Databricks における Databricks:Unity Catalog でガバナンスへの旅を始める
Unity Catalog を使用して、最大の Databricks ワークスペースを 10 か月で管理されたレイクハウスに変換

Databricks のデータ プラットフォーム チームとして、私たちは独自のプラットフォームを活用して、直感的で構成可能な包括的なデータおよび AI プラットフォームを社内のデータ担当者に提供し、彼らが安全に使用状況を分析し、製品とビジネス オペレーションを改善できるようにしています。 当社は成長するにつれて、安全でコンプライアンスに準拠した費用対効果の高いデータ運用を可能にするデータガバナンスを確立することに特に意欲を持っています。 何千人もの従業員と何百ものチームがデータを分析しているため、大規模なデータガバナンスと継続的なコンプライアンスを達成するには、一貫した基準を構築して実装する必要があります。 当社では、2022 年 8 月に一般公開された Unity Catalog (UC) を標準的なガバナンスプラクティスを確立するための基盤として特定し、社内レイクハウスの 100% を Unity Catalog に移行�することが会社の最優先事項となりました。
データガバナンスを実現するために Unity Catalog に移行する理由は何か?
データ移行は難しく、費用もかかります。 そこで私たちは自問しました。すべてのデータを Unity Catalog に移行せずにガバナンスの目標を達成できるだろうか?
私たちはすべてのテーブルを管理するために Databricks のデフォルトの Hive Metastore (HMS) を使用していました。HMS 上に独自のデータガバナンス機能をゼロから構築するのは無駄な作業であり、数四半期の遅れにつながります。 一方、Unity Catalog は、すぐに使用できる非常に大きな価値を提供しました。
- HMS 上のすべてのデータは誰でも読み取ることができました。 UC は、きめ細かなアクセスを安全にサポートします。
- HMS はリネージや監査ログを提供しません。 リネージ サポートは、データ フローを理解し、効果的なデータ ライフサイクル管理を実現するために不可欠です。 監査ログと組み合わせることで、データの変更と伝播に関する可観測性が得られます。
- 製品内検索機能との統合が強化された UC により、ユーザーは高品質なデータに注釈を付けたり、データを発見したりするための優れたエクスペリエンスを実現できます。
- Delta Sharing、クエリ フェデレーション、カタログ バインディングは、セキュリティやコンプライアンスのリスクを生み出すことなく、リージョン間のデータ メッシュを作成するための効果的なオプションを提供します。
Unity Catalog の移行はガバナンス戦略から始まる
大まかに言うと、次の 2 つのパスのいずれかに進むことができ�ます。
- リフトアンドシフト:すべてのスキーマとテーブルをそのままレガシー HMS から UC カタログにコピーし、すべてのユーザーにすべてのデータへの読み取りアクセス権を付与します。 このパスは、短期的には少ない労力で済みます。 しかし、HMS または有機的な成長を動機として、古いデータセットや一貫性のない悪いプラクティスを持ち込むリスクがあります。 クリーンアップのために、その後の複数の大規模な移行が必要になる可能性が高くなります。
- 変革:Unity Catalog でのデータ編成のコア構造を確立しながら、データセットを選択的に移行します。 この道筋は短期的にはより多くの努力を必要としますが、軌道修正の重要な機会を提供します。 その後の増分 (小規模) クリーンアップが必要になる場合があります。
私たちは後者を選びました。 これにより、将来のガバナンス ポリシーを導入するための基礎を築くと同時に、構築に必要な骨組みを提供することができました。 私たちは、デフォルトですべての従業員にアクセスを開放するのではなく、明確なデータ所有権、命名規則、意図的なアクセスを保証する舗装されたパスを可能にするインフラストラクチャを構築しました。
そのような例の 1 つは、事前に選択したカタログ整理戦略です。
| カタログ | 目的 | ガバナンス |
|---|---|---|
| ユーザー | 個々のユーザースペース(スキーマ) |
|
| チーム | 一緒に働くユーザーのためのコラボレーションスペース |
|
| 統合 | チーム間の特定の統合プロジェクトのためのスペース |
|
| メイン | 本番運用環境 |
|
課題
以前に明らかになったように、HMS にはリネージとアクセス制御がないため、社内のデータレイクは時間の経過とともにさらに「データ スワンプ」のようになっていました。 移行に不可欠な 3 つの基本的な質問に対する答えはありませんでした。
- テーブル "foo" の所有者は誰ですか?
