ゲスト投稿: Laminiを使用してDatabricksのデータで独自のLLMをトレーニングする

Original : Guest Post: Using Lamini to train your own LLM on your Databricks data
翻訳:Junichi Maruyama
これは私たちのスタートアップパートナーである Lamini からのゲスト投稿です。
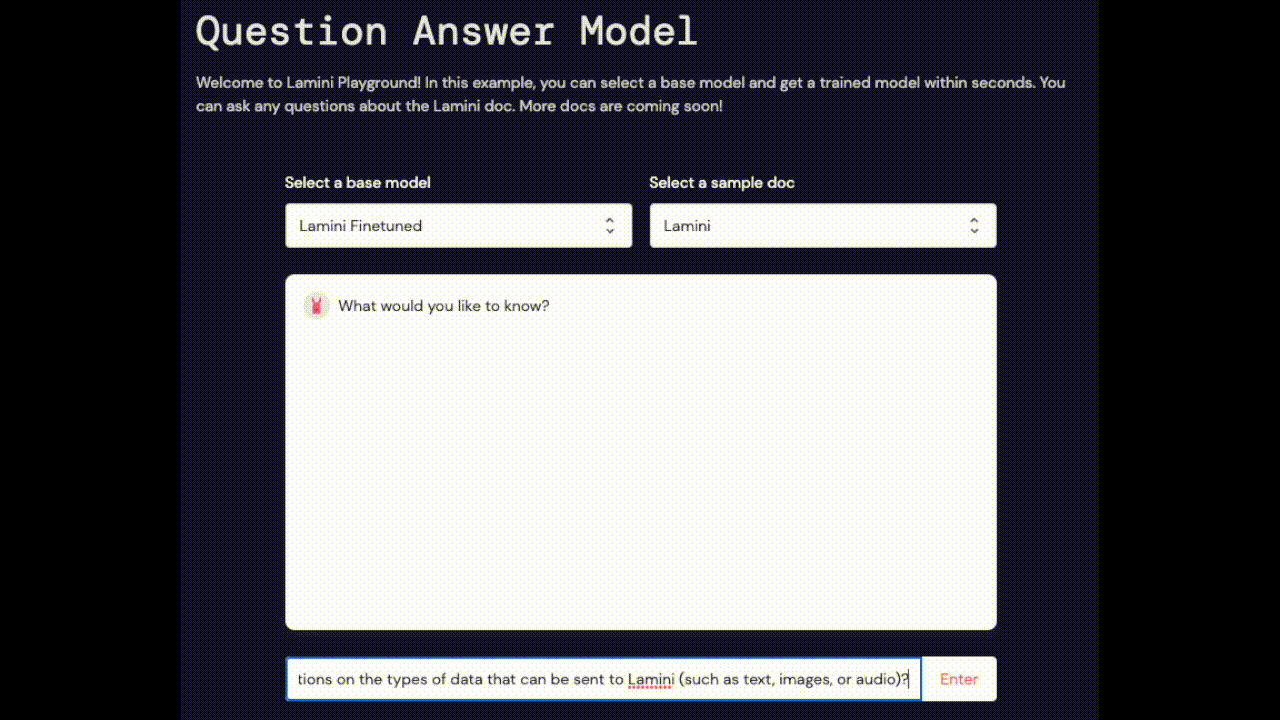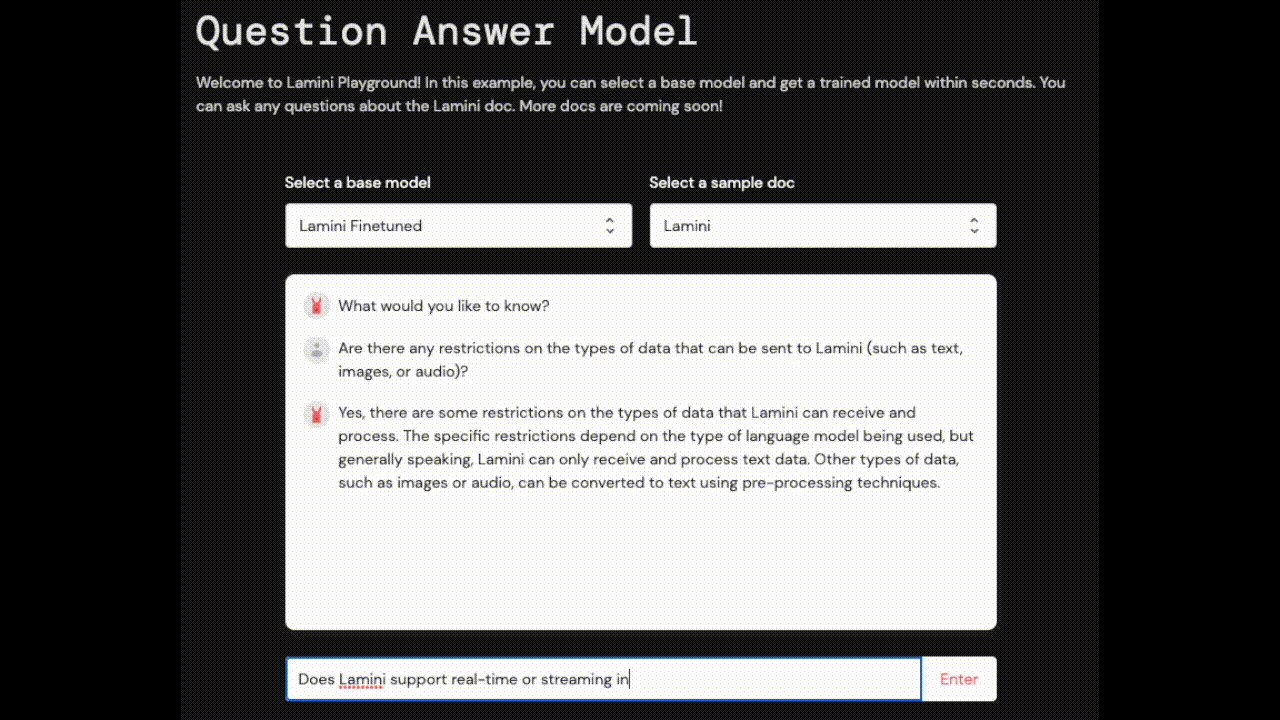