Databricksがファイルサイズの自動最適化によりクエリパフォーマンスを最大2.2倍向上させた方法
An inside look at how Databricks constantly improves performance without sacrificing simplicity.
によって Sirui Sun, Himanshu Raja, ヴィジャヤン プラバカラン 、 テリー・キム による投稿
Original : How Databricks improved query performance by up to 2.2x by automatically optimizing file sizes
翻訳:saki.kitaoka
テーブルファイルサイズの最適化は、長い間データエンジニアにとって必要だが複雑なタスクでした。テーブルの適切なファイルサイズに到達すると、大幅なパフォーマンス向上が実現しますが、これは伝統的に深い専門知識と大量の時間投資を必要としていました。
最近、Databricks SQLのためのPredictive I/O(Predictive I/O for Databricks SQL)を発表し、ポイントルックアップをより高速かつコスト効率良く行うことができました。その作業を基に、本日はファイルサイズを自動的に最適化する追加のAI-powered機能を発表します。数千のプロダクションデプロイメントから収集したデータから学び、これらの更新はユーザーの介入を必要とせずに顕著なクエリパフォーマンスの向上をもたらしました。AI駆動のファイルサイズ最適化とPredictive I/Oの組み合わせにより、手動チューニングなしに大幅に高速な洞察時間が実現します。
結果
今年初めから、これらの更新はUnity Catalog Managedテーブルに展開されました。現在Unity Catalog Managed Tablesを使用している場合、これらの改善を手間をかけずに自動的に得ることができます - 設定は不要です。近く、Unity Catalog内のすべてのDeltaテーブルもこれらの最適化を適用することになります。
以下に、Databricks SQLでベンチマークを取った際の結果を示します:
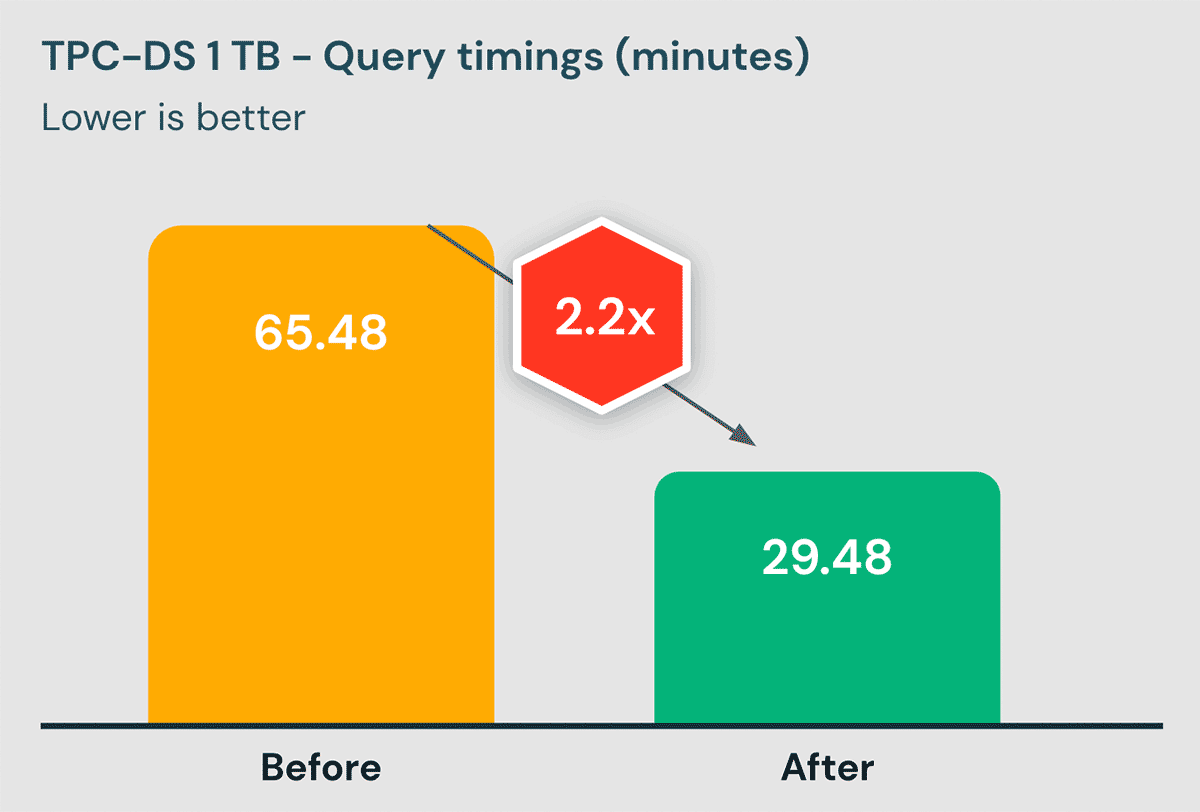
これらのベンチマークは、可能な限り現実的なものであることを確認するために、さまざまな工夫がなされています:
- 事実上すべてのベンダーが採用しているデータウェアハウスベンチマークであるTPC-DSを使用しています。
- 1TBのデータセットを使用したのは、ほとんどのテーブルがこのサイズであり�、このようなテーブルではカスタマイズされたチューニングのメリットを享受しにくいからです。しかし、より大きなテーブルでも同様に改善されるはずであることに注意してください。
- データセットのインジェストは、お客様でよく見られるインジェストパターンと同じように、小さなファイルで段階的に行っています。
ファイルサイズ最適化の技術的課題
Deltaテーブルをバックアップするデータファイルのサイズは、パフォーマンスにおいて重要な役割を果たします。ファイルサイズが小さすぎると、ファイル数が多くなりすぎて、メタデータ処理による処理のオーバーヘッドやクラウドプロバイダーのストレージサービスによるAPIレートの制限により、パフォーマンスが低下してしまいます。ファイルサイズが大きすぎると、タスクレベルの並列処理やデータスキップのような操作が難しくなり、コストが高くなります。Goldilocksのように、ちょうど良いファイルサイズにすることが課題です。