- "foo" の上流にあるすべてのテーブルは、すでに新しい場所に移行されていますか?
- 更新する必要があるテーブル "foo" の下流の顧客は誰ですか?
以下のような規模のデータレイクで可視性が欠如していることを想像してください。
さて、4 人のエンジニアリング チームが、専任のプログラム管理サポートなしで 10 か月でこれをやり遂げると想像してください。
モダンアナリティクスへのコンパクトガイド

アプローチ
移行は、実際には 4 つのフェーズに分けることができます。
フェーズ1: HMS のリネージをアンロックして計画を立てる
私たちは Unity Catalog および Discovery チームと協力して、社内の Databricksワークスペース上に HMS 用のリネージ パイプラインのデータを構築しました。これにより、次のことを確認できました。
A. 誰がいつテーブルを更新したか
B. 誰がいつテーブルから読み取ったか
C. データはダッシュボード、クエリ、ジョブ、ノートブックのどれを介して消費されたか
A により、テーブルの所有者である可能性が最も高い人物を推測することが��できました。 B と C は、差し迫った移行の「影響範囲」、つまり、通知するすべてのダウンストリーム消費者は誰で、どれがミッションクリティカルかを確立するのに役立ちました。 さらに、B により、データレイク内にどれだけの「古い」データが残っていて、それを単に無視して(最終的には削除して)移行を簡素化できるかを推定できるようになりました。
この可観測性は、全体的な移行作業を見積もり、会社にとって現実的なタイムラインを作成し、チームが投資する必要のあるツール、自動化、ガバナンス ポリシーを通知する上で非常に重要でした。
社内でこの有用性が実証された後、顧客の Unity Catalog 移行を支援するために、一定期間 HMS リネージを有効にするパスを顧客に提供しています。有効にするには、アカウント担当者にお問い合わせください。
フェーズ 2: データ保持を強制して流出を止める
リネージの可観測性により、2 つの重要な知見が明らかになりました。
- データレイクには、しばらく使用されていない「古い」テーブルが大量に存在し、移行する価値がない可能性があります。
- HMS 上の新規テーブル作成率はかなり高かったです。 最終的に Unity Catalog への切り替えを成功させ、移行を成功させるには、これを大幅に (ほぼ 0 まで) 削減する必要がありました。
これらの知見により、私たちはデータ保持インフラストラクチャに先行投資し、次のポリシーを展開することになり、私たちの取り組みがさらに強化されました。
- 古いデータのガベージコレクション:このポ��リシーは、リリース直後から、30 日間更新されなかった HMS テーブルをすべて削除しました。 私たちはチームに免除を登録するための猶予期間を与えました。 これにより、「干し草の山」のサイズが大幅に縮小され、データ担当者は実際に重要なデータに集中できるようになりました。
