
良いベンチマークとは、どのモデルが優れていて、どのモデルが劣っているかを明確に示すものです。 Databricks Mosaic Researchチームは、研究者が実験を評価するための優れた測定ツール�を見つけることに専念しています。 モザイク評価ガントレットは、モデルの質を評価するためのベンチマークセットで、言語理解、読解力、記号的問題解決、世界知識、常識、プログラミングの6つのコアコンピテンシーにまたがる39の公開ベンチマークで構成されています。 モデル規模を超えた研究タスクに最も有用なメトリクスに優先順位をつけるため、一連の高度なモデルを使用してベンチマークをテストしました。
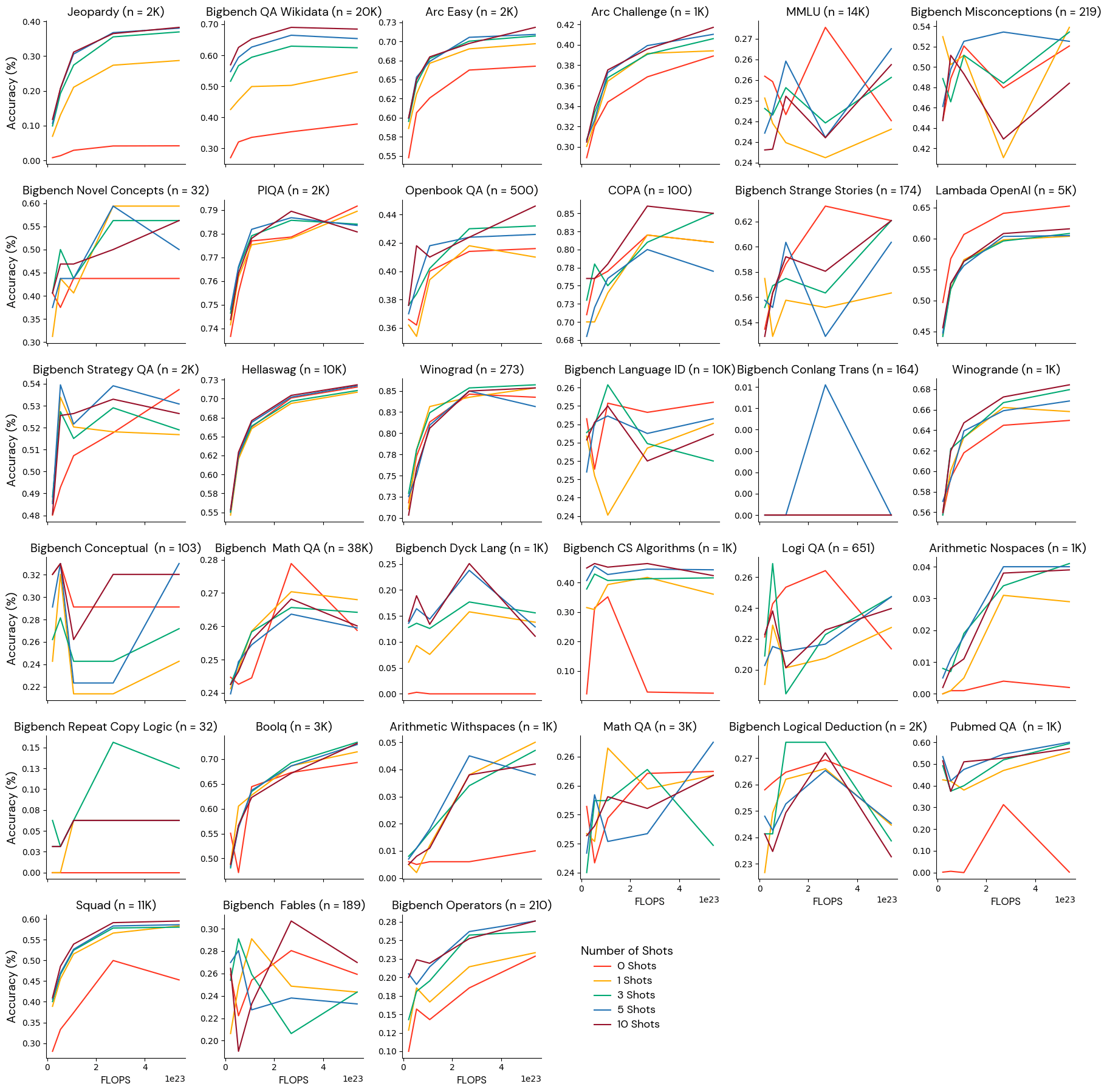
最近の研究、特に DeepMindのChinchilla論文では、パラメータ数と学習データサイズの両方を増やすことで言語モデルをスケールアップすると、性能が大幅に向上することが実証されています。信頼できるベンチマー�クセットを特定するには、モデルの性能とスケールの間に確立された関係を活用します。スケーリング法則は個々のベンチマークよりも強力な根拠となる真実であると仮定し、どのベンチマークが最も少ないトレーニングFLOPSから最も多いトレーニングFLOPSまでモデルを正しくランク付けできるかをテストしました。
1パラメータあたり20トークンの割合から、1パラメータあたり500トークンの割合まで、徐々に大きな量の学習データで5つのモデルを学習しました。 各モデルには30億のパラメータがあり、総FLOPSは2.1e22~5.4e23FLOPSでした。 そして、学習FLOPSが少ないモデルから多いモデルへと単調にランク付けされるメトリクスを選択しました。
