キャピタルマーケットのための生成AI戦略

公開日: 2024年7月29日
によって ジョー・マラシエロ、アントワーヌ・アメンド(Antoine Amend)、Marzi Rasooli 、 エミリア・ヴォリネツ による投稿
財務評価と比較分析
ヘッジファンド、マーケットメーカー、年金基金などのキャピタルマーケットに特化した金融機関は、これまでも最新の分析手法や新しいオルタナティブデータの導入に積極的でした。この競争の激しい業界では、成功者はより広範なデータを迅速に要約し、それに基づいて行動することで「アルファ」を獲得しています。
生成AI(Gen AI)の成熟は、金融サービス業界全体で注目されており、買い手側と売り手側の間に長く存在していたデータの格差は急速に縮まっています。リーダーたちは、大規模な言語モデル(LLM)やAI技術が、金融アナリストチームを強化するために大きな価値をもたらすことを認識しています。多くの企業が、データサイエンス部門から生まれた概念実証や限定的なパイロットプロジェクトに、すでに意欲的に投資を行っています。今日、「アルファ」を獲得するための戦いは、早期に正しい情報を手に入れるだけでなく、技術的なパイロットをいち早くビジネスユーザーが信頼して活用できる企業向けアプリケーションに変換する能力にも依存しています。
さらなる投資の準備が整った��リーディング金融機関は、金融アナリスト向けに特別に設計されたインタラクティブなビジュアル体験を通じて、これらのモデルを運用化することに取り組んでいます。先進的な金融機関は、これらの新しいツールを既存の分析プラットフォーム投資やガバナンス基準と整合させることを目指しています。また、ベンダーロックインを避け、オープンソースコミュニティによって継続的に開発・リリースされる最新の優れた機能やAI標準を柔軟に導入できるように、この能力をコスト効果の高い方法で提供したいと考えています。
財務評価に信頼できる生産品質のGenAIを構築するか購入するかを選択する際に考慮すべき主なポイントは、以下の3つです。
- データ収集
- RAGワークフロー
- デプロイメント、モニタリング、およびユーザーインターフェース
データ収集
「アルファ」を求める人々にとって、包括的で、クリーンで、発見可能かつ信頼できるデータは不可欠な出発点です。Lakehouseプラットフォームはこれを実現する基盤を提供し、急速に進化する生成AIの分野に適応するために必要な柔軟性とコントロールを提供します。
キャピタルマーケットのチームは、さまざまな市場調査や分析ソフトウェアのポイントソリューションを頻繁に利用・管理しています。これらのツールは金融アナリストにとって非常に貴重ですが、ITデータチームの同僚が管理する広範なデータセットからは切り離されているように感じられることがあります。この状況は、重複したパラレルストレージや、組織の主要なクラウド環境外での分析システムや活動を引き起こす可能性があります。
