Spark NLPでDatabricks Lakehouse Platform上のVision Transformers(ViT)をスケールさせる

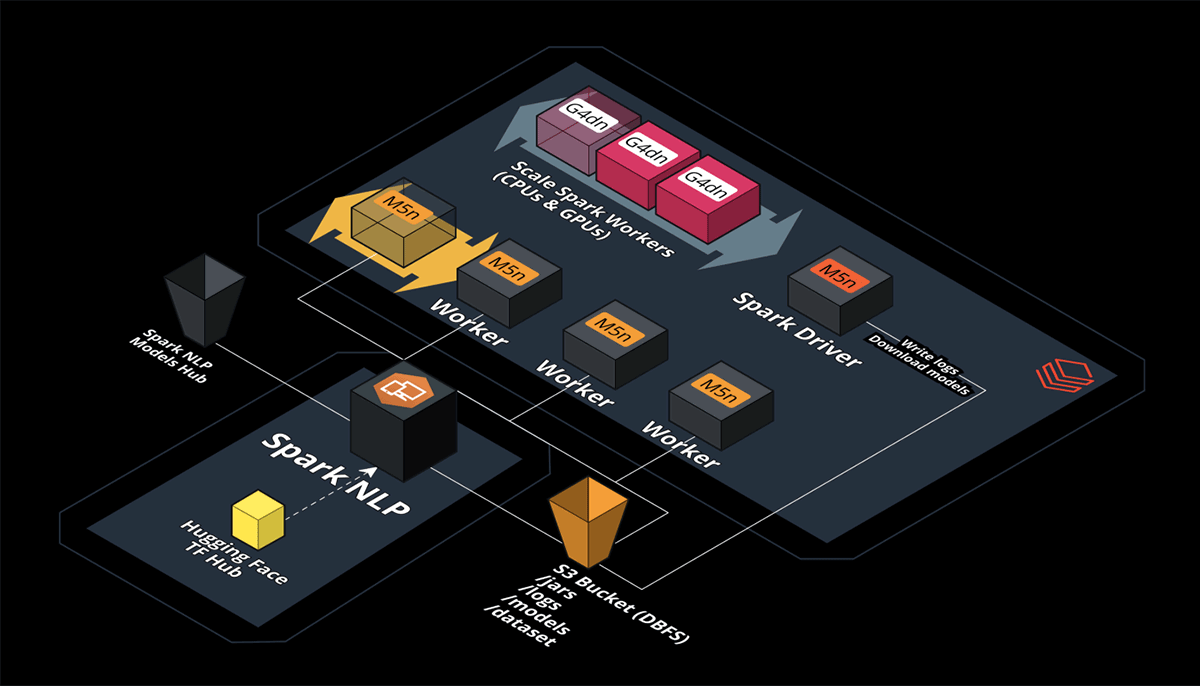
Scale Vision Transformers (ViT) on the Databricks Lakehouse Platform with Spark NLP
翻訳: junichi.maruyama
イントロダクション
2017年のことですが、Google AIの研究者グループが、すべての自然言語処理(NLP)の基準を変えるトランスフォーマーモデルのアーキテクチャを紹介する論文を発表しました。これらの新しいTransformerベースのモデルは、NLPタスクに革命を起こしているように見えますが、コンピュータビジョン(CV)での使�用はかなり制限されたままでした。これらの新しいTransformerベースのモデルは、NLPタスクに革命をもたらすように見えるが、コンピュータビジョン(CV)での使用はかなり制限されたままであった。コンピュータビジョンの分野は、畳み込みニューラルネットワーク(CNN)の使用によって支配されてきました。CNNをベースとした一般的なアーキテクチャ(ResNetなど)があります。Google Brainの別の研究チームは、2021年6月に「An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 」と題した論文で「Vision Transformer(ViT)」に紹介しました。