理想的なファイルサイズを選択することは、戦いの半分に過ぎません。残りの半分は、実際にそのサイズになるようにファイルを作成することです。
私たちは、お客様のワークロードにおいて、平均してファイルが小さすぎることを発見しました!- 実際、90%のファイルが1MB未満でした!
DeepDive:Databricksがファイルサイズを自動的に最適化する方法
何千もの本番環境から収集したデータと厳密な実験により、テーブルサイズや読み取り/書き込みの動作などの入力に基づき、「ちょうどよい」ファイルサイズのモデルを構築しました。例えば、1TB��サイズの典型的な顧客テーブルの場合、理想的なファイルサイズは64~100MBであることがわかりました。
理想的なファイルサイズを決定した後は、実際のファイルサイズを理想に近づけるために、多方面からアプローチしました。まず、ファイルの書き方を改善しました。パーティション化されたテーブルでは、データをシャッフルして、実行者がより少ない、より大きなファイルに書き込むようにしました。一方、パーティションなしのテーブルでは、より大きなファイルに対してタスクをまとめることができました。どちらの場合も、書き込みパフォーマンスへの影響が無視できる場合にのみ、これらの機能を有効にするよう注意しました。導入後、インジェストされるファイルの平均サイズは6倍になり、理想的なサイズに近づいています。
次に、小さすぎるファイルをちょうどいいサイズに圧縮するバックグラウンドプロセスを作成しました。この方法は、書き込みの改善にもかかわらず、まだ小さすぎるファイルに対処する、徹底的な防御を行うものです。以前の自動コンパクション機能(previous auto-compaction capability)とは異なり、この新しい機能は書き込みパフォーマンスへの影響を避けるために非同期で実行され、クラスタのアイドルタイムにのみ実行され、同時書き込み者がいる状況への対応に優れています。これまでのところ、9.8Mのコンパクションを実行し、各実行で平均29ファイルを1つに圧縮しています。
始めるにあたって
このパフ��ォーマンス向上のために、何もする必要はありません。
お使いのDeltaテーブルが以下の要件を満たしていれば、AIファーストの恩恵はすでに今日から享受できるのです!
- DB SQLまたはDBR 11.3以降を使用する。
- Unity Catalog Managed Tablesを使用(外部テーブルのサポートは近日公開予定です)
これらの改善により、ファイルサイズを最適化するためのチューニング(tuning for optimal file sizes)に悩まされることはありません。これは、Databricksが実装している多くの機能拡張の一例に過ぎず、DatabricksのデータとAI機能を活用して、ビジネス価値の最大化に集中できるよう、時間とエネルギーを解放することができるようになります。
Data + AI Summitでは、今後もAIを活用した様々な発表が予定されていますので、ぜひご参加ください!
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けし��ます。