結果
メトリクスを 4 つのグループに分類しました: (1) 少数ショットの設定に対して適切に振る舞うかつ堅牢、(2) 少数ショットが一定数ある場合に適切に振る舞う、(3) ノイズより良くない、(4) 振る舞いが悪い。
グループ1:少数ショットの設定に対して適切に振る舞うかつ堅牢なメトリクス
これらのベンチマークは、訓練規模によってモデルを確実に並べ替え、どのショット数でも単調に改善します。 これらのベンチマークは、この範囲のモデルに対して信頼性の高い評価シグナルを提供できると考えています。
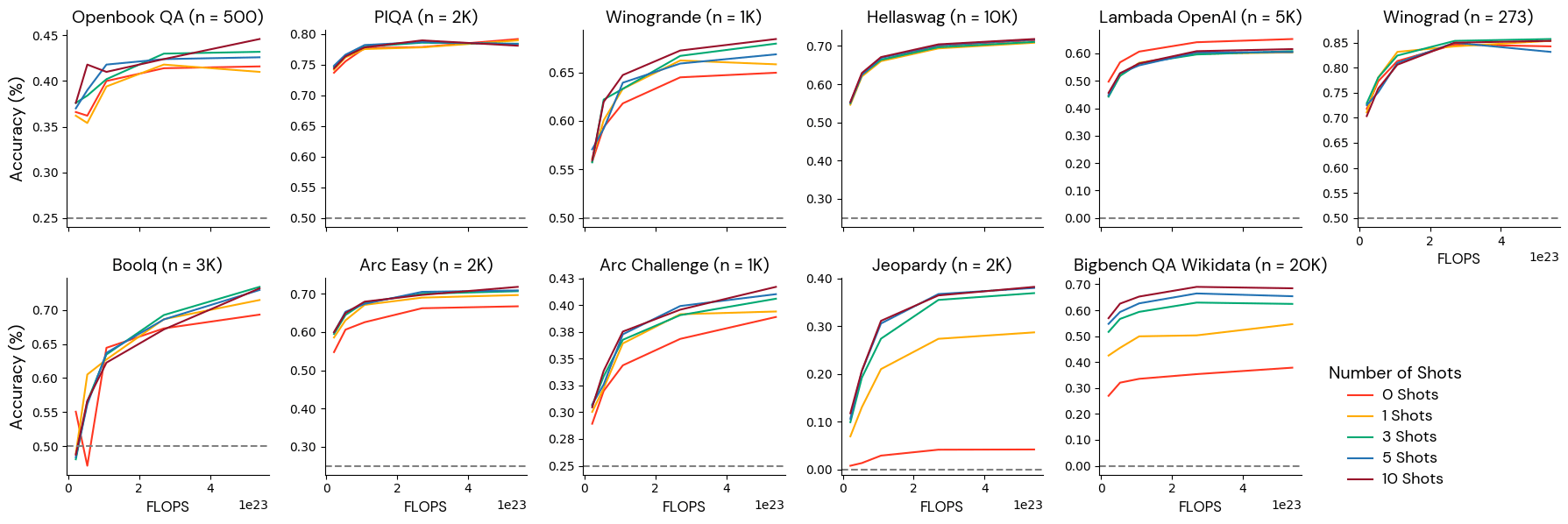
グループ2:特定の少数ショットの設定で適切に振る舞う
これらのベンチマークは、いくつかの少数ショット設定ではモデルスケールと単調に関連していましたが、他の少数ショット設定ではモデルスケールと無関係でした。 例えば、BigBenchストラテジーQAは、0ショットで提供された場合、モデルスケールと単調に関係しましたが、1ショットで提供された場合、スケールと反相関しました。 これらの指標は、信頼できる数ショットの設定で使用することをお勧めします。

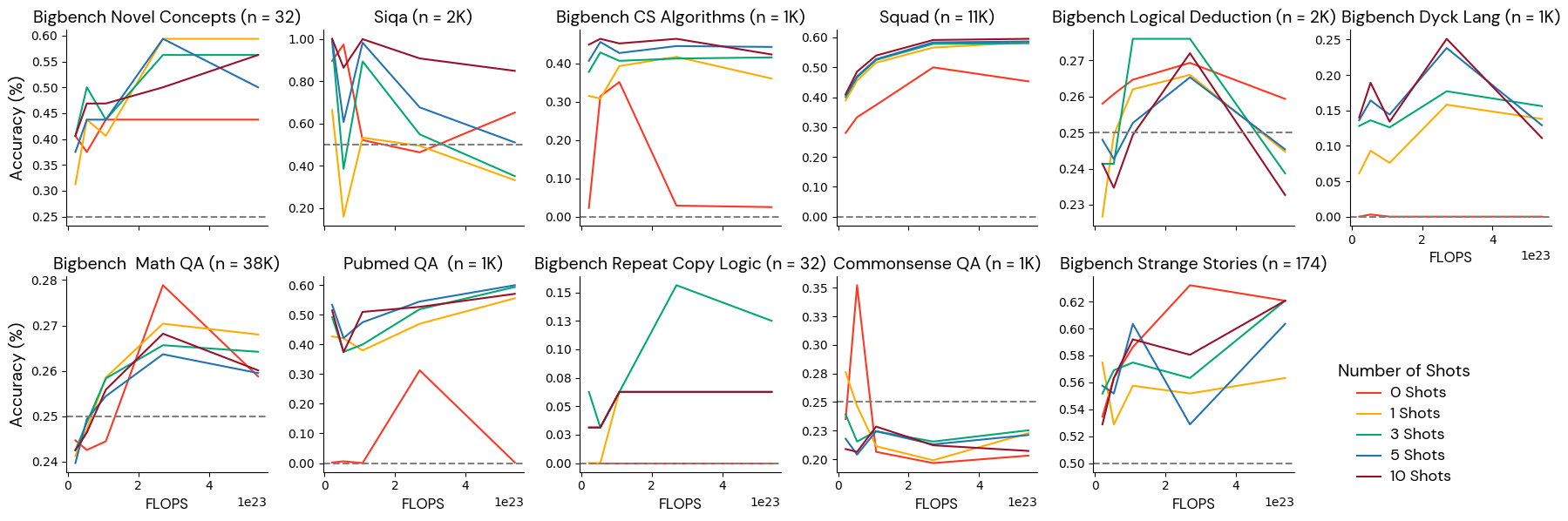
グループ3:振る舞いの悪いベンチマーク
これらのベンチマークは、このモデル規模では、トークンの持続時間が長くなるにつれて単調に改善することはありませんでした。 このカテゴリのいくつかのベンチマークは、実際に規模が大きくなるにつれて悪化しています。 このようなベンチマークは、実験結果に対してどのような判断を下すべきかについて、研究者を惑わすかもしれません。 