コンテキストを認識するAIアシスタント、Databricks Assistantの紹介

翻訳:Junichi Maruyama. - Original Blog Link
本日、Databricks Notebooks、SQLエディタ、ファイルエディタでネイティブに利用可能な、コンテキストを意識したAIアシスタント、Databricks Assistantのパブリックプレビューを発表します。Databricks Assistantを使えば、会話形式のインターフェイスでデータを照会することができ、Databricks内での生産性が向上します。タスクを英語で説明すると、アシス��タントが SQL クエリを生成し、複雑なコードを説明し、エラーを自動的に修正します。アシスタントは、Unity カタログのメタデータを活用して、テーブル、カラム、説明、および会社全体で人気のあるデータ資産を理解し、あなたにパーソナライズされた応答を提供します。
データおよびAIプロジェクトの迅速な構築
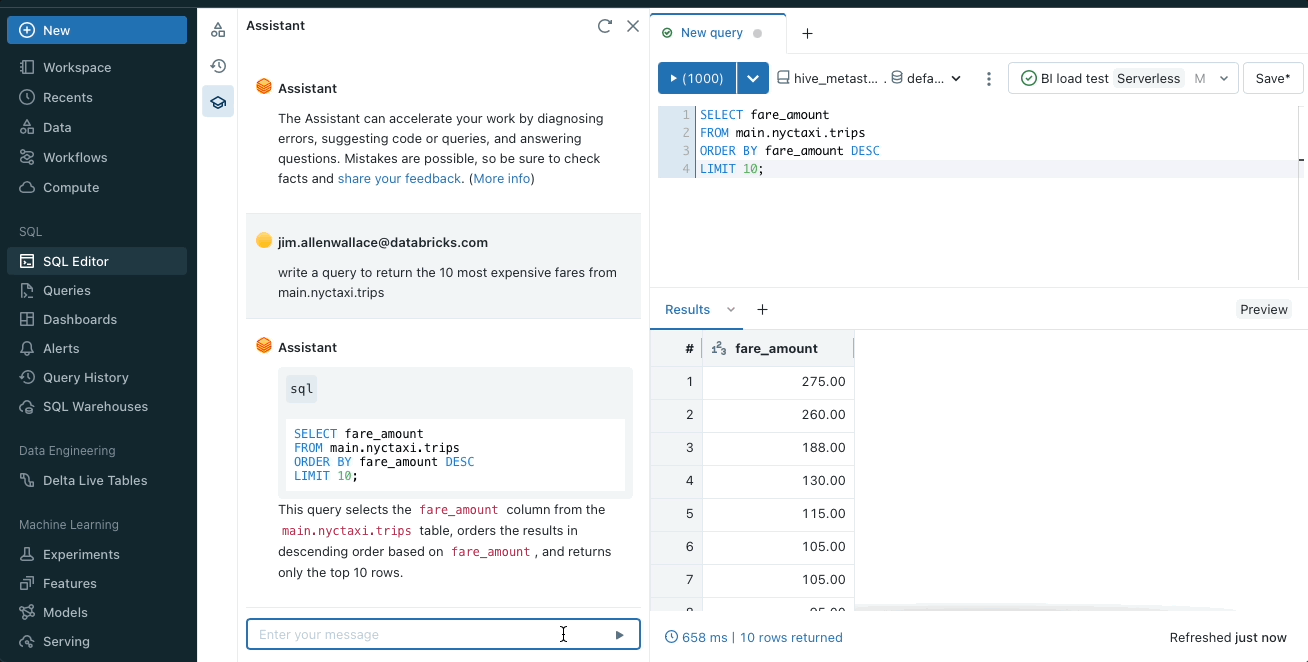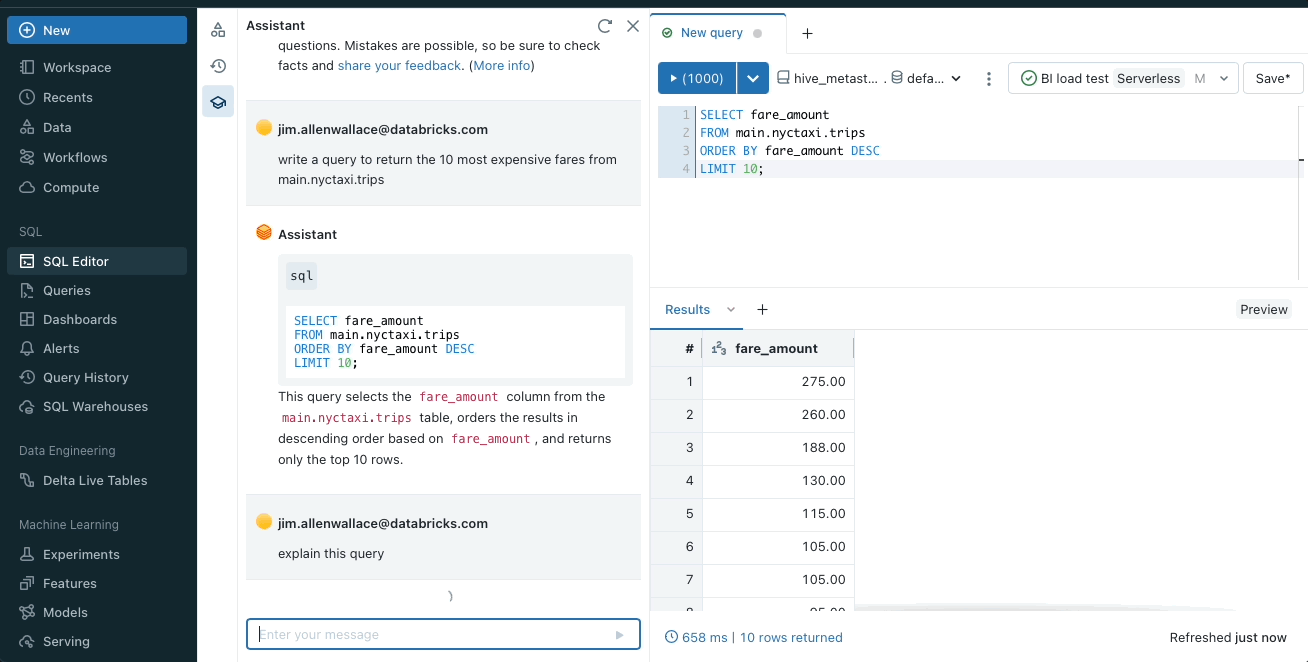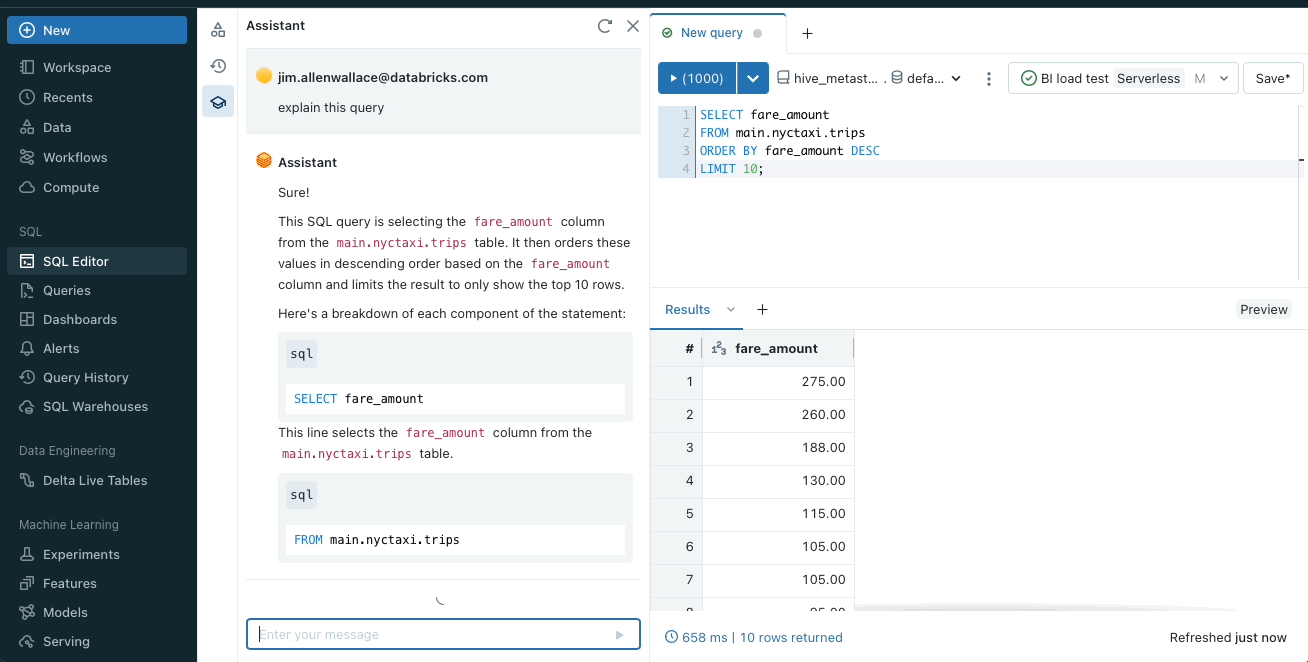