DatabricksによるGenAIの構築とカスタマイズ:LLMとその先へ

ジェネレーティブAIは、ビジネスに新たな可能性をもたらし、組織全体で力強く受け入れられています。 最近のMIT Tech Reviewのレポートによると、調査対象となった600人のCIO全員がAIへの投資を増やしており、71%が独自のカスタムLLMやその他のGenAIモデルの構築を計画していると回答しています。 しかし、多くの組織では、自社のデータで学習させたモデルを効果的に開発するために必要なツールが不足している可能性があります。
ジェネレーティブAIへの飛躍は、単にチャットボットを導入するだけではありません。 この変革の中心は、データレイクハウス の出現です。 このような高度なデータアーキテクチャは、GenAIの可能性を最大限に活用する上で不可欠であり、データとAI技術の迅速かつコスト効率の高い、より広範な民主化を可能にします。 企業が競争上の優位性を確保するためにGenAIを活用したツールやアプリケーションへの依存度を高める中、基盤となるデータインフラは、これらの先進技術を効果的かつ安全にサポートできるように進化しなければなりません。
Databricksデータインテリジェンスプラットフォームは、生データの取り込みからモデルのカスタマイズ、そして最終的には生産可能なアプリケーションに至るまで、AIライフサイクル全体をサポートできるエンドツーエンドのプラットフォームです。 より厳密なセキュリティとモニタリングによってモデルとデータを完全に制御し、ガバナンス、リネージ、透明性によってMLモデルの製品化を容易にし、企業独自のモデルをトレーニングするコストを削減します。 Databricks は、プロンプトエンジニアリング、RAG、ファインチューニング、および事前トレーニングを含む、これらの包括的なサービスを提供できる唯一のプロバイダーとして際立っています。
このブログでは、企業がDatabricksを使用して独自のGenAIアプリケーションを構築する理由、Databricks Data Intelligence PlatformがエンタープライズAIに最適なプラットフォームである理由、および開始方法について説明します。
興奮した? 私たちもです!
トピックは以下の通り:
- GenAIアプリケーションと、よりスマートなビジネス上の意思決定のために、自社のデータで訓練されたLLMをどのように活用できますか?
- Databricks Data Intelligence Platform を使用して、コンプライアンスと透明性を維持しながら、統一プラットフォーム上ですべてのデータ、モデル、API をファインチューニング、管理、運用するにはどうすればよいでしょうか?