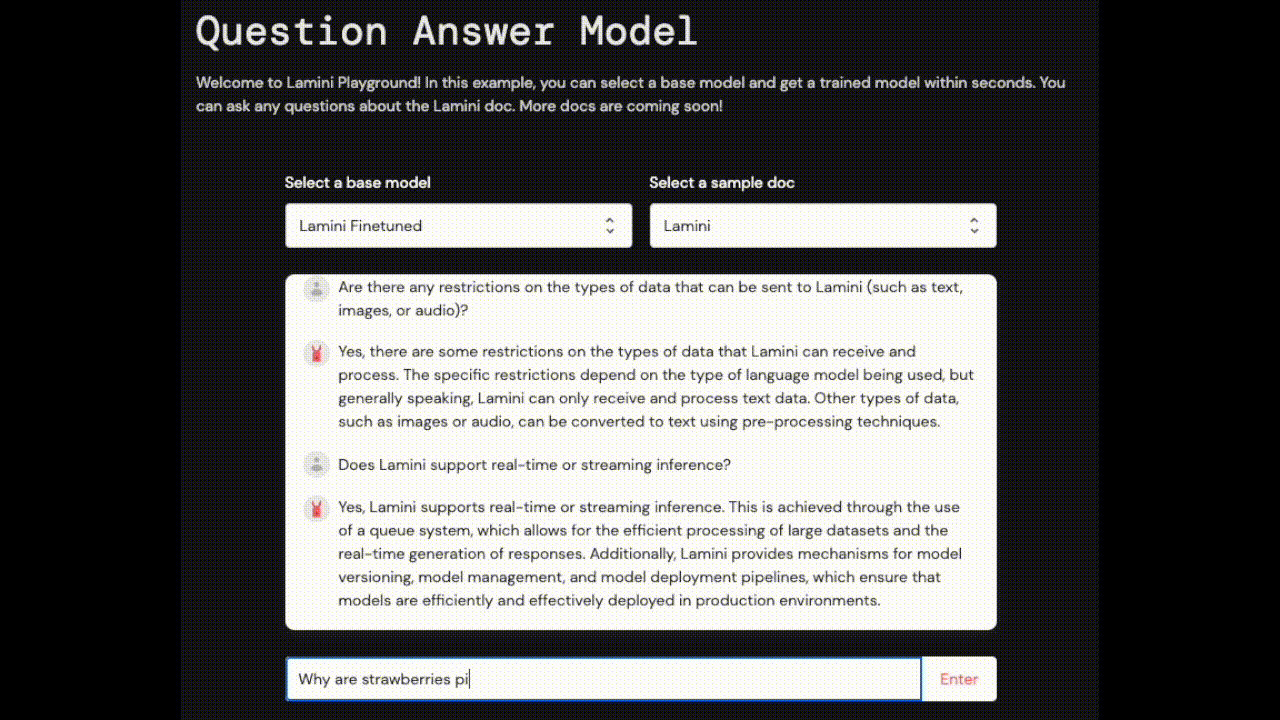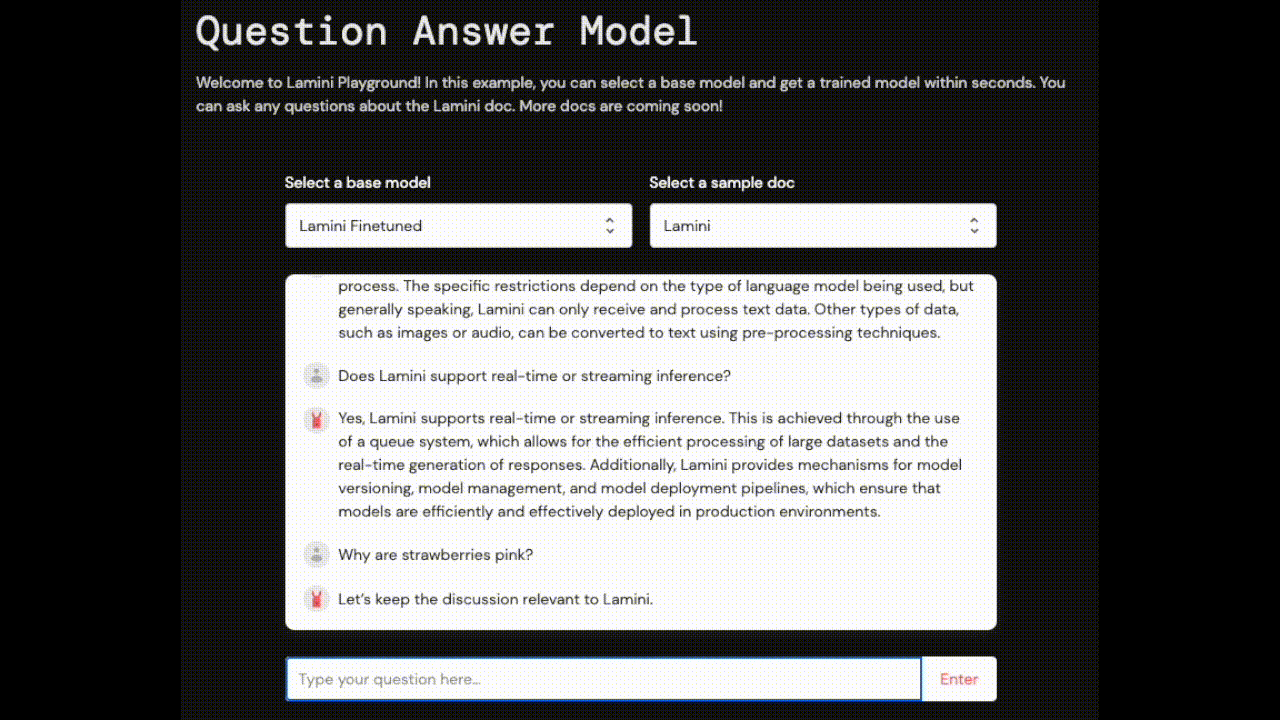
上の写真のLLMは、Laminiのドキュメントで訓練されたものです。遊んでみてください。 Live now!
