Spark JDBCを使用してリアルタイムのSAP HANAデータをDatabricksにフェデレートする最速の方法

翻訳:Junichi Maruyama. - Original Blog Link
SAPが最近発表したDatabricksとの戦略的パートナーシップは、SAPの顧客の間で大きな興奮を呼んでいる。データとAIのエキスパートであるDatabricksは、SAP HANAとDatabricksを統合することで、アナリティクスとML/AI機能を活用するための魅力的な機会を提供します。このコラボレーションの大きな関心を受け、私たちはディープダイブ・ブログ・シリーズに着手することになりました。
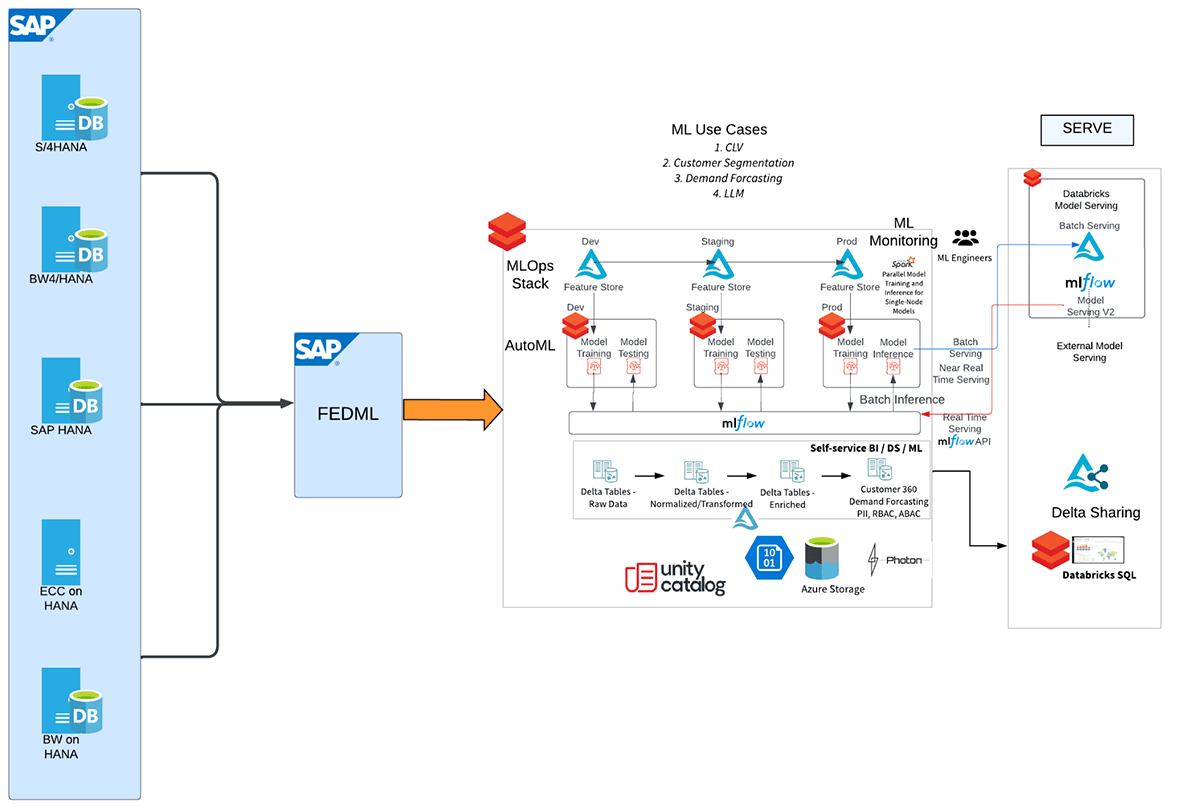
多くのお客様のシナリオでは、SAP HANAシステムは、SAP CRM、SAP ERP/ECC、SAP BWなど、さまざまなソースシステムからのデータ基盤の主要なエンティティとして機能しています。そして今、この堅牢なSAP HANA分析サイドカーシステムをDatabricksとシームレスに統合し、組織のデータ機能をさらに強化するエキサイティングな可能性が生まれました。