Databricks Unityカタログのボリュームのパブリックプレビューを発表
表形式以外のデータを発見し、管理し、照会する

翻訳:Junichi Maruyama. - Original Blog Link
Data and AI Summit 2023では、Databricks Unity CatalogのVolumesを紹介した。この機能により、Unity Catalog内の表形式データとともに、非構造化データ、半構造化データ、構造化データなど、あらゆる非表形式データの発見、管理、処理、系譜の追跡が可能になります。本日、AWS、Azure、GCPで利用可能なVolumesのパブリックプレビューを発表できることを嬉しく思います。
このブログでは、表形式以外のデータに関連する一般的なユースケースについて説明し、Unity CatalogのVolumesを使用した主な機能の概要を提供し、Volumesの実用的なアプリケーションを示す作業例を紹介し、Volumesを開始する方法の詳細を提供します。
非表形式データのガバナンスとアクセスに関連する一般的なユースケース
Databricks Lakehouse Platformは、大量のデータをさまざまな形式で保存し、処理することができます。これらのデータの多くはテーブルによって管理されますが、特に機械学習やデータサイエンスのワークロードでは、テキスト、画像、音声、動画、PDF、XMLファイルなど、テーブル以外のデータにアクセスする必要があるユースケースが多くあります。
私たちがお客様からお聞きした一般的な使用例には、以下のようなものがありますが、これらに限定されるものではありません:
- 画像、音声、動画、PDFファイルなどの非構造化データの大規模なコレクションに対して機械学習を実行する。