このブログ記事では、Hugging FaceからVision Transformer(ViT)モデルをスケールアウトして、加速された高性能な推論のために本番環境に展開する方法を示し、Databricks、Nvidia、Spark NLPを使用してViTモデルを21倍スケールする方法を説明します。
Spark NLPオープンソースプロジェクトの貢献者として、このライブラリがエンドツーエンドのVision Transformers(ViT)モデルのサポートを開始したことに興奮しています。私はSpark NLPや他のML/DLオープンソースライブラリを毎日仕事で使っており、最先端の画像分類タスクのためにViTパイプラインを展開し、Hugging FaceとSpark NLPの詳細な比較を提供しています。
この記事の長いバージョンは、Mediumに3つのパートシリーズとして公開されています:
このプロジェクトのノートブック、ログ、スクリーンショット、スプレッドシートはGitHubで提供されています。
ベンチマーク設定
データセットとモデル
- データセット ImageNet mini: サンプル (>3K) - フル (>34K)
- KaggleからImageNet 1000 (mini)データセットをダウンロードしました。
- 必要なのは、時間のかかるベンチマークを行うのに十分な画像だけだったので、34K以上の画像を持つ列車ディレクトリを選び、imagenet-miniと名付けました。 - モデル: Googleによる「vit-base-patch16-224」です。
Hugging FaceでホストされているGoogleのこのモデルを使用する予定です。 - ライブラリのご紹介 Transformers & Spark NLP
