Lakehouseの価値を最大化するためのデータアーキテクチャパターン

公開日: April 26, 2023
によって ベルンハルト・ワルター、マグヌス・ピエール、Marco Scagliola、Matthieu Lamairesse による投稿
Original Blog : A data architecture pattern to maximize the value of the Lakehouse
翻訳: junichi.maruyama
Lakehouseの優れた成果の1つは、従来のBI、機械学習&AIといったモダンなユースケースのワークロードを1つのプラットフォームで組み合わせることができることです。このブログ記事では、「1つのプラットフォームに2つのサイロがある」というリスクを軽減するアーキテクチャ・パターンを説明しています。本ブログで紹介す�るアプローチに従えば、機械学習やAIを利用するデータサイエンティストは、組織のビジネス情報モデルから得られる信頼性の高いデータに容易にアクセスできるようになります。同時に、ビジネスアナリストは、中核となるエンタープライズデータウェアハウス(EDW)の安定性と適合性を維持しながら、レイクハウスの機能を活用してデータウェアハウス(DWH)プロジェクトのデリバリーを加速させることができます。
データレイクとDWHという2つの世界の橋渡しをするのに役立つ、セマンティック一貫性という概念を紹介します:
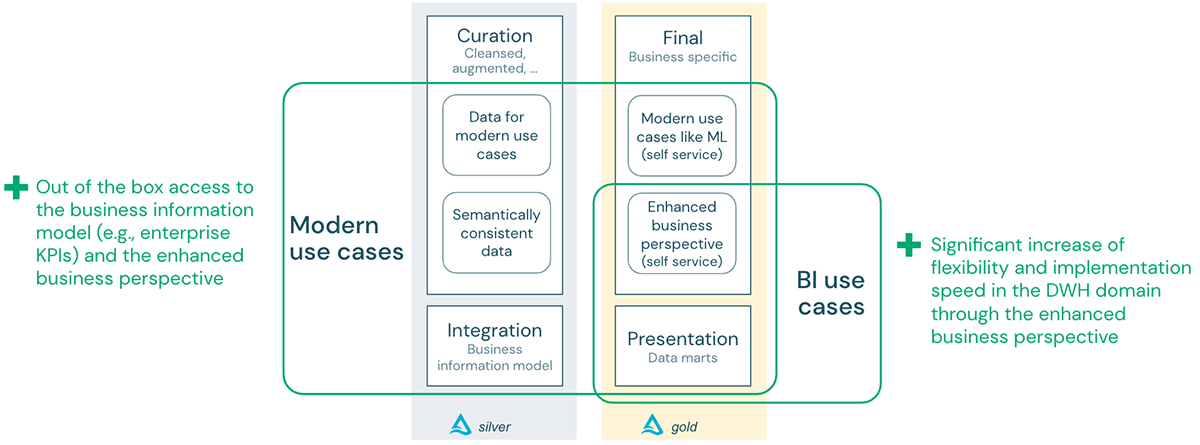
背景
このブログ記事では、データレイク上でのモダンなユースケースと、データウェアハウス上での従来のBIユースケースを区別して説明します:
モダンなユースケースのためのデータレイク 現代のユースケースは、通常、データレイクに保存されたデータに対して機械学習やAIを使用します。どちらのアプローチも、行動や起こりうる結果を予測するモデルを作成し、ビジネスユーザーが事前に適切な行動を取れるようにすることを目的としています。
機械学習モデルは、データセットに対して学習(教師ありまたは教師なし)され、以前に見たことのないデータセットからパターンを見つけたり予測を行ったりするように最適化されます。ディープラーニングは、機械学習のサブセットで、人間の脳の構造と機能から着想を�得たアルゴリズムを使用します。ディープラーニングは、従来のタスクに特化したアルゴリズムではなく、データ表現の学習に基づく、より広範な機械学習手法の一群に属します。機械学習では、ユースケースのためにデータレイクに明示的に取り込まれた大規模なデータセットを使用することがよくあります。