SAP HANA(HANA Enterprise Editionライセンス)とDatabricksを接続することで、企業はSAP HANAに保存されている豊富で統合されたデータを活用しながら、Databricksの高度なアナリティクスと機械学習機能(MLflow、AutoML、MLOpsなど)を活用することができます。この統合により、企業は貴重な洞察を引き出し、SAPシステム全体でデータ主導の意思決定を推進する可能性が広がります。
Databricks で SAP HANA テーブル、SQL ビュー、および計算ビューを連携させるには、複数のアプローチを利用できます。しかし、最も手っ取り早い方法はSparkJDBCを使用することです。最も大きな利点は、SparkJDBCがSparkワーカーノードからリモートHANAエンドポイントへの並列JDBC接続をサポートしていることです。
SAP HANAとDatabricksの統合から始めよう。
このDatabricksとの統合をテストするために、SAP HANA 2.0がAzureクラウドにインストールされた。
Installed SAP HANA info in Azure:
| version | 2.00.061.00.1644229038 |
| branch | fa/hana2sp06 |
| Operating System | SUSE Linux Enterprise Server 15 SP1 |
以下は、この統合のさまざまなステップを示すハイレベルなワークフローです。
SparkJDBC を使用して SAP HANA の計算ビューとテーブルから Databricks にデータを抽出する詳細な手順については、添付のノートブックを参照してください。

以下の画像に示すように、SAP HANA JDBC jar(ngdbc.jar)を設定します。
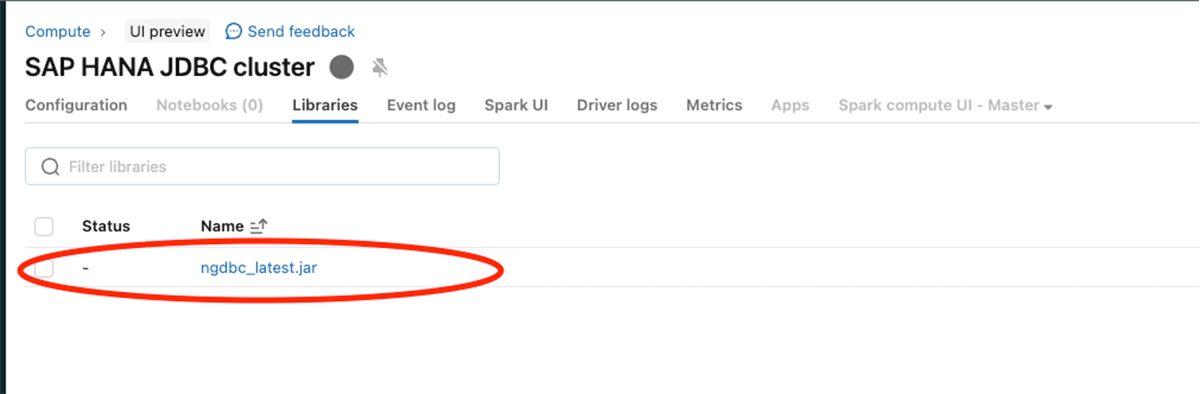
上記の手順を実行したら、SAP HANAサーバーとJDBCポートを使用してスパークリードを実行します。
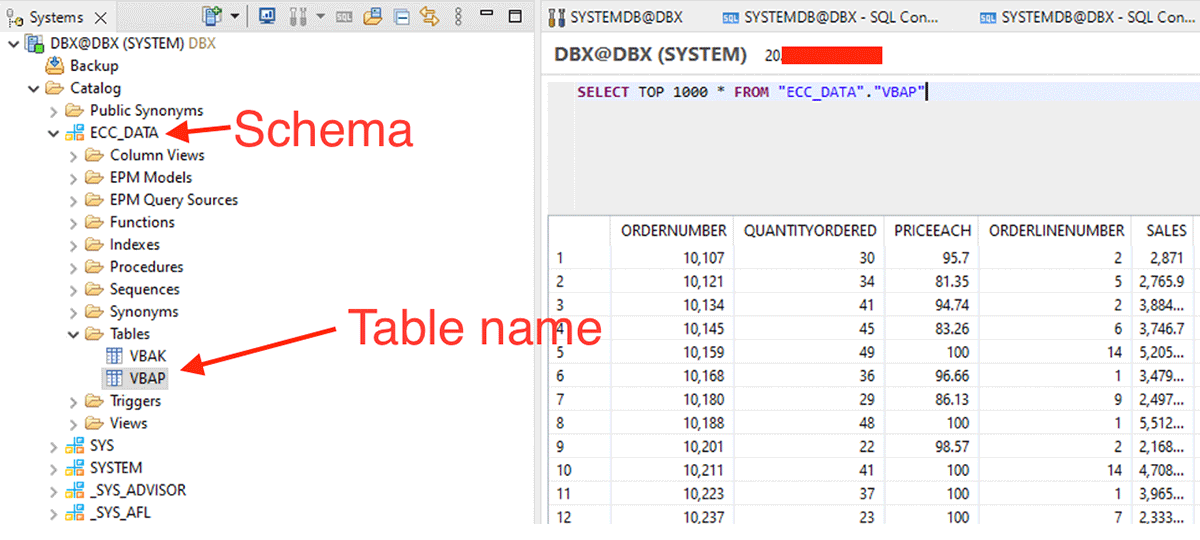
スキーマ、テーブル名を指定し、データフレームの作成を開始する。
また、dbtableオプションにSQL文を渡すことで、フィルタのプッシュダウンを行うこともできる。
