IoT向けの分散ML

イントロダクション
今日、メーカーの現場でのメンテナンスは、事前対応型よりも事後対応型であることが多く、コストのかかるダウンタイムや修理につながる可能性があります。 これまで、データウェアハウスは、履歴レポートに対して高性能で高度に構造化されたレンズを提供してきましたが、ユーザーには効果的な予測ソリューションが求められていました。 ただし、Databricks データ インテリジェンス プラットフォームを使用すると、企業はデータの同じコピーに対して履歴分析と予測分析の両方を実装できます。 製造業者は、予測メンテナンス ソリューションを活用して、潜在的な問題がビジネス上重要な顧客対応の問題になる前に特定し、対処することができます。 Databricks は、データ準備、モデル トレーニング、根本原因分析レポート用のツールを含む、エンドツーエンドの機械学習ソリューションを提供します。 このブログの目的は、統一されたスケーラブルなアプローチで IoT 異常検出の予測ソリューションを実装する方法を明らかにすることです。
問題提起
膨大な量のデータが関係することを考慮すると、既存のコードベースとスキルセットを拡張することは、IoT 予測メンテナンス ソリューションを開発する上で重要なテーマとなります。 明確な説明もなく、不良率が上昇する企業をよく見かけます。 データの小さなサブセットに対して Pandas を使用してデータ操作や分析を行うスキルを持つデータサイエンティストのチームがすでに存在する場合もありますが (たとえば、特に注目すべき移動を 1 つずつ分析するなど)、これらのチームは Databricks を使用して既存のコードを大規模な データセット全体に簡単に適用できます。以下の例では、データ サイエンティストがソリューションの開発と保守のためにまったく新しいツールとテクノロジーのセットを学習する必要なく、簡単に配布できる方法で Pandas コードをデプロイする方法を紹介します。さらに、 ML の実験はサイロ化された状態で実行されることが多く、データ サイエンティストが自分のマシンでデータの異なるコピーに対してローカルかつ手動で作業します。 これにより、再現性とコラボレーションが欠如し、組織全体で ML の取り組みを実行することが困難になる可能性があります。 Databricks は、統合された機械学習モデルの実験、レジストリ、およびデプロイメントのためのオープンソース ツールである MLflow を有効にすることで、この課題に対処します。 MLflow を使用すると、データ サイエンティストが実験を簡単に追跡して再現できるだけでなく、モデルを本番運用に展開することもできます。
例 1: Databricks で既存の異常検出コードを実行する
Databricks を IoT 異常検出に使用する方法を説明するために、一連のエンジンからのセンサー データのデータセットを考えてみましょう。 データセットには、温度、圧力、オイル密度などのセンサーの読み取り値と、各データポイントが欠陥を示しているかどうかを示すラベルが含まれます。 この例では、データのサブセットで実行される既存のコードを使用します。 私たちの目標は、既存の単一ノード コードを移行し、最終的には Spark クラスター全体で並列実行することです。 コードを拡張する前であっても、探索的分析のためのノートブック内ダッシュボードや、コードの作成とトラブルシューティングのためのDatabricks Assistantなどのツールを有効にする共同インターフェイスのメリットが得られます。
この例では、組織の統合データレイクからテーブルを読み取るための簡単な追加を 1 つだけ加えてPandasコードをDatabricksダッシュボードにコピーし、データを探索するためのポイント アンド クリック インターフェイスをすぐに取得します。
例2: 本番運用のMLOps
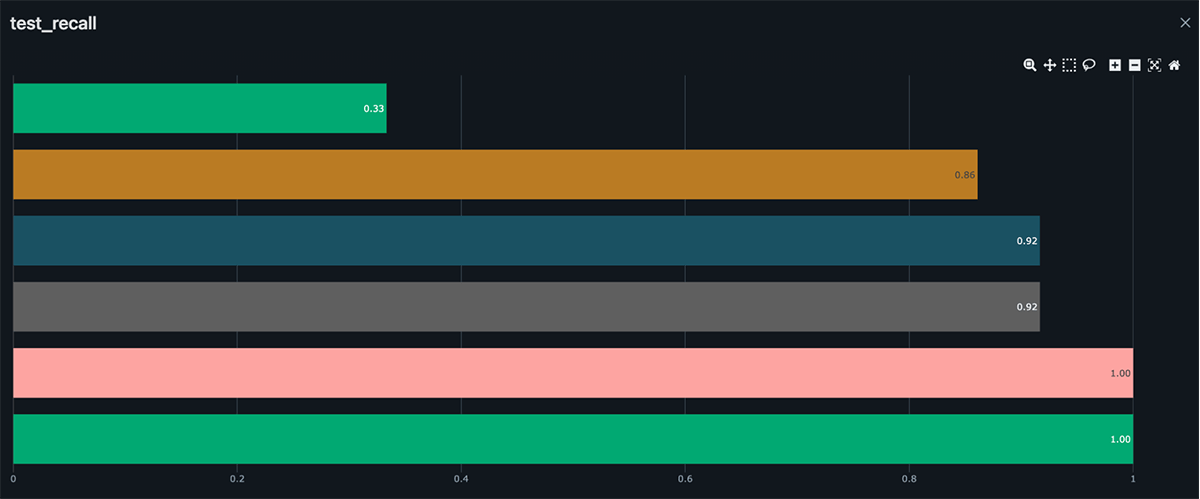
次に、 DatabricksとMLflowを使用して、実験を簡単に追跡および再現し、時間の��経過とともにモデルを反復して改善できるようにします。 私たちの目標は、異なるチーム、役割、システム間でデータやモデルを複製することなく、センサーの読み取り値に基づいて特定のデータポイントが欠陥であるかどうかを正確に予測できる機械学習モデルを構築することです。 シンプルな autolog() 関数を追加することで、モデル成果物、ライブラリ依存関係、モデル パラメーター、パフォーマンス メトリックなど、 ML問題を解決するための各試行に関する情報を自動的に追跡できます。 これらのモデルを使用すると、バッチ パイプラインまたはリアルタイム パイプラインでエンジンの欠陥が大きな問題になる前に特定して対処することができます。