- AI の成熟曲線に沿って進む中で、自社独自のデータを十分に活用しながら Databricks Data Intelligence Platform を活用するにはどうすればよいで��しょうか?
企業向けGenAI:DatabricksデータインテリジェンスプラットフォームによるAIの活用
GenAIにデータインテリジェンスプラットフォームを使用する理由
データインテリジェンスプラットフォームは、GenAIツールを使用して構築された差別化されたアプリケーションで業界のリーダーシップを維持することができます。 データインテリジェンスプラットフォームを使用する利点は以下のとおりです:

- 完全なコントロール:データインテリジェンスプラットフォームは、RAGまたはカスタムGenAIソリューションを構築するために、貴社独自の企業データを使用することができます。 お客様の組織は、モデルとデータの両方を完全に所有することができます。 また、セキュリティーとアクセス・コントロールがあるので、データにアクセスすべきでないユーザーがデータにアクセスすることはありません。
- プロダクション対応:データインテリジェンスプラットフォームは、ガバナンス、再現性、コンプライアンスを組み込んだ大規模なモデルを提供する能力を備えています。
- 費用対効果:データ・インテリジェンス・プラットフォームは、データ・ストリーミングを最大限に効率化し、お客様のドメインに合わせてカスタマイズしたLLMの作成やファインチューニングを可能にします。
データインテリジェンスプラッ�トフォームのおかげで、企業は次のような成果を得ることができます:
- インテリジェントなデータインサイト:構造化、半構造化、非構造化、ストリーミングなど、すべてのデータ資産を活用することで、ビジネス上の意思決定がより豊かになります。 MIT Tech Reviewのレポートによると、企業のデータの最大90%は未開拓です。 モデルの学習に使用するデータ(PDF、Word文書、画像、ソーシャルメディアなど)が多様であればあるほど、インパクトのある洞察が得られます。 どのようなデータがどのくらいの頻度でアクセスされているかを知ることで、何が最も価値があり、どのようなデータが未開拓であるかが明らかになります。
- ドメイン固有のカスタマイズ:LLMは、お客様が選択したデータのみを取り込み、お客様の業界の専門用語に基づいて構築されます。 これにより、LLMは、サードパーティのサービスではわからないドメイン固有の用語を理解することができます。 さらに良いことに、お客様自身のデータを使用することで、お客様のIPは社内に保持されます。