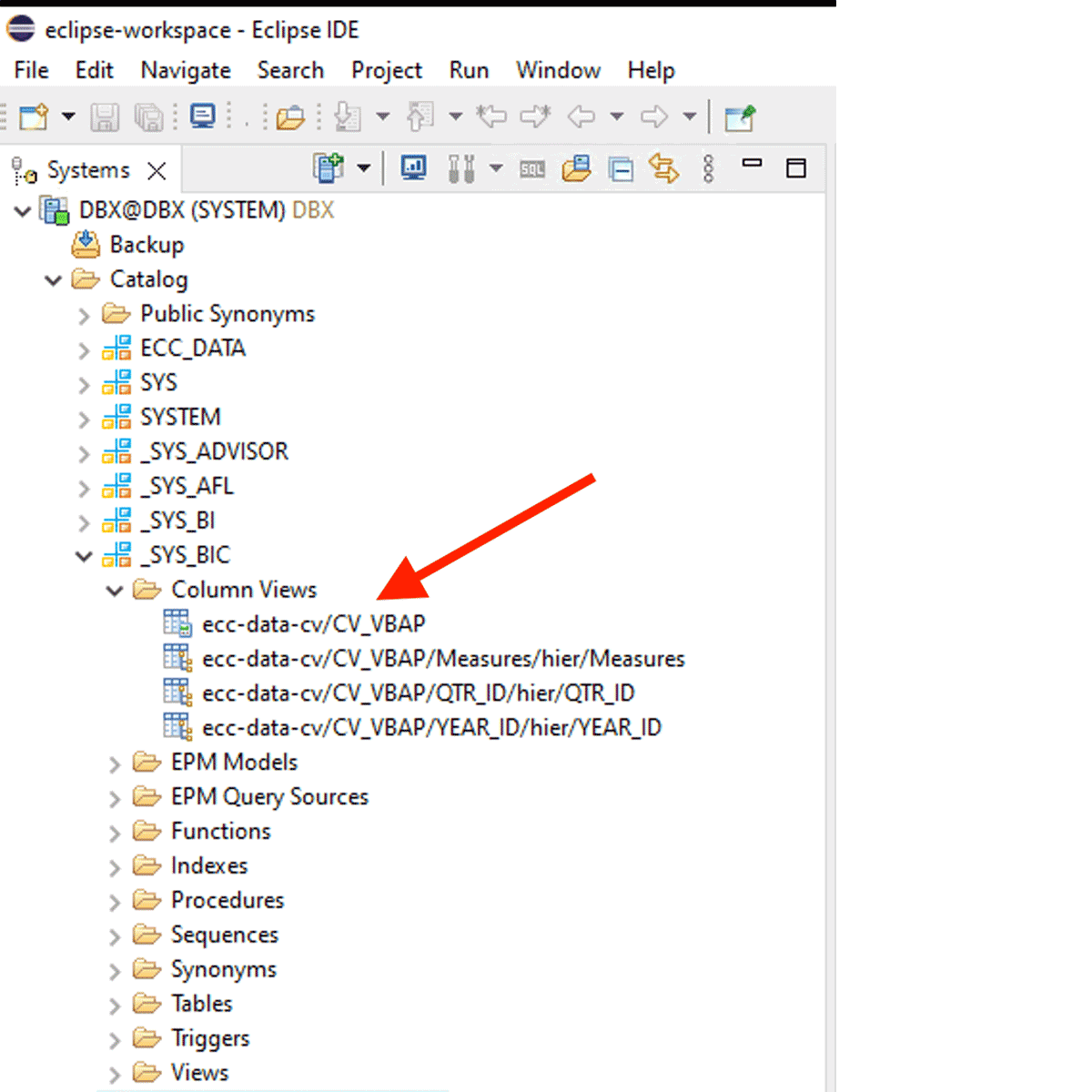
計算ビューからデータを取得するには、次のようにします:
例えば、このXS-classic計算ビューは内部スキーマ"_SYS_BIC "で作成されています。
このコードスニペットは、"df_sap_ecc_hana_cv_vbap "という名前のPySparkデータフレームを作成し、SAP HANAシステムの計算ビュー(この場合はCV_VBAP)からそのデータフレームに入力します。
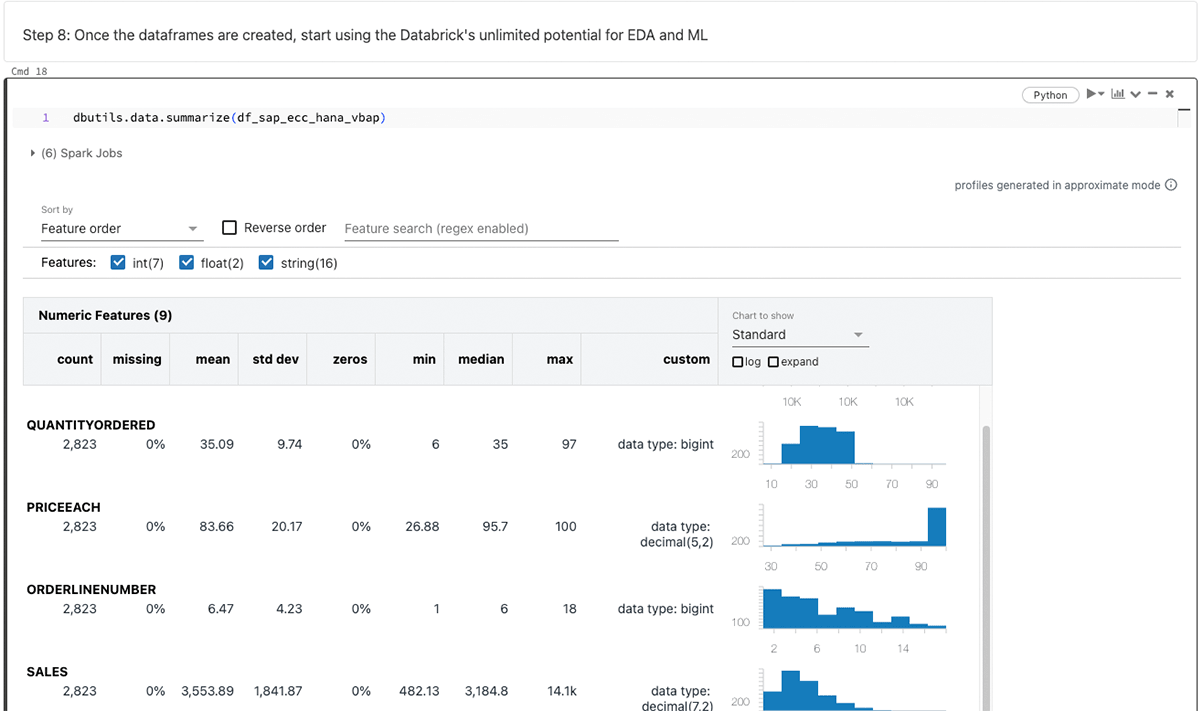
PySparkデータフレームを生成した後、探索的データ分析(EDA)と機械学習/人工知能(ML/AI)のためにDatabricksの無限の機能を活用する。
上記のデータフレームをまとめると
このブログでは、SAP HANA用のSparkJDBCに焦点を当てていますが、FedML、hdbcli、hana_mlなどの代替メソッドも同様の目的で利用可能であることは注目に値します。


{kind=link}
{kind=link}
{kind=link}
{kind=link}