしにこの機能を提供します。Apply Changesは、TPC-DIベンチマークの主要要件の1つであるSCD Type 2の実装と最適化にかかる時間を劇的に短縮してくれます。
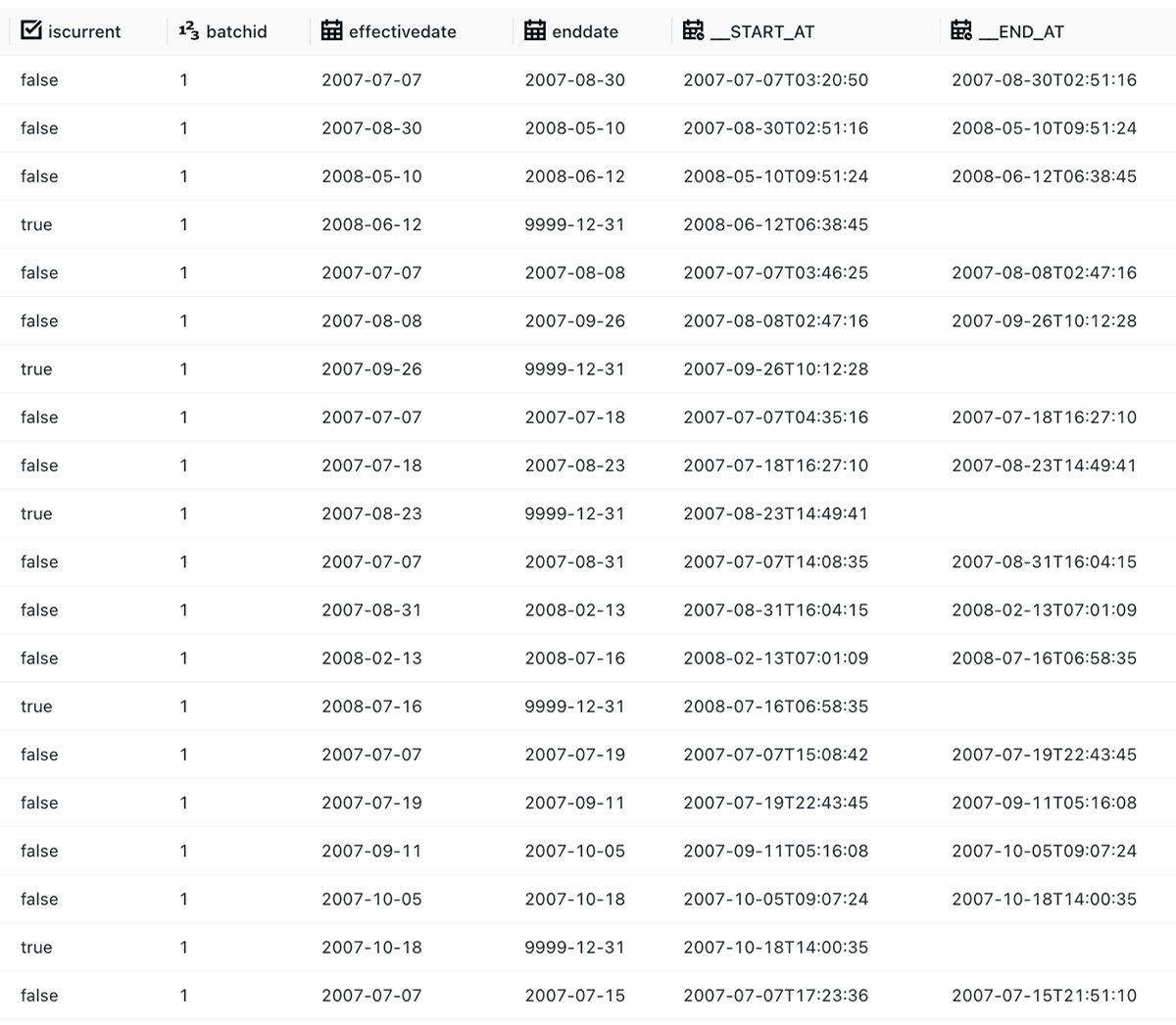
TPC-DIは、挿入、更新、削除を行う CDC Extract ファイルを提供します。これは、順序を解決するために使用できる単調に増加するシーケンス番号を与えるもので、通常は困難なエッジケースについて推論する必要があるものである。幸いなことに、Apply Changes Intoに内蔵されたSEQUENCE BY機能を使って、TPC-DIの順序のずれたCDCデータを自動的に判断し、最新の次元が常に適切に順序付けされるようにすることができます。Apply Changesを1回実行した結果を以下に示します:
データ品質
ガートナーは、データ品質の低下により、企業は年間平均1,290万ドルのコストをかけていると推定しています。また、データ駆動型企業の半数以上が、今後数年間はデータ品質に重点を置くと予測しています。
ベストプラクティスとして、ブロンズ層にすべてのデータを取り込む際に、DLTのData Expectationsを使用して、基本的なデータの妥当性を確保しました。TPC-DIの場合、すべてのキーが有効であることを保証するための「期待値」を作成しました:
DLTは自動的にリアルタイムのデータ品質メトリクスを提供し、デバッグを加速させ、下流の消費者のデータに対する信頼性を向上させます。DLTのビルトインされた品質UIを使ってTPC-DIの合成データを監査したところ、重要なサロゲートキーが0.1%未満の確率で欠落するTPCデータ生成器のバグを発見することができました。
興味深いことに、DLTを使用しないパイプラインを実装した場合には、このバグを発見することができませんでした。さらに、TPC-DIが存在した8年間、他のTPC-DI実装ではこのバグに気づいたことはありませんでした!DLTでデータ品質のベストプラクティスに従うことで、試行錯誤することなくバグを発見することができたのです:

DLTエクスペクテーションがなければ、銀層と金層にぶら下がった参照を許してしまい、本番まで気づかないうちに結合が失敗する可能性がありました。この場合、通常、破損したレコードを追跡するために、ゼロからデバッグするのに数え切れないほどの時間がかかるでしょう。
結論
Databricks LakehouseのTPC-DI結果は素晴らしいものでしたが、Delta Live Tablesは、自動オーケストレーション、SCD Type 2、データ品質制約によって、テーブルに命を吹き込みました。その結果、総所有コスト(TCO)と生産までの時間を大幅に削減することができました。TPC-DS (BI serving)の結果に加え、このTPC-DI(従来のETL)ベンチマークがLakehouseのビジョンをさらに証明するものであり、このウォークスルーがDLTを使った独自のETLパイプラインの実装に役立つことを期待しています。
DLTを使い始めるための完全なガイドはこちらをご覧ください。また、TPC-DIで使用されている当社のチューニング方法については、最近のData + AI Summitでの講演 "So Fresh and So Clean." をご覧ください。

