
Ali Ghodsi(アリ・ゴディシ)
共同創業者兼 CEO
Follow Ali Ghodsi(アリ・ゴディシ)
Ali is the CEO and co–founder of Databricks, responsible for the growth and international expansion of the company. He previously served as the VP of Engineering and Product Management before taking the role of CEO in January 2016. In addition to his work at Databricks, Ali serves as an adjunct professor at UC Berkeley and is on the board at UC Berkeley’s RiseLab. Ali was one of the creators of open source project, Apache Spark, and ideas from his academic research in the areas of resource management and scheduling and data caching have been applied to Apache Mesos and Apache Hadoop. Ali received his MBA from Mid-Sweden University in 2003 and PhD from KTH/Royal Institute of Technology in Sweden in 2006 in the area of Distributed Computing.
Ali Ghodsi(アリ・ゴディシ)'s posts

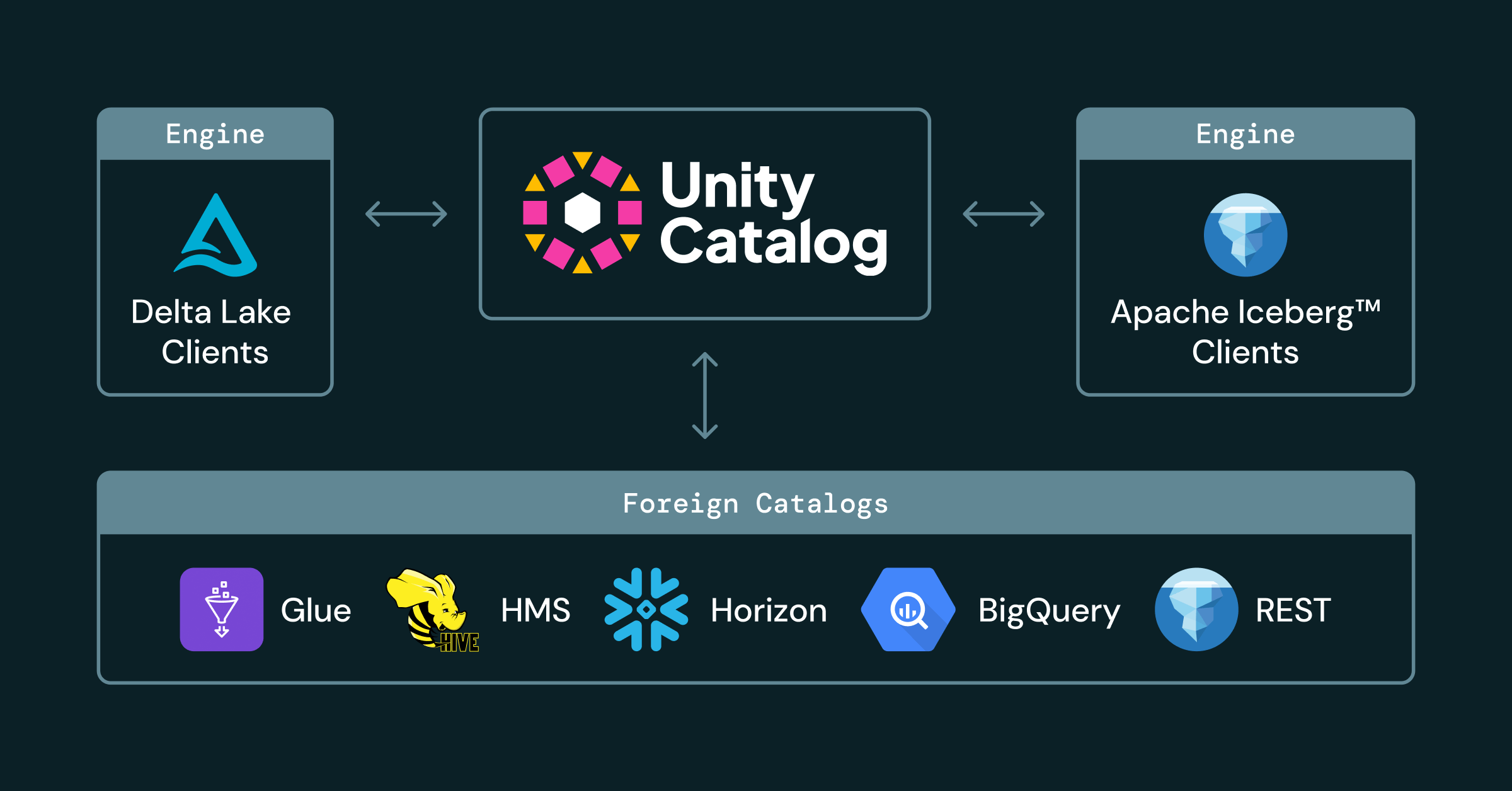









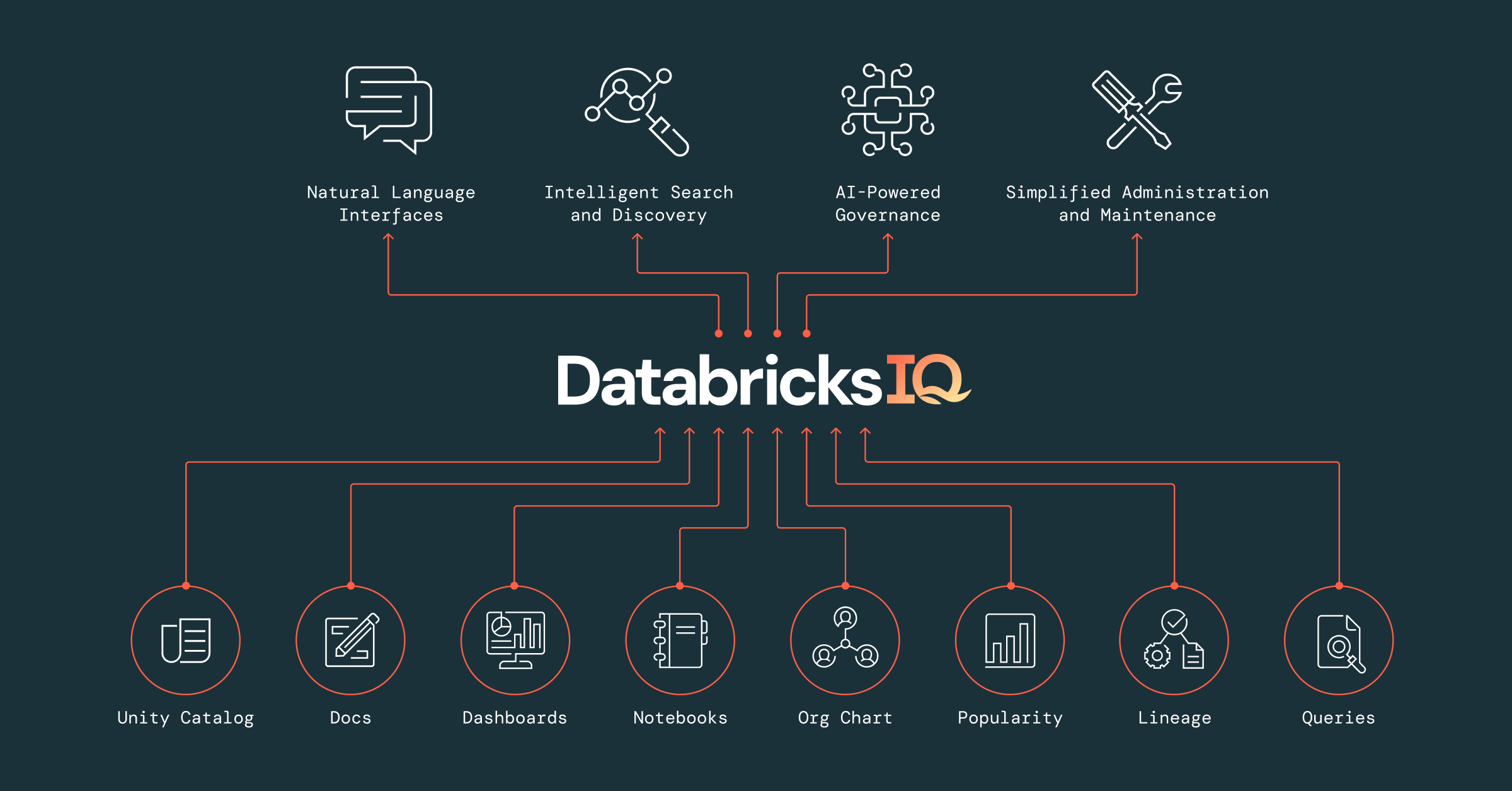
18 の結果のうち 1 - 12 を表示しています