Cracking the Code: Databricksがバイオメカニクスデータでメジャーリーグを再構築する方法

公開日: November 1, 2023
によって Harrison Flax、Chris Niesel、Hussain Vahanvaty による投稿
翻訳:Saki Kitaoka. - Original Blog Link
バイオメカニカルデータは、メジャーリーグ(MLB)のチームにとって、選手のパフォーマンスを向上させ、怪我を減らすという競争上の優位性を提供する、ゲームを変える要素として登場しました。しかし、その潜在的な可能性にもかかわらず、ほとんどのチームはその能力を十分に活用できずにいます。
バイオメカニクスデータのソースは、ウェアラブルセンサー、フォースプレート、モバイルデバイス、そして特に高速度カメラなど多岐にわたります。2020年、各球場に12台のカメラを戦略的に配置したHawk-Eye Statcastシステムの登場は、大きな前進でした。これらのカメラのうち5台は投球と打撃専用で、毎秒100フレーム(FPS)で作動。残りの7台のカメラは、フィールドプレーヤーと打球に焦点を当て、50 FPSでデータを取得します。これらのカメラシステムを合計すると、MLBのレギュラーシーズン2,430試合ごとに24テラバイトという途方もない量のデータが生成されます。
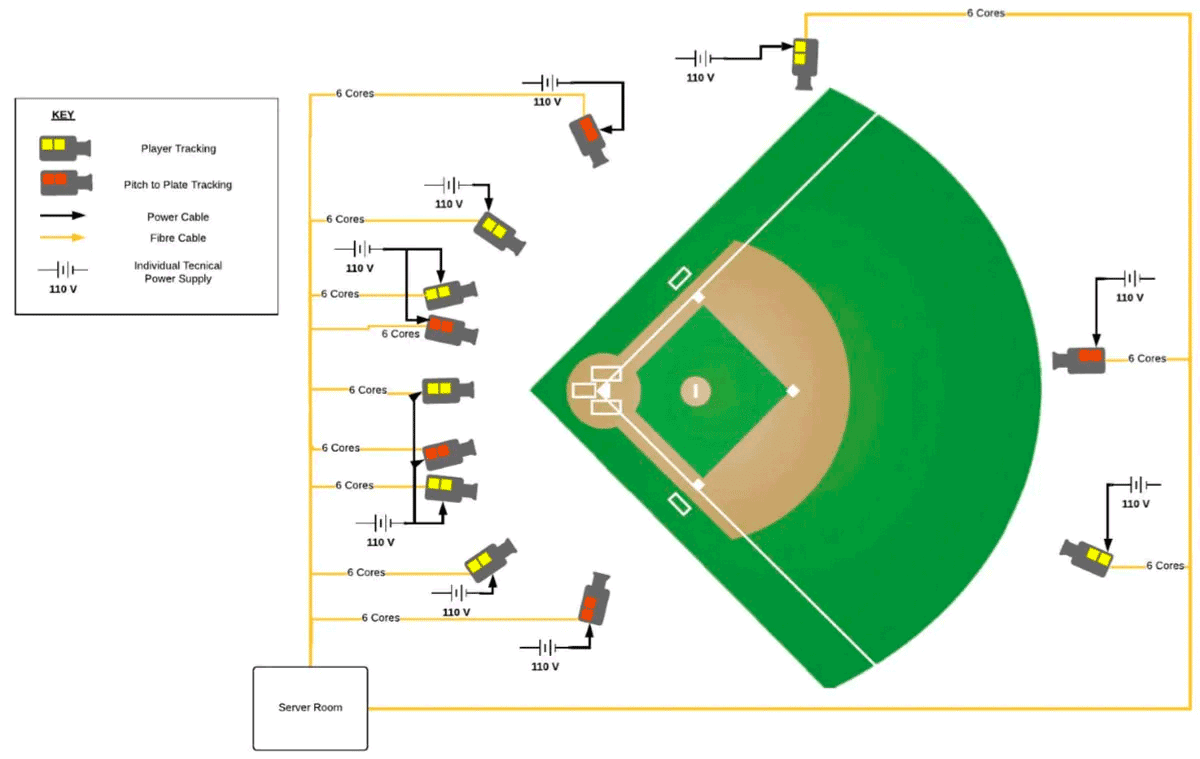
しかし、膨大な量のデータと、それを取得するための革新的なテクノロジーにもかかわらず、多くのMLBチームはいまだに伝統的な手法でデータを分析しています。理由はいくつかありますが、より高度な手法を採用する上で最も一般的な障害は、コスト、スキルセット、技術的制約などのリソース不足によるものです。
従来の分析ツール: データウェアハウス
データウェアハウスのような従来の分析ツールは、バイオメカニクスデータと分析を扱う際にいくつかの欠点に直面します。ここでは、データウェアハウスを使ったバイオメカニカルデータの適応において懸念される4つの領域を紹介します。
第一に、バイオメカニクスデータのための正確でスケーラブルなデータパイプラインの確立は本質的に複雑です。データレイクとウェアハウスを分離した2階層データアーキテクチャが一般的です。ほとんどのチームは現在、生データをデータレイクに置き、データウェアハウスでデータを複製することで何らかの分析を実行できることを期待しています。これらの異種システムは、データ型、SQL方言、データスキーマに矛盾があることがよくあります。これは不整合につながり、抽出、変換、ローディング(ETL/ELT)プロセスでの失敗やエラーのリスクを高めます。
第二に、多くのバイオメカニクス・アプリケーションは、よりリアルタイムのデータへのアクセスを必要とします。しかし、既存のデータアーキテクチャでは、データロードのために個別のステージング領域と定期的なETL/ELTジョブを採用しているため、データの陳腐化の問題が生じています。コーチやアスリートは、次の試合に備えてパフォーマンスを向上させ、怪我を予防するために、より迅速なフィードバックを必要としています。
