クラスターポリシー オンボーディング入門
クラスターポリシーによるデータプラットフォームの民主化

Original : Cluster Policy Onboarding Primer
翻訳: junichi.maruyama
はじめに
このブログは、Databricks環境を管理・維持するために重要なトピックに焦点を当てる「Admin Essentials」シリーズの一部です。ワークスペース組織、ワークスペース管理、UCオンボーディング、コスト管理のベストプラクティスについては、以前のブログをご覧ください!
データは、洞察に変換されて初めて有用なものとなります。データの民主化とは、過度なプロセスのボトルネックや、高価で恥ずかしい失敗をすることなく、データを付加価値を与えることができる人々の手に届けるセルフサービスプロセスである。例えば、若手のデータアナリストが「SELECT * from <massive table here>」という誤ったクエリを発行したり、適切な結合フィルタやキーがないデータエンリッチメントプロセスを行ったりするなど、不注意なミスは数え切れないほど存在します。データだけでなく、データを解析するために必要な基礎的な計算機への正しいアクセス権を確保し、ユーザーの無秩序を避けるためには、ガバナンスが必要です。データプラットフォームのガバナンスは、ユーザー、データ、コンピュートという3つの主要な領域に分けられます。
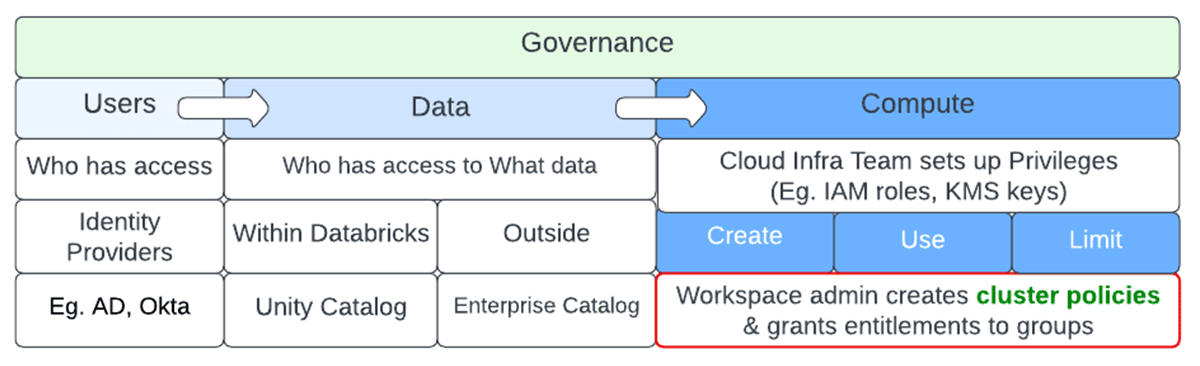
ユーザーのガバナンスは、適切なエンティティやグループがデータとコンピュートへのアクセスを持つことを保証します。エンタープライズレベルのIDプロバイ�ダは通常これを実施し、このデータはDatabricksに同期されます。データのガバナンスは、行と列のレベルで誰がどのデータセットにアクセスできるかを決定します。エンタープライズカタログとUnity Catalogは、これを実施するのに役立ちます。データパイプラインで最もコストがかかるのは、基盤となるコンピュートです。通常、クラウドインフラチームがアクセスを容易にするための特権を設定する必要があり、その後、Databricks管理者がcluster policiesを設定して、適切なプリンシパルが必要なコンピュートコントロールにアクセスできるようにします。repoを参照しながら進めてください。
クラスターポリシーのメリット