データウェアハウスは、複数のコアビジネスソリューションから現在および過去のデータを保存するデータ管理システムです。データウェアハウスは、組織がどのようにビジネスを行っているかをモデル化したもので、洞察やレポーティングを容易に行うことができます。データウェアハウスは、BI、レポーティング、データ分析のために、運用データベースからデータを抽出・集約します。データウェアハウスの利点は、多くのソースからのデータを統合し、履歴情報を提供し、分析処理をトランザクションデータベースから切り離すことです。データウェアハウスは、データの品質と正確性を確保し、例えば、異なる製品タイプ、言語、通貨に対する命名規則やコードによって一貫性を持たせることでデータを標準化します。
データウェアハウスの構築は、厳密で統制のとれたプロセスに従って行われます: ビジネスアクターとプロセスは、ビジネス情報モデルでモデル化されます。このモデルを流れるデータは、論理データモデル(技術にとらわれない)として反映され、データウェアハウスのデータベース技術に応じて、物理データモデルとして実装されます。このプロセスは比較的時間がかかりますが、(ビジネス価値のない)生データをビジネス全体の文脈に適合したデ�ータに変換し、実用的で信頼性のあるビジネス情報を生成します。
従来、データウェアハウスは企業のビジネスプロセスを内観するものでした。それらのプロセスからデータを統合すると、通常、顧客の在庫や契約書など、その企業に固有のマスターデータが含まれます。私たちが利用できるデータの多くが外部データであるため、このデータをモデル化する必要性は、いくつかの理由からかなり低くなっています:
1)自社のデータではなく、自社のプロセスを記述するものでもない、
2)私たちの「コアデータ」との関連性を十分に理解していない可能性があること。
3)私たちが反応したいと思うかもしれない会社の外部のもの(データ信号)を記述しているが、「私たちが運営しているビジネスプロセスからの信頼できる情報」と同じレベルまで高めてはいけない。
しかし、それでも私たちは、このデータで「エンタープライズビュー」を補強し、新たな洞察を得ることができるようにしたいと考えています。
そして......何が問題なのでしょうか?