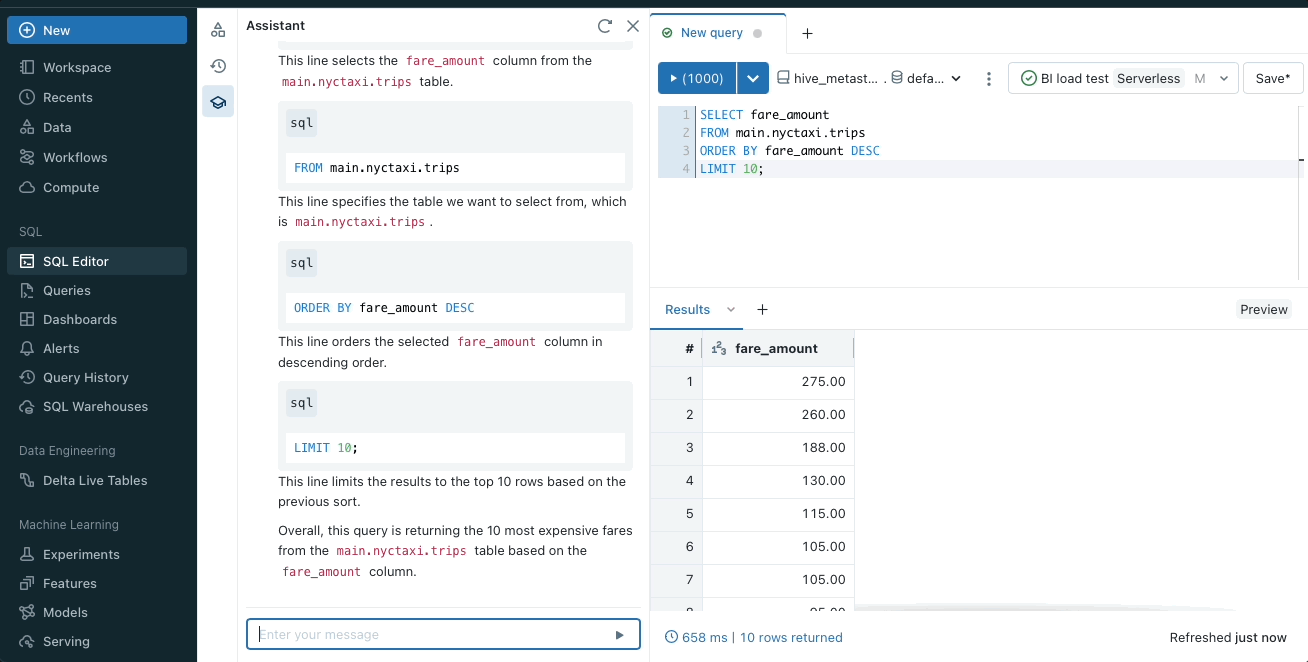
SQLまたはPythonコードの生成
Databricks Assistant は Databricks の各編集画面にネイティブに統合されています。編集サーフェス (ノートブック、SQL エディタ、ファイルエディタ) に応じて、関連する SQL クエリや Python コードを返します。