クラスタポリシーは、ユーザーと、ユーザーがアクセスできるクラスタ使用関連の特権との間の橋渡しをする役割を果たします。クラスタポリシーの主な利点は、プラットフォーム利用の簡素化と効果的なコスト管理の2つです。ユーザが試すべきノブの数が減るため、特にクラスタのサイジングに関する不注意なミスを減らすことができます。これにより、ユーザーエクスペリエンスの向上、生産性の向上、セキュリティ、コーポレートガバナンスに沿った管理体制が実現します。ユーザーごとの最大使用量、ワークロードごとの最大使用量、��時間ごとの最大使用量を設定し、コストがかかるリソースタイプへのアクセスを制限することで、使用料金を予測しやすくすることができます。例えば、制限されたノードタイプ、タグ付けとオートスケールによるDBRバージョンなどです(AWS, Azure, GCP)
クラスター・ポリシー定義
Databricksでは、クラスタUI、指定したコンピュートリソースを起動するジョブ、REST API、BIツール(例:PowerBIはクラスタを自己起動)、Databricks SQLダッシュボード、アドホッククエリー、サーバーレスクエリーを介して、コンピュートリソースを呼び出す方法がいくつかあります。
Databricksの管理者は、企業レベルでコンピュートリソースを作成、使用、制限するための条件を規定するルールを定義するクラスタポリシーを作成、デプロイ、管理することを任務とします。一般的に、これは様々な LOB (Lines of Business) がそれぞれの要件を満たし、企業全体のガイドラインに沿うように適応、調整されます。各コントロールエレメントが境界を設定するためのいくつかの戦略を提供するため、ポリシーの定義に多くの柔軟性があります。様々な属性がここにリストアップされています。
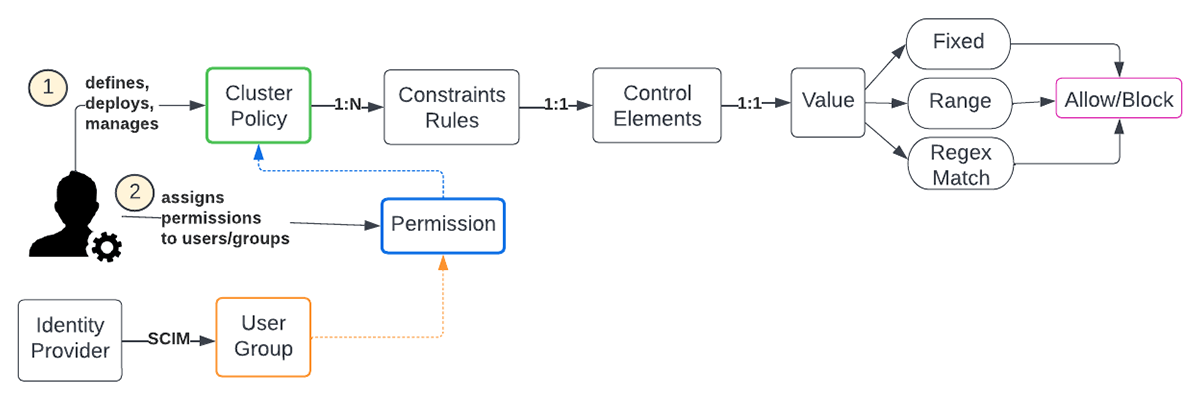
ワークスペース管理者は、すべてのポリシーに対する権限を持ちます。クラスタを作成する場合、非管理者は、権限が付与されたポリシーのみを選択できます。ユーザーがクラスタの作成権限を持っている場合、「制限なし」ポリシーを選択することもでき、完全に設定可能なクラスタを作成することができます。次の問題は、どの程度の数のクラスタポリシーが十分であると考えられるか、また、どのようなセットが良いかということです。
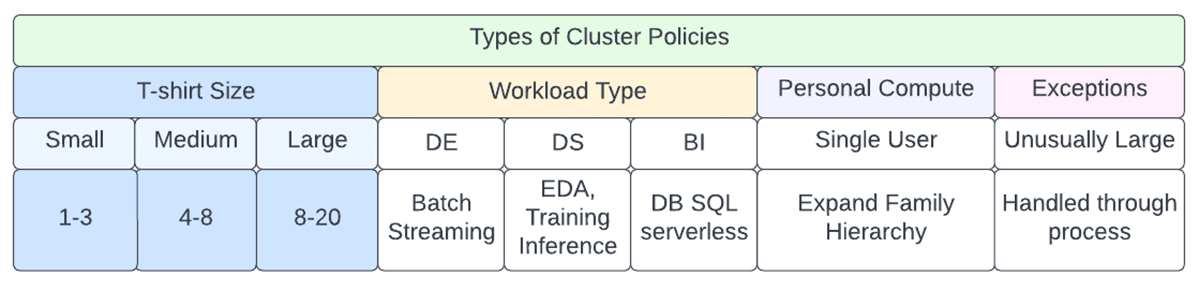
ワークスペースのデプロイ時にすぐに提供される標準的なクラスターポリシーファミリーがあり(これらは最終的にアカウントレベルに移行されます)、ベーステンプレートとして使用することが強く推奨されています。ポリシーファミリーを使用する場合、ポリシールールはポリシーファミリーから継承されます。ポリシーは、追加のルールを追加したり、�継承されたルールを上書きすることができます。
現在提供されているものは以下の通りです。
- Personal Compute & Power User Compute (all-purposeクラスタを使用するシングルユーザー)