例3: Spark上でPandasを配布する
既存のコードを Databricks に移植し、ML モデルの追跡、再現性、運用性を強化したので、データセット全体に拡張したいと考えています。 分散コンピューティングではApache Sparkのパフォーマンスに勝るものはありませんが、 データ サイエンティストが別のフレームワークを学習�したり、すでに開発したコードを変更したりしたくないことがよくあります。 幸いなことに、Spark は、Pandas ワークロードを水平方向にスケーリングしてデータセット全体で実行するためのさまざまなアプローチを提供しています。 以下では、3つの異なるオプションについて説明します。
a. PySpark Pandas
この例では、PySpark Pandas を使用して例 1 の機能を構築するために同じコードを使用しますが、今回は Spark クラスター上の多数のノード間で並列に実行されます。 この並列化を使用すると、コードでロジックを書き直すことなく、大規模なデータセットを効率的に拡張できます。 このコードは、 Pandasインポート ステートメントと、 DataFrameを定義するために toPandas() ではなく pandas_api() を使用している点を除けば、例 1 と同一であることに注意してください。
b. Pandas UDF
PySpark Pandas は、Pandas のすべてのユースケースをカバーしているわけではありません。場合によっては、操作をより細かく制御したり、PySpark 実装のないライブラリを使用したりする必要があることもあります。 このような場合には Pandas UDF を使用できます。 Pandas UDF を使用すると、使い慣れたオブジェクト (この場合は Pandas Series) を受け入れ、ローカルで行うのと同じように操作する関数を作成できます。 ただし、実行時には、このコードは Spark クラスター全体で並列に実行されます。 必要な唯一のコード変更は、関数を @pandas_udf で装飾することです。 この例では、ARIMA モデルを使用して温度予測を並行して行い、データセットに予測値の高い機能を追加します。
c. applyInPandas
Pandas コードを並列化するアプローチの最後を飾るのは、applyInPandas です。 例 3b の Pandas UDF アプローチと同様に、applyInPandas を使用すると、使い慣れたオブジェクト (Pandas DataFrame 全体) を受け入れ、コードの実行を Spark クラスター全体に分散する関数を記述できます。 ただし、このアプローチでは、いくつかのキーでグループ化することから始めます (以下の例では device_id)。 グループ化キーによって、どのデータが一緒に処理されるかが決まります。たとえば、device_id が 1 であるすべてのデータは 1 つの Pandas DataFrame にグループ化され、device_id が 2 であるデータは別の Pandas DataFrame にグループ化される、などです。 これにより、以前は一度に 1 つのデバイスで実行されていたコードをクラスター全体にスケールアウトできるようになり、大規模なデータ処理が大幅に高速化されます。 また、Spark がPyArrowを活用して結果を効率的にシリアル化できるように、applyInPandas 関数の予想される出力スキーマも提供します。 この簡単な例では、各デバイスの燃料密度について指数関数的に加重された移動平均を取り、null値を前方に埋めます。
まとめ
結論として、IoT 予測メンテナンスに Databricks を使用すると、ML ワークロードを簡単に拡張したり、チーム間で共同作業を行ったり、モデルを本番運用にデプロイしたりする機能など、多くの利点が得られます。Databricksを使用することで、データ サイエンティストは、まったく新しい一連のテ��クノロジーを学習することなく、既存のPandasスキルとコードを適用して大規模なIoTデータを処理できます。 これにより、IoT 異常検出モデルを迅速に構築して展開できるようになり、エンジンの欠陥が大きな問題になる前に特定して対処できるようになります。 つまり、 Databricks は、データ サイエンティストが既存のPandasスキルを大規模なIoTデータに適用するための強力で柔軟なプラットフォームを提供します。 データと ワークロードの拡張を検討しているデータサイエンティストまたはデータサイエンスのリーダーであれば、AI MLIoTソリューション アクセラレータ向け分散 を試して、予測メンテナンス イニシアチブの有効性を高めてください。
このソリューション アクセラレータへのリンクはこちらです。