S&P500の20%以上が今年(2023年)の第1四半期に決算説明会でAIを話題にしたのですから。LLMはあなたの製品に魔法をかけ、顧客を喜ばせ、トップラインを増加させることができます。顧客は、パーソナライズされた情報を含むあなたのすべてのドキュメントにアクセスし、数秒で自分の質問に答えることができます。また、副操縦士がいれば、あらゆる新機能の構築が10倍速くなり、エンジニアリングコストや運用コストを削減することができます。
しかし、GPT-4のような公開LLMは、ほとんど他人のデータで訓練されています。しかし、GPT-4のような公開LLMは、ほとんど他人のデータで訓練されたもので、確かに優れていますが、あなたのデータやユースケースに合わせたパーソナライズができません。もし、GPT-4があなたのビジネスに特化してチューニングされていたら、どんなに強力なものになるか想像してみてください!
さらに悪いことに、最も価値のあるデータを、独占的に渡すわけにはいきません。データ漏えいや顧客との約束に不安を感じている。IPやソースコードを第三者に渡してしまい、せっかく築いたデータ堀を放棄してしまうことに不安を感じている。AIサービスの信頼性やメンテナンスに不安があり、AIサービスは適応が早く、新しいバージョンで重要なユースケースが壊れてしまう。
Github がGithub Copilot で行ったように、あるいはOpenAIがChatGPTで行ったように、何十人ものトップAI研究者を雇ってプライベートLLMを構築してもらうという選択肢もあります。いずれのソリューションも、時間とコストがかかり、ROIも非常に低くなります。だから、あなたは行き詰まりを感じているのです。
私たちは、開発者が自分のデータで訓練した独��自のLLMを作成できるようにする新製品を発表できることをうれしく思っています。AI研究者のチームも、VPCからデータを持ち出すことも、専門的なモデルの専門知識も必要ありません。
お客様からは、LaminiなしではLLMの使用と精度をここまで高めることはできなかったとお言葉をいただいています。また、ChatGPTと検索を比較したブラインドテストでは、LaminiでトレーニングしたLLMが最も優れており、彼らのユースケースに最も近いと言われています。
その前に:なぜLLMを自分でトレーニングするのか?

ChatGPTは多くの人を驚かせました。しかし、何十年もこの分野に携わってきたAI研究者の観点からすると、有望なのは常にお客様のデータで訓練されたモデルです。ChatGPTのようなものですが、あなたの特定のニーズとコンテンツに合わせたものです。LLMのトレーニングが短期的にも長期的にも理にかなっているのには、いくつかの理由があります。
- より良いパフォーマンス: LLMから一貫性のある出力が欲しい、虚偽の主張をしたり競合他社を持ち出したりするような幻覚を見せなくしたい。何十年もの時間をかけてすべてのデータに目を通す専門家のように、ユースケースに対してより良いパフォーマンスを求めるのです。ギガバイトやテラバイトのデータに対して、小さなプロンプトに収まるような重要なものはありません。
- データプライバシー: LLMにプ�ライベートなデータにアクセスさせたいが、すべてを自社のインフラで管理したい。そのため、第三者にデータを提供することは避けたい。また、競合他社に利益をもたらす可能性のある一般的なモデルの改良に、自社の専有データ(またはその派生物)が使用され、自社のデータ・モートを脅かすようなことは避けたいでしょう。