定型的なコードを書いたり、最初のコードを提供することで、プロジェクトを加速させることができます。その後、コードを実行したり、コピーしたり、新しいセルに追加して開発を進めることができます。
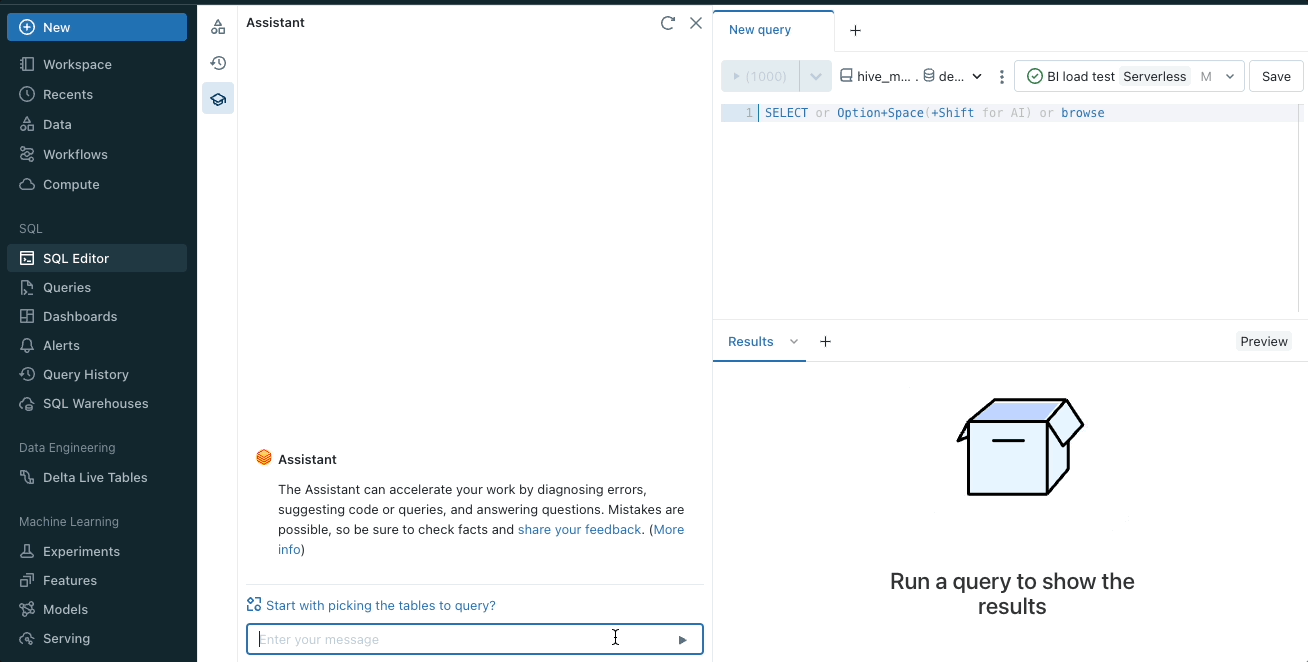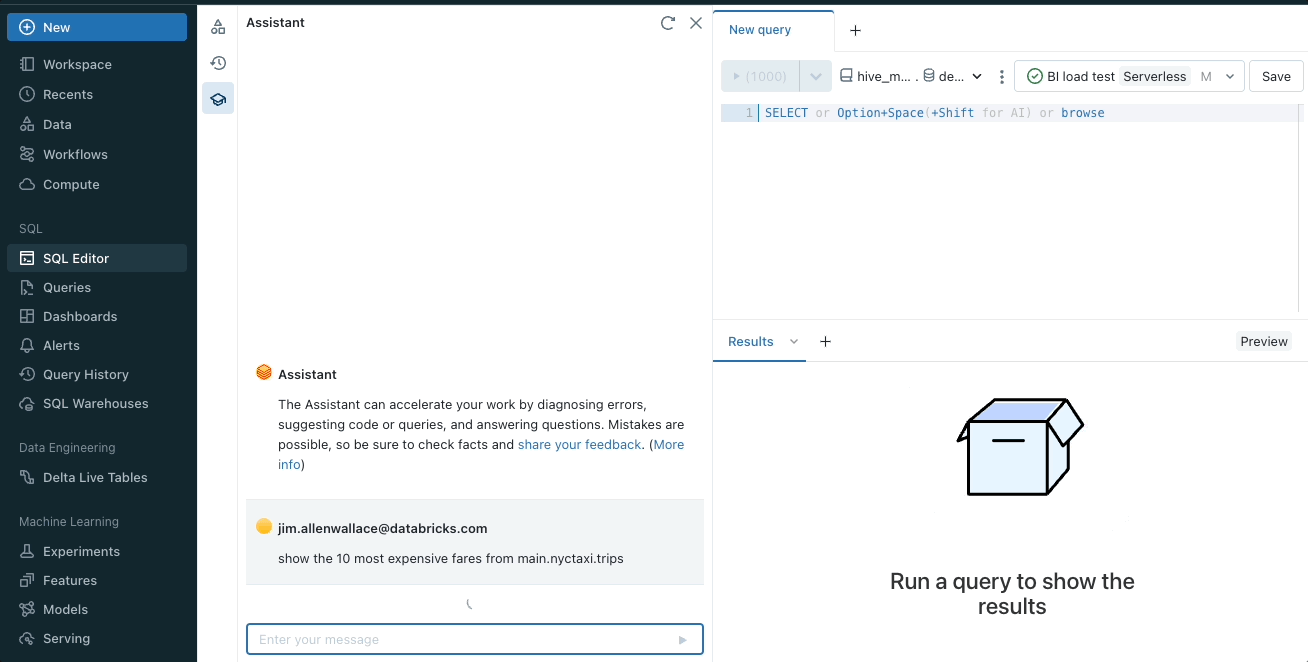