- モデルのトレーニングに使用されるトレーニング、テスト、検証データセットの永続化と共有、およびロギングやチェックポイントのディレクトリなどの運用データの場所の定義。
- データサイエンスにおけるデータ探索段階での、表形式でないデータファイルのアップロードとクエリ。
- クラウドオブジェクトストレージAPIをネイティブにサポートしておらず、代わりにクラスタマシン上のローカルファイルシステムにファイルを期待するツールでの作業。
- ライブラリ、証明書、および .whl や .txt など任意の形式のその他の設定ファイルを、クラスタライブラリ、ノートブックスコープライブラリ、またはジョブの依存関係の設定に使用する前に、ワークスペース全体で安全に保存し、アクセスできるようにする。
- ��インジェスト・パイプラインの初期段階で、Auto LoaderやCOPY INTOなどを使用して、テーブルにロードする前に生データ・ファイルをステージングおよび前処理する。
- ワークスペース内またはワークスペース間で、大規模なファイルコレクションを他のユーザと共有する。
Volumesを使用すると、クラウドストレージのパフォーマンスで、形式に関係なく非表形式データの大規模なコレクションを読み取り、処理するスケーラブルなファイルベースのアプリケーションを構築できます。
ガートナー®: Databricks、クラウドデータベースのリーダー

Volumes とは何ですか?
Volumes は、Unity カタログのディレクトリとファイルのコレクションをカタログ化する新しいタイプのオブジェクトです。ボリュームは、クラウドオブジェクトストレージの場所にあるストレージの論理ボリュームを表し、構造化データ、半構造化データ、非構造化データなど、あらゆる形式のデータにアクセス、保存、管理する機能を提供します。これにより、Unity Catalog 内の表形式データおよびモデルとともに、表形式以外のデータの管理、ガバナンス、系統追跡が可能になり、統一されたディスカバリーおよびガバナンスのエクスペリエンスが提供されます。
