ソフトウェア開発およびDevOpsのベストプラクティスをDelta Live Tableパイプラインに適用
Delta Live Tablesのユニット/インテグレーションテストとCI/CDの実装

Original Blog : Applying software development & DevOps best practices to Delta Live Table pipelines
翻訳: junichi.maruyama
Databricks Delta Live Tables(DLT)は、データエンジニアが記述・維持する必要のあるコード量を減らすことで、堅牢なデータ処理パイプラインの開発を根本的に簡素化します。また、環境間でコードとパイプラインの構成をシームレスに推進できるようにしながら、データのメンテナンスとインフラ運用の必要性を低減します。しかし、パイプラインに含まれるコードのテストを行う必要があり、それを効率的に行う方法につい��てよく質問を受けます。
このブログでは、複数のお客様との共同作業の経験に基づき、以下の項目を取り上げます:
- DevOpsのベストプラクティスをDelta Live Tablesに適用する方法
- ユニットテストと統合テストを容易にするために、DLTパイプラインのコードをどのように構成するか
- DLTパイプラインの個々の変換の単体テストを実施する方法
- DLTパイプライン全体を実行することで統合テストを行う方法
- ステージ間でDLT資産を促進する方法
- すべてをまとめてCI/CDパイプラインを形成する方法(Azure DevOpsを例として)
DevOpsのプラクティスをDLTに適用する:その全体像
DevOpsの実践は、ソフトウェア開発ライフサイクル(SDLC)を短縮し、同時に高い品質を提供することを目的としています。一般的に、以下のようなステップがあります:
- ソースコードとインフラストラクチャのバージョン管理
- コードレビュー
- 環境の分離(開発/ステージング/本番)。
- ユニットテストと統合テストによる、個々のソフトウェアコンポーネントと製品全体のテストの自動化。
- 継続的な統合(テスト)と変更の継続的な展開(CI/CD)。