- コスト: より低いコストで運用したい。既製品のソリューションは、顧客が頻繁に使用すると、法外に高価になることがあります。
- レイテンシー: レイテンシーを時間軸で選択し、コントロールしたい。市販のAPIでは、速度が制限されていたり、本番のユースケースには遅すぎたりすることがよくあります。
- アップタイム: 既製のAPIは稼働時間が一定せず、最高のソリューションでも稼働率は99%未満です。DevOpsチームがサーバーをコントロールできるようにしたいのですが、サードパーティーでは、トラフィックの多い時間帯や停電時に他の顧客と使用量を争うことになります。
- オーナーシップ: そのため、エンジニアリング・チームが、何十人ものML専門家を新たに雇用することなく、それを構築することを望んでいます。また、エンジニアが自社の製品やデータを最もよく知っているため、プロフェッショナル・サービスを契約したくないでしょうし、この分野の進歩が速いため、LLMを常にリフレッシュする必要があります。
- フレキシビリティ: 使用するLLMプロバイダーやオープンソースソリューションをコントロールし、モデリングスタックをユースケースやカスタムアプリケーション��に適応させることができるようにしたい。
- バイアス: 既製品のモデルにはバイアスがあります。LLMはトレーニングによって、気になる次元に沿ったバイアスを学習させることができます。
- コンテンツコントロール: モデルに提供するトレーニングデータをコントロールすることができます。これは、不適切でライセンスされていないコンテンツを緩和し、適切にライセンスされた関連性の高いデータという法的要件を満たすために重要です。ベースモデルの中には、これまで触れてきたデータについてより透明性の高いものがあり、それに基づいてベースモデルを選択することができます。
LLMを自分でトレーニングする仕組み
LLMを自分でトレーニングするというアイデアは、困難なものに思えるかもしれません。LLMをベースモデル以上に改善するためにデータを適切な形式で取得し、それを自分のインフラやGPUで確実にホストするためには、多くのコードと専門知識が必要です。Laminiライブラリは、少量のコードを書いてDatabricksの既存データにアクセスするだけで、そのプロセスを簡素化します。

- まず、Laminiは簡単なインストールでDatabricksクラスタに接続します。LLMにアクセスさせたい重要なデータを指定し、データの粒度を揃えます。
- そして、Laminiが自動的にインフラを管理します:ベースモデルの選択、トレーニングのためのデータ変換、検索による拡張トレーニング、パラメータ効率的な微調整、データ生成、自動評価など。このインフラは、通常、AI研究者やAIインフラエンジニアが数カ月かけて構築し、長期的にメンテナンスしています。ハイレベルな機能もローレベルな機能も、コードやホストされたノートブックを通じて利用することができます。
- 最後に、あなたのデータとカスタムLLMは、トレーニングプロセス中、あなたのVPCに留まります。ここから、組織全体で異なるユースケースや異なるデータに対して、より多くのLLMをトレーニングすることができます。