コード
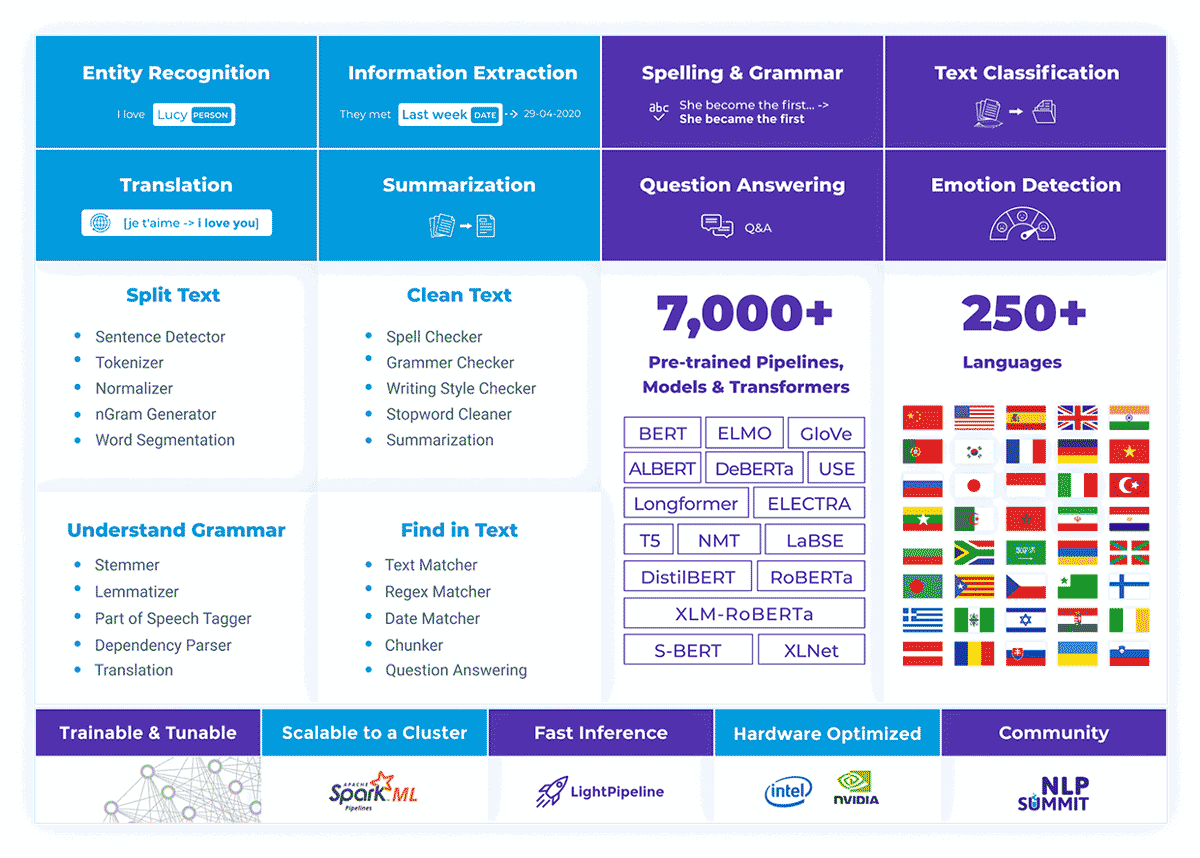
Spark NLPは、Apache Spark™の上に構築された最先端の自然言語処理ライブラリです。分散環境で容易にスケールする機械学習パイプラインのために、シンプルでパフォーマンスと精度の高いNLPアノテーションを提供します。Spark NLPには、200以上の言語に対応した7000以上の事前学習済みパイプラインとモデルが付属しています。また、トークン化、単語分割、品詞タグ付け、単語と文の埋め込み、名前付き固有表現認識、依存関係解析、スペルチェック、テキスト分類、感情分析、トークン分類、機械翻訳(+180言語)、要約と質問応答、テキスト生成、画像分類(ViT)、その他多くのNLPタスクが提供されています。
Spark NLPは、BERT、CamemBERT、ALBERT、ELECTRA、XLNet、DistilBERT、RoBERTa、DeBERTa、XLM-RoBERTa、Longformer、ELMOなどの最先端のトランスフォーマーを提供する量産中の唯一のオープンソースNLPライブラリです、 Universal Sentence Encoder、Google T5、MarianMT、GPT2、Vision Transformer (ViT) をPythonやRだけでなく、Apache Sparkをネイティブに拡張することでJVMエコシステム(Java、Scala、Kotlin)にもスケールアップしています。
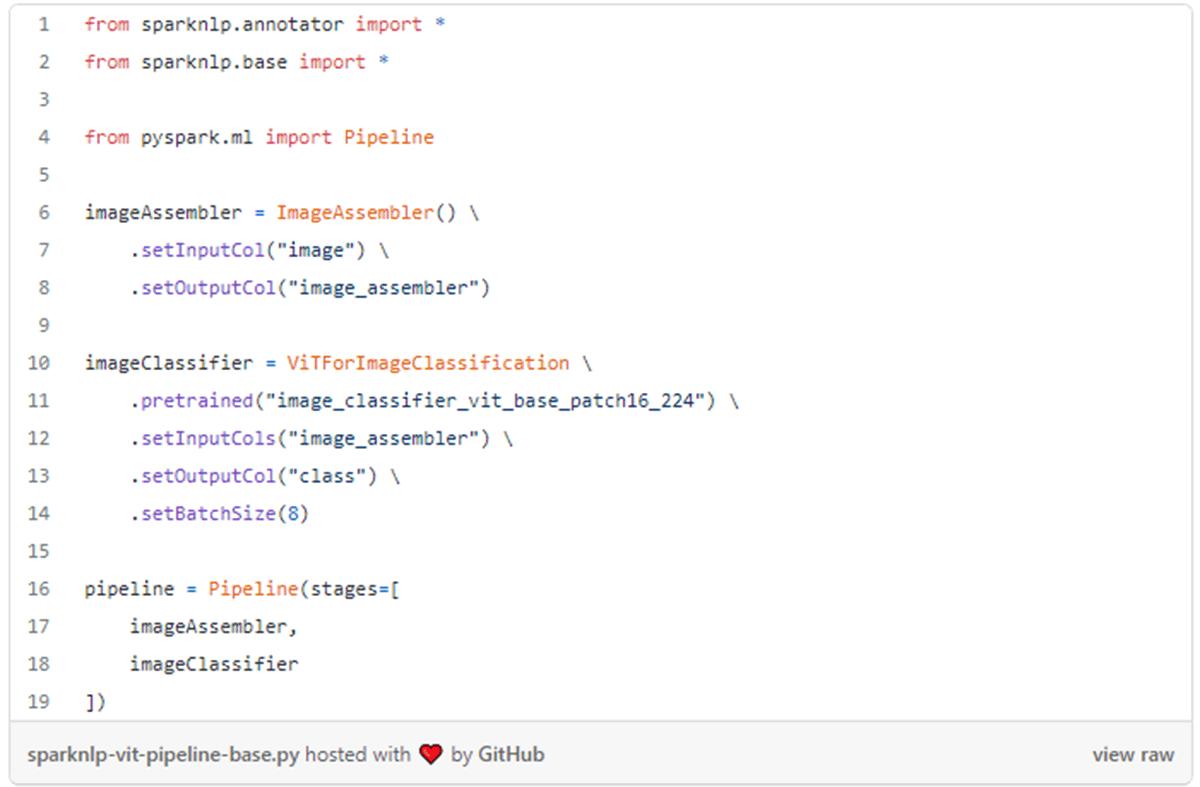