第三に、バイオメカニクスデータのかなりの部分は、ビデオ映像、トラッキングデータ、派生メトリクス、メタデータを含む非構造化データです。しかし、従来のSQLデータウェアハウスや関連APIは、このような非構造化バイオメカニクスデータの処理には適していません。
最後に、バイオメカニクスにおける機械学習とデータサイエンスの採用の増加は、従来のデータウェアハウスとデータレイクの限界を浮き彫りにしています。これらのアプリケーション�では、SQL 以外の大量のデータを処理することが多いため、ODBC/JDBC 接続だけに頼っていると非効率的です。そのため、バイオメカニクス解析とモデリングの進化するニーズをサポートするために、オープンフォーマットでバイオメカニクスデータへの直接アクセスを提供することがますます重要になっています。

最先端のテクノロジー:バイオメカニクスのためのDatabricks Lakehouse
Lakehouseアーキテクチャを開発したDatabricksは、ビッグデータ処理に最適化されています。Databricksは、MLB全体のバイオメカニクス解析に最適なプラットフォームとして急速に台頭しています。
DatabricksがMLBで支持されている理由は以下の通りです:
大規模データ処理
Databricksは本来、分散コンピューティングで膨大なデータ量を管理するように設計されています。バイオメカニカルデータを取得するソースが多数あるため、一元的なデータ管理が必要です。現在、ほとんどのチームがパッチワークのようなソフトウェアシステムを採用しており、冗長性、データのサイロ化、処理時間の遅さ、法外なコストにつながっています。
Databricksは、チームのすべてのデータを、その構造に関係なく、一つ屋根の下で集中管理することを可能にします。これは、データレイクのストレージ機能とデータウェアハウスの組織能力を組み合わせたLakehouseアーキテクチャによって可能になります。Databricksを使用することで、チームは現在のデータと過去のデータの両方を迅速に処理し、意味のある洞察を導き出すことができます。
ストリーミング処理
練習や試合中にコーチや選手が十分な情報に基づいた判断を下せるようになるため、リアルタイムの洞察を引き出す能力は非常に貴重です。Databricksは、イベント単位でのバイオメカニクスのストリーミングを、1回ごとの処理を保証することで容易に実現します。これにより、1回のパスで処理されるデータ量が大幅に削減され、プロセスがイベントドリブンになり、データ処理がインクリメンタルになります。
多くの場合、MLBのチームは、試合に影響を与えたり、重要な選手の怪我を防いだりすることができる情報を受け取るまで、数時間から数日間も待たなければなりませんでした。しかし、Databricksの構造化ストリーミングはこの問題を軽減します。
機械学習処理
Databricksは高度な機械学習機能をネイティブサポートしています。これにより、データを別プラットフォームにコピーする必要なく、レイク内のデータで直接エンドツーエンドの機械学習ライフサイクルを簡素化します。Databricksがオープンソースで提供するMLOps「MLflow」は、一連の機械学習機能をユーザーに提供します:
- エクスペリメントの追跡 - モデルパラメータの記録と比較、パフォーマンスの評価、成果物の管理。