どちらのプラットフォームも、それを利用する組織に多大な価値を提供することができます。しかし、多くの組織がデータウェアハウスとデータレイクの統合に苦慮しています:
- データウェアハウスとデータレイクは通常、ほとんどあるいはまったく相互作用のない2つのサイロである。データウェアハウスとデータレイクは通常2つのサイロで、ほとんど相互作用がありません。データレイクからデータウェアハウスに(またはその逆に)データが重複していることもあり、データのサイロ化が新たな問題を引き起こしています。
- 最新のユースケースのためにデータウェアハウスにアクセスすることは困難であり、時には高いコストがかかることもあります(ML&AIプラットフォームとデータウェアハウスの両方に料金がかかる場合があります)。
- データウェアハウスは通常、機械学習やAI機能を内蔵するためのサポートを欠いています。データウェアハウスはSQLのみで、画像などの非構造化データやJSONなどの半構造化データを保存する機能が制限されています。
- データは、全体的な整合性を無視してデータレイクにコピーされることが多い。これは、データウェアハウスのデータとデータレイクのデータを簡単に統合できないことを意味します。
- 厳密な設計プロセスにより、DWHの変更と拡張に時間とコストがかかる。
レイクハウスで両者を両立させる
前述のように、Lakehouseの優れた成果の1つは、モダンなユースケースと従来のBIのワークロードを1つのプラットフォームで組み合わせることができることです。これは、いくつかの利点につながります。
では、例を見てみましょう。
ある大企業では、セールスサイクル全体を通じてSalesforce(CRM)を使用しています。案件が成立すると、Salesforceで注文が作成され、プロセス統合フェーズを経由してSAPに転送されます。プロセス統合のロジックは、「注文」と「顧客」のデータをSAPのデータモデルコンテキストに変換します。
レポーティングのために、両システムのデータはLakehouseに取り込まれる:
- 財務報告に関連するSAPデータは、LakehouseのDHWパートに統合されます。
- Salesforceのパイプラインデータ�は、高度な分析、およびLakehouseのAIユースケースのためのデータレイクパートに統合されます。
データセットは、ゴールドレイヤーでビジネス固有のテーブルやBIデータマートに投影されます。
