
Databricks / Mosaic R&Dチームは、わずか7ヶ月前に推論サービスアーキテクチャの最初のイテレーションを開始しました。それ以来、私たちは、急速に成長するジェネレーティブAI環境におけるあらゆる新しい進歩を統合する準備が整った、スケーラブルでモジュール化されたパフォーマンスの高いプラットフォームを提供するために、飛躍的な進歩を遂げてきました。
2024 年 1 月には、NVIDIA TensorRT-LLM 上に構築された大規模言語モデル(LLM)を提供するための新しい推論エンジンの使用を開始しました。
NVIDIA TensorRT-LLMの 紹介
TensorRT-LLM は、大規模言語モデルの高速推論を実現するオープンソースライブラリです。TensorRT-LLMは、NVIDIAのTensorRTディープラーニングコンパイラとのファーストクラスの統合、言語モデルの主要な操作のための最適化されたカーネル、効率的なマルチGPUサービングを可能にする通信プリミティブなど、複数のコンポーネントで構成されています。これらの最適化は、NVIDIA Tensor Core GPUを搭載した推論サービス上でシームレスに動作し、最先端のパフォーマンスを実現するための重要な要素となっています。
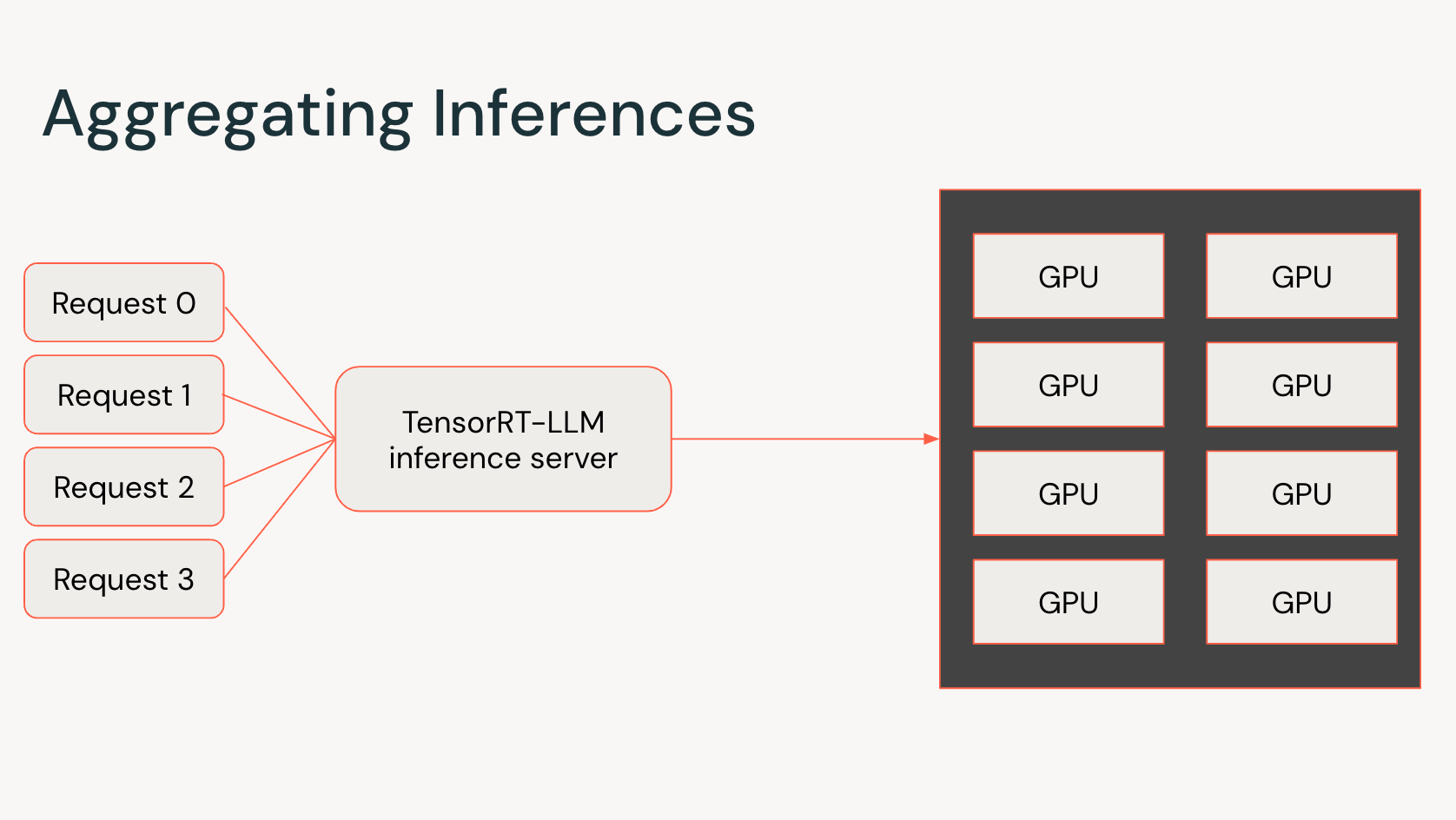
この6ヶ月間、私たちはNVIDIAと協力して、TensorRT-LLMを私たちの推論サービスに統合してきました。TensorRT-LLM を使用することで、大規模言語モデルにおける最初のトークン生成時間と出力トークン速度を大幅に改善できます。以前の投稿で説明したように、これらのメトリクスは、LLMで作業する際のユーザーエクスペリエンスの質を推定する重要な指標です。
NVIDIAとの協力関係は、相互に有益なものでした。TensorRT-LLM プロジェクトのアーリーアクセスフェーズにおいて、Databricks は MPT モデル変換スクリプトを提供し、Hugging Face から直接 MPT モデルを提供したり、MPT アーキテクチャを使用して事前学習モデルや微調整されたモデルを提供したりすることを、より迅速かつ容易にしました。また、NVIDIAのチームは、H100 Tensor Core GPUにおける量子化とFP8のサポートを導入するだけでなく、インストール手順を追加することで、MPTモデルのサポートを強化しました。私たちは、TensorRT-LLMでMPTアーキテクチャをファーストクラスでサポートできることに興奮しています。このコラボレーションは、私たちのチームと顧客に利益をもたらすだけでなく、より広範なコミュニティが、最先端の推論性能で、特定のニーズに合わせてMPTモデルを自由に適応できるようにするものです。
プラグインによる柔軟性
