メインコンテンツへジャンプ登録する ![Mosaic AI: Build and Deploy Production-quality AI Agent Systems]()
![Databricks on Databricks - Transforming the Sales Experience using GenAI agents]()
生成 AI に関する投稿
データドリブンAIエージェントシステム開発を推進するための最新の進歩を探る
注目のストーリー

データサイエンス・ML
June 12, 2024/2分で読めます
Mosaic AI:本番運用のための複合AIシステムの構築とデプロイ

生成 AI
January 7, 2025/1分未満
"DatabricksはDatabricksをどう活用しているのか" - GenAIエージェントで販売体験を革新
すべての投稿
Loading...
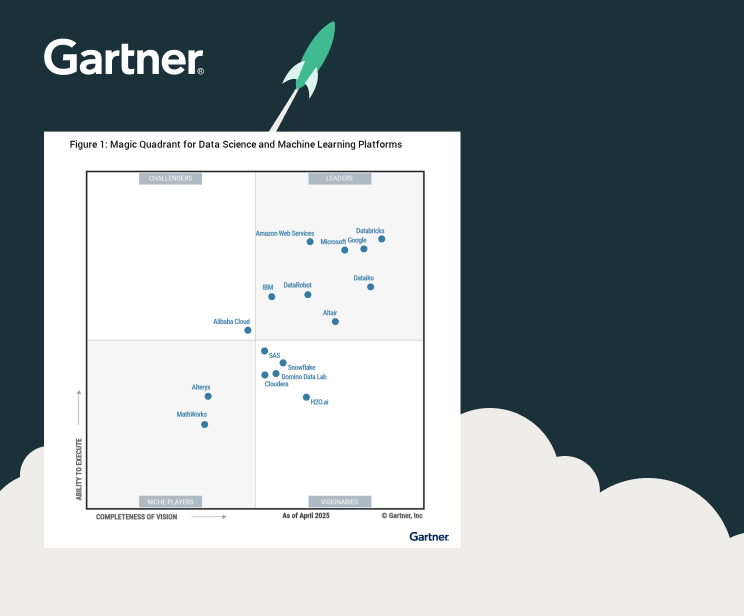
ANALYST REPORT
GartnerがDatabricksをリーダーに選出
Databricksの投稿を見逃さないようにしましょう
興味のあるカテゴリを購読して、最新の投稿を受信トレイに届けましょう