ボリュームに保存された画像データセットで画像分類を実行する
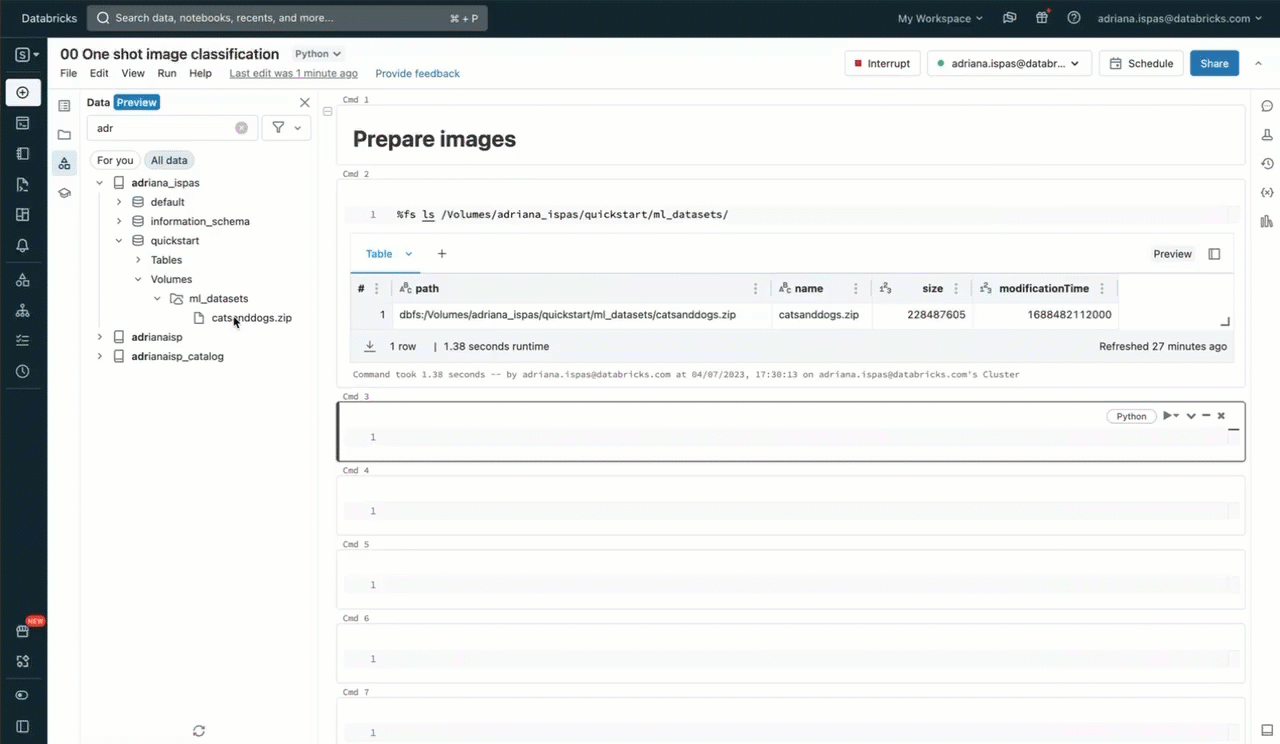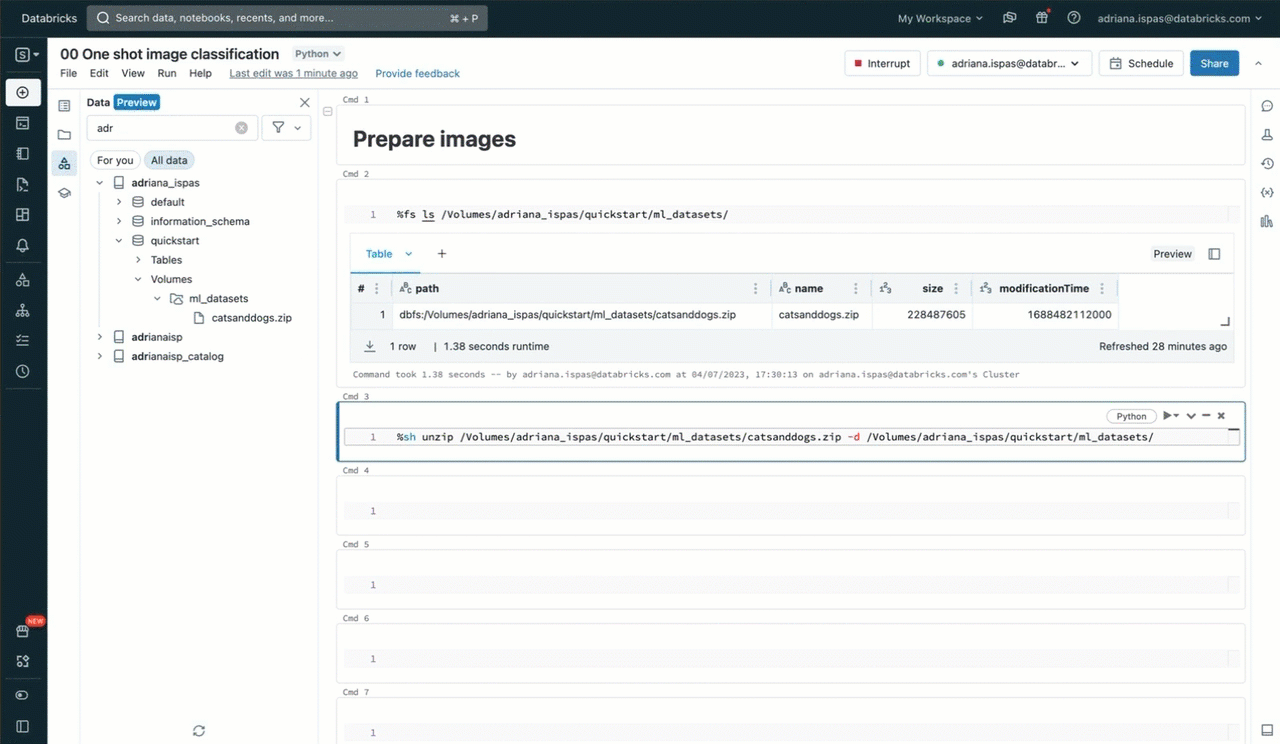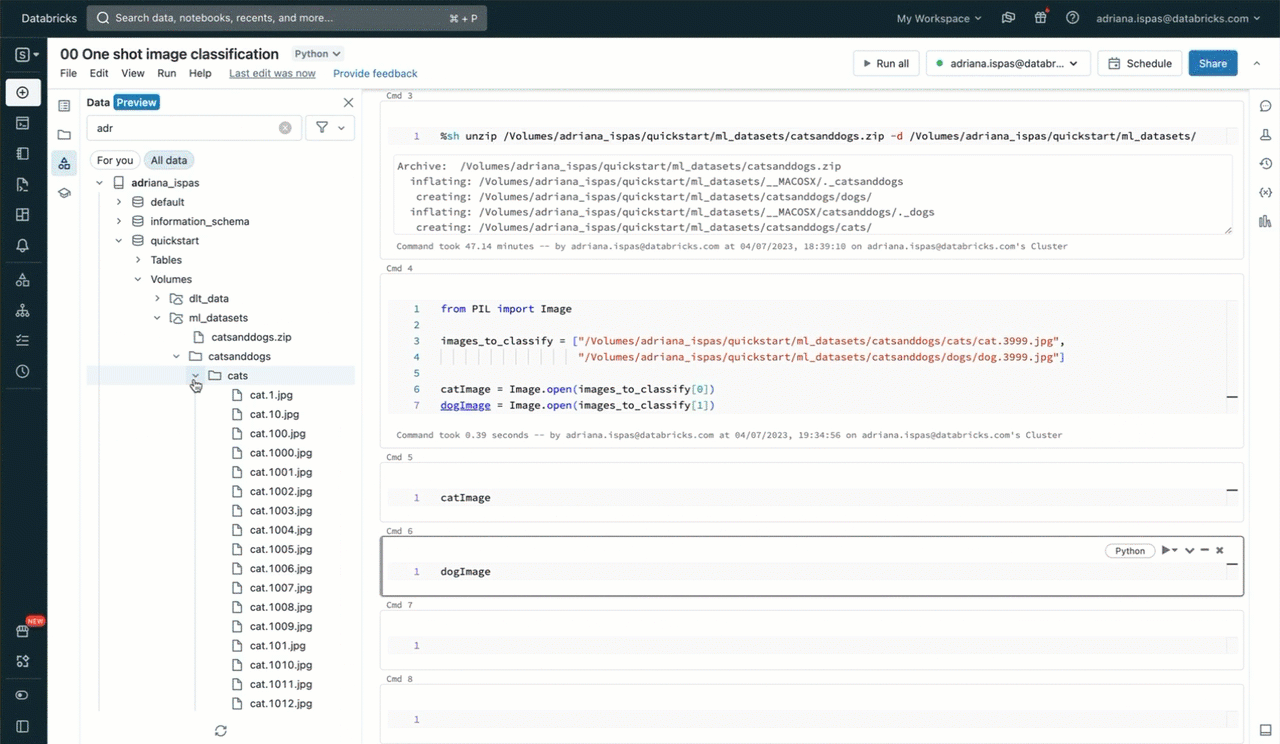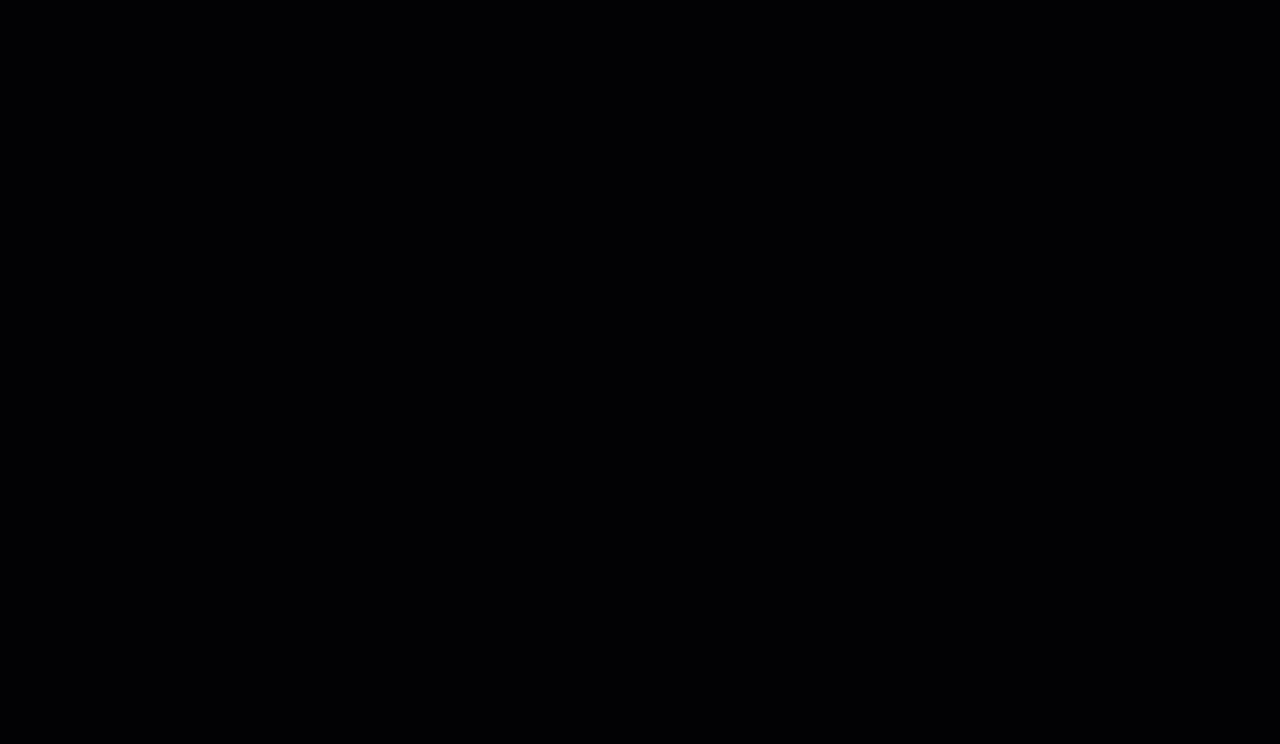
Volumeとその実用的な応用について理解を深めるために、例を挙げてみよう。猫と犬の画像からなるdatasetを使って、画像の分類に機械学習(ML)を利用したいとする。最初のステップは、これらの画像をローカル・マシンにダウンロードすることだ。我々の目的は、データサイエンスのためにこれらの画像をDatabricksに取り込むことだ。
そのために、Data Explorerユーザーインターフェイスを活用する。Unityカタログスキーマ内に新しいボリュームを作成します。その後、共同研究者にアクセス許可を与え、画像ファイルを含むアーカイブをアップロードします。書き込み権限を持つ既存のボリュームにファイルをアップロードするオプションもあることに注意してください。また、独自のVolumeを作成し、ノートブックやSQLエディタでSQLコマンドを使用してアクセス権を管理することもできます。
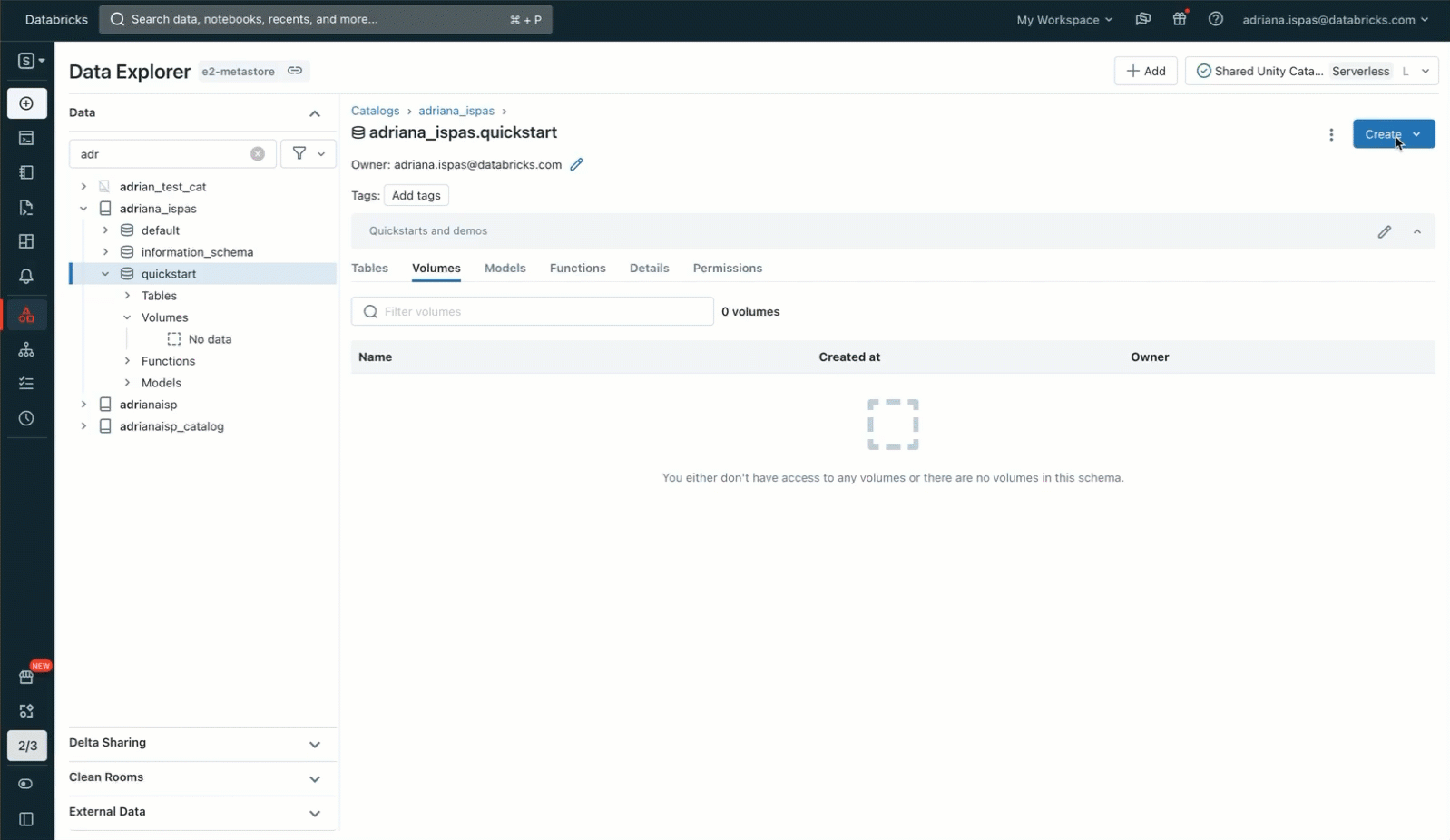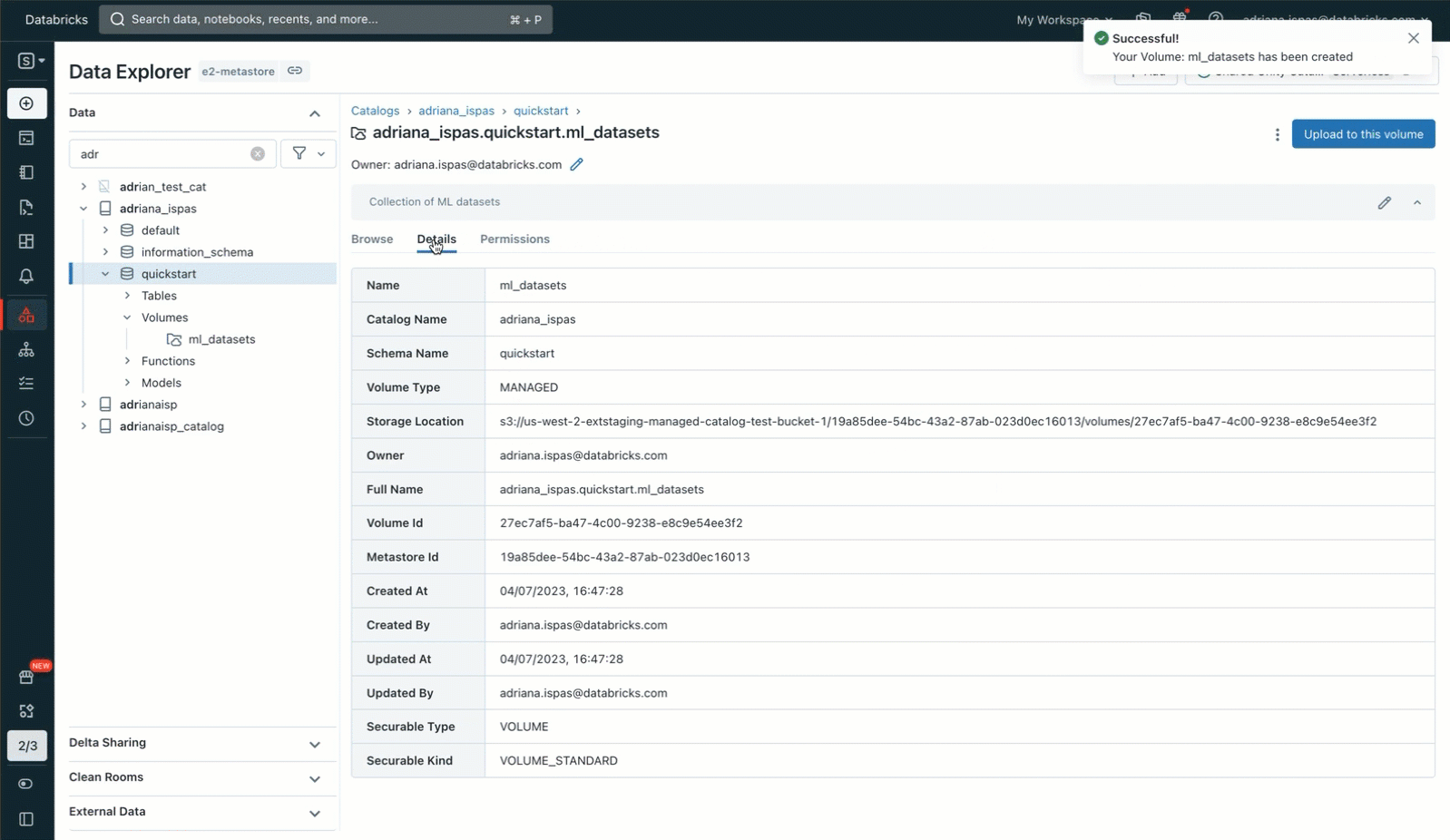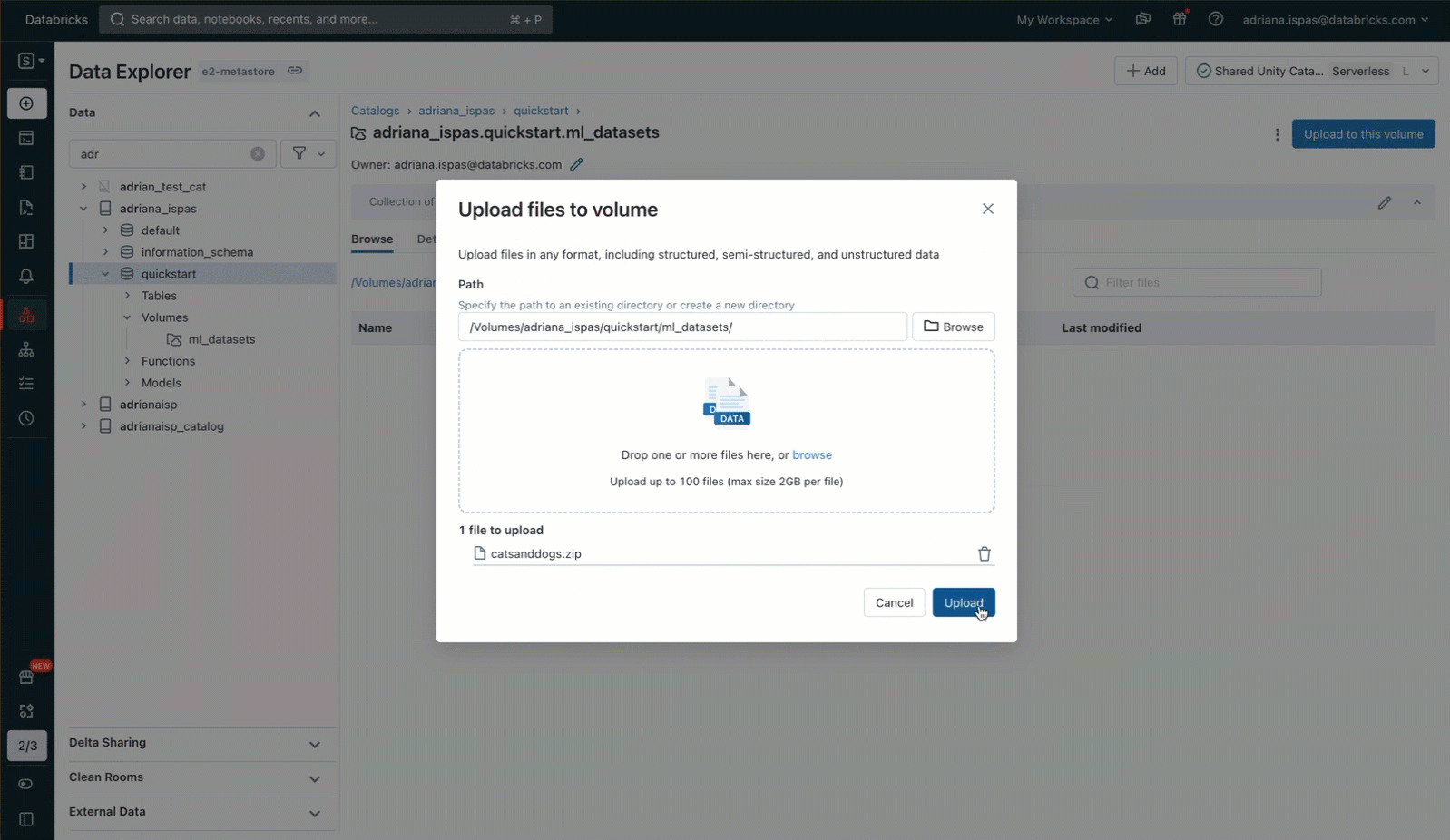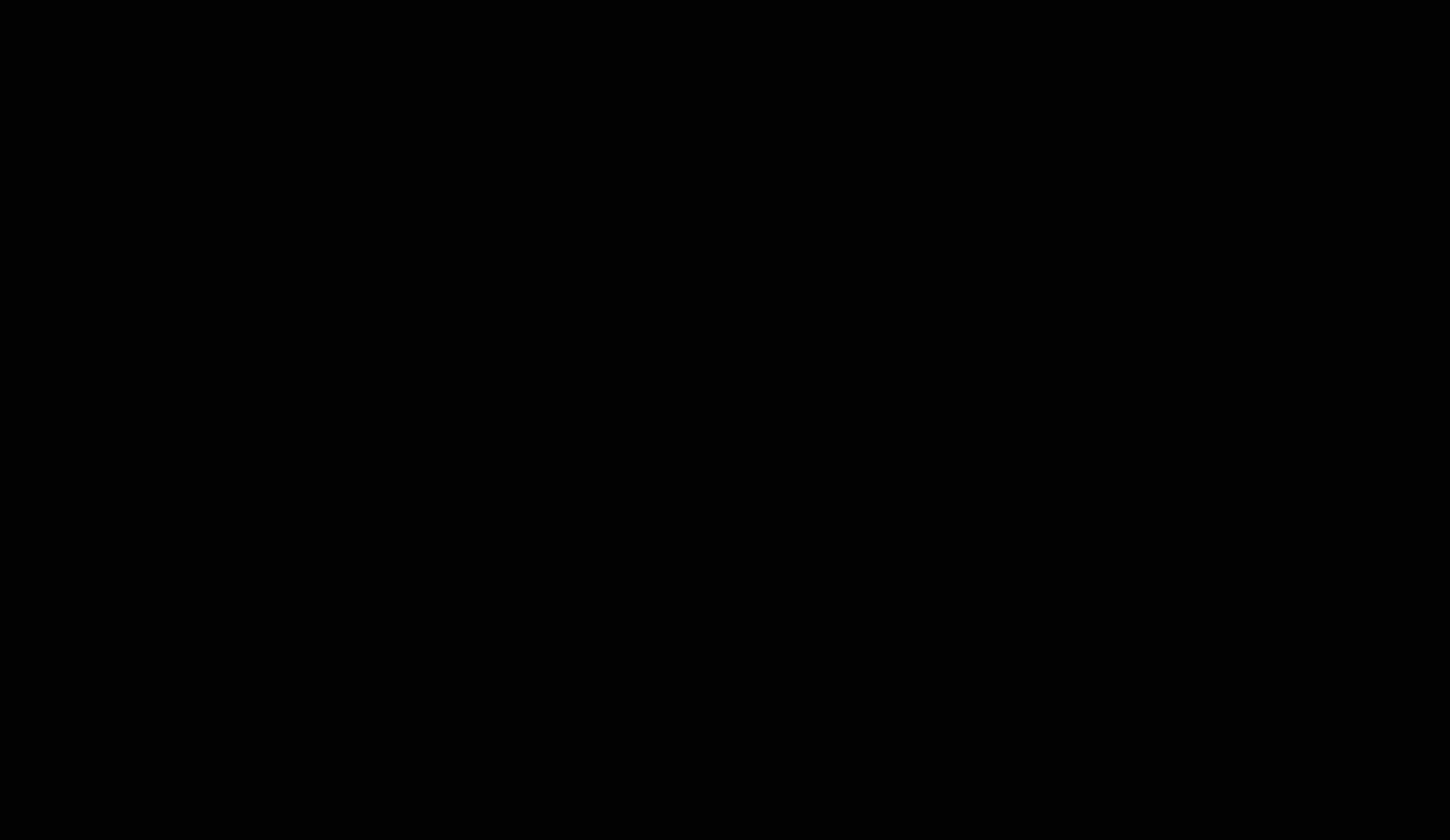