これらのアプリケーションを構築するためにはデータ主導のアプローチが重要ですが、組織全体と整合しないソリューションは、生成AIソリューションがパイロットフェーズで停滞する原因となります。ある大規模な年金基金は、インフラとデータをパラレルクラウドに複製する必要があったため、ポイントソリューションを拒否しました。理想的には、オープンなストレージフォーマットで構築された中央集約型リポジトリが、生成AIモデルに最も幅広い入力ドキュメントを提供します。すでに活用できるパブリック、所有、または購入された膨大なドキュメントやデータがあるかもしれませんが、高価なデータの重複や冗長なプロセスを避けることが重要です。
ドキュメントの範囲が広がるほど、モデルが明らかにできるインサイトのカバレッジと量が増えます。
生成AIの財務評価ソリューションに提供することを検討すべきドキュメントには、以下のようなものがあります:
- 10-Kやその他の公開レポート
- 株式およびアナリストレポート
- アナリストのビデオトランスクリプト
- その他の有料市場インテリジェンスレポート
- プライベートエクイティ分析
これらのドキュメントを分析プラットフォームに取り込むためには、メダリオンアーキテクチャパターンが推奨されます。データエンジニアは、最も一般的なタイプのドキュメントやデータのために自動化されたパイプラインを構築できます。アドホックなドキュメントの取り込みには、以下に示すように金融アナリストが直接使用できるグラフィカルユーザーインターフェースを提供することを検討してください。
RAGワークフロー
RAG(Retrieval-Augmented Generation)ワークフローまたはチェーンは、任意のGen AIベースのソリューションのバックエンドの中心に位置しています。これらのワークフローには、あなた自身のプライベートデータと組織の標準を選択したLLM(s)に結びつける指示が含まれています。RAGアーキテクチャパターンは、訓練中にLLMに提供された情報に頼るのではなく、独自のプロプライエタリデータを任意の形式で事前訓練済みのLLMにクエリを行うことを意味します。このアプローチは、あなたのデータのセマンティクスを理解する“データインテリジェンスプラットフォーム”戦略と一致しています。
ソフトウェア開発者にとって、RAGパターンはAPIを使用してコーディングすることにある程度類似しています - 他のソフトウェアへのサービスでリクエストを豊かにします。技術的に詳しくない方々には、RAGパターンを、あなたが非常に賢い友人にアドバイスを求め、自分の個人的なメモを装備させ、それを図書館に送るというものと想像してみてください。彼らが去る前に、あなたは彼らに「プロンプト」を与えて、彼らの反応の範囲を制限する一方で、彼らが最高の分析的推論を答えに提供する自由を与えます。
RAGワークフローは、この引き継ぎの指示を含んでおり、独自のデータソース、特別な計算、ガードレール、独自の企業コンテキストに合わせて調整することができます。なぜなら、競争優位性は常に独自のデータを使用することにありますから。
オープンアーキテクチャ。オープンモデル。