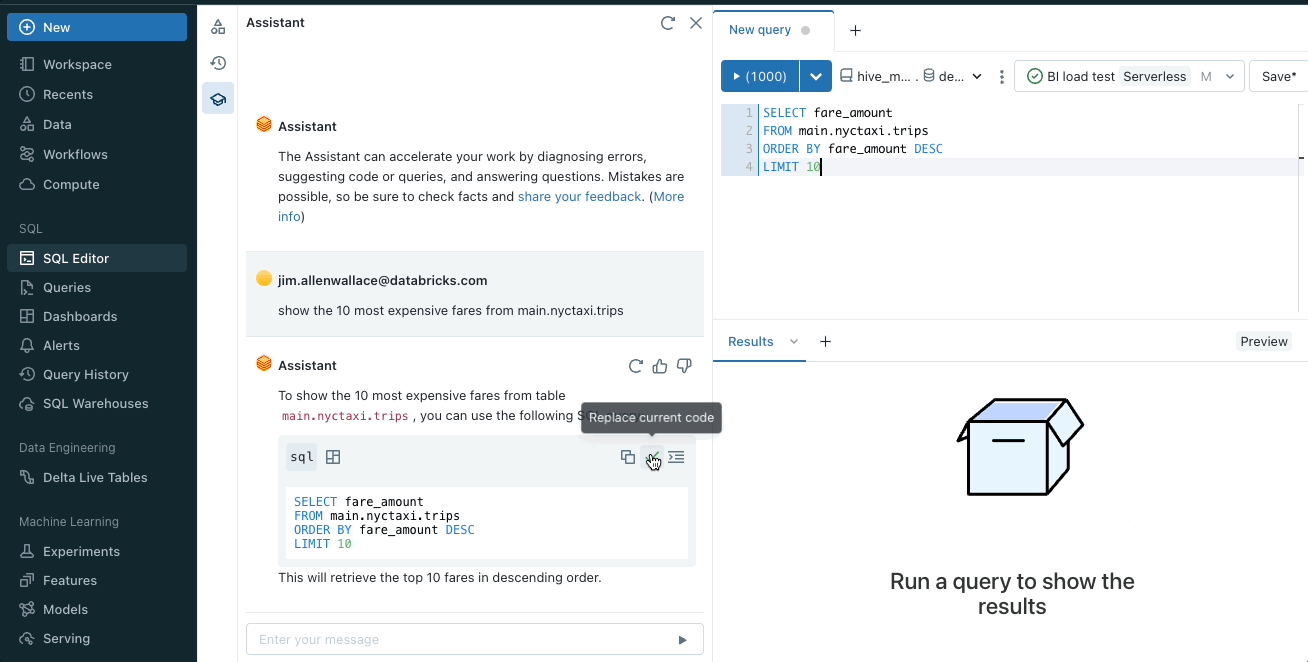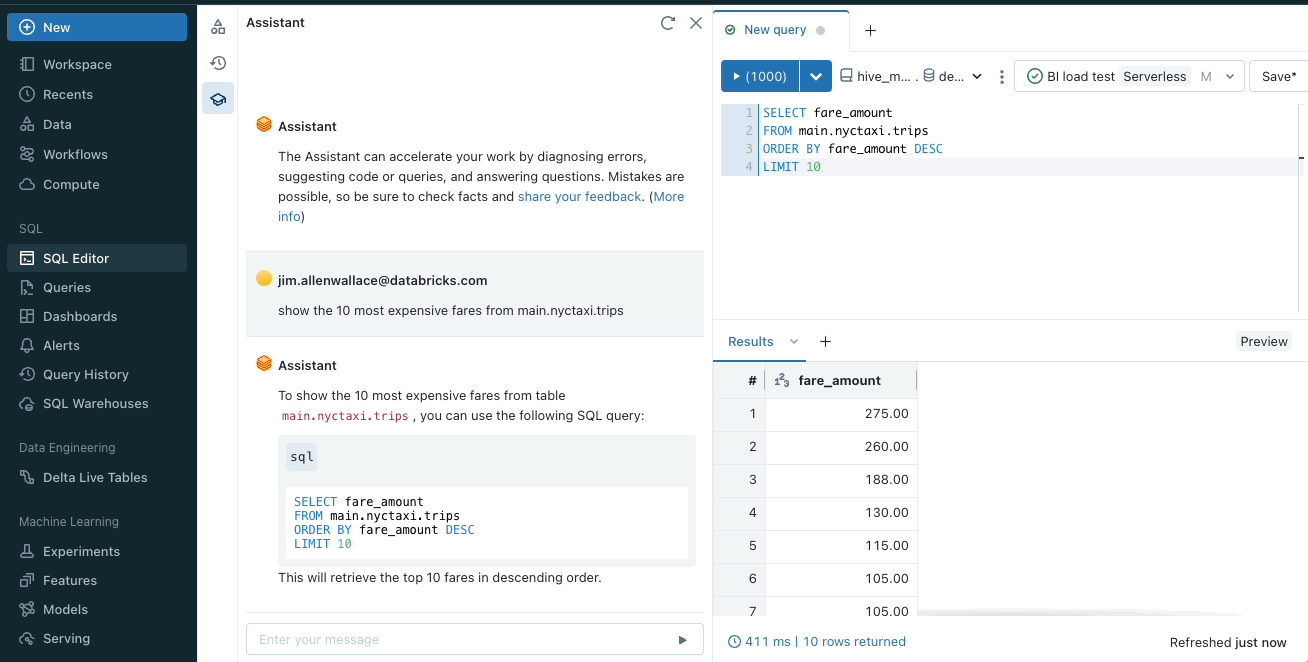
オートコンプリートコードまたはクエリ
ノートブック・セルやクエリ・エディタの中からアシスタントを使用して、コード・スニペットを提案することができます。コメントを入力し、control + shift + space(Windows)またはoption + shift + space(Mac)を押すと、オートコンプリート候補が表示されます。
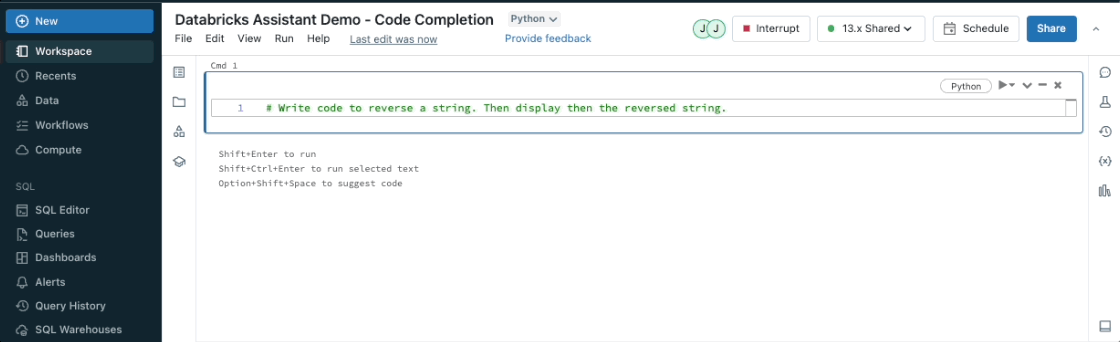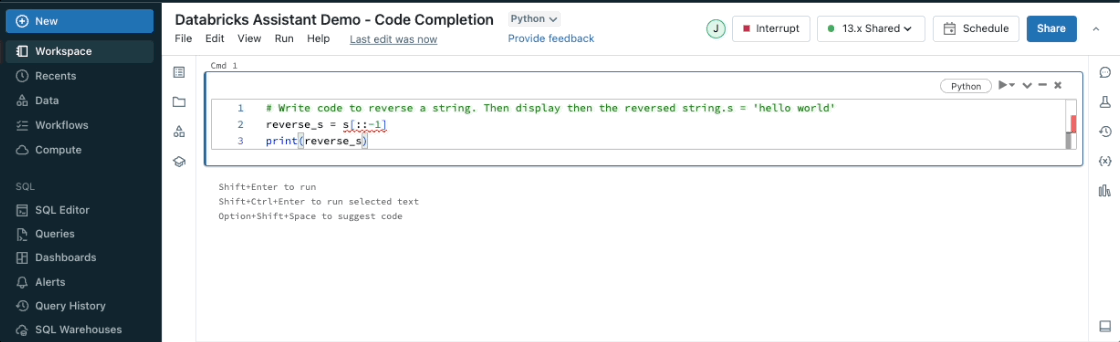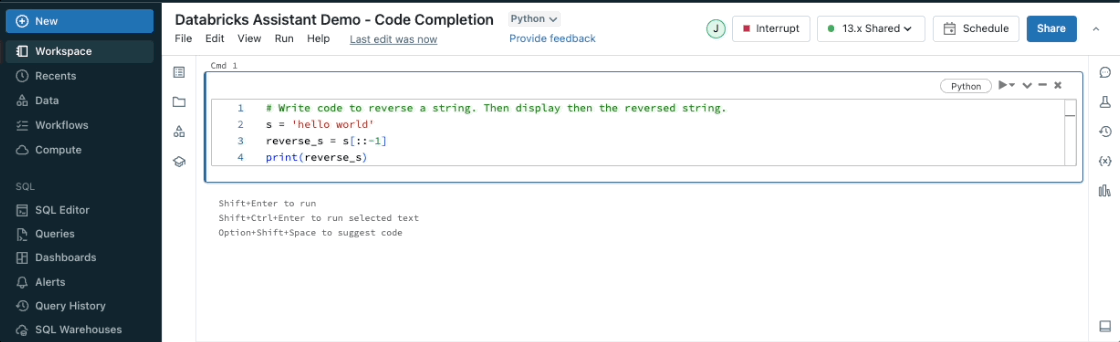