これらのプラクティスはすべて、Delta Live Tablesのパイプラインにも適用することができます:
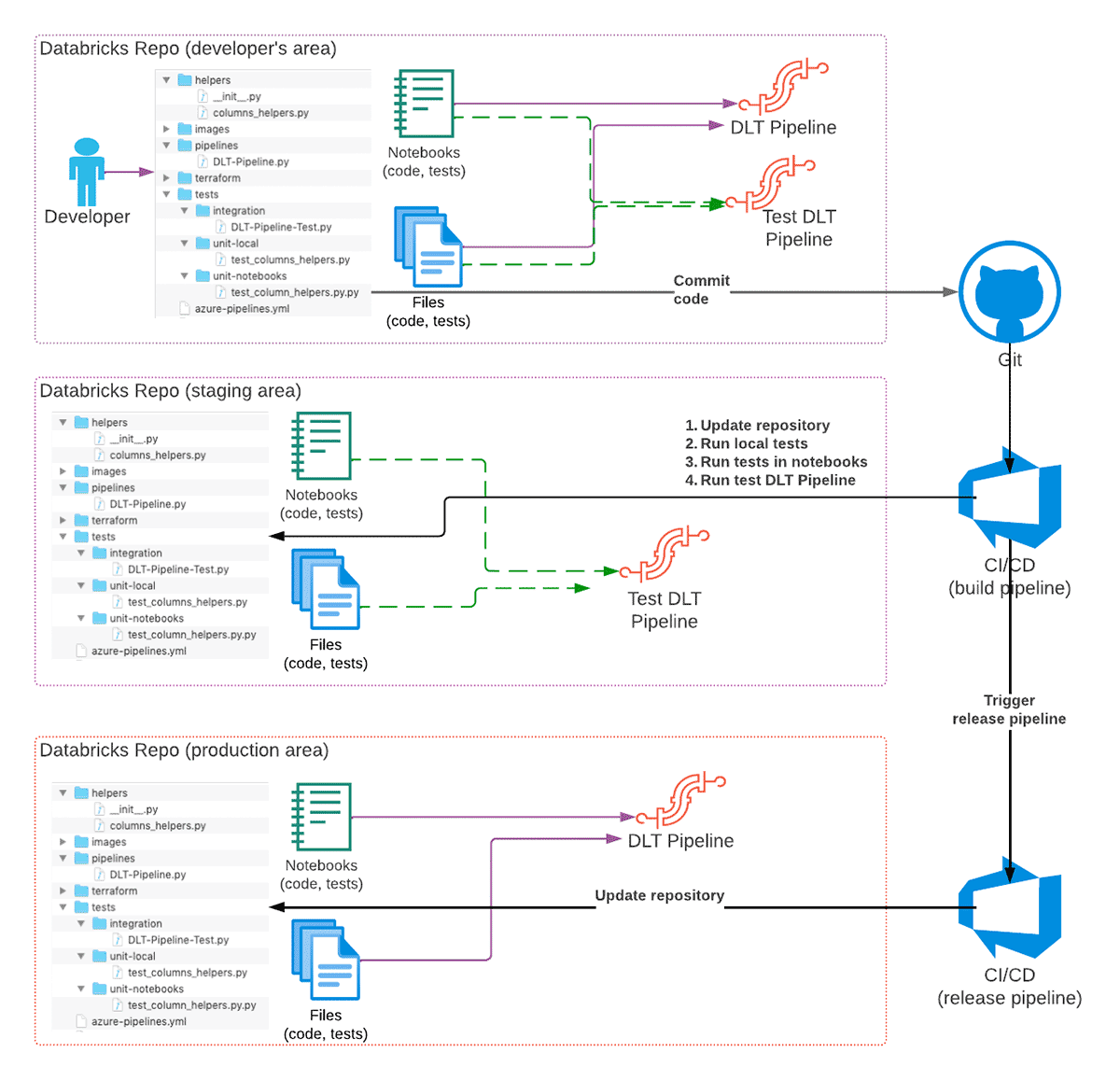
これを実現するために、私たちはDatabricksの製品ポートフォリオの以下の機能を利用しています:
- Databricks Reposは様々なGitサービスへのインターフェースを提供するので、コードのバージョン管理、CI/CDシステムとの統合、環境間でのコードの推進に利用することができます。
- Databricks CLI (またはDatabricks REST API)でCI/CDパイプラインを実装できます。
- Databricks Terraform Providerは、必要なインフラをすべてデプロイし、最新の状態に維持します。
DLTパイプラインの推奨されるハイレベルな開発ワークフローは、以下の通りです:
- 開発者は、Git リポジトリの自分自身のチェックアウトで、変更用に別の Git ブランチを使用して DLT コードを開発しています。
- コードの準備が整い、テストされると、コードはGitにコミットされ、プルリクエストが作成されます。
- CI/CDシステムはコミットに反応し、ビルドパイプライン(CI/CDのCI部分)を開始し、ステージングDatabricks Repoを�変更内容で更新し、ユニットテストの実行を開始します。
a) オプションとして、統合テストも実行することができますが、場合によっては、一部のブランチに対してのみ、または別のパイプラインとして実行することもできます。 - すべてのテストが成功し、コードのレビューが行われた場合、変更はGitリポジトリのメイン(または専用のブランチ)にマージされます。
- 特定のブランチ(例えばリリース)への変更のマージは、本番環境のDatabricks Repoを更新するリリースパイプライン(CI/CDのCD部分)をトリガーする場合があり、コードの変更はパイプラインが次回実行するときに反映されます。
ここでは、2つのテーブルからなる非常にシンプルなDLTパイプラインを用いて、典型的なLakehouseアーキテクチャのブロンズ/シルバー層を説明します。完全なソースコードと導入手順はGitHubで公開されています。