これで、よく使われるunzipユーティリティを使って、イメージアーカ��イブを解凍することができます。このコマンドには、特に私たちのVolumeに関連するパスが含まれていることは注目に値します。このパスはUnity Catalogリソース階層に対応し、Unity Catalogで定義されたパーミッションを尊重します。
このコマンドを実行するには、サイドバーからボリュームの内容にアクセスできる便利なノートブックを使うことができる。さらに、「パスのコピー」機能を使えば、ファイルの一覧表示や画像の表示など、ファイル関連のコマンドを入力するプロセスを短縮できる。
以下のスクリーンキャストは、完全なインタラクションの流れを示している。
事前に定義されたリストからラベルを使用して画像を分類するために、Unityカタログ内のMLflow Model Registryに事前に登録されたゼロショット画像分類モデルを利用します。以下に示すコードスニペットは、モデルをロードし、分類を実行し、結果の予測を表示する方法を示しています。以下に示す付属のスクリーンキャストは、これらの相互作用の視覚的な表現を提供します。
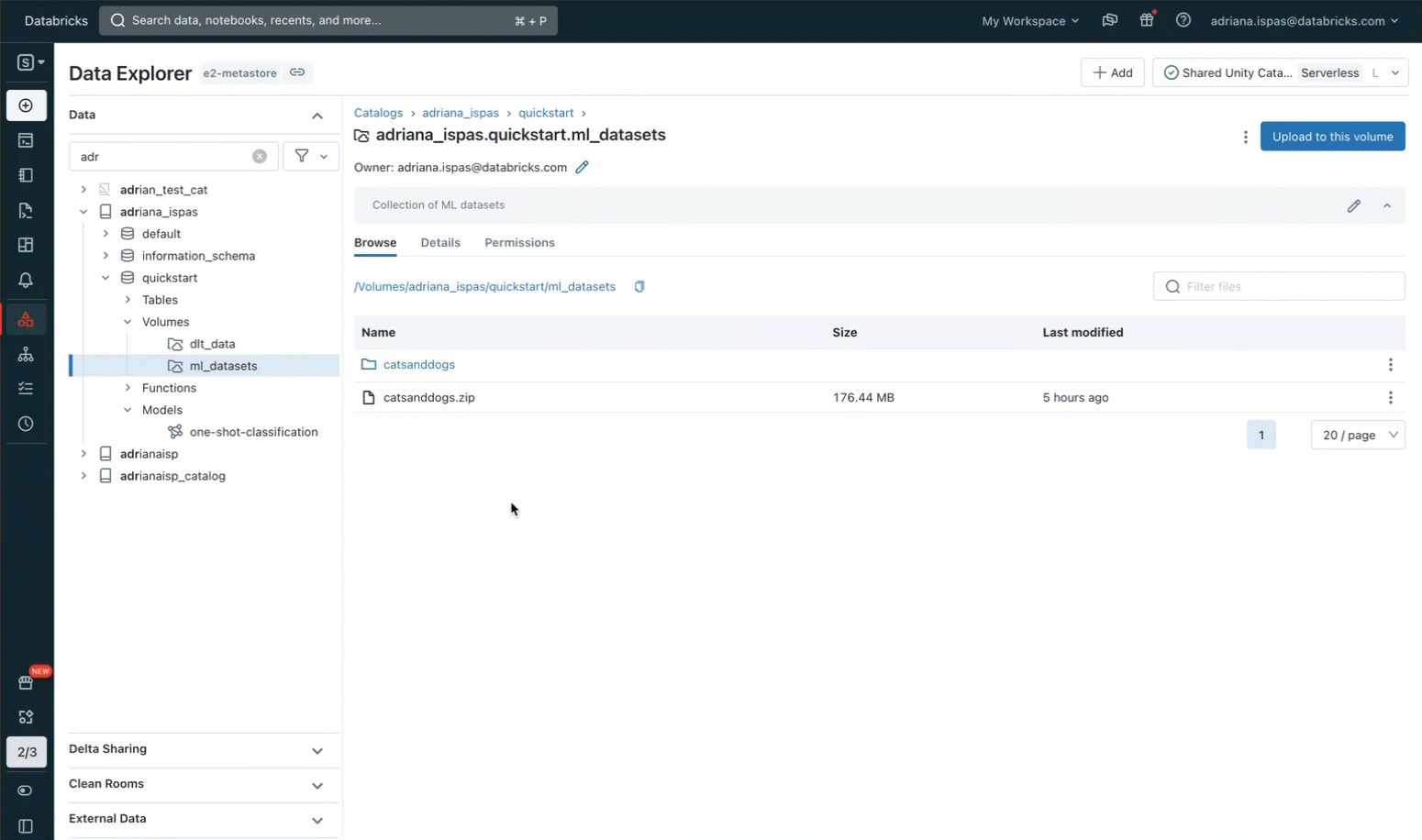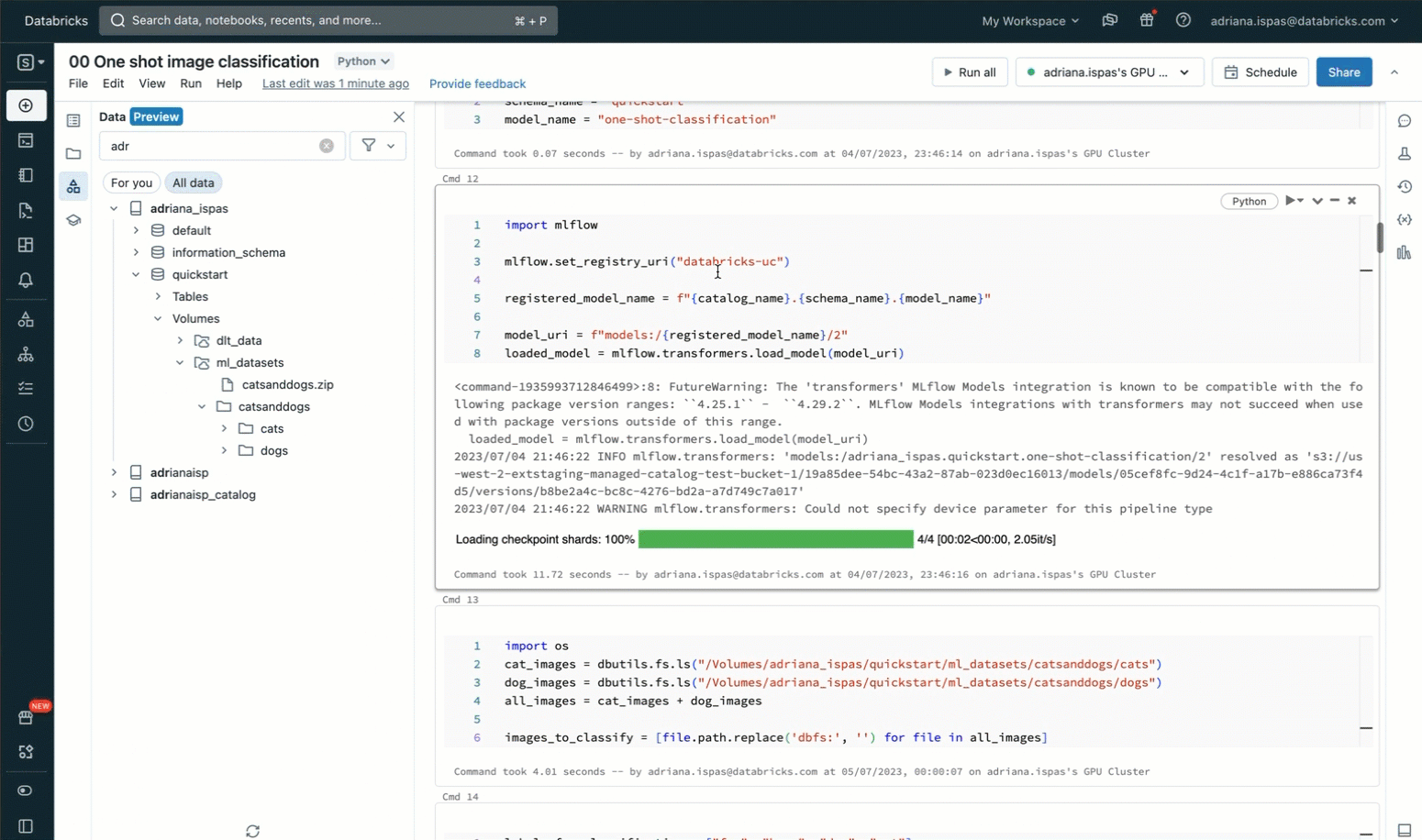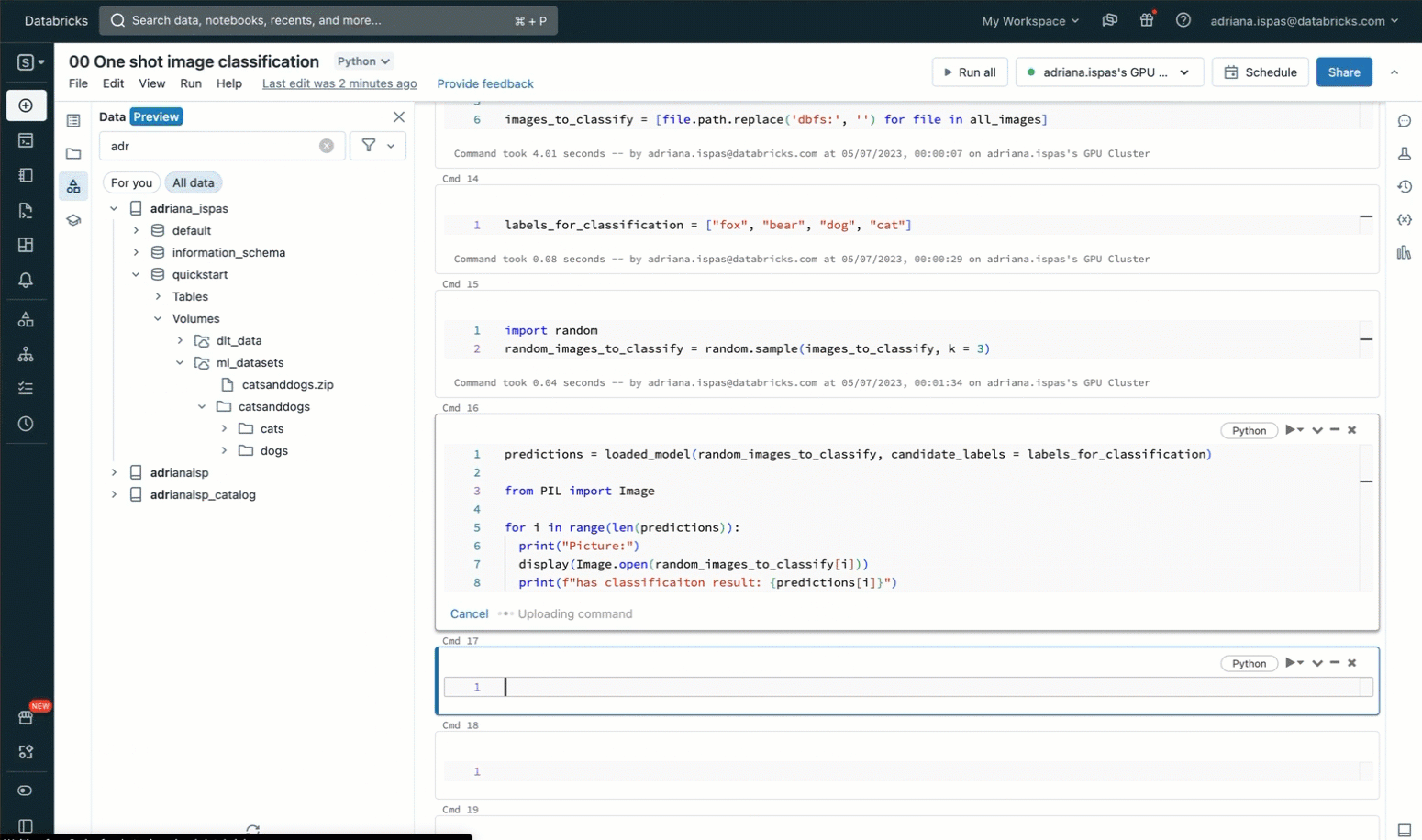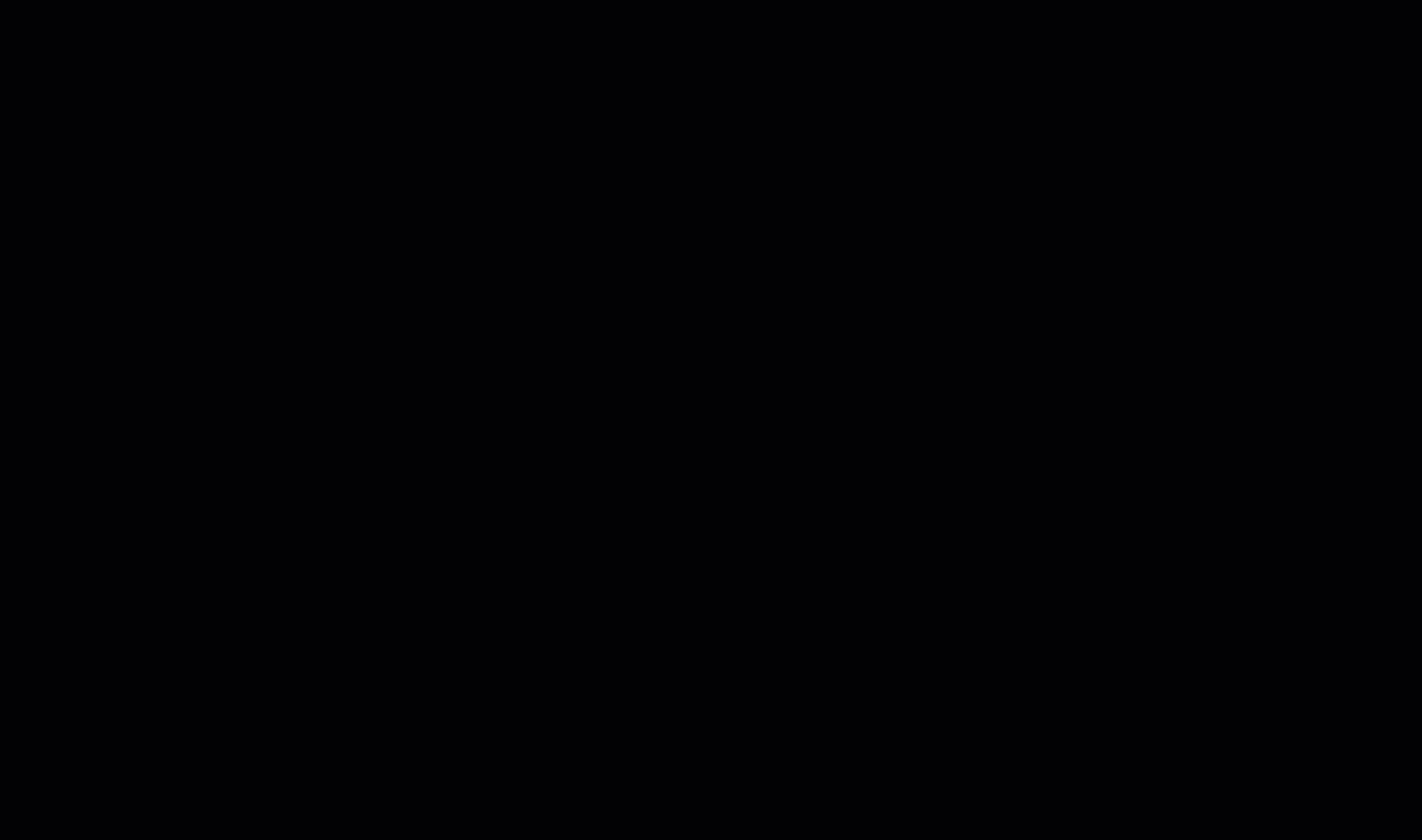
Unityカタログの必須ボリューム機能
Unityカタログで非表形式データを管理する. Volumeは、テーブル、モデル、関数と並んでUnity Catalogのスキーマ内でカタログ化され、Unity Catalogオブジェクトモデルの基本原則に従います。