カスタマイズされたRAGワークフローにまだ投資する準備ができていないですか?オープンでカスタマイズ可能なアーキテクチャを基盤として整備することは、ソリューションを本番環境に移行する前に、組織内で信頼を築くために重要です。RAGワークフローに対する可視性とコントロールは、説明可能性と信頼性を高めるのに役立ちます。例えば、ある大手プライベートエクイティ投資家は、同じ入力を週ごとに使用しても同一の結果を再現できなかったため、市販の生成AIソリューションを拒否しました。これは、基礎となるモデルやRAGワークフローが変更されており、以前のバージョンに戻す方法がなかったからです。
商用の生成AIモデルは当初、多くの注目とメディアの関心を集めましたが、オープンソースの代替モデルも追いついており、進化し続けています。調整やカスタムRAGワークフローに加えて、オープンソースモデルは、パフォーマンスとコスト効果の評価において、商用代替品に対して強力な選択肢となっています。
柔軟で透明性の高いソリューションは、最新のオープンソースモデルを簡単に組み込むことができる汎用性を持っています。例えば、カスタマイズ可能なRAGワークフローで構築された生成AIアプ�リケーションは、DatabricksのオープンソースモデルであるDBRXモデルを即座に活用できました。このモデルは、既存のオープンソースおよび商用モデルを上回る性能を発揮しています。これは最近の一例に過ぎませんが、オープンソースコミュニティは四半期ごとに新しい強力なモデルを絶え間なくリリースし続けています。
価格&パフォーマンス
金融機関でのGen AIアプリケーションの採用が増えるにつれて、これらのソリューションのコストは時間とともにますます厳しく見直されることになるでしょう。商用のGen AIモデルを使用した概念実証は、初期のコストが許容範囲内で、限られた時間で数人のアナリストがソリューションを使用する場合があります。プライベートデータの量、応答時間SLA、クエリの複雑さ、リクエストの数が増えるにつれて、よりコスト効率の良い代替案の探求が必要となるでしょう。
ファイナンシャル分析を行うチームの真のコストは、ユーザーがそれらに対して求める要求に基づいて変動します。ある大手金融機関では、限定的なパイロットでは2分以上の応答時間を許容していましたが、全面的なプロダクション展開を考慮する際には、出力が1分以内に部分的に生成されるSLAを持つ計算能力を増強することを検討しました。最新のオープンソースモデルと基盤インフラストラクチャを選択できる柔軟なソリューションは、さまざまなタイプのユースケースに必要なコストパフォーマンスバランスを達成し、金融機関にとって不可欠なコスト効果的なスケールを提供します。
柔軟性
オープンソースのLLMsとOpenAIの選択は、あなたの特定のニーズ、リソース、制約によります。カスタマイズ、コスト効率、データプライバシーが優先事項であるなら、オープンソースのLLMがより良い選択かもしれません。高品質なテキスト生成が必要で、コストを負担する意志がある場合、商用のオファリングが適切な選択肢となるかもしれません。最も重要な要素は、すべてのオプションを提供し、技術の急速な変化に基づいてアーキテクチャを柔軟にするプラットフォームを選択することです。これがDatabricks Intelligence Platformのユニークな提供であり、以下に要約したように、カスタマイズと複雑さのレベルに関係なく完全なコントロールを提供します。