Note: DLTはSQLとPythonの両方のAPIを提供しています。このブログではPythonの実装に焦点を当てますが、SQLベースのパイプラインにもほとんどのベストプラクティスを適用することができます
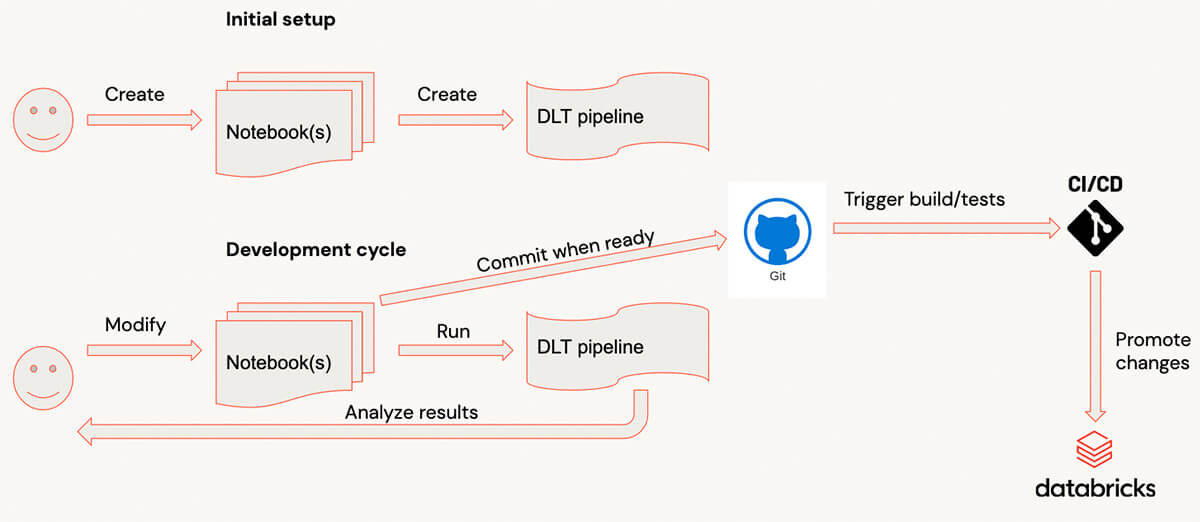
Delta Live Tablesによる開発サイクル
Delta Live Tablesで開発する場合、典型的な開発プロセスは次のようになります:
- コードはノートブックに書かれる
- コードの準備ができたら、DLT UIに切り替えてパイプラインを開始します。(このプロセスを高速化するために、パイプラインを開発モードで実行することをお勧めします(リソースを何度も待つ必要はありません)
- パイプラインが終了するか、エラーで失敗すると、ユーザーは結果を分析し、コードを追加/修正し、このプロセスを繰り返します
- コードの準備ができたら、コミットする
数十のテーブルやビューを持つ複雑なパイプラインでは、パイプラインのスタートアップが比較的長くなり、多くのライブラリが接続されている場合、このような開発サイクルは大きなオーバーヘッドになる可能性があります。ユーザーにとっては、個々の変換を評価し、対話型クラスタ上のサンプルデータでテストすることで、非常に速いフィードバックを得ることが容易になります。
DLTパイプラインのコードの構造化
個々の関数を評価し、テスト可能にするためには、正しいコード構造を持つことが非常に重要である。通常のアプローチでは、すべてのデータ変換をSpark DataFrameを受け取って返す個々の関数として定義し、DLT実行グラフを形成するDLTパイプライン関数からこれらの関数を呼び出すことになります。これを実現する最善の方法は、Databricksノートブックや他のPythonコードにインポート可能な通常のPythonモジュールとしてPythonファイルを公開することができるfiles in repos機能を使用することです。DLTは、PythonファイルをPythonモジュールとしてインポートできるfiles in reposをネイティブでサポートしています(files in reposを使用する場合、Pythonのsys.pathに二つの項目が追加されることに注意してください-一つはリポジトリのルート、一つは呼び出し元のノートブックの現在のディレクトリです)。これで、レポルート下の専用フォルダにある別のPythonファイルとしてコードを書き始め、Pythonモジュールとしてインポートすることができます:
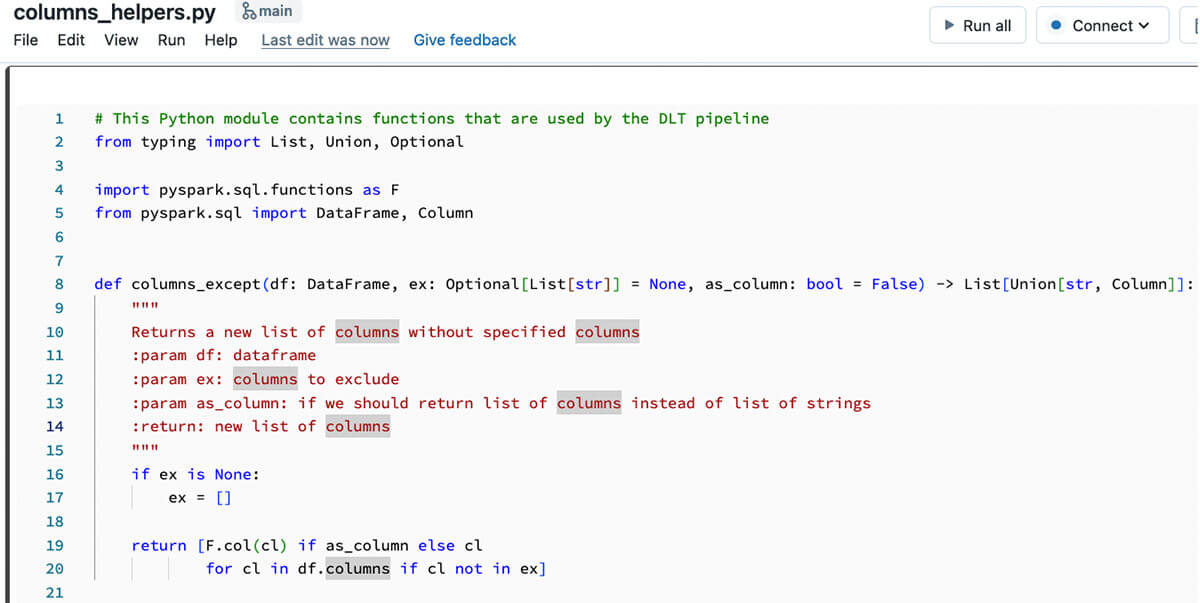
そしてこのPythonパッケージのコードは、DLTパイプラインのコード内部で使用することができます:
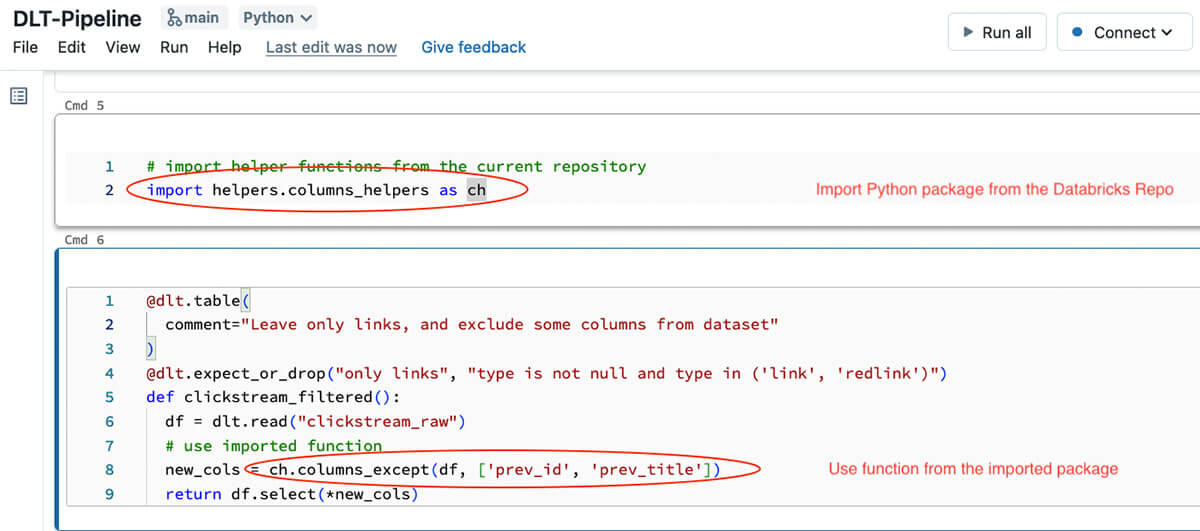
このDLTコードスニペットの関数は非常に小さいもので、上流テーブルからデータを読み込み、Pythonモジュールで定義した変換を適用するだけであることに注意してください。このアプローチにより、DLTコードをよりシンプルに理解できるようになり、ローカルまたは対話型クラスタに接続された別のノートブックを使用してテストすることが容易になります。変換ロジックを別のPythonモジュールに分割することで、ノートブックから変換をインタラクティブにテストしたり、変換のユニットテストを書いたり、パイプライン全体をテストすることができます(テストについては次のセクションで説明します)
ユニットテストと統合テストを含むDatabricks Repoの最終的なレイアウトは、以下のようになります:
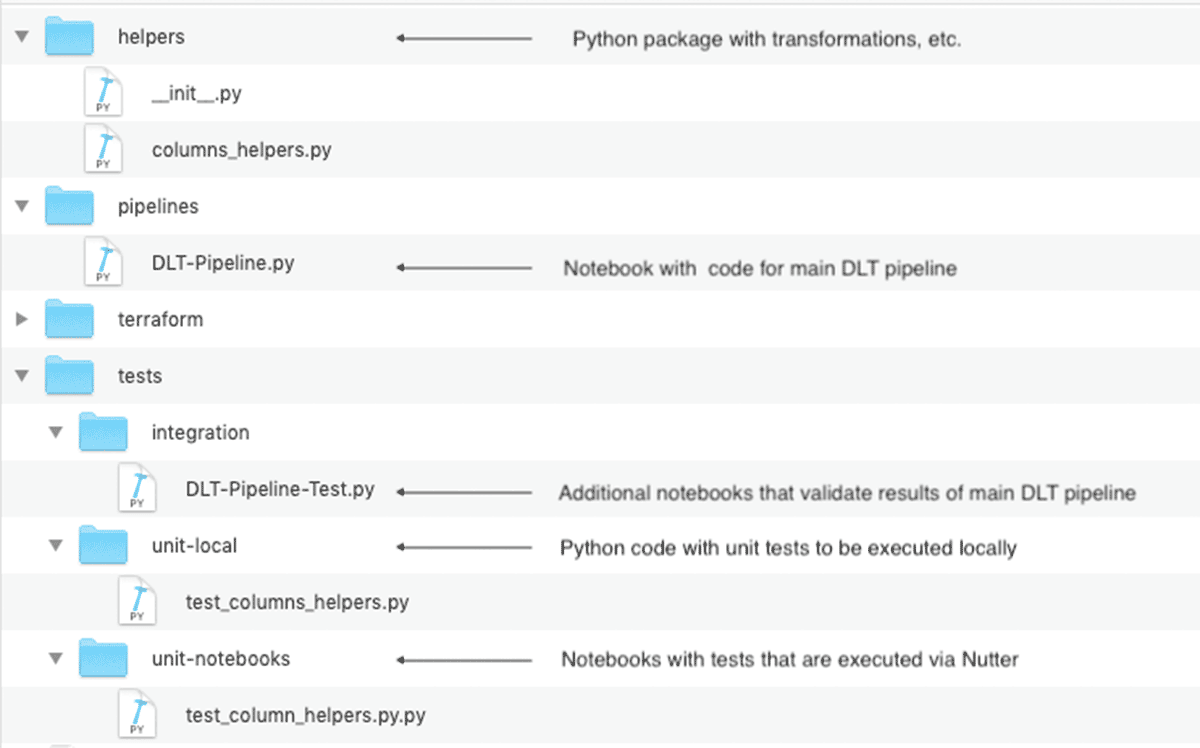
このコード構造は、複数のDLTパイプラインが共通の変換を共有するような大規模プロジェクトでは特に重要です
単体テストを実装する
前述のように、変換を別のPythonモジュールに分割することで、個々の関数の動作をチェックするユニットテストを簡単に書くことができます。このユニットテストをどのように実装するかは自由です:
- 例えば、pytestを使ってローカルに実行できるPythonファイルとして定義することができます。この方法には、次のような利点があ�ります:
- IDEを使用してこれらの変換を開発・テストし、例えばDatabricks extension for Visual Studio Codeまたは他のIDEを使用している場合はdbx syncコマンドを使用してローカルコードをDatabricksリポジトリに同期することができます。