十分な権限を持つデータスチュワードはVolumeを作成し、Volumeの所有者となり、そのコンテンツにアクセスできる唯一のプリンシパルになることができます。そして、他のユーザーやグループにボリュームのコンテンツの読み取りと書き込みの権限を与えることができます。親カタログを必要なワークスペースにバインドすることで、ボリュームのアクセスを特定のワークスペースに制限することもできます。
管理ボリュームまたは外部ボリュームによる柔軟なストレージ構成. 管理ボリュームまたは外部ボリュームのいずれかを構成するオプションがあります。マネージドボリュームは、Unityカタログスキーマのデフォルトのストレージ場所にファイルを保存し、クラウドストレージへのアクセスを最初に構成するオーバーヘッドなしにファイルの保存場所を管理したい場合に便利なソリューションです。外部ボリュームは、ボリュームの作成時に参照される外部ストレージの場所にファイルを保存します。他のシステムで作成されたファイルをDatabricks内からアクセスできるようにステージングする必要がある場合に便利です。例えば、IoTや医療機器によって生成された画像やビデオデータの大規模なコレクションが保存されているクラウドストレージへの直接アクセスを提供することができます。
クラウドストレージのパフォーマンスとスケールでデータを処理する. Volumesはクラウドオブジェクトストレージによってバックアップされるため、クラウドストレージの耐久性、可用性、拡張性、安定性の恩恵を受けることができます。Volumesを使用して、高トラフィックのワークロードをクラウドストレージのパフォーマンスで実行し、ペタバイト以上のスケールのデータを処理することができます。