ViTアーキテクチャによるモデルの学習が完了したら、NLPと同様にトランスフォーマーの事前学習とファインチューニングを行うことができます。Spark NLPでは、最近の4.1.0リリースで画像分類のためのViT機能が追加されました。この機能は、ViT For Image Classificationと呼ばれています。240以上のプレトレーニングモデルが用意されており、Spark NLP��でこの機能を利用する簡単なコードは以下のようになります:
シングルノードでの比較 - Spark NLPはクラスタだけのものではありません!
シングルノードのDatabricks CPUクラスタ構成
Databricksでは、Apache Sparkを1台で使いたい、あるいはSpark以外のアプリケーション、特にMLやDLベースのPythonライブラリを使いたいという方に適したクラスタを作成する際に「Single Node」というクラスタタイプを用意しています。ベンチマークを始める前の、私のSingle Node Databricksのクラスタ構成はこんな感じです(CPUのみ):
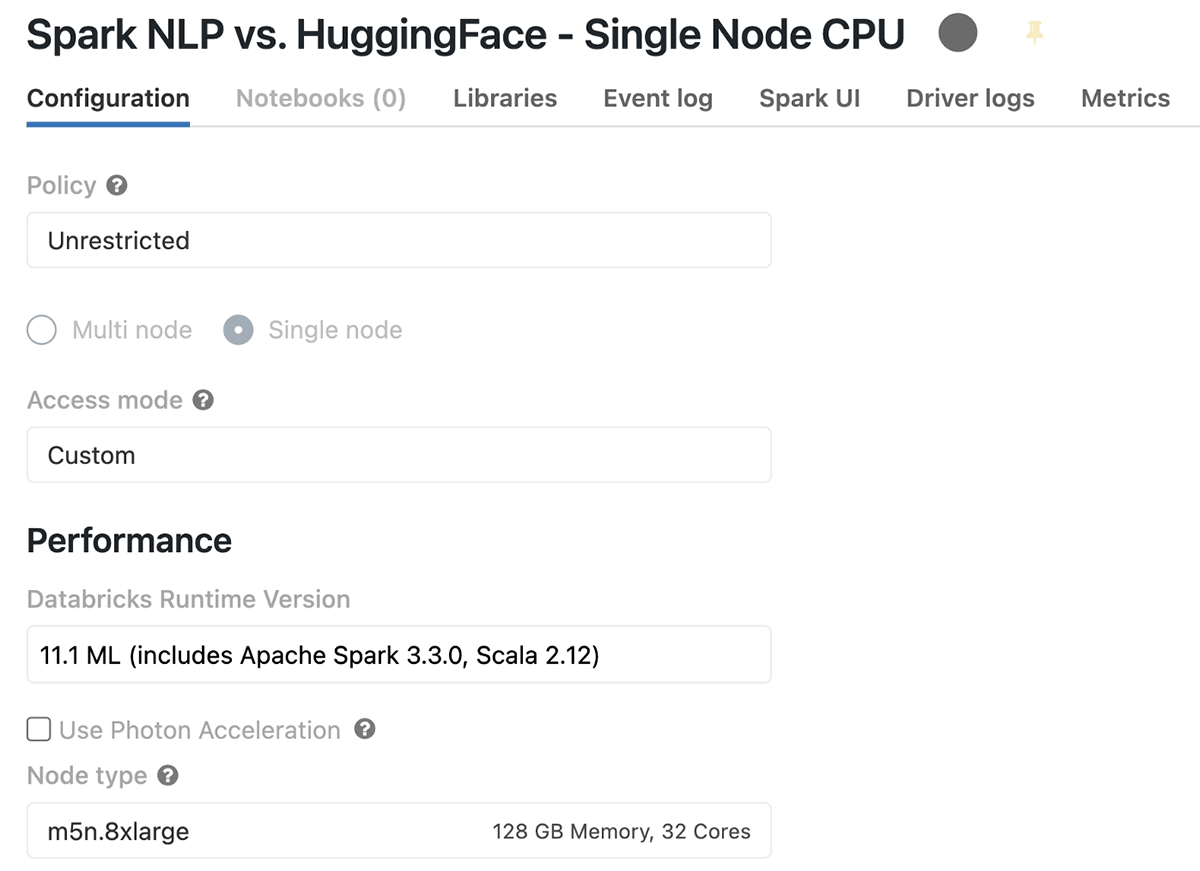
AWSのm5n.8xlargeインスタンスを利用したこのクラスタの概要は、1Driver(1ノードのみ)、128GBのメモリ、32CoresのCPU、そして1時間あたり5.71DBUのコストです。
まず、Single Node DatabricksのCPUにSpark NLPをインストールしましょう。クラスタ内のLibrariesタブで、以下の手順を踏む必要があります:
- 新規インストール -> PyPI -> spark-nlp==4.1.0 -> インストール