- このようなテストは、Databricksのリソースを使用することなくCI/CDビルドパイプライン内で実行することができます(ただし、Databricks固有の機能が使用されているか、コードがPySparkで実行されているかによるかもしれません)。
- 静的コード・コードカバレッジ解析、コードリファクタリングツール、対話型デバッグなど、より多くの開発関連ツールにアクセスできるようになります。
- Pythonのコードをライブラリとしてパッケージ化し、複数のプロジェクトに添付することも可能です。
- ノートブックで定義することもできます:
- サンプルコードやテストを常にインタラクティブに実行できるため、フィードバックをより早く得ることができます。
- Nutter のような追加ツールを使って、CI/CDビルドパイプラインから(またはローカルマシンから)ノートブックの実行をトリガーし、結果を収集してレポートすることができます。
デモリポジトリには、ローカルでテストを実行する方法と、ノートブックとしてテストを実行する方法の、両方のアプローチのサンプルコードが含まれています。CI pipelineでは、両方のアプローチを示しています。
もしSQLを使ってDLTパイプラインを実装するのであれば、次のセクションで説明するアプローチに従う必要があることに注意してください。
統合テストの実施
単体テストは個々の変換が正常に動作していることを保証してくれますが、パイプライン全体が正常に動作していることを確認する必要があります。通常、これはパイプライン全体を実行する統合テストとして実装されますが、通常はより少ないデータ量で実行され、実行結果を検証する必要があります。Delta Live Tablesでは、統合テストを実装する方法が複数用意されています:
- 複数のタスクからなるDatabricksワークフローとして実装する(DLT以外のコードで一般的に行われていることと同様)。
- パイプラインの結果をチェックするために、DLTの期待値を使用する。
Databricks Workflowsを使った統合テストの実装