最先端のユーザーインターフェースで生産性を向上: Volumeは、Data Explorer、ノートブック、Lineage、Add Data、クラスタライブラリ構成のユーザーインターフェイスを含む、Databricks Platformのエクスペリエンス全体にシームレスに統合されています。ボリュームの権限と所有権の管理、ボリュームのエンティティの作成、名前変更、削除などのアクションによるボリュームのライフサイクルの管理、ファイルのブラウズ、アップロード、ダウンロードなどのボリュームのコンテンツの管理、ノートブックと一緒にボリュームのブラウズとそのコンテンツのブラウズ、リネージの検査、クラスタライブラリやジョブライブラリのソースの設定など、様々なアクションにユーザーインターフェイスを使用することができます。
ファイル操作に使い慣れたツールを活用 Volumesは、Unityカタログ階層を反映し、Databricks間で使用する際に定義されたパーミッションを尊重する、ファイルにアクセスするための専用パス形式を導入します:
You can use the path to reference files inside Apache Spark™ and SQL commands, REST APIs, Databricks file system utilities (dbutils.fs), the Databricks CLI, Terraform, or when using various operating system libraries and file utilities. Below is a non-exhaustive list with usage examples.
| Usage | Example |
|---|---|
| Databricks file system utilities | dbutils.fs.ls("/Volumes/my_catalog/my_schema/my_volume/") |