- Shared Compute(マルチユーザー、all-purposeクラスタ使用)
- Job Compute (ジョブコンピュート)
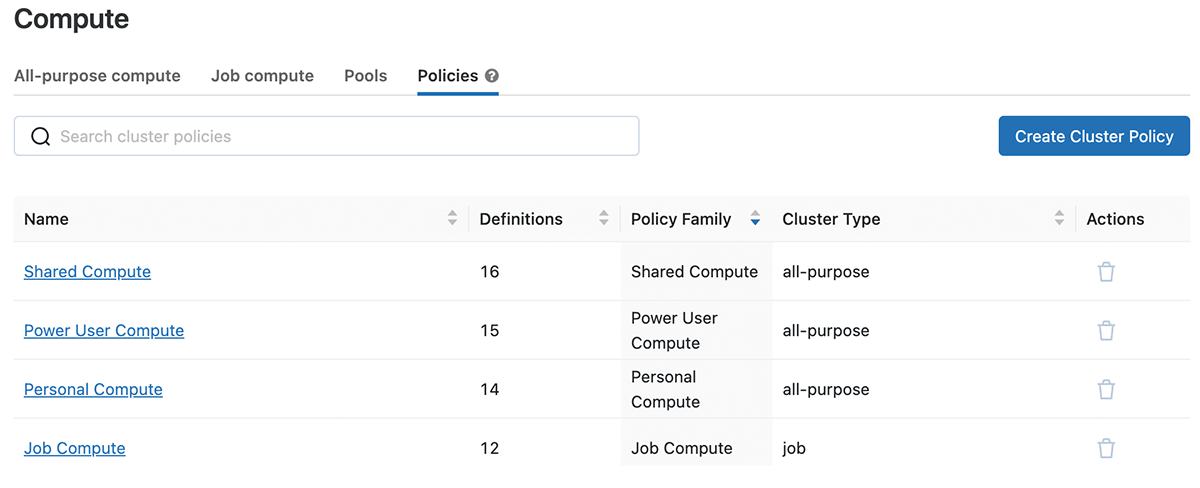
ポリシーファミリーをクリックすると、JSON定義と、それに関連するベース、パーミッション、クラスタ、ジョブへのオーバーライドが表示されます。

4つのクラスタファミリーがあらかじめ定義されており、そのまま使用したり、組織のさまざまなニーズに合わせて他のクラスタファミリーを追加することができます。以下の図を参照して、ワークロードの種類、サイズ、およびペルソナを考慮した上で、企業レベルで実施する必要があるポリシーの初期セットを計画します。
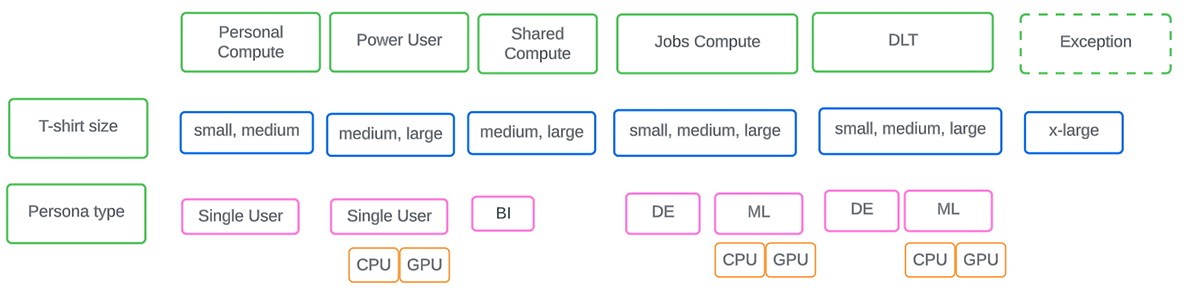
企業におけるクラスターポリシーの展開

- Planning(計画): 予算管理、タグによる使用状況の把握、コストセンターによる正確なチャージバック、互換性とサポート要件のためのランタイムバージョン、規制当局の監査要件など、企業統治のゴールを明確にする。
- クラスタポリシーの「無制限」権限は、クラスタポリシーをバイパスするためのバックドアルートを提供するので、管理者以外のユーザーには抑制する必要があります。この設定は、ユーザー用のワークスペース設定で提供されます。さらに、ほとんどのユーザーに対して、対話型クラスタに対して「再起動可能」だけを提供することを検討します。
- プロセスでは、例外シナリオを処理する必要があります。たとえば、正式な承認プロセスを使用して、異常に大きなクラスタを要求します。クラスタポリシーの有効性を定量化できるように、主要な成功指標を定義する必要があります。
- 適切な命名規則は、自己記述と管理の必要性に役立ち、ユーザーは直感的にどれを使うべきか、管理者はそれがどのLOBに属するかを認識できるようにする。例えば、mkt_prod_analyst_medは、LOB、環境、ペルソナ、Tシャツのサイズを表します。
予算追跡API(プライベートプレビュー)機能により、アカウント管理者はDatabricksの利用予算を定期的また��は単発的に設定し、閾値を超えた場合にメールで通知を受け取ることができます。
- Defining(定義): 最初のステップは、Databricksの管理者がプレミアム以上のワークスペースに対して Cluster Access Control を有効にすることです。管理者は、LOBに継承され、適応される基本クラスタポリシーのセットを作成する必要があります。