では、実際にChatGPTを凌駕するプライベートLLMの例を見てみましょう。 もしくは just start playing with it now.
ケーススタディ: 社内のエンジニアリング文書でLLMを養成する
あなたは、膨大な量の社内エンジニアリング・ドキュメントを持っています。ChatGPTのように、コードベースの内部Wikiを持ち、特定のアーキテクチャを学ぶ必要のない領域について質問したり、あなたの仕事に影響を与える他のチームからエラーのデバッグを手伝ってもらったりすることができるようにしたいのでしょう。しかし、ChatGPTはあなたのコードベース全体を把握しているわけではなく、コードベース全体で確実に正確な接続を行うことができず、実際には真実ではない新しい説得力のある知識を作り上げ、関連するトピックに会話を戻すことができません。
例えば、Laminiのエンジニアリング・ドキュメントを見ながら雑談をするような場合です。
ここでは、LLMにすべてのデータを渡し�た場合と、プロンプトエンジニアリングChatGPTで検索した場合との比較を示します:
| User's question | Private LLM Trained with Lamini and Databricks Data | ChatGPT + Retrieval |
|---|---|---|
| Laminiに送信できるデータの種類(テキスト、画像、音声など)に制限はありますか? | はい、Laminiが扱うことができるデータの種類には制限があります。ドキュメントには、データ形式の最適化、プライバシーとセキュリティの確保に関するガイドラインが記載されています。 | Lamini AIは、テキストと画像や音声を組み合わせるなど、マルチモーダルな入力に対応しています。 |
| Laminiはリアルタイム推論やストリーミング推論に対応していますか? | はい、Laminiはリアルタイムまたはストリーミング推論をサポートしています。これは、モデルをリアルタイムで更新し、リアルタイムで結果を生成できることを意味し、チャットボットやバーチャルアシスタントなどのアプリケーションに適しています。 | いいえ、Laminiは現在、リアルタイムまたはストリーミング推論をサポートしていません。 |
| なぜイチゴはピンク色なのか? | Laminiに関連した議論を続けましょう。 | わかりません |
Table: なおライブ版では常に結果が改善されているため、多少の違いがあることをご了承ください。
ChatGPTの検索では、情報を合成するのに十分な文脈がないため、上表の最初の例のように、Laminiが「テキストと画像や音声の組み合わせなど、マルチモーダルな入力をサポートする」と書いてあるが、そうではないと、頻繁に幻覚を見ている。
また、上表の2番目の例のように、本当は「はい」なのに「いいえ」と答えてしまうなど、検索に失敗すると、判断するためにデータの1%未満しか読んでいないため、存在する情報を見逃してしまいます。このような場合、プロンプトエンジニアリングでは不十分なことが多いのです。
一方、LLMはLaminiのドキュメントを100%熟知しています。LLMは、ラミニのドキュメントを100%熟知し、異なるセクションのドキュメントから情報を集約し、訓練されたように、会話を関連性のあるものに戻すことができます(「わからない」ではなく、「ラミニに関連した議論を続けよう」)。