新しいモデルアーキテクチャでTensorRT-LLMを拡張することは、スムーズなプロセスでした。TensorRT-LLM固有の柔軟性と、プラグインによってさまざまな最適化を追加できる機能によって、当社のエンジニアは、当社独自のモデリングニーズをサポートするために、TensorRT-LLMを迅速に変更することができました。この柔軟性により、開発プロセスが加速されただけでなく、NVIDIAチームがすべてのユーザー要件を単独でサポートする必要性も軽減されました。
LLM推論に不可欠なコンポーネント
各クラウドプラットフォームのすべてのGPUモデル(A10G、A100、H100)で、TensorRT-LLMの包括的なベ�ンチマークを実施しました。最小のコストで最適なレイテンシを達成するために、連続バッチサイズ、テンソルシャード、モデルのパイプライン化など、TensorRT-LLMの構成を最適化しました。私たちは、LLAMA-2 や Mixtral を含む大規模言語モデル(LLM)に対して、各クラウドやインスタンス構成に最適な推論構成を導入してきました。Databricksのモデルサービングを使えば、いつでも最高のLLMパフォーマンスを得ることができます!
統合を容易にするPython API
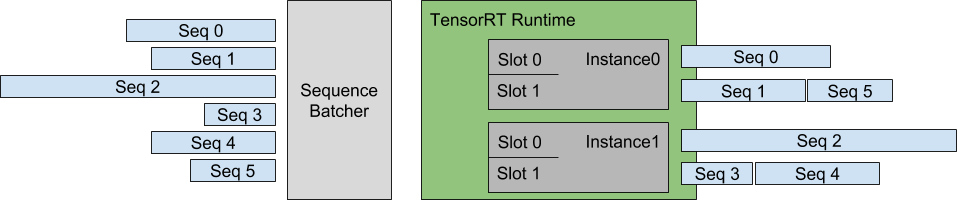
TensorRT-LLMのオフライン推論性能は、ネイティブのインフライト(連続)バッチングサポートと併用することで、より強力になります。インフライトバッチングは、トラフィックが多い環境で高いリクエストスループットを維持するために重要な要素であることがわかりました。最近、NVIDIAチームは、C++で書かれたバッチマネージャのPythonサポートに取り組んでおり、TensorRT-LLMをバックエンドのWebサーバにシームレスに統合できるようにしています。
早速試してみませんか?
Databricksのお客様であれば、AI Playground(現在パブリックプレビュー中)を通じて今日から推論サーバーを使用することができます。ログインして、左のナビゲーションバーの機械学習(Machine Learning)の下にあるPlaygroundの項目を見つけるだけです。
LLMをホストするための推論エンジンとしてTensorRT-LLMを統合する旅を通して、素晴らしい協力者であったNVIDIAのチームに感謝したいと思います。今後リリースされるDatabricks推論エンジンのイノベーションの基盤として、TensorRT-LLMを活用していきます。私たちは、以前の実装よりも向上した私たちのプラットフォームのパフォーマンスを共有できることを楽しみにしています。(効率的なLLM推論のための大規模なオープンソースコミュニティの取り組みであるvLLMは、別の素晴らしい選択肢を提供し、勢いを増していることも重要です)。
パフォーマンスの詳細については、来月のブログ記事をお楽しみに。