このような動作は、このカテゴリのベンチマークにラベルの不均衡(1つの答えが他の答えよりも頻度が高い場合、モデルが偏り、より頻度の高い答えを与える可能性がある)、情報量の少なさ(同じ問題が繰り返し出題され、わずかなバリエーションしかない)、またはラベラー間の不一致(同じ問題を見た2人の専門家が正しい答えに異議を唱える)が含まれているためではないかと仮説を立てています。 これらのベンチマークの手動検査とフィルタリングが必要な場合があります。
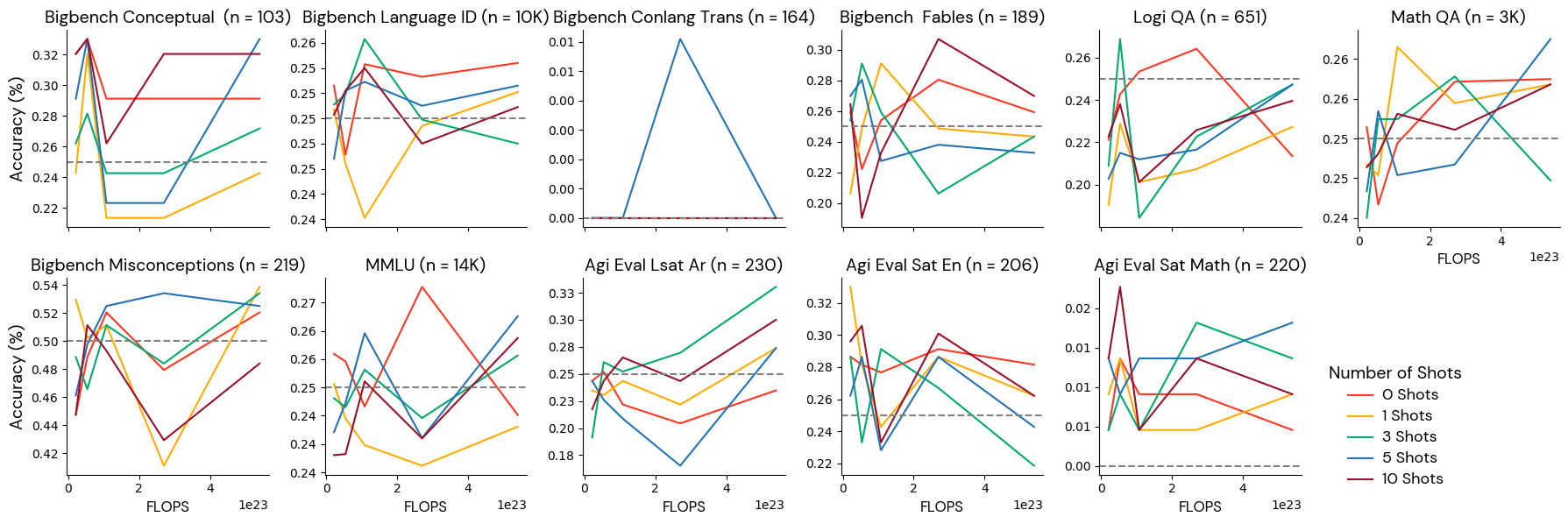
グループ4:ノイズレベルのベンチマーク
これらのベンチマークでは、��モデルはランダムな推測よりも優れておらず、スコアはこのスケールでトレーニングを重ねても確実に向上することはありません。 これらのベンチマークは、この規模のモデル(2.1e22~5.4e23 FLOPS)には難しすぎるため、研究者は、小規模なモデルに対するこれらのベンチマークを使用した実験から結論を導き出すことには慎重であるべきです。 このカテゴリには、MMLUのような人気のあるベンチマークや、より高性能なモデルに役立つベンチマークが含まれていることに注意してください。 本研究で検討したモデルサイズとトークン数の組み合わせのいずれについても、これらのベンチマークに依存する場合は、結果が参考にならないため、注意することをお勧めします。
結論と限界
このキャリブレーション実験を行った後、評価ガントレットの構成を変更し、グループ3「振る舞いの悪いベンチマーク」のタスクを削除しました。 これにより、スコアの合計に含まれるノイズの量を減らすことができました。 