- シンプルなガバナンス、観測可能性、モニタリング:独自のモデルを構築またはファインチューニングすることで、結果の理解を深めることができます。 モデルがどのように作られたのか、どのバージョンのデータに基づいて作られたのかを知ることができます。 モデルがどのように機能しているか、入力データがドリフトし始めていないか、精度を向上させるためにモデルの再トレーニングが必要かどうかを把握することができます。
「既存のモデルから構築することで、その企業が自社の主力製品と競合するようなデータを利用することは、必ずしも避けたいものです」。 - マイケル・カービン、MIT教授、Mosaic AI創設アドバイザ-
進化段階
飛び込む準備はできていますか? AI成熟度曲線の各段階における組織の典型的なプロフィールを見てみましょう。
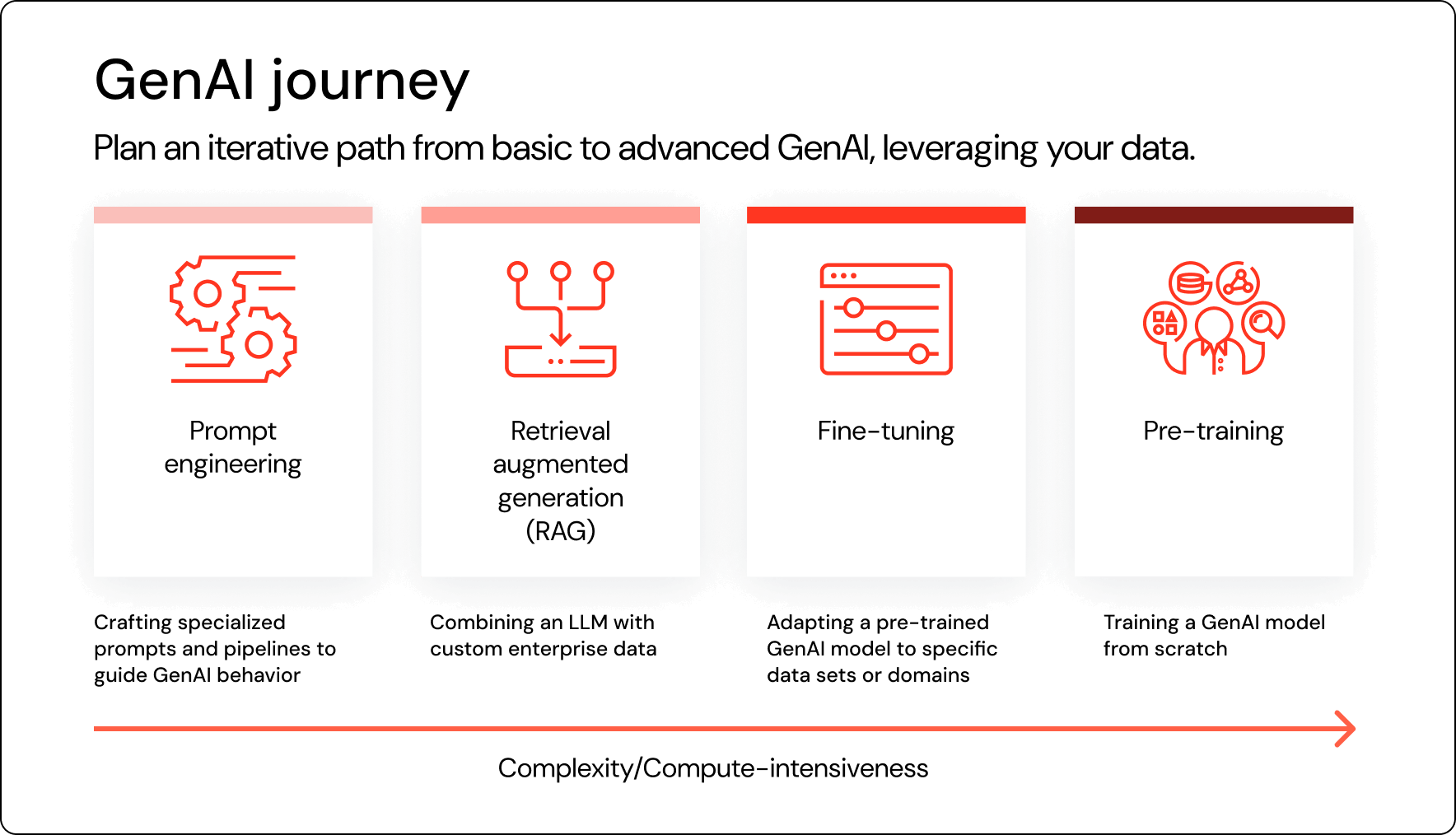
前段階:データの取り込み、変換、準備
AIの冒険の出発点は常にデータです。 企業は多くの場合、すでに膨大な量のデータを収集しており、新しいデータの増加ペースは非常に速いです。 データは、リアルタイムで収集される構造化されたトランザクションデータから、ウェブ経由でスキャンされたPDFまで、あらゆるタイプが混在しています。
DatabricksLakehouseは、お客様のデータワークロードを処理し、運用コストと頭痛の種を軽減します。 このエコシステムの中心となるのが、すべてのデータとAI資産を管理し、SnowflakeやMySQLなどの社内外のデータソースのシームレスな統合と管理を実現する基盤レイヤーのUnityカタログです。 これにより、データエコシステムの豊かさと多様性が向上します。
デルタ・ライブ・テーブルを通じて、ほぼリアルタイムのストリーミング・データを取り込むことができ、イベントに対して早急に対応することができます。 ETLワークフローは、適切な周期で実行されるように設定することができ、パイプラインがあらゆるソースから健全なデータを経由することを保証すると同時に、何か問題が発生するとすぐにタイムリーなアラートを提供します。 外部データセットを含め、最高品質のデータを持つことが、このデータの上で使用されるAIのパフォーマンスに直接影響するからです。
データを自信を持って扱えるようになったら、ジェネレーティブAIの世界に足を踏み入れて、最初の概念実証をどのように作成できるかを見てみましょう。
ステージ1:プロンプト・エンジニアリング
包括的なAI戦略もなく、追求すべき明確なユースケースもなく、企業のAI導入の道しるべとなるデータサイエンティストやその他の専門家のチームへのアクセスもありません。
