R開発者にレイクハウスを:Databricks Connectがsparklyrで利用可能に

CRAN 上の sparklyr の最新リリースに Databricks Connect のサポートが導入されたことをお知らせできることを嬉しく思います。R ユーザーは、リモートの RStudio Desktop、Posit Workbench、またはアクティブな R ターミナルやプロセスから、Databricks のクラスタリングと Unity Catalog にシームレスにアクセスできるようになりました。今回のアップデートにより、R ユーザーであれば誰でも、わずか数行のコードで Databricks を使ってデータアプリケーションを構築で�きるようになりました。
Sparklyr と Python Databricks Connect との統合方法
このリリースでは、pysparklyr コンパニオン・パッケージを通じて、sparklyr の新しいバックエンドを導入しています。pysparklyr は sparklyr が Python Databricks Connect API とやりとりするためのブリッジを提供します。これは、R から Python と対話するために reticulate パッケージを使用することによって実現されます。

この方法で新しい sparklyr バックエンドを設計すると、Python でリリースされた機能をラップするだけで、Databricks Connect の機能を R ユーザーに提供することが容易になります。 現在、Databricks Connect はApache Spark™ DataFrame API を完全にサポートしており、Sparklyr のチートシートを参照することで、利用可能な追加機能を確認できます。
Sparklyr と Databricks Connect を使い始める
まず、sparklyr と pysparklyr パッケージを CRAN から R セッションにインストールします。
ワークスペースのURL(別名ホスト)、アクセストークン、クラスタ IDを指定することで、R セッションと Databricks クラスタとの接続を確立できます。sparklyr::spark_connect() に直接引数として認証情報を渡すこともできますが、セキュリティを高めるために環境変数として保存することをお勧めします。 さらに、sparklyr を使って Databricks に接続する場合、pysparklyr が依存関係を特定し、Python 仮想環境へのインストールをサポートしてくれます。
初期セットアップの詳細とヒントは、公式ページ(sparklyr )に掲載されています。
Unity Catalog のデータへのアクセス