この場合、Databricks ワークフローを使用して、複数のタスクからなる統合テストを実装することができます(タスクの値を使用して、タスク間でデータの場所などのデータを渡すこともできます)。通常、このようなワークフロー��は以下のようなタスクで構成されています:
- DLTパイプラインのためのデータをセットアップする。
- このデータに対してパイプラインを実行する。
- 生成された結果の検証を行う。
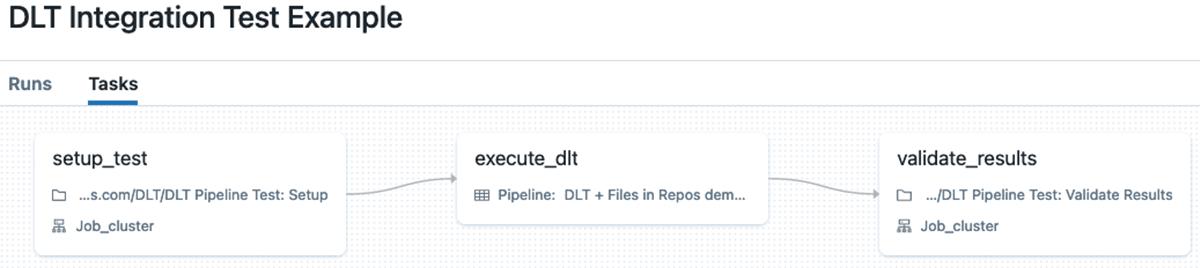
この方法の主な欠点は、セットアップと検証タスクのためにかなりの量の補助コードを書く必要があり、さらにセットアップと検証タスクを実行するために追加の計算リソースが必要であることです。
統合テストを実施するためにDLTの期待を利用する
DLTパイプラインにDLTテーブルを追加して拡張することで、DLTの統合テストを実施できます。DLTテーブルは、DLTの期待値をデータに適用し、結果が提供された期待値と一致しない場合はfail演算子を使用してパイプラインを失敗させます。DLTパイプラインを別途作成し、DLTテーブルを定義するノートブックを追加して、期待値を付加するだけです。
例えば、シルバーテーブルがtypeカラムに許可されたデータのみを含むことをチェックするには、以下のDLTテーブルを追加し�て、それに期待値を付けます:
統合テストのDLTパイプラインは、次のようになります(実行グラフには、データが有効であることを確認するためのテーブルが2つ追加されています):
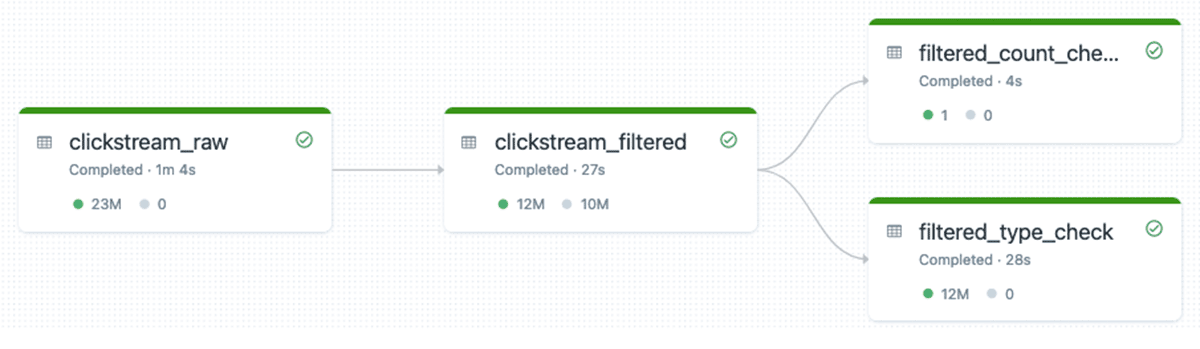
これは、DLTパイプラインの統合テストを実行するための推奨アプローチです。このアプローチでは、追加の計算リソースは必要ありません。すべてが同じDLTパイプラインで実行されるため、クラスタの再利用が可能で、すべてのデータはDLTパイプラインのイベントログに記録され、レポート作成などに使用することができます。
行の一意性のチェック、結果における特定の行の存在のチェックなど、高度な検証のためにDLT期待を使用する例については、DLTドキュメントを参照してください。また、DLT期待値のライブラリを共有Pythonモジュールとして構築し、�異なるDLTパイプライン間で再利用することも可能です。