今すぐこのLLMライブで遊ぼう!Googleアカウントを使ってLaminiにサインインし、質問を始めるだけです。
Databricksのデータで自分だけのLLMを育成する3つのステップ 1️⃣2️⃣3️⃣
ここでは、あなた自身の文書(または他のデータ)に対して、同じLLMを、世の中のどこよりも速く、より良く得るために必要なステップを紹介します:
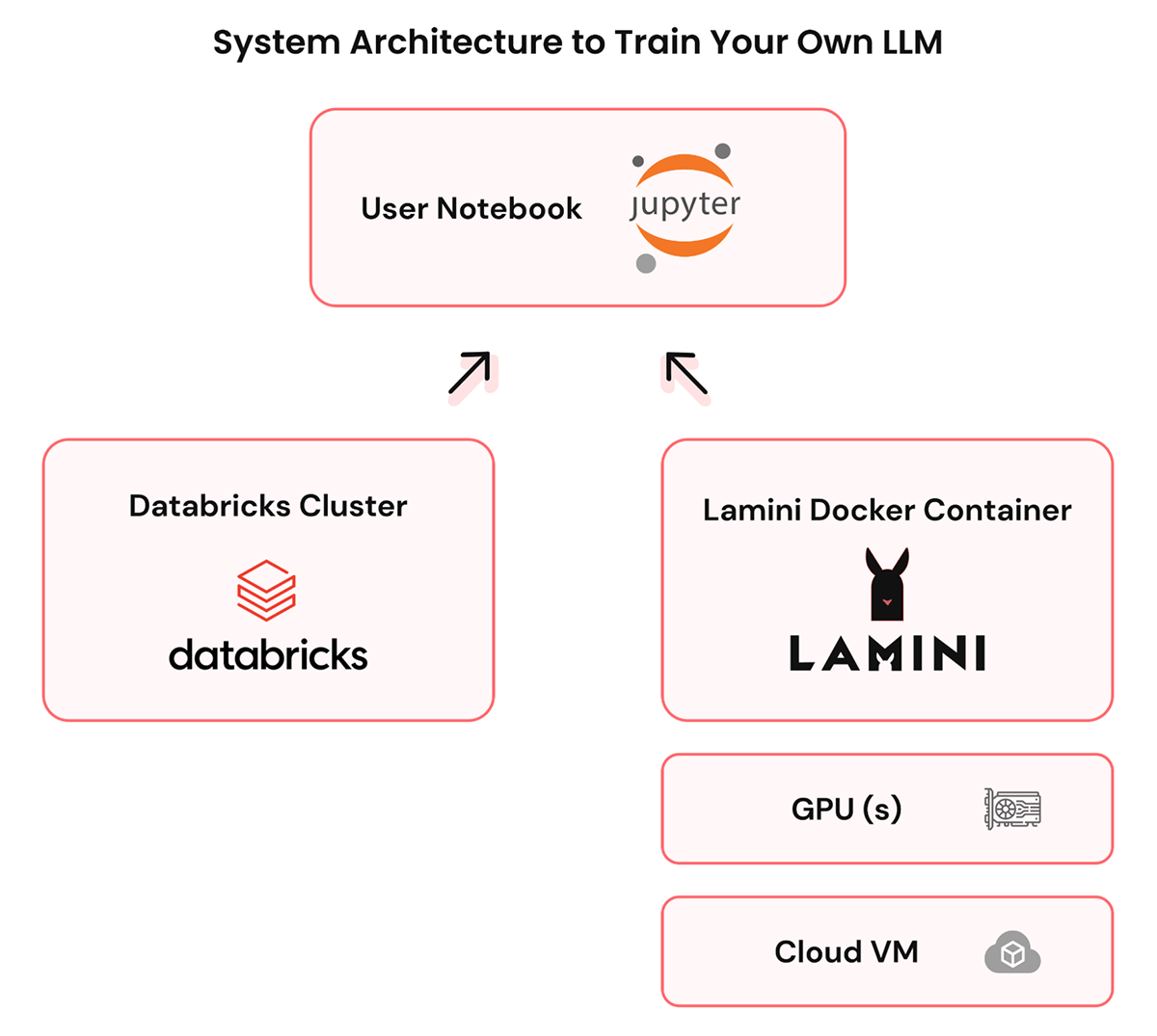
Step 1: Databricksの環境にLaminiをセットアップします。Databricks VPCにVMを作成し、その中にLaminiのDockerをインストールします。
- LLMを実行でき�るGPUインスタンス、すなわちモダンLinux(Ubuntuなど)、T4 GPU以上、100GBのディスクを作成する
- GPUドライバとDockerランタイムをインストールする
- Laminiのインストール(Dockerコンテナを含むtar.gzとインストールスクリプトを1つずつ)
- lamini-upを実行してLaminiのサービスを立ち上げる
- VPC内にクライアントがアクセスできるポート(例:80)を開設してください。

Step 2: Lamini libraryでコードを書いて、データレイクハウスをベースLLMに接続することで、重要なデータを指し示すことができます。データはあなたのVPCに残ります。
- LaminiとDatabricksにアクセスできるノートブック(JupyterやDatabricksなど)を開く
- SparkやSparkSQLを使って、Databricksから関連するデータをdataframeとして抽出する。
- データフレームのスキーマにマッチしたLaminiタイプを定義し、データフレームをLaminiオブジェクトに変換する。
Step 3: Lamini libraryを使えば、数行のコードで自分だけのLLMを育成することができます。Laminiは、ファインチューニング、最適化、データ生成、自動評価など、AI研究者チームが行うようなことを行います。このLLMは、あなたのVPCで提供されます。
- Laminiを使用してLLMを定義する。例) `from lamini import LLM; llm = LLM(...., config={""}))`
- LLMにデータを追加する。例)`llm.add_data(dataframe)`
- LLMを評価する。例)`answer = llm(question)`
Lamini は、お客様自身のデータで学習させた独自のLLMを作成することを可能にします。AI研究者のチームも、VPCからデータを持ち出すことも、専門的なモデルの専門知識も必要ありません。
この記事の内容は、Laminiの共同創業者兼CEOであるSharon Zhouがセッションを開催する「Data + AI Summit」ですべて学ぶことができます。Laminiは、Databricksのテクノロジーパートナーです。
Join other top tech companies building their custom LLMs on Lamini and sign up for early access today!