sparklyr との接続に成功すると、RStudio の [接続] ペインにUnity Catalog のデータが表示され、Databricks で管理されているデータを簡単にブラウズしてアクセスできるようになります。
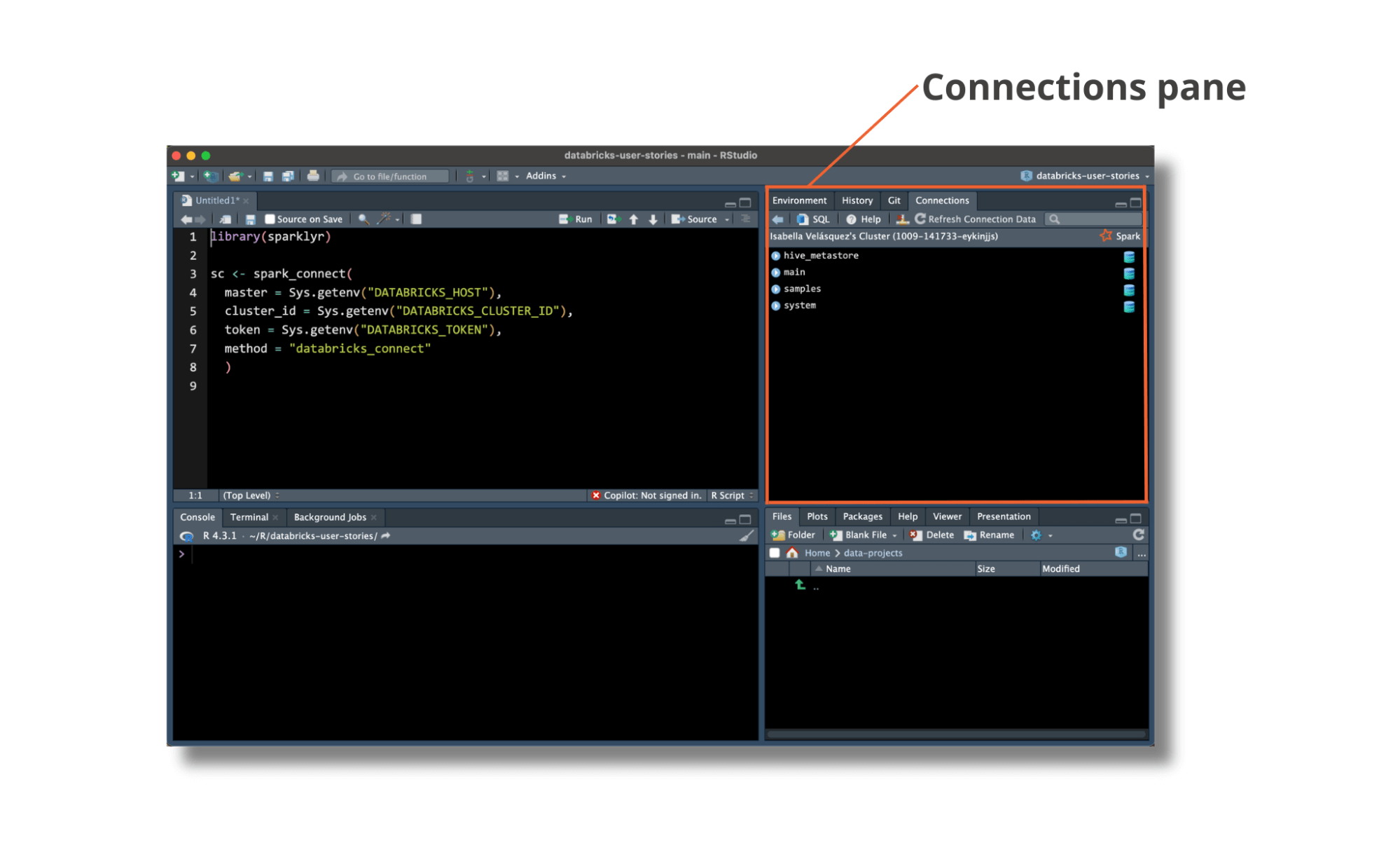
Unity Catalog は、Databricks 上のデータと AI のための包括的なガバナンス・ソリューションです。 Unity Catalog で管理されるデータ・テーブルは、カタログ、スキーマ、テーブルの 3 レベルのネームスペースに存在します。 sparklyr バックエンドを Databricks Connect を使用するように更新することで、R ユーザーは catalog.schema.table 階層を表現するデータを読み書きできるようになりました:
インタラクティブな開発とデバッグ
Databricks を使ったインタラクティブな作業をシンプルで使い慣れたものにするため、sparklyr はデータの変換と集計のための dplyr 構文を長い間サポートしてきました。 Databricks Connectを搭載した最新バージョンも同様です:
さらに、sparklyr や Databricks Connect を使用する関数やスクリプトをデバッグする必要がある場合、RStudio の browser() 関数は、膨大なデータセットを扱う場合でも、見事に機能します。
Databricksを利用したアプリケーション
Databricks バックエンド上で Shyny のようなデータアプリケーションを開発することは、かつてないほど簡単になりました。Databricks Connect は軽量であるため、Databricks クラスタ上に直接デプロイすることなく、大規模なデータの読み取り、変換、書き込みを行うアプリケーションを構築できます。
R で Shyny を使用する場合、接続方法は上記の開発作業で使用したものと同じです。Shiny for Python で作業する場合も同様で、PySpark で Databricks Connect を使用するためのドキュメントに従ってください。 R で Shyny を使用したデータアプリの例や、Python の plotly のような他のフレームワークの例もあります。
関連リソース
詳細については、公式の sparklyr および Databricks Connect のドキュ�メントを参照してください。Apache Spark™ API が現在サポートしているものについての詳細情報も含まれています。 また、Posit Connect 上で Databricks Connect を使用する Shyny アプリをデプロイする方法など、これらの機能をすべてデモンストレーションする Posit Webセミナーもご覧ください。