このような場合は、既成のLLMか��ら始めるのがよいでしょう。 これらのLLMには、カスタムAIモデルのようなドメイン固有の専門知識はありませんが、実験を行うことで、次のステップを計画することができます。 従業員は、専用のプロンプトやワークフローを作成し、使用方法をガイドすることができます。 リーダーは、これらのツールの長所と短所をよりよく理解し、AIにおける初期の成功がどのようなものかをより明確にイメージすることができます。 あなたの組織は、より強力なAIツールやシステムに投資することで、より大きな業務利益を上げることができます。
外部モデルを実験する準備ができている場合、Model Servingは、すべてのモデルを一箇所で管理し、単一のAPIでクエリするための統一されたプラットフォームを提供します。
以下は、POCに対するプロンプトと回答の例です:

ステージ2:検索拡張生成 (RAG)
Retrieval Augmented Generation (RAG)を使用すると、補足的な知識リソースを取り込んで、既製のAIシステムをより賢くすることができます。 RAGはモデルの根本的な動作を変えることはありませんが、回答の関連性と精度を向上させます。
しかしこの時点では、「ミッションクリティカル」なデータをアップロードすべきではありません。 その代わり、RAGプロセスでは通常、より少量の非機密情報を扱います。
例えば、従業員ハンドブックをプラグインすることで、従業員が組織の休暇ポリシーについて基本モデルに質問を始めることができます。 取扱説明書をアップロードすることで、サービスチャットボットに力を与えることができます。 しかし、従業員が会社の業績について問い合わせることができるように、機密の財務データを入力するのは行き過ぎでしょう。
まず、使用するデータを統合し、クレンジングします。 RAGでは、下流のモデルに適したサイズでデータを保存することが不可欠です。 多くの場合、ユーザーはそれをより小さなセグメントに分割する必要があります。
それなら、Databricks Vector Searchのようなツールを探してみてください。 また、Unity Catalogによって管理されるため、従業員が資格情報を持つデータセットにのみアクセスできるように、きめ細かな管理を行うことができます。
最後に、そのエンドポイントを市販のLLMに接続することができます。 Databricks MLflowのようなツールは、このようなAPIの一元管理に役立ちます。
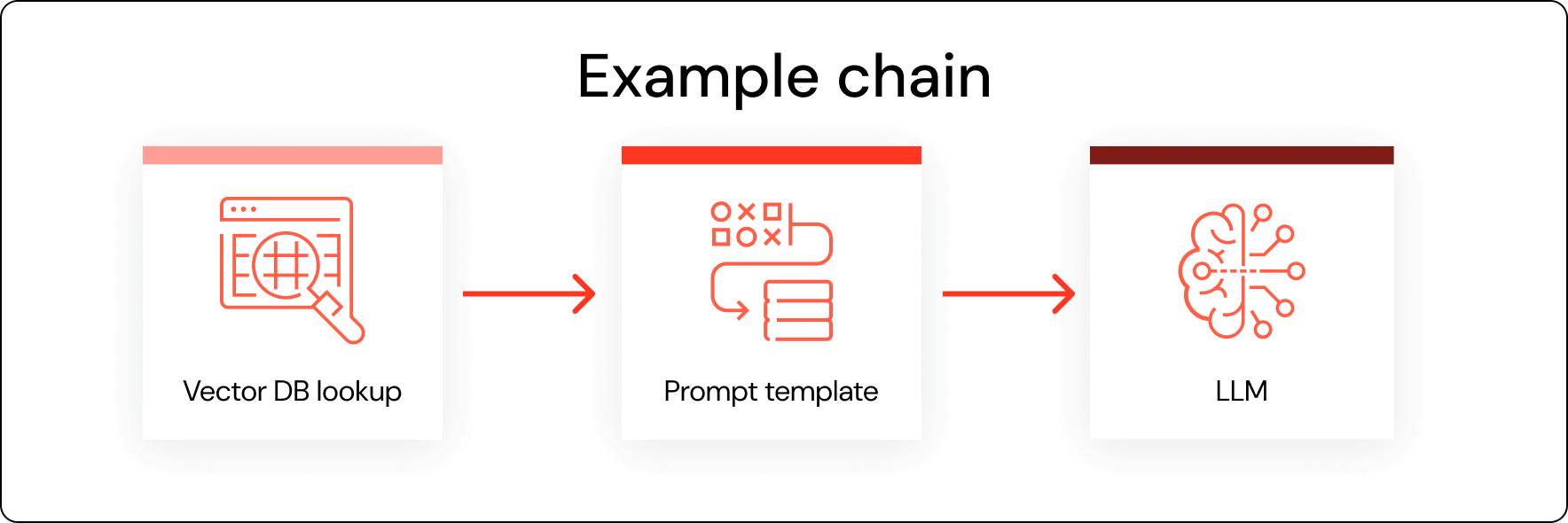
RAGの利点としては、幻覚の減少、より最新で正確な反応、より優れた領域別知能などが挙げられます。 RAG支援モデルは、ほとんどの組織にとって、より費用対効果の高いアプローチでもあります。