| Apache Spark™ APIs | spark.read.text("/Volumes/my_catalog/my_schema/my_volume/data.txt").show() |
| Apache Spark™ SQL / DBSQL | SELECT * FROM csv.`/Volumes/my_catalog/my_schema/my_volume/data.csv` |
| Pandas | import pandas as pd |
| Shell commands via %sh | %sh curl http://<address>/text.zip > /Volumes/my_catalog/my_schema/my_volume/tmp/text.zip |
| Library installs using %pip | %pip install /Volumes/my_catalog/my_schema/my_volume/my_library.whl |
| Operating system file utilities | import os |
Unityカタログで管理されるデータの新しい処理能力を引き出す. Volumes は、s3a://, abfss://, or gs://, などのクラウド固有の API や Hadoop コネクタを抽象化し、Apache Spark™ Spark アプリケーションや、オブジェクトストレージ API をネイティブにサポートしていないツールで、クラウドに保存されたデータファイルを簡単に扱えるようにします。専用のVolumeファイルパスを使用すると、ファイルがクラスタノードにローカルであるかのように、Volumeのコンテンツにアクセス、トラバース、処理することができます。これは、Pandas, scikit-learn、TensorFlow kerasなど、さまざまなデータサイエンスやMLライブラリと連携する際に特に便利です。