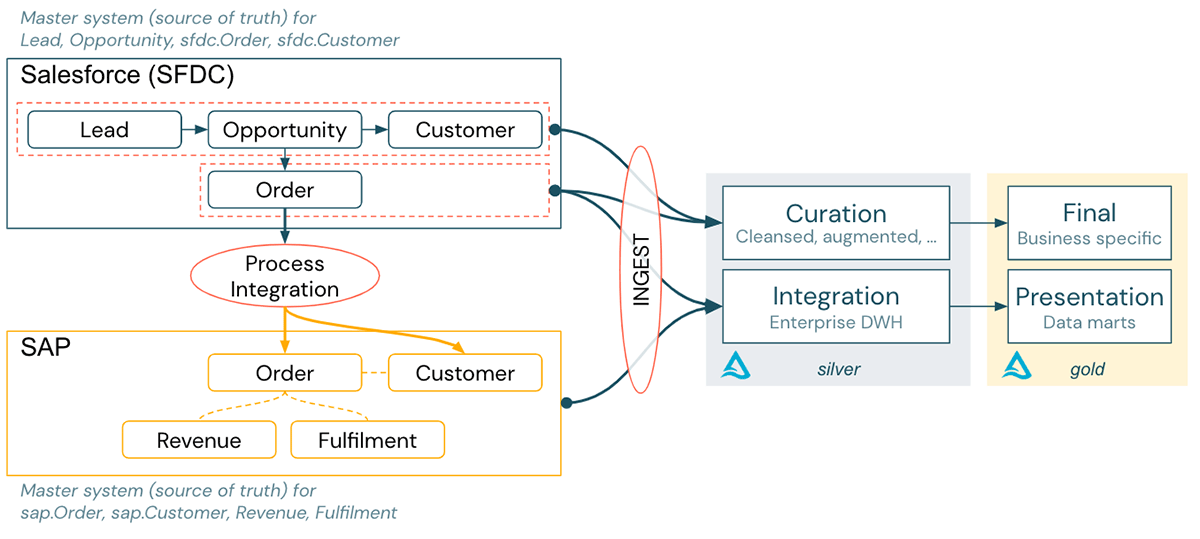
この設定を踏まえて、以下のように作成します:
- ゴールドレイヤーの業務に特化したデータからの売上予測レポート。
- 全体の財務報告の文脈で、データマートから収益認識レポート。
どちらのレポートも独立しているので、SalesforceとSAPから取り込んだデータを組み合わせる必要はない。
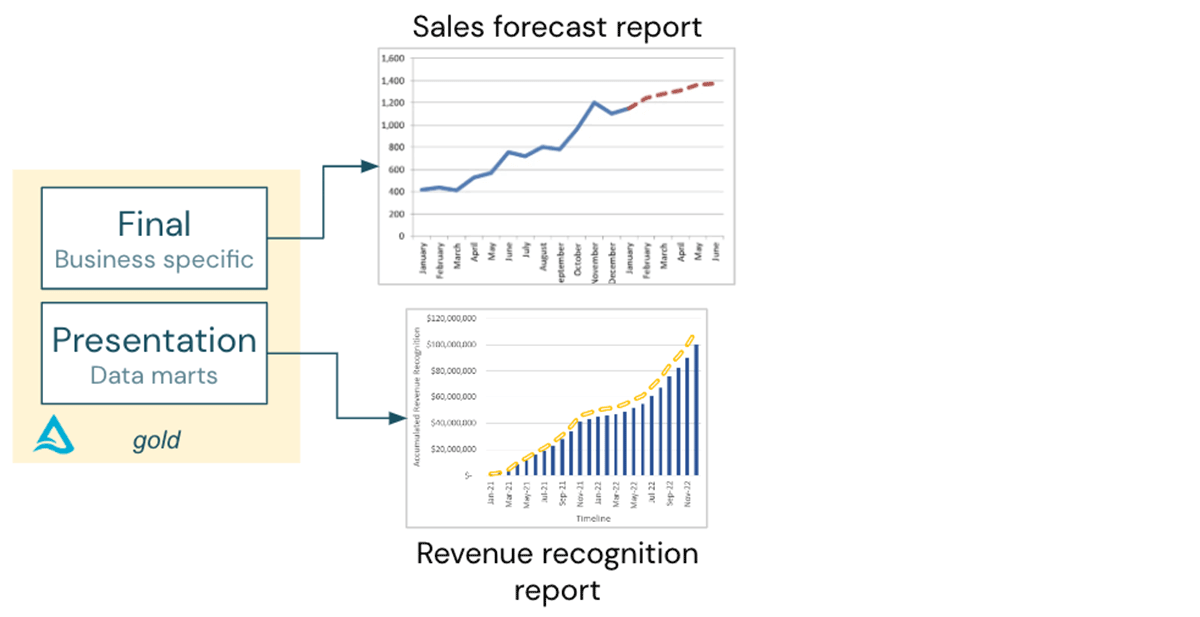
今度はCFOが「収益認識予測レポート」を要求してきた!
ビジネスの観点から、CFOからの新しい要請は、会社の標準的な収益認識パターンをモデル化することを求めています(通常、収益は製品またはサービスが顧客に引き渡されたときに認識されます。一部のサービスは長期間にわたって提供されるため、長期的に収益を認識するモデルが必要です)。このモデルは簡略化することができますが、実装されているSAPの収益認識ロジックと整合性がとれている必要があります。
データの観点からは、収益認識予測には、Salesforceのセール��スパイプラインデータとSAPの収益データを組み合わせる必要があります。
前述の「プロセス統合」ステップでは、SAPのデータモデルの要件に準拠するために、Salesforceのエンティティに変換とビジネスロジックを適用します。語彙や粒度が異なる可能性が高いため、Lakehouseで2つのシステムのデータを単純に結合することはできません。
次の2つの方法があります。
- SalesforceのオブジェクトをIntegrationレイヤーに追加する(つまり、ビジネス情報とデータモデルを強化する)。このアプローチは一般的に時間がかかり、簡単に数ヶ月かかることがあります。さらに、これらのオブジェクトをビジネス情報モデルに追加するのは、このレポートが必要なビジネス資産であることが証明された後であるべきです。
- Integrationレイヤーのデータ(sap.order、収益など)とキュレーションレイヤーのデータ(リード、機会、sfdc.order)を結合する。ただし、この方法は、キュレーションレイヤーのSalesforceテーブルがインテグレーションレイヤーのデータと意味的に一致している場合にのみ可能です。
オプション1は最も簡単で最速のアプローチではないので、オプション2について理解しましょう。
セマンティックコンシステンシー
セマンティック・コンシステントとはどういう意味ですか?