- Deploying(デプロイ): クラスタポリシーは、ロールアウトの前に慎重に検討する必要があります。頻繁な変更はエンドユーザーを混乱させ、本来の目的を果たさないため、理想的ではありません。新しいポリシーを導入したり、既存のポリシーに手を加えたりすることがありますが、そのような変更は自動化を使用して行うのが最適です。クラスタポリシーが変更されると、その後に作成されるコンピュートにも影響します。"クラスタ "と "ジョブ " タブは、ポリシーを使用しているすべてのクラスタとジョブを一覧表示し、同期していないクラスタを特定するために使用することができます。
- Evaluating(評価) : 計画段階で定義した成功指標を継続的に評価し、ポリシーとプロセスの両レベルで調整が必要かどうかを確認する必要があります。
- Monitoring(監視): クラスタの定期的なスキャンを行い、関連するクラスタポリシーなしにクラスタが起動されていないことを確認する必要があります。
クラスターポリシー管理・自動化
クラスタポリシーは、どのユーザーがどのクラスタポリシーを使用できるかを管理するCluster Policies API 2.0とPermissions API 2.0 (Cluster policy permissions) を使用してJSONで定義します。Clusters API 2.0で制御されるすべてのクラスタ属性、最大DBU時間などの追加合成属性、およびクラスタを作成するソースの制限をサポートしています。
クラスタポリシーのロールアウトは、プロダクション��にロールアウトする前に下位環境で適切にテストし、クラスタ作成権限の不備による不慮のジョブ失敗を避けるため、事前にチームに伝える必要があります。旧バージョンで稼働している古いクラスタでは、UIまたはREST APIを通じて新しいポリシーを採用するために、クラスタの編集と再起動が必要です。本番環境ではソフトロールアウトを推奨しており、最初の段階ではタグ付け部分のみを実施し、すべてのグループがグリーンシグナルを出したら次の段階に移行します。最終的には、クラスタポリシーガバナンスを回避するためのバックドアがないことを確認するために、制限付きユーザーの制限なしポリシーへのアクセス権を削除します。次の図は、段階的なロールアウト・プロセスを示しています:

クラスタポリシーの展開を自動化することで、ヒューマンエラーを減らすことができます。
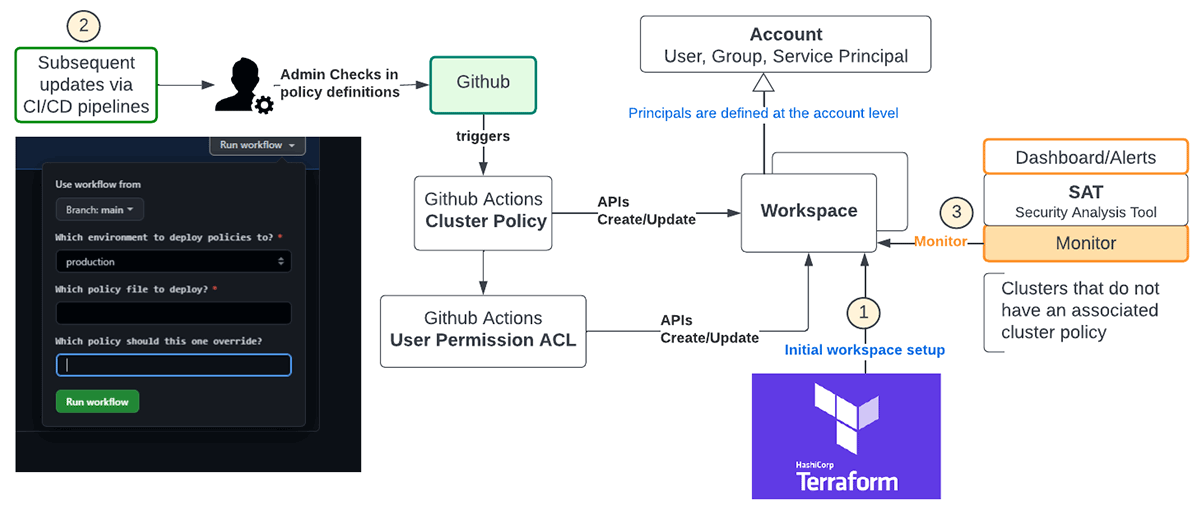
- Terraformはマルチクラウドの標準であり、新しいワークスペースとそれに関連する設定をデプロイするために使用する必要があります。例えば、これはTerraformでこれらのポリシーをインスタンス化するためのテンプレートであり、クラスタポリシーの状態を維持するという利点もある。