- 新規インストール -> Maven -> コーディネート -> com.johnsnowlabs.nlp:spark-nlp_2.12:4.1.0 -> インストール
- クラスタ->アドバンスドオプション->スパーク->環境変数に`TF_ENABLE_ONEDNN_OPTS=1`を追加し、oneDNNを有効にする予定です。
シングルノードのDatabricks GPUクラスタ構成
新しいクラスタを作成しましょう。今回はGPU付きのランタイムを選択します。この場合、11.1 ML (includes Apache Spark 3.3.0, GPU, Scala 2.12) と呼ばれ、必要なCUDAとNVIDIAソフトウェアがすべてインストールされている状態になっています。次に必要なのは、GPUを搭載したAWSインスタンスも選択することで、GPUが1つ、コア/メモリ数が同じであるg4dn.8xlargeクラスタを選択しました。このGPUインスタンスは、Tesla T4と16GBメモリ(15GBの使用可能なGPUメモリ)を搭載しています。
GPUクラスタ用のライブラリのセットアップは、CPUの場合と同様です。唯一の違い��は、Mavenから「spark-nlp-gpu」を使用することです。つまり、「com.johnsnowlabs.nlp:spark-nlp_2.12:4.1.0」ではなく「com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:4.1.0」になっています。
Benchmarking