- HMS に新しいテーブルを作成できない:移行が進行中で会社全体に認識が広まってから 1 四半期後、新しい HMS テーブルの作成を防止するポリシーを導入しました。 この措置により、レガシー メタストアを抑制しながら、新しいテーブルを作成するためにデータ パイプラインを拡張または変更できなくなったため、 HMS 上のデータ パイプラインは実質的に停止されました。
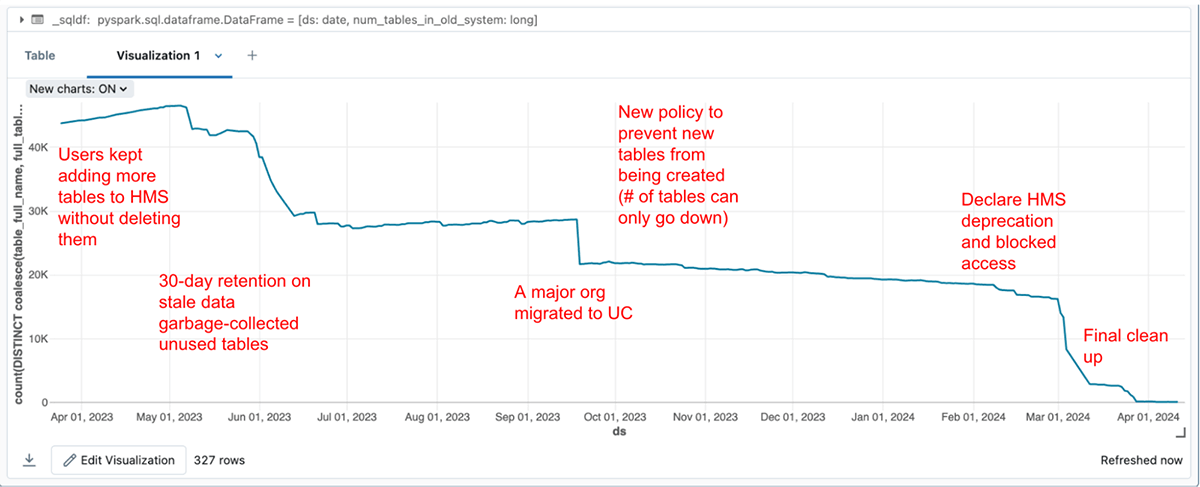
これらが整ったことで、私たちはもはや動くターゲットを追いかける必要がなくなりました。
フェーズ 3: セルフサービス追跡ツールを使用して作業を配布する
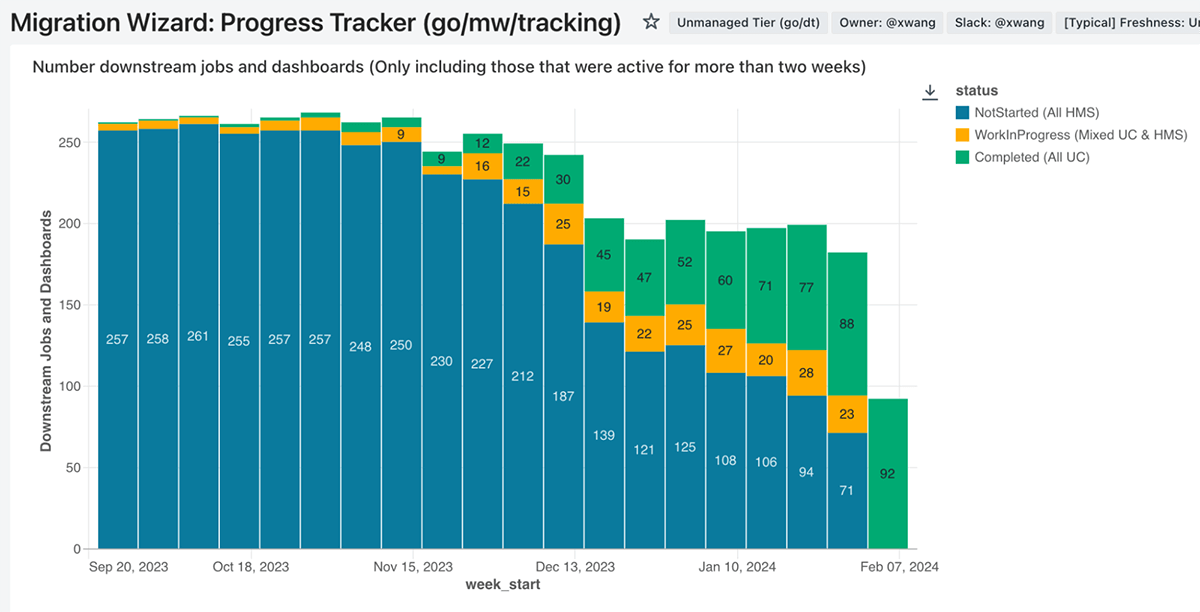
社内のほとんどの組織では、計画のリズム、実行を追跡するためのプロセス、優先順位や制約が異なります。 小規模なデータ プラットフォーム チームとして、私たちの目標は、調整を最小限に抑え、チームが独自のデータセット移行作業を自�信を持って見積もり、調整し、追跡できるようにすることでした。 この目的を達成するために、私たちはリネージの可観測性データをエグゼクティブレベルのダッシュボードに変換し、各チームがデータの作成者と消費者の両方として、重要度順に並べられた未解決の作業を把握できるようにしました。 これにより、マネージャーレベルと個々のコントリビューターレベルにさらにドリルダウンすることができました。 これらは、進行状況を追跡する目的で毎日更新されました。
さらに、データはリーダーボードに集約されたため、リーダーシップは可視性を持ち、必要に応じてプレッシャーをかけることができました。 グローバル トラッキング ダッシュボードは、Unity Catalog に移行された新しいテーブルの場所を消費者が見つけることができる参照テーブルという 2 つの目的も果たしました。
Databricks 組織の人材とプロセスのダイナミクスの管理に重点を置いたことが、成功の重要な原動力でした。 組織はそれぞれ異なり、会社に合わせてアプローチを調整することが成功の鍵です。
フェーズ4: 自動化を使用してロングテールに取り組む
ロングテールを効果的に管理することは、会社のすべてのチーム全体で 2.5K のデータ消費者と 50K を超える消費エンティティによる移行の成否を分けます。 データプロデューサーや小規模なプラットフォームチームに頼って、これらすべての消費者を追跡し、期限までに自分の役割を果たすことは不可能でした。
私たちは、「移行ウィザード」という名前で、データ プロデューサーがテーブルを削除したり、 Unity Catalog のカタログに移行したりできるデータ プラットフォームを構築しました。 プロデューサーは、テーブルパス (新旧) とともに、レガシーテーブルのサポート終了 (EOL) 日や、質問や懸念事項の連絡方法などの運用メタデータを提供しました。
移行ウィザードは、次の操作を行います。