環境間のDLT資産の普及を図る
DLTの文脈で変革の促進を語るとき、複数の資産について語ることになる:
- パイプラインの変換を定義するソースコード。
- 特定のDelta Live Tablesパイプラインのための設定。
コードを促進する最もシンプルな方法は、Databricks Reposを使用してGitリポジトリに保存されたコードを扱うことです。Databricks Reposでは、コードのバージョン管理ができるほか、Repos REST API or Databricks CLIを使って、コードの変更を他の環境に簡単に伝搬させることができます。
DLTでは最初からコードをパイプラインの構成から分離し、スキーマやデータの場所などを指定できるようにしてステージ間の昇格を容易にしています。そのため、各ステージで同じコードを使用しながら、異なる場所にデータを保存したり、異なるクラスタサイズを使用したりすることができる、個別のDLT設定を定義することができます。
パイプラインの設定を定義するには、Delta Live Tables REST APIやDatabricks CLIのpipelinesコマンドを使用しますが、インスタンスプールやクラスタポリシー、その他の依存関係を使用する必要がある場合は、難しくなります。この場合、より柔軟な選択肢として、Databricks Terraform Providerのdatabricks_pipelineリソースがあり、他のリソースへの依存関係を簡単に扱うことができ、Terraformモジュールを使用してTerraformコードをモジュール化して再利用できるようにすることができます。提供されるコードリポジトリには、DLTパイプラインを複数の環境にデプロイするためのTerraformのコード例が含まれています。
すべてをまとめてCI/CDパイプラインを形成する
個々のパーツをすべて実装した後、CI/CDパイプラインを実装するのは比較的簡単です。GitHubリポジトリにはAzure DevOps用のビルドパイプラインが含まれています(他のシステムもサポート可能です - 違いは通常ファイル構造です)。このパイプラインには2つのステージがあり、特定のイベントに応じて異なるテストセットを実行する能力を示しています:
- onPushは、releaseブランチとバージョンタグを除くすべてのGitブランチにプッシュしたときに実行されます。このステージでは、ユニットテストの結果(ローカルとノートブックの両方)を実行し報告するだけです。
- onReleaseはreleasesブランチへのコミット時にのみ実行され、ユニットテストに加え、統合テストを含むDLTパイプラインが実行されます。
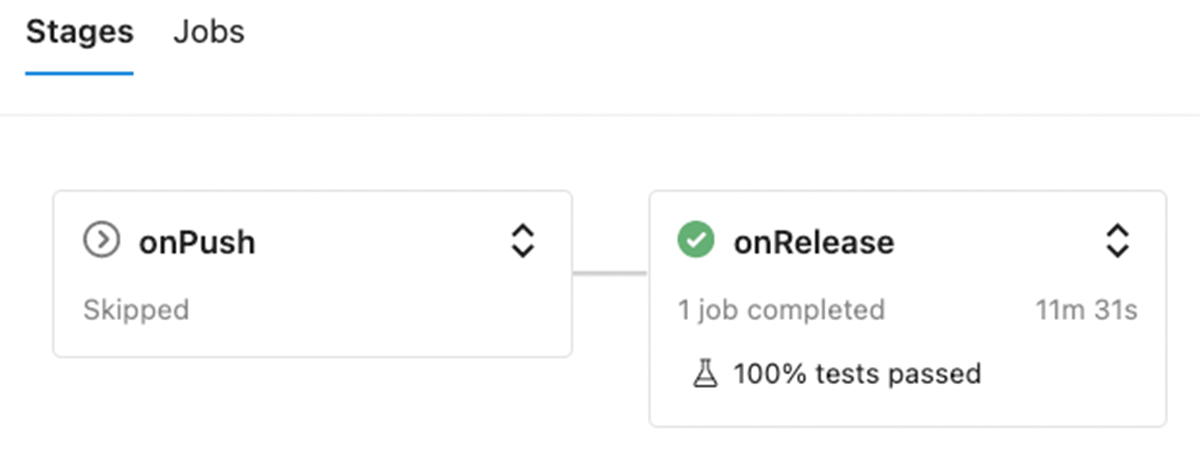
onReleaseステージで統合テストを実行する以外は、両ステージの構成は同じで、以下のステップで構成されます:
- 変更のあったブランチをチェックアウトします。
- 環境のセットアップ - Pythonの環境管理に使用するPoetryをインストールし、必要な依存関係をインストールします。
- ステージング環境のDatabricks Reposを更新します。
- PySparkを使用してローカルのユニットテストを実行します。
- Databricksのノートブックとして実装されたユニットテストをNutterを使って実行する。
- リリースブランチの場合、統合テストを実行する。
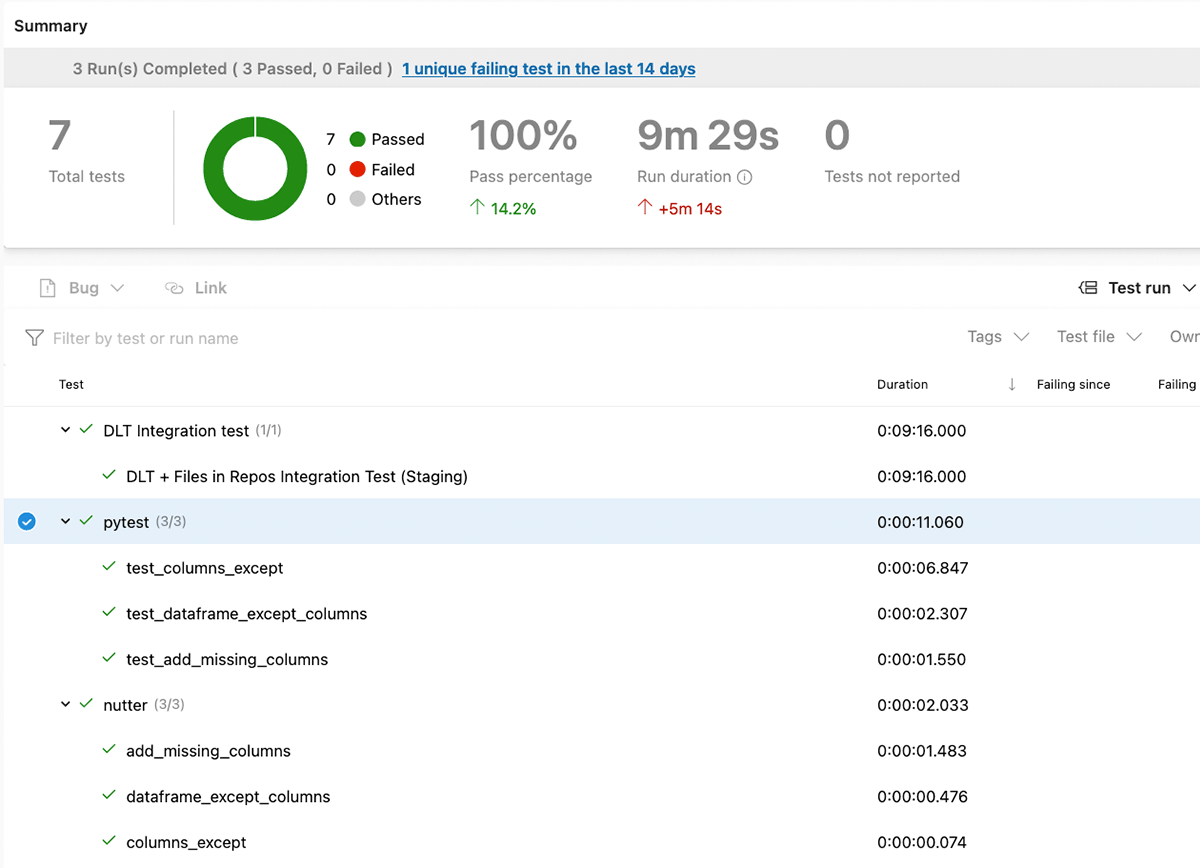
- テスト結果を収集し、Azure DevOpsに公開する。
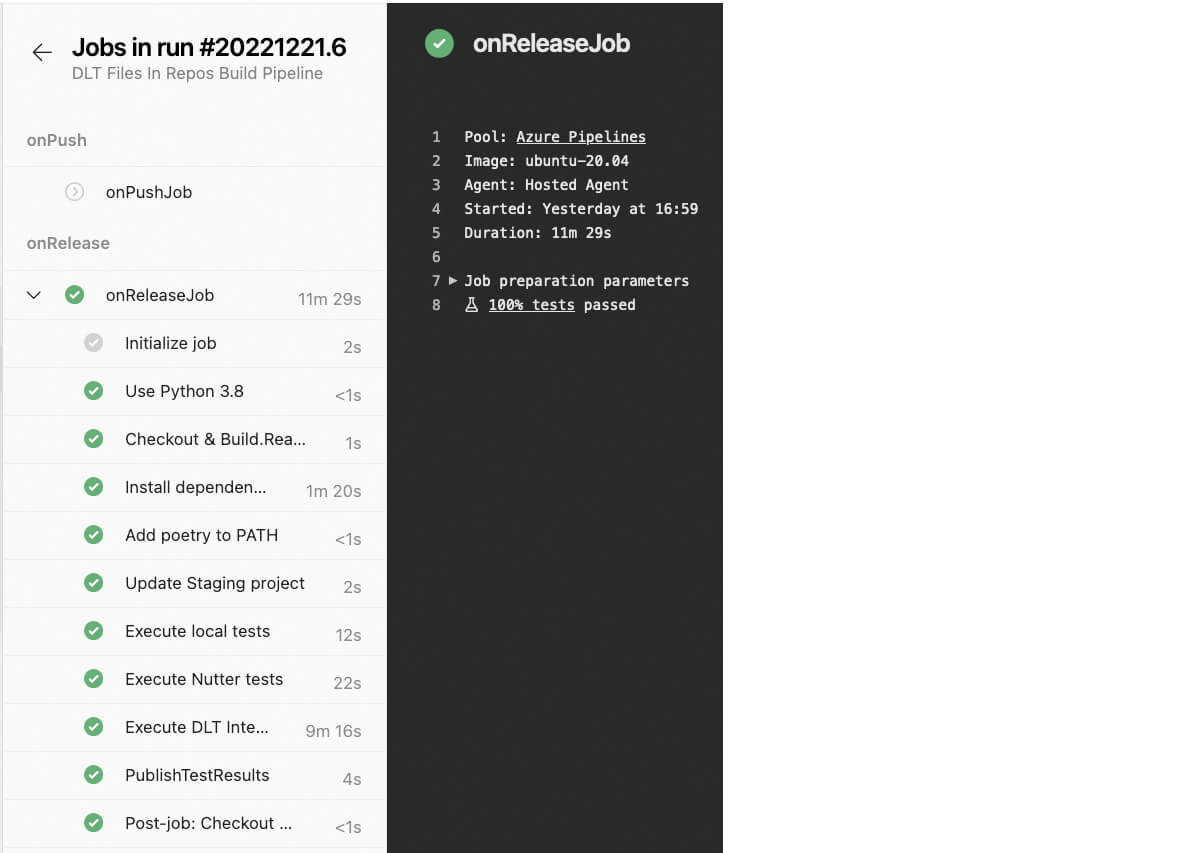
テスト実行の結果はAzure DevOpsに報告され、追跡できるようになっています:
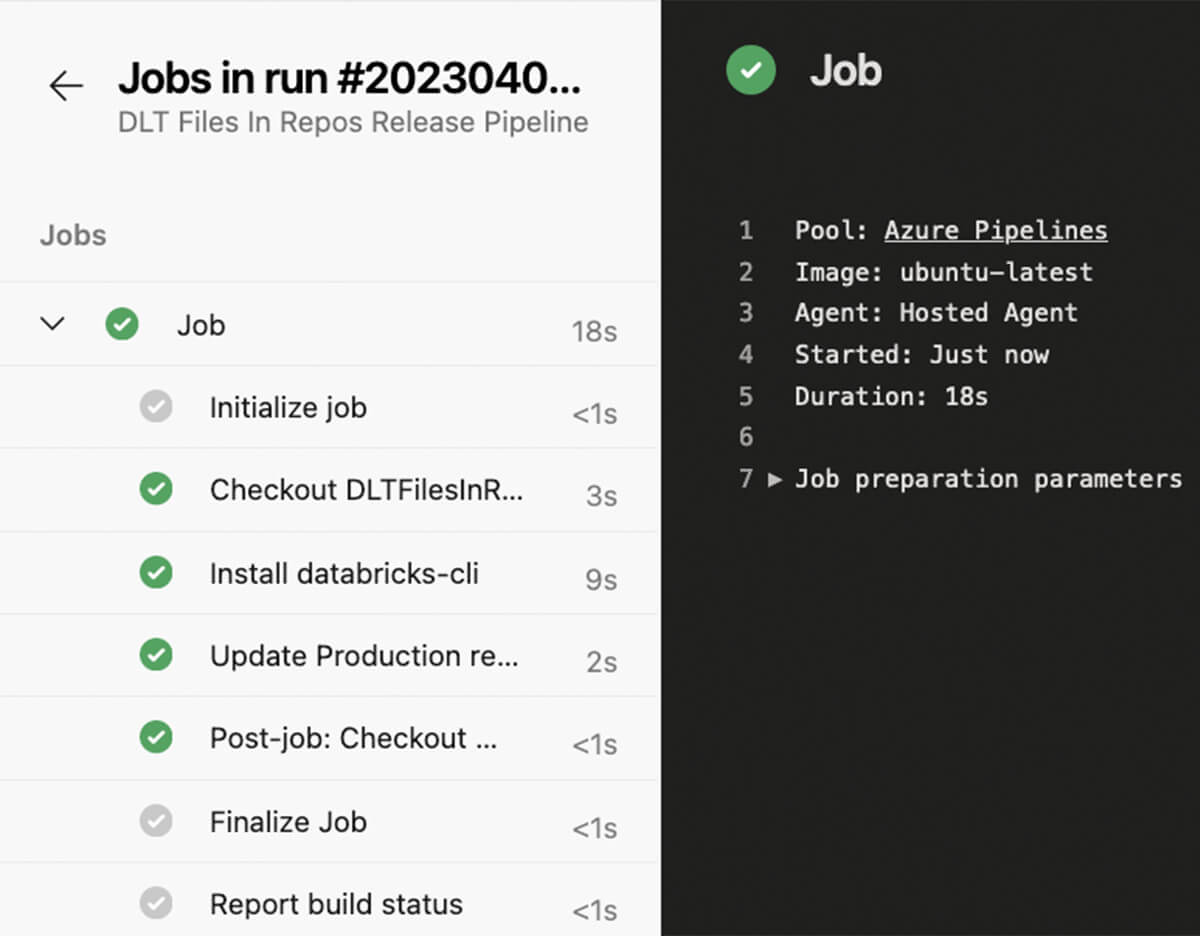
リリースブランチへのコミットが完了し、すべてのテストが成功した場合、リリースパイプラインが起動し、本番のDatabricksレポが更新され、コードの変更がDLTパイプラインの次の実行で考慮されるようになります。
このブログポストで説明されているアプローチをあなたのDelta Live Tableパイプラインに適用してみてください!提供されたデモリポジトリには、必要なすべてのコードと、Azure DevOpsにすべ�てをデプロイするための設定手順とTerraformコードが含まれています。