DatabricksのシングルノードクラスターにSpark NLPをインストールしたので、CPUとGPUの両方でサンプルデータセットとフルデータセットのベンチマークを繰り返してみます。まずはサンプルデータセットに対して、まずCPUでのベンチマークから見てみましょう。バッチサイズ16で34Kの画像を処理し、そのクラスを予測し終えるまでに、ほぼ12分(1072秒)かかっています。最適なバッチサイズのベンチマークについては、この投稿のオリジナルリビジョンに記載されています。
より大きなデータセットでは、バッチサイズ8で34K以上の画像のクラス予測を終えるのに7分半(435秒)近くかかりました。CPUを搭載したシングルノードと1GPUを搭載したシングルノードのベンチマーク結果を比較すると、ここではGPUノードの勝利であることがわかります:
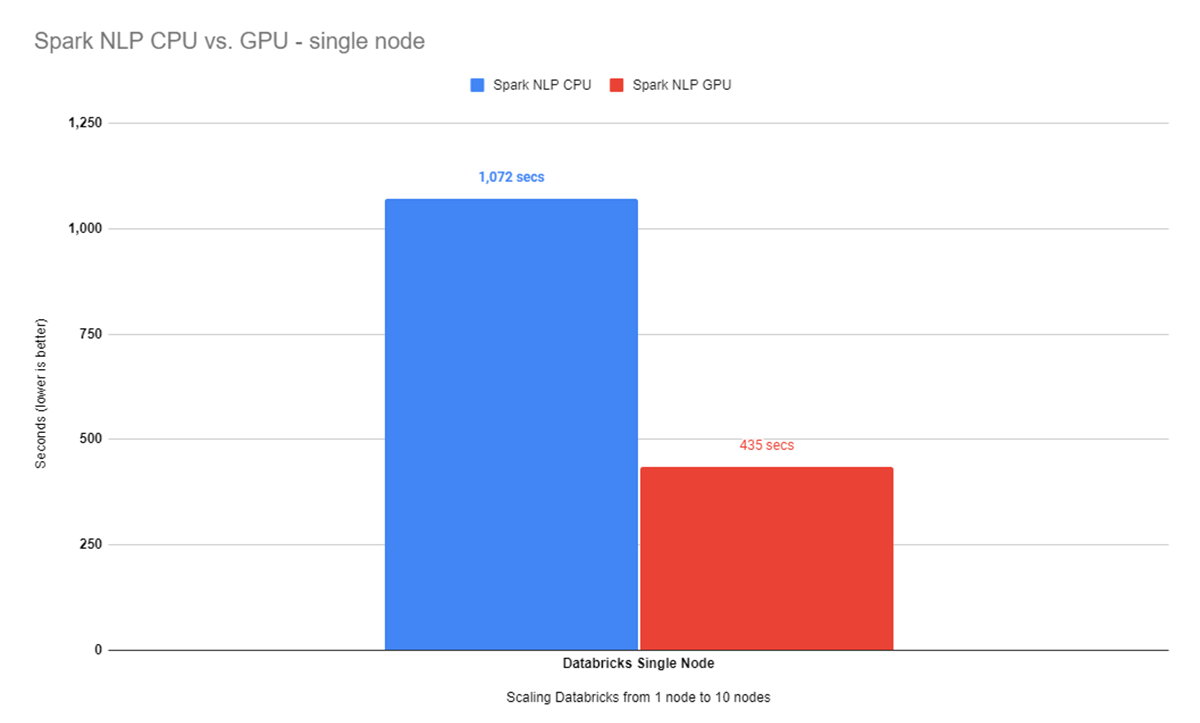
これはすごいことです!GPU上のSpark NLPは、oneDNNを有効にしてもCPUの約2.5倍高速であることがわかりますね。
この記事の拡張版では、最新のIntelアーキテクチャでoneDNNライブラリを使用した場合の影響についてベンチマークを実施しました。oneDNNはCPUの結果を10%から20%向上させました。
1台のマシンを超えたスケーリング
Spark NLPは、Spark MLを拡張したものです。Databricks を含む Apache Spark がサポートするすべてのプラットフォームで、ネイティブかつシームレスにスケールします。コードの変更は一切必要ありません!Spark NLPは、コードを何も変更することなく、1台のマシンから無限のマシンまでスケールすることができます!