RAGは市販モデルの結果を改善するのに役立ちますが、RAGの使用にはまだ多くの制限があります。 ビジネスが望む結果を得られない場合は、より重量のあるソリューションに移行する時ですが、RAGサポートモデルを超えるには、多くの場合、より深いコミットメントが必要です。 追加のカスタマイズにはコストがかかり、より多くのデータを必要とします。
だからこそ、組織はまず、LLMをどのように活用するかという核心的な理解を築くことが重要なのです。 既製モデルの性能の限界に到達してから次のモデルに移行することで、あなたとあなたのリーダーシップは、リソースを割り当てるべき場所をさらに絞り込むことができます。
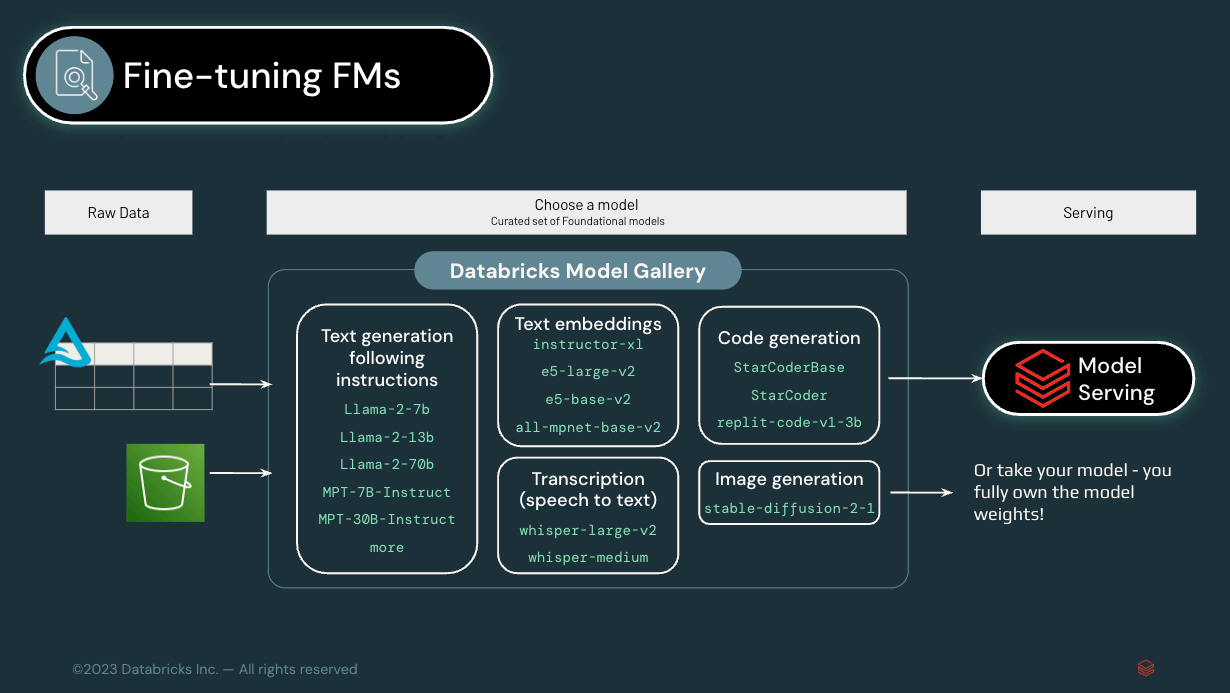
ステージ3:基礎モデルのファインチューニング
RAGからモデルのファインチューニングに移行することで、ビジネスにより深くパーソナライズされたモデルを構築することができます。 すでに事業全体で商業モデルを実験しているのであれば、この段階に進む準備ができている可能性が高いでしょう。 ジェネレーティブAIの価値について、経営幹部レベルでは明確な理解があり、また一般に利用可能なLLMの限界についても理解があります。 具体的なユースケー�スが確立されています。 そして今、あなたとあなたの企業は、より深く踏み込む準備ができています。
ファインチューニングを行うことで、汎用のモデルをあなた自身の特定のデータで訓練することができます。 例えば、データ管理プロバイダーのスタードッグは、ナレッジグラフ・プラットフォームの基盤として使用している既製のLLMをファインチューニングするために、Databricks のMosaic AIツールを利用しています。 これにより、スタードッグの顧客は、自然言語を使用するだけで、異なるサイロを横断して自社のデータを照会することができます。
この段階にある組織では、モデルをサポートするデータの安全性と正確性を確保するために、基盤となるアーキテクチャを整備することが不可欠です。 AIシステムのファインチューニングには膨大な量の独自情報が必要であり、ビジネスのAI成熟度曲線が進むにつれて、実行するモデルの数は増加し、データアクセスの需要は高まる一方です。
そのため、データが生成された瞬間から最終的に使用されるまでを追跡するための適切なメカニズムが必要であり、UnityカタログがDatabricksのお客様に人気の機能である理由です。 データ・リネージ機能により、企業はデータがどこに移動し、誰がアクセスしているかを常に把握することができます。
ステージ4:ゼロからのモデルの事前学習