|
|
事前トレーニング |
統一ツールを使用してもしなくても(Mosaic AIなど)、LLMをゼロからトレーニング |
| ファインチューニング | 事前に訓練されたLLMを特定のデータセットやドメイン、例えば金融評価や比較分析に適応させる | |
| 検索拡張生成(RAG) | 公開およびプライベートの金融レポート、トランスクリプト、代替金融データなどのエンタープライズデータとLLMを組み合わせる | |
| プロンプトエンジニアリング | LLMの振る舞いを導くための特別なプロンプトを作成すること、これは静的なレポートであったり、金融アナリストのための視覚的な探索ツールの一部�として提示されることもあります |

エンタープライズ向けエージェントAIプレイブック

デプロイメント、モニタリング&ユーザーインターフェース
あなたの公開および非公開の金融文書が取り込まれ、エンタープライズのコンテキストでRAGワークフローが設定されると、モデルのデプロイメントオプションを探索し、モデルを金融アナリストに公開する準備が整います。
デプロイメントについては、Databricksはさまざまな現行機能とプレビュー機能を提供し、これにより初期デプロイメントの成功だけでなく、継続的に監視、管理、精度を確認し、時間とともにコスト効果的にスケールするための適切なツールを提供します。展開関連の主要な機能には次のようなものがあります:
- LLMサービングのためのプロビジョニングおよびオンデマンド最適化クラスタ
- モデルの精度と品質を確認するためのMLFlow LLM評価
- Databricksベクトル検索
- LLMを自動評価のための判断者として
- RAGワークフロー��最適化のためのRAG Studio(プレビュー)
- ホールシネーションや不正確さの自動スキャンとアラートのためのLakehouseモニタリング
これらの機能とツールを組み合わせることで、データサイエンティストは金融アナリストからのフィードバックにより容易に対応することができます。モデル品質の理解が深まることで、モデルの有用性、関連性、精度が時間とともに向上し、より迅速で影響力のある金融洞察をもたらします。
Gen AIを使って金融アナリストの働き方を変える
金融アナリストは、日々の業務の要求に合わせてGen AIモデルと対話する視覚的な方法を必要としています。評価と比較分析は調査と反復のプロセスであり、モデルとの対話方法が必要です。これにより、ペースを維持できます。金融アナリストとモデルとの間のインタラクティブな体験には、生成された金融サマリーの特定の段落を詳述するリクエストや、引用や参照を準備することが含まれます。