- リネージを活用して消費を検出し、下流のチームに通知します。 この的を絞ったアプローチにより、チームはデータ廃止メッセージを全員に繰り返し送信する必要がなくなりました
- EOL の日に、アクセス権の削除による「論理的な削除」を行い、1 週間後にデータを消去します
- 新しい場所から読み取るレガシ データに応じた DBSQL クエリの自動更新
したがって、数行の設定で、データプロデューサーは、ダウンストリームの影響を心配することなく、効果的かつ自信を持って移行作業から切り離されました。 自動化は顧客への通知を継続し、廃止トリガーが引かれた後に発見されたクエリの破損に対しても迅速な修正を提供しました。
その後、DBSQL およびノートブック クエリを従来のHMSテーブルから新しい UC 代替テーブルに自動更新する機能が製品に追加され、お客様のUnity Catalogへの移行を支援しました。
着地を成功させる
2024 年 2 月に、 Hive Metastore へのアクセスを削除し、残っているすべてのレガシー データの削除を開始しました。 コミュニケーションと調整の量を考えると、この潜在的に破壊的な変化はスムーズであることが判明しました。 この変更によるインシデントは発生せず、すぐに 「成功」 を宣言することができました。
変更により失敗した所有されていないジョブをオフにできるようになったため、コスト面でのメリットがすぐに現れました。 暗黙的に非推奨となったダッシュボードは、限界的なコンピュートコストが発生しながらも機能しなくなり、同様に廃止される可能性があります。
重要な目標は、Databricks の顧客が Unity Catalog に移行しやすくするための機能を特定することでした。 Unity Catalog およびその他の製品開発チームは、製品の改善に役立つ広範な実用的なフィードバック��を収集しました。 データ プラットフォーム チームは、まもなく顧客に展開されるさまざまな機能のプロトタイプを作成し、提案し、設計しました。
旅は続く
Unity Catalog への移行により、データ担当者の負担が軽減され、データの拡散が大幅に軽減され、新しい機能が利用できるようになりました。 たとえば、マーケティング アナリティクス チームは、廃止されたデータセットのリネージ対応の識別 (および削除) によって管理されるテーブルが 10 分の 1 に削減されたことを確認しました。 一方、アクセス管理の改善とリネージにより、強力なワンクリックアクセス取得パスとアクセス削減の自動化が可能になりました。
詳細については、Data + AI Summit 2024 での統合ガバナンスに関する講演をご覧ください。 このシリーズの今後のブログでは、ガバナンスの決定についてもさらに詳しく説明します。 データガバナンスへの旅の詳細をお楽しみに!
Vinod Marur 氏、Sam Shah 氏、Bruce Wong 氏のリーダーシップとサポート、そして製品エンジニアリング @ Databricks 、特にUnity Catalog とデータブライトンのこの取り組みにおける継続的なパートナーシップに感謝します。