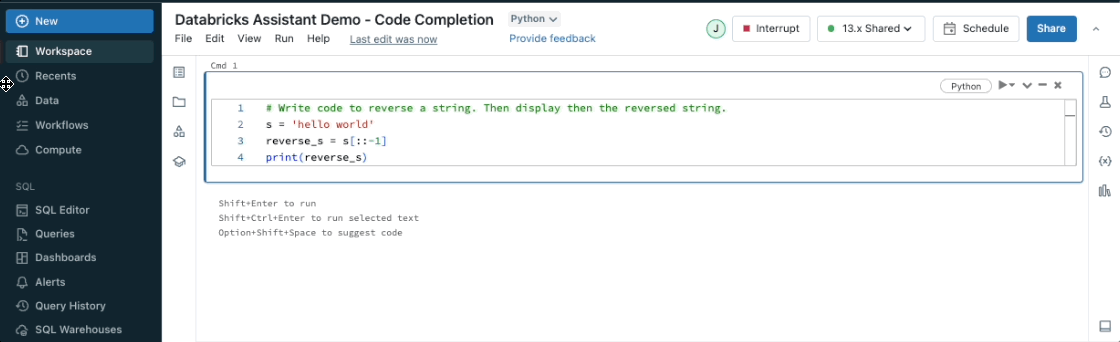
コード変換
アシスタントは、ある言語やフレームワークから別の言語にコードを変換することもできるので、常に現在のタスクに最適な言語を使うことができる。例えば、pandasのコードを書き直すことなくPySparkに変換することができます。
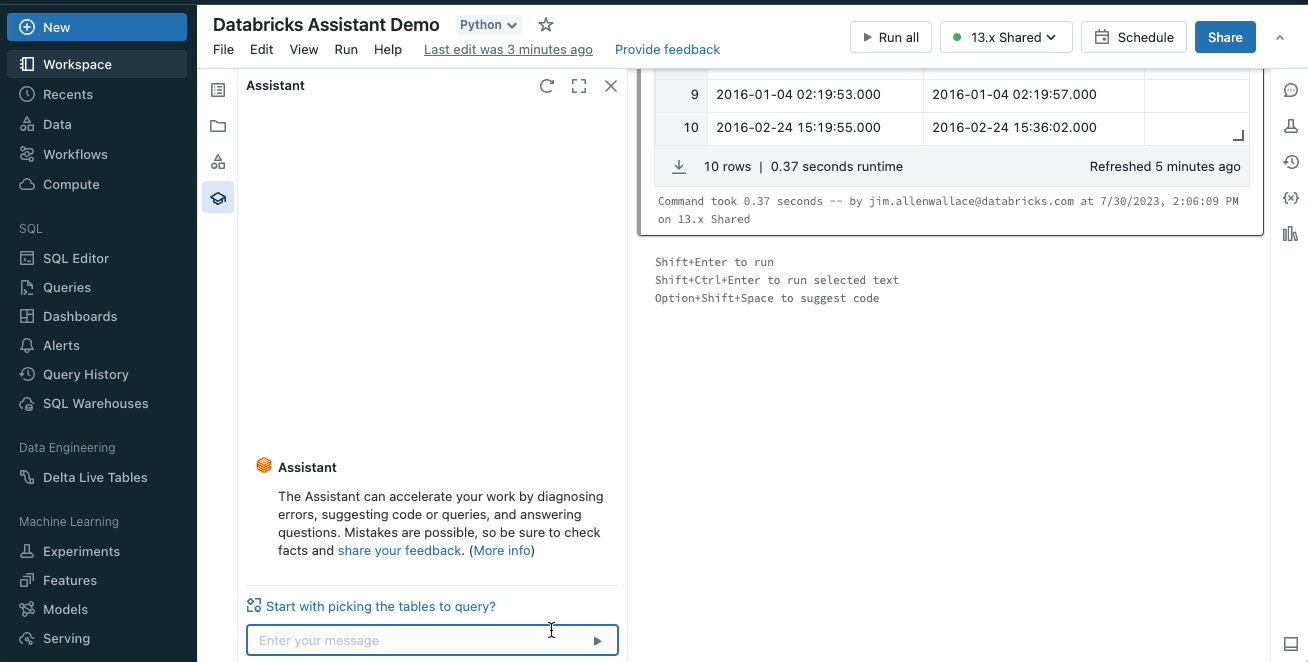