カスタムモデルを事前にトレーニングする準備が整った段階であれば、AI成熟曲線の頂点に達しています。 ここでの成功は、適切な場所に適切なデータがあるだけでなく、必要な専門知識とインフラを利用できるかどうかにかかっています。 大規模なモデルのトレーニングには、大量の計算と、"ヒーローラン "のハードウェアとソフトウェアの複雑性を理解する必要があります。 また、インフラやデータガバナンスを考慮するだけでなく、ユースケースと成果が明確に定義されていることを確認してください。
恐れることはありません。これらのツールの開発には投資と時間がかかるかもしれませんが、ビジネスに変革をもたらす可能性があります。 カスタムモデルは、オペレーションの基幹となるヘビーデューティーなシステムであり、新しい製品提供の原動力となるものです。 例えば、ソフトウェア・プロバイダのReplit社は、コード生成を自動化するために、Mosaic AIプラットフォームを利用して独自のLLMを構築しました。
これらの事前訓練されたモデルは、RAGアシストモデルやファインチューニングされたモデルよりも大幅に優れた性能を発��揮します。 スタンフォード大学の財団モデル研究センター(モザイクAIと共同)は、生物医学に特化した独自のLLMを構築しました。 カスタムモデルの精度は74.4%で、ファインチューニングされた既製モデルの精度65.2%よりもはるかに正確でした。
ポストステージオペレーションとLLMOps
おめでとうございます! 細かくチューニングされた、あるいは事前にトレーニングされたモデルを実装することに成功しました。そして、最後のステップは、そのすべてを製品化することです。
LLMOpsでは、コンテクスチュアルデータが毎晩ベクターデータベースに統合され、AIモデルが卓越した精度を発揮し、パフォーマンスが低下するたびに自己改善します。 このステージでは、部門を超えた完全な透明性も提供され、AIモデルの健全性と機能性に関する深い洞察が得られます。
LLMOps(大規模言語モデル・オペレーション)の役割は、AIの高度化のピーク時だけでなく、この旅を通して非常に重要です。 LLMOpsは最終段階だけでなく、初期段階から不可欠なものであるべきです。 GenAIの顧客は複雑なモデルの事前トレーニングに最初は取り組まないかもしれませんが、LLMOpsの原則は普遍的に関連性があり、有利です。 さまざまな段階でLLMOpsを導入することで、�強力でスケーラブルかつ効率的なAI運用フレームワークが確保され、AIの成熟度がどのようなレベルの組織であっても、高度なAIのメリットを享受することができます。
成功するLLMOpsアーキテクチャとはどのようなものでしょうか?