- コードパッケージング - コードの再利用と複製を容易にし、ワークフローを合理化します。
- モデルのデプロイメント - さまざまな機械学習ライブラリから��リアルタイム、バッチ処理、推論プラットフォームにモデルをデプロイします。
- 一元的なモデル管理 - バージョン管理とシームレスなステージ遷移を完備した中央リポジトリでモデルを共同管理します。
DatabricksとMLflowは、野球選手育成のための貴重な洞察を発見することを可能にします。例えば、ドラフト外や最近ドラフトされた選手は、かなりの不確実性を生み出します。というのも、新人がチームに大きな影響を与えるには3〜4年かかるからです。その結果、MLBの組織は長期的な戦略を立てなければなりません。
テキサス・レンジャーズのマイナーチームでのエバン・カーターのストーリーは、MLBの可能性を例証するものです。カーターはアマチュア時代、ショーケースにほとんど参加しなかったため、大きくスカウトされることはありませんでした。限られたデータしかなかったにもかかわらず、彼のバイオメカニクスをMLで分析したところ、生まれつきの才能が発掘されたのです。
スケーラビリティ
バイオメカニクスで生成されるデータ量が増加し続ける中、処理の増減をスケールアップする能力は不可欠です。Databricksを使用すれば、チームは必要なだけのコンピュートへ即座に、そして柔軟にアクセスできます。ジョブは、Databricks Workflowsを介してプラットフォーム内で直接オーケ�ストレーションできます。
Databricksプラットフォームは、ストレージとコンピューティングを分離することで、総所有コストを削減します。この例は、2023 Data+AI SummitでのTexas Rangersのプレゼンテーションで示されました。レンジャーズは、予算を変更することなく、新しいデータパイプラインを作成する際に、データ速度が7倍向上しました。
コラボレーション環境
MLB 加盟チームは、国内外を問わずプロリーグとマイナーリーグにまたがっています。Databricksは、組織の分散に関係なく、データエンジニア、データサイエンティスト、データアナリストのためのコラボレーション環境を提供します。これにより、一つ屋根の下でのシームレスなデータ共有、モデル開発、改良が容易になります。
まとめ
結論として、メジャーリーグにおける選手のパフォーマンスと傷害予防に革命をもたらすバイオメカニクスの可能性は疑いようがありません。しかし、これらのメリットを実現するには、最新かつ俊敏でスケーラブルなデータ処理プラットフォームが必要です。Lakehouse アーキテクチャを採用した Databricks は、MLB チームがバイオメカニクスデータの可能性を最大限に活用できるようにする画期的なソリューションです。Databricksがあれば、データ量、多様性、速度、リアルタイムの洞察、非構造化データの処理、高度なアナリティクスの強固なサポートといった課題を克服することができます。で��は、なぜ待つのでしょうか?今すぐバイオメカニクス解析の未来に参加し、Databricksでチームの新たな可能性を引き出しましょう。ぜひお試しいただき、貴社の競争力を高めてください。
Databricksのスポーツチームへのお問い合わせは、Harrison Flaxまでご連絡ください。