通常、データレイクに取り込まれたデータは、取り込み層からキュレーション層へと移動する際にクレンジングされます。データを意味的に一貫したものにするためには、ビジネスコンテキストの観点からも整合性をとる必要があります。例えば、異なるシステムからの顧客データや収益データは、両方のレイヤーで同じ意味を持たせる必要があります。そして、適切なレベルで、データの重複を排除する必要があります。
この追加ステップにより、キュレーション層の意味的に一貫したデータをインテグレーション層のデータと安全に結合し、ゴールド層のビジネス対応テーブルを提供できるようになります: 次の図に示すように、収益認識予測レポートが正常に作成されます。
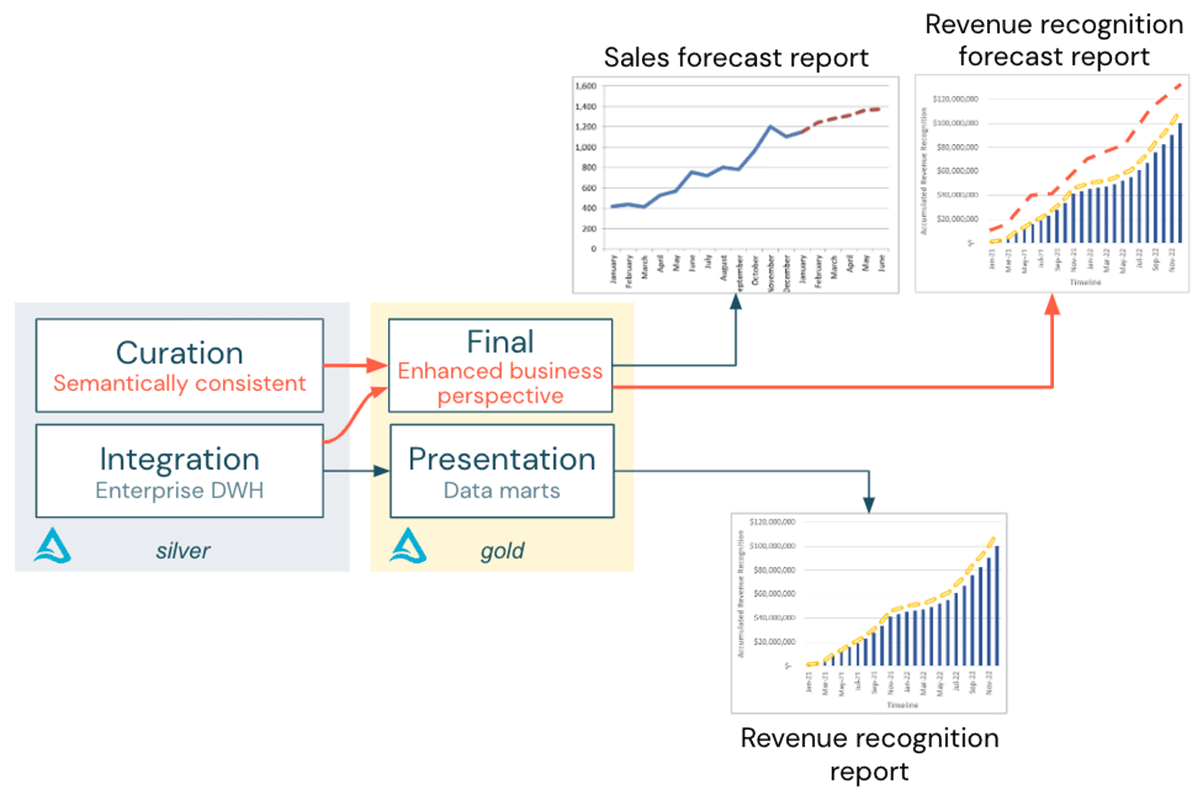
意味的な一貫性を実現するには?