Databricksデータインテリジェンスプラットフォームは、LLMOpsプロセスを構築するための基盤です。 モデルやデータの管理、統制、評価、監視を簡単に行うことができます。 以下はその利点の一部です:
- 統一されたガバナンス:Unity Catalogは、データとモデル全体で統一されたガバナンスとセキュリティ・ポリシーを実現し、MLOps管理を合理化するとともに、単一のソリューションで柔軟かつレベル別の管理を可能にします。
- プロダクションアセットへの読み取りアクセス:データサイエンティストは、Unityカタログを通じて本番データとAIアセットに読み取り専用でアクセスできるため、モデルのトレーニング、デバッグ、比較が容易になり、開発スピードと品質が向上します。
- モデルのデプロイメント:Unity Catalogでモデルエイリアスを利用することで、的を絞ったデプロイとワークロード管理が可能になり、モデルのバージョニングとプロダクショントラフィックの処理が最適化されます。
- リネージ:Unity Catalogの堅牢なリネージトラッキングは、モデルのバージョンをトレーニングデータおよびダウンストリームコンシューマーにリンクし、MLflowを介して包括的な影響分析と詳細なトラッキングを提供します。
- 発見性:データとAIアセットをUnityカタログに一元化することで、これらのアセットを発見しやすくなり、MLOpsソリューションの効率�的なリソースの配置と活用を支援します。
どのような建築がこの世界を前進させることができるかを垣間見るために、私たちは多くの考えや経験を「MLOps大全」にまとめました。この本にはLLMに関する大きなセクションがあり、ここでお話ししたことすべてを網羅しています。 AIの涅槃の境地に達したい方は、ぜひご覧ください。
このブログでは、GenAIアプリケーションを導入している企業の成熟度が複数の段階に分かれていることを学びました。 詳細は下表の通り:
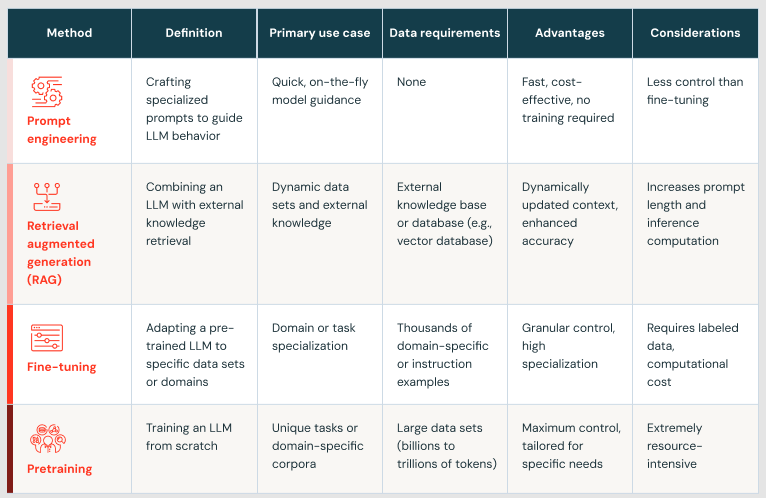
まとめ
ジェネレーティブAIの成熟度曲線に沿って旅をし、LLMを組織に役立てるために必要なテクニックを検討したところで、すべての始まりであるデータ・インテリジェンス・プラットフォームに戻りましょう。
Databricksのような強力なデータインテリジェンスプラットフォームは、カスタマイズされたAI搭載アプリケーションのバックボーンを提供します。 データレイヤーは、スケールアップしても非常に高いパフォーマンスを発揮し、適切なデータのみが使用されるようにセキュアかつガバメントされています。 データの上に構築さ�れた真のデータインテリジェンスプラットフォームは、セマンティクスも理解し、モデルが御社独自のデータ構造と用語にアクセスできるため、AIアシスタントの使用がより強力になります。
AIのユースケースが構築され、本番稼動が開始されると、すべてが最適に実行されていることを確認するために、優れた観測性と監視機能を提供するプラットフォームも必要になります。 真のデータインテリジェンスプラットフォームは、データの「通常の」プロファイルがどのようなものか、またどのような場合に問題が発生するかを理解することができるため、ここで輝きを放ちます。
最終的に、データインテリジェンスプラットフォームの最も重要な目標は、複雑なAIモデルとユーザーの多様なニーズとのギャップを埋めることであり、より幅広い個人や組織がLLM(およびGenerative AI)のパワーを活用し、自社のデータを使用して困難な問題を解決できるようにすることです。
Databricks Data Intelligence Platformは、データの取り込みと保存からAIモデルのカスタマイズまで企業をサポートし、最終的にGenAIを搭載したAIアプリケーションを提供できる唯一のエンドツーエンドプラットフォームです。