ノイズの多いベンチマーク(グループ4)は、特に数学とMMLUなど、私たちが改善に関心のある課題の成績を測定するため、そのままにしています。 グループ 2 のベンチマークについては、FLOPS との相関の強さと単調性に基 づいて、デフォルトの少数ショット設定を選択しました。
モデルのスケールとベンチマークの性能の関係は確立されていますが、どのベンチマークでも、モデルのスケールによって必ずしも向上しない能力を測定している可能性があります。 この場合、この較正法を使った判断は見当違いだったことになります。 さらに、私たちの分析は、限られたモデルのスケールとアーキテクチャに依存しています。 これらのベンチマークでは、異なるモデルファミリーが異なるスケーリング挙動を示す可能性があります。 今後の研究では、より幅広いモデルのサイズとタイプを検討し、これらの知見の頑健性をさらに検証することができるでしょう。
このような制約があるにもかかわらず、このキャリブレーション作業により、モデルの進歩に合わせてベンチマーク・スイートを改良するための原則的なアプローチが得られました。私たちの評価手法を言語モデルの経験的なスケーリング特性に合わせることで、進化する能力をより効果的に追跡し、比較することができます。 LLM Foundryレポの評価フレームワークを使用して、独自の評価指標をテスト することができます 。Mosaic AIトレーニングインフラでモデルをトレーニングする準備はできましたか? 今すぐご連絡ください。
謝辞
オリジナルのアイデアと実験を構築してくれたMansheej Paul、 モデルのトレーニングをしてくれた Sasha Doubov、 オリジナルのGauntletを作ってくれた Jeremy Dohmannに感謝します。