上記のSAPとSalesforceの例でもう一度見てみましょう。まず最初に行うべきは、結合が必要なテーブルの用語と粒度を揃えることです:
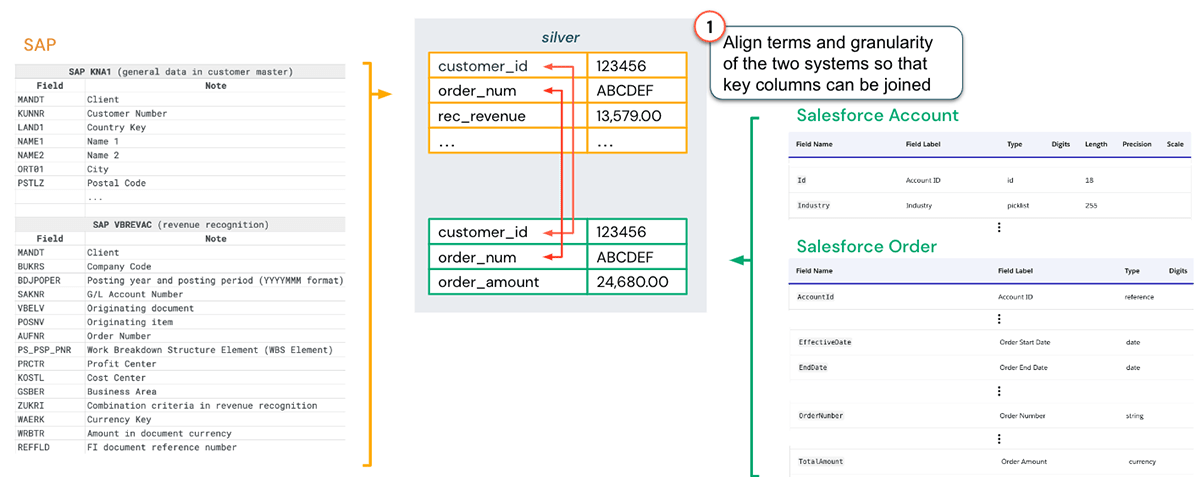
次のステップは、収益認識モデルの構築です。レイクハウスの主な利点は、データマートに格納されたSAPの収益認識データが同じシステムで利用できるため、データサイエンティストが簡単にアクセスできることです(適切なアクセス権が付与されていることが前提)。このデータがあれば、下図に示すように、いくつかの標準的な収益認識プロファイルを作成することができます。

用語、粒度、収益認識プロファイルがSAPのデータとロジックと一致したことで、収益認識予測レポートに必要なデータは意味的に一貫しており、組み合わせることができるようになりました:
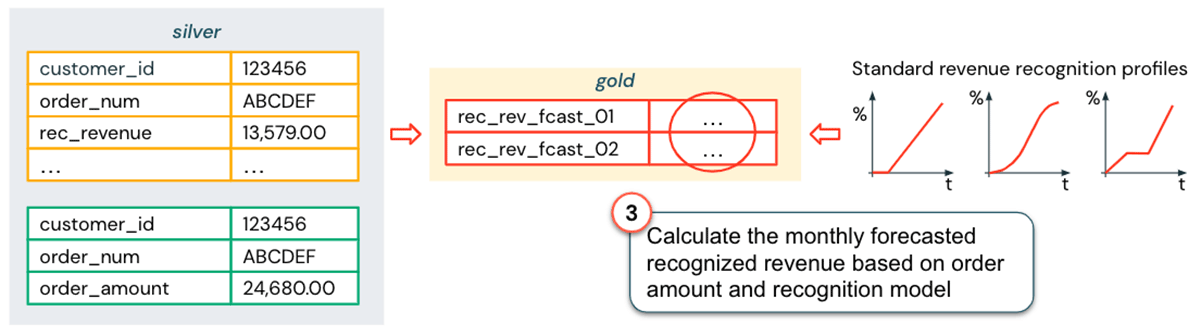
上記のプロセスは簡略化されていますが、一般的な考え方は明らかでしょう。Salesforceのデータをビジネス情報モデルとEDWに全体的に統合する代わりに、Lakehouseを使用すれば、より迅速かつ柔軟な方法で分析ユースケースを実装することができます: このレポートが財務報告の標準的な一部であると確信するまでは、セマンティック一貫性アプローチ(DWHの完全統合よりもはるかに小さな労力)を使用して、標準データマート内のビューを補完する「強化されたビジネス視点」を構築することができます。
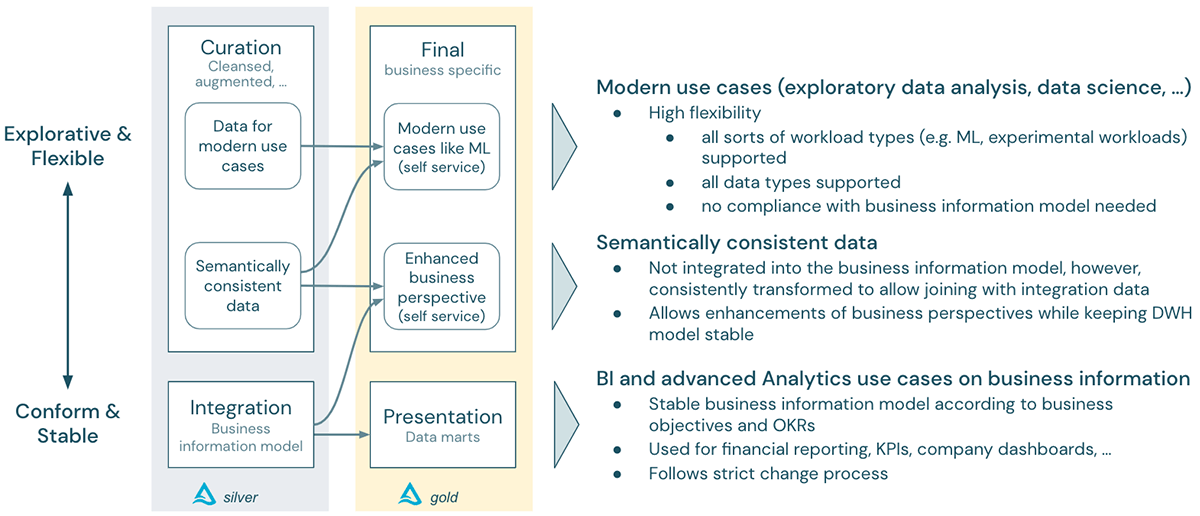
このように、Lakehouseは、現代の高度な分析ユースケースのパラダイムである探索的で柔軟な世界と、DWHの世界である安定的で適合的なパラダイムの橋渡しをするのに役立ちます:
概要
データウェアハウスとデータレイクの統合に関して、多くの組織が「2つのサイロ」という課題に悩まされています。レイクハウスは、機械学習やAIといった最新のユースケースに対応したワークロードと、従来のBIを1つのプラットフォーム上で統合したものです。このブログ記事では、データレイクとDWHの2つの世界を橋渡しし、「1つのプラットフォームに2つのサイロ」ができるのを回避するための、セマンティック一貫性の概念を紹介しました。
DWH層内のデータと結合するDWH層外のデータセットにセマンティック一貫性を適用することで、いくつかのメリットがあります:
- DWHレイヤーの外にあるデータのセマンティック一貫性を実現することは、そのデータをDWHに統合するよりもはるかに簡単です。
- その結果、コアとなるDWHが安定したまま、DWHの開発をより速く、より探索的に行うことができます。また、ある結果が永続的な価値を持つことが証明された場合、そのデータセットを後日DWHに統合することができます。
- データサイエンティストは、ビジネスKPIなど組織のビジネス情報モデルに由来するデータに簡単にアクセスでき、意味的に一貫性のあるデータと組み合わせることができます。
- 最後に、すべてのデータが意味的に一貫している必要はないので、データレイクアプローチの高速で探索的な性質は、現代のユースケースでも利用可能です。
時間の経過とともに、厳密にモデル化された部分は、コアビジネスソリューション以外のソースに劇的に追い抜かれることになると考えています。しかし、厳密にモデル化されたビジネスの部分は、依然とし�て組織にとって多くの価値を持ち、最新のデータレイクハウスから信頼できる情報を得るためのアンカーポイントとして重要です。