- ワークスペース全体のポリシー定義のその後の更新は、CI/CDパイプラインを使用して管理ペルソナによって管理される必要があります。上図は、Githubアクションで管理されるGithubワークフローを示し、選択したワークスペースにポリシー定義と関連するユーザー権限をデプロイします。
- REST APIを活用して、ワークスペース内のクラスタを明示的または暗黙的に監視し、SATツールを使用して企業全体のコンプライアンスを確保することができます。
Delta Live Tables (DLT)
DLTは、Databricks上のETLプロセスを簡素化します。デフォルトとメンテナンスの両方のDLTクラスタに単一のポリシーを適用することが推奨されます。パイプラインのクラスタポリシーを構成するには、次のように cluster_type フィールドが dlt に設定されたポリシーを作成します。here
外部メタストア
管理者が定義した外部メタストアにアタッチする必要がある場合、�以下のテンプレートを使用することができます。
サーバーレス
サーバーレスアーキテクチャがない場合、クラスタポリシーは管理者が管理し、コンピュートリソースを作成、管理、制限するためのコントロールノブを公開します。サーバーレスでは、この管理者の責任がある程度軽減されると思われます。しかし、ワークロードの特定のニーズやプロファイルに合わせてコンピュートリソースを柔軟に作成するために、これらのノブは必要です。
Summary
要約すると、クラスタポリシーは企業全体で可視化され、管理者は以下のことが可能になります:
- エンドユーザーのクラスタ構成を制御してコストを抑える
- エンドユーザーによるクラスタ作成を効率化する
- コスト管理のため、ワークスペース全体にタグ付けを強制する。
CoE/Platformチームは、必要なガバナンスをもたらす可能性がありながら、適切に行わなければ全く効果がないため、これらの導入を計画する必要があります。これは単なるコスト削減ではなく、あらゆるデータプラットフォームにとって重要なガードレールについてです。
ここでは、効果的な実装を確実にするための推奨事項を紹介します:
- まず、個人利用、共有利用、ジョブという一般的な3つのユースケースについて、あらかじめ設定されたクラスタポリシーから始め、Tシャツのサイズやペルソナのタイプによってポリシーを拡張し、ワークロードのニーズに対応する。
- LOBチームが基本ポ�リシーを継承し、各自のシナリオに合わせて変更できるように、命名とタグ付けの規約を明確に定義する。
- 新しいものを追加したり、古いものに手を加えたりできるように、変更管理プロセスを確立する。
クラスターポリシーを導入するためのサンプルは、 repoを参照してください。