DatabricksのパートナーであるT1Aは、この目的のためにLimeを開発しました。Limeは、Databricksによって動力を得ており、この記事で概説されているGen AIの原則に沿った、金融アナリスト専用に設計されたユーザーインターフェースを提供します。下の例では、LLMが生成したレポートと、アナリストがポイントアンドクリックの経験を通じて段落を詳述する能力を見ることができます。
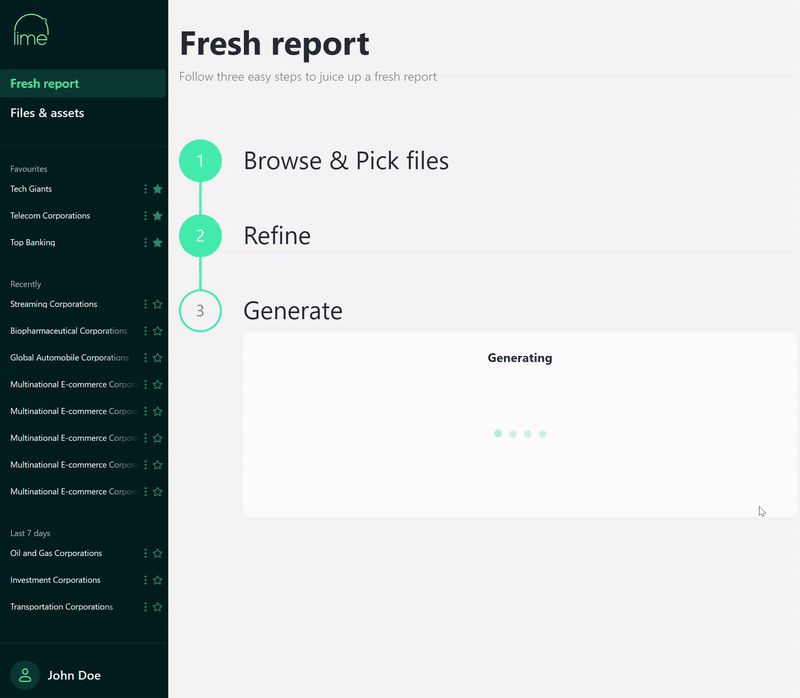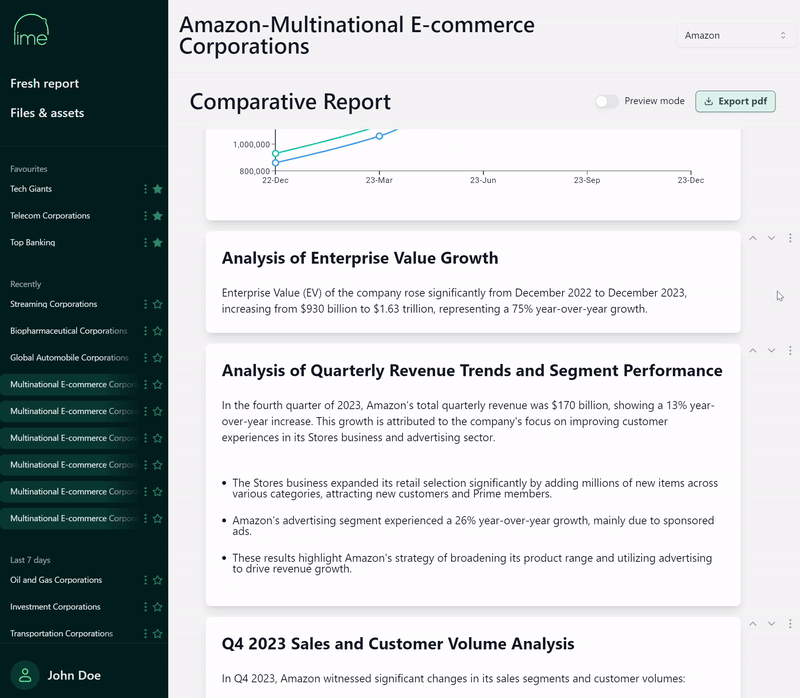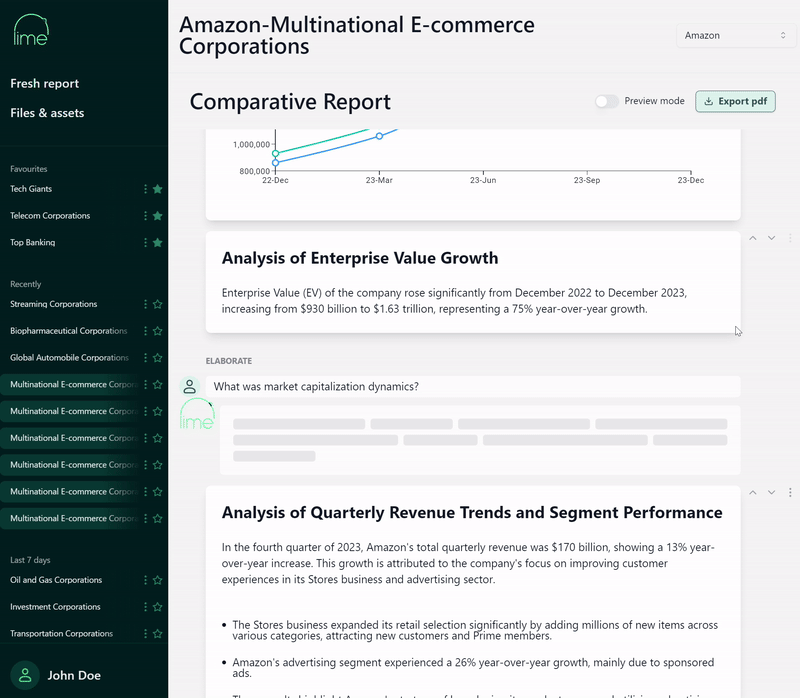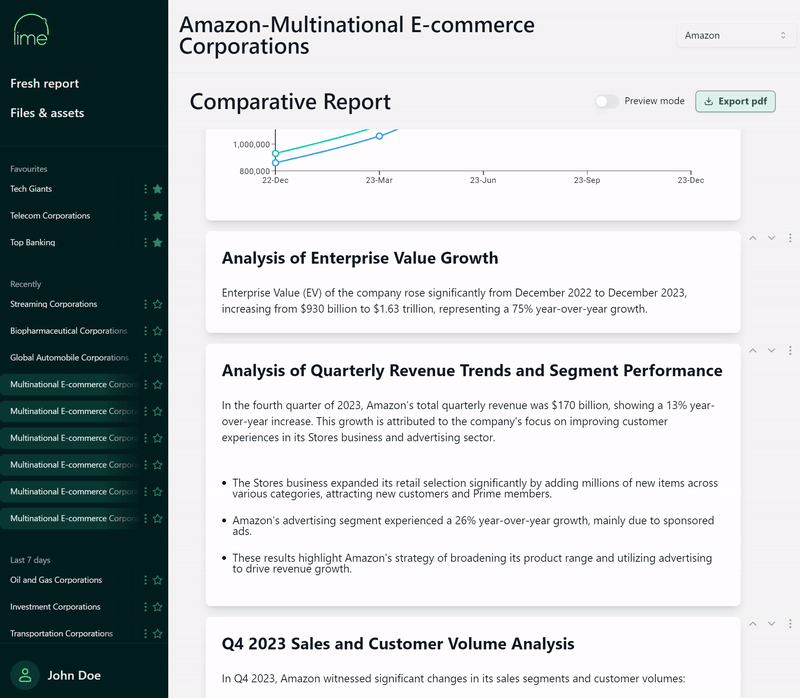
アナリストは、個々の株式のサマリーを作成することができるだけでなく、比較分析のための統合レポートも作成することができます。チャットやダイナミックレポートインターフェースを使用して、「なぜEBITDAが最近の期間に変動したのか?」や「次の12ヶ月で企業価値に影響を与える可能性のある要因は何か?」などのフォローアップの問い合わせを行うことができます。
インターフェースには、アナリストが作業中に段落、チャート、詳細な説明の品質について評価を提供する機会が含まれています。このループは追加の品質管理層を提供するだけでなく、貴重なフィードバックを提供し、これがRAGワークフローとモデルチューニングの変更につながる強化学習の一種を提供することができます。金融アナリストがソリューションを使用するほど、それはあなたの組織のユニークなコンテキストをより反映し、戦略的な利点が大きくなります。
まとめ
アルファを求める道は、適切なGen AIインフラストラクチャで舗装されています。それは、組織全体で共有され、金融文書の重複を避けるオープンストレージ基準を採用した取り込みフレームワークから始まります。成長と戦略的な差別化は、あなたの企業のコンテキストを理解し、理解可能で再現可能なRAGワークフローへの継続的な投資によって生じます。次に、最新のオープンソースモデルを活用したコスト効率的な方法でソリューションを展開し、品質と精度を継続的に監視することが求められます。最後に、金融アナリストによる継続的なエンゲージメントと採用を確保するためのユーザーインターフェースを追加します。
T1Aについて
T1Aは、エンタープライズがDatabricksの全能力を活用するのを支援し、Lime - Gen AI for Financial Valuationsの開発者であるテクノロジーコンサルティング会社です。T1Aは、GetAlchemist.ioを開発したSASからDatabricksへの移行専門家です。ビジュアルプロファイラーと自動コード変換ソリューション。
金融評価と比較分析のために特別に構築されたGen AIユーザーインターフェースを金融アナリストがどのように使用できるかを詳しく知りたい方は、ailime.ioをご覧ください。ビデオコンテンツを視聴するか、カスタムデモをリクエストして、Gen AIプロジェクトへの需要をどのように促進し、内部のビジネスパートナーとの協力を増やすかを確認してください。