UnityカタログでVolumesを使い始める
Unity Catalog Volumesは、Databricks Runtime 13.2 以降の Databricks Enterprise および Pro Tier で利用できるようになりました。 Volumesを使い始めるために、包括的なステップバイステップガイドを用意しました。既に Databricks アカウントをお持ちの場合は、最初の Volume (AWS | Azure | GCP) を作成するための詳細な手順が記載されたドキュメントに従ってください。 Volumeを作成したら、Data Explorer (AWS | Azure | GCP)を活用して内容を調べたり、Volume管理用のSQL構文(AWS | Azure | GCP))を学ぶことができます。また、Volumeを最大限に活用するためのベストプラクティス(AWS | Azure | GCP)を確認することをお勧めします。Databricksが初めてでまだアカウントをお持ちでない方は、無料トライアルにサインアップしてUnityカタログのVolumesの利点を直接体験してください。
Delta Sharingを使用したVolumeの共有機能や、ファイルのアップロード、ダウンロード、削除などのファイル管理操作のためのREST APIなど、エキサイティングなVolumes機能の数々にご期待ください。
またWhat's new with Unity Catalog、ベスト・インプリメンテーション・プラクティスのためのdeep dive session、Everything You Need to Know to Manage LLMsについてのData and AI Summitセッションもご覧いただけます。