AWSでCPUを搭載したDatabricksマルチノード
クラスタを作成し、今回はClusterモード内のStandardを選択します。つまり、クラスタ内に複数のノードを持つことができ、Apache Sparkの用語では、1つのドライバとN個のワーカー(実行者)を意味します。

また、この新しいクラスタにSpark NLPをLibrariesタブでインストールする必要があります。前のセクションで紹介した、CPUを搭載したSingle Node Databricksの手順を踏めばよいでしょう。ご覧のように、Hugging FaceとSpark NLPの両方のベンチマークに使用したのと同じCPUベースのAWSインスタンスを選択したので、ノードを増やしたときにどのようにスケールアウトするかを確認することができます。
Clusterの構成はこんな感じです:
以前のベンチマークで使用したSpark NLPパイプラインを再利用し(コードを変更する必要はありません)、34Kの画像を持つより大きなデータセットのみを使用します。ワーカーの数は2人から10人へと徐々にスケールさせています。
Databricks Multi-Node with GPUs on AWS
GPUベースのマルチノードDatabricksクラスタを持つことは、シングルノードクラスタを持つこととほとんど同じです。唯一の違いは、Standardを選択し、シングルノードのGPUのベンチマークで選択したのと同じAWSインスタンス仕様で同じML/GPU Runtimeを維持することです。
また、この新しいクラスタにSpark NLPをLibrariesタブでインストールする必要があります。以前と同じように、GPUを使ったシングルノードのDatabricksで紹介した手順に従えばよい。
念のため、各AWSインスタンス(g4dn.8xlarge)には、1つのNVIDIA T4 GPU 16GB(使用可能メモリ15GB)が搭載されています。
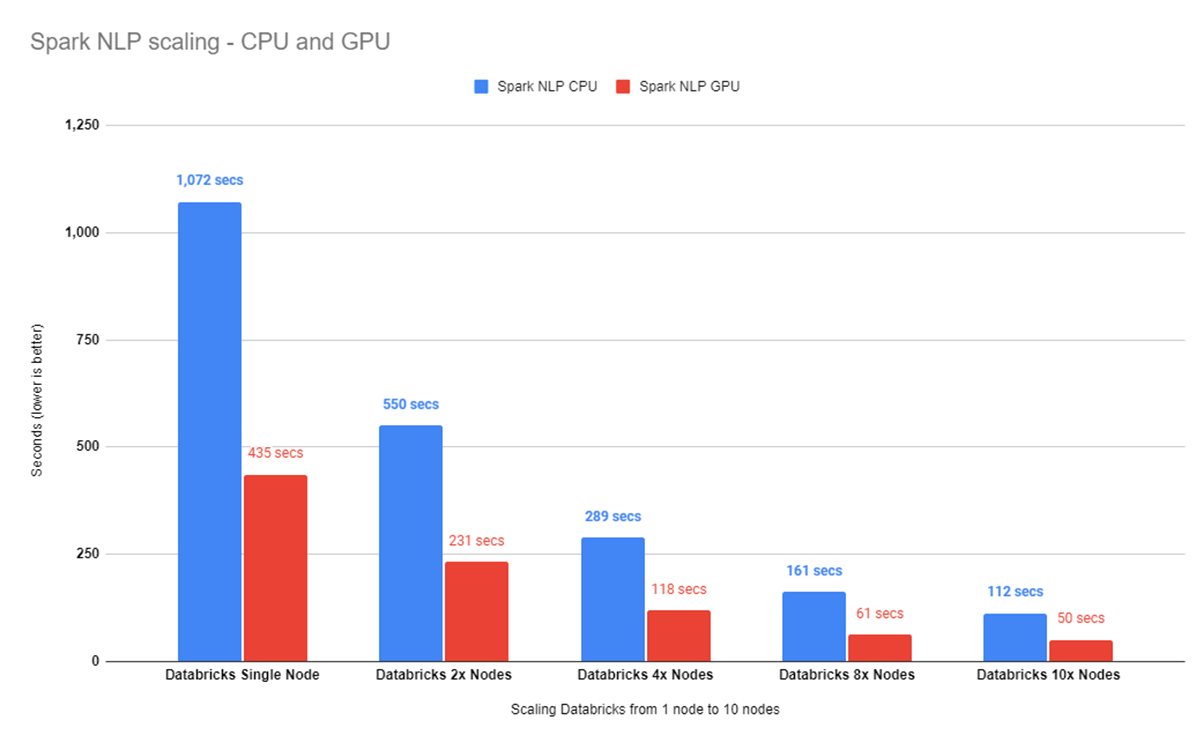
34Kイメージのベンチマークを2、4、8、10個のDatabricksノードで実行すると、CPUで112秒かかります(シングルノードでは1,072秒です)。GPUクラスタは435秒から50秒にスケールアップしています。
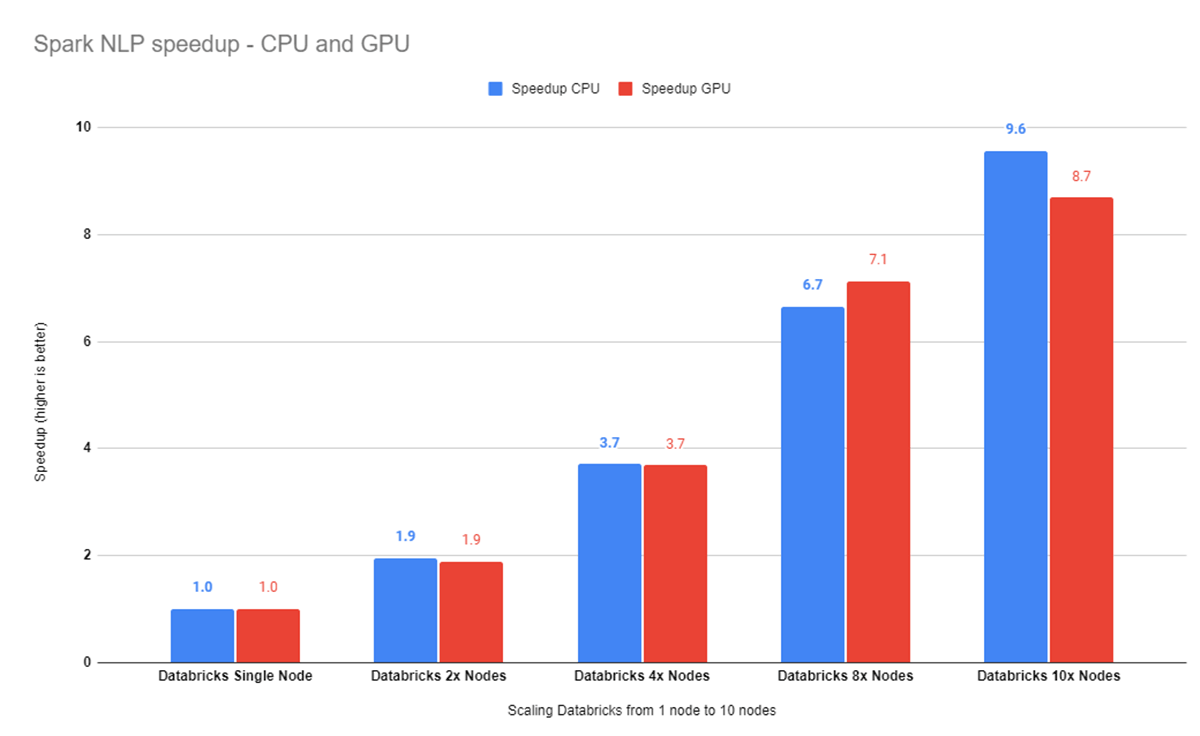
10ノードクラス��タを使用すると、96%の効率を達成し、すなわち、シングルノード設定での実行よりも9.6倍高速になります。10ノードGPUクラスターは8.7倍高速に動作します。
Conclusions
Spark NLPは、10ノードのGPUクラスタでは、シングルノードのCPUクラスタよりも21.4倍高速で、pythonコードの1行も変更せずに実行できます。
Spark NLPは、Databricksプラットフォームと完全に統合されています。ぜひお試しください!
- 詳細については、https://johnsnowlabs.com をご覧ください。
- インストール方法はこちらでご覧いただけます。
- John Snow LabsのSlack channelに参加すると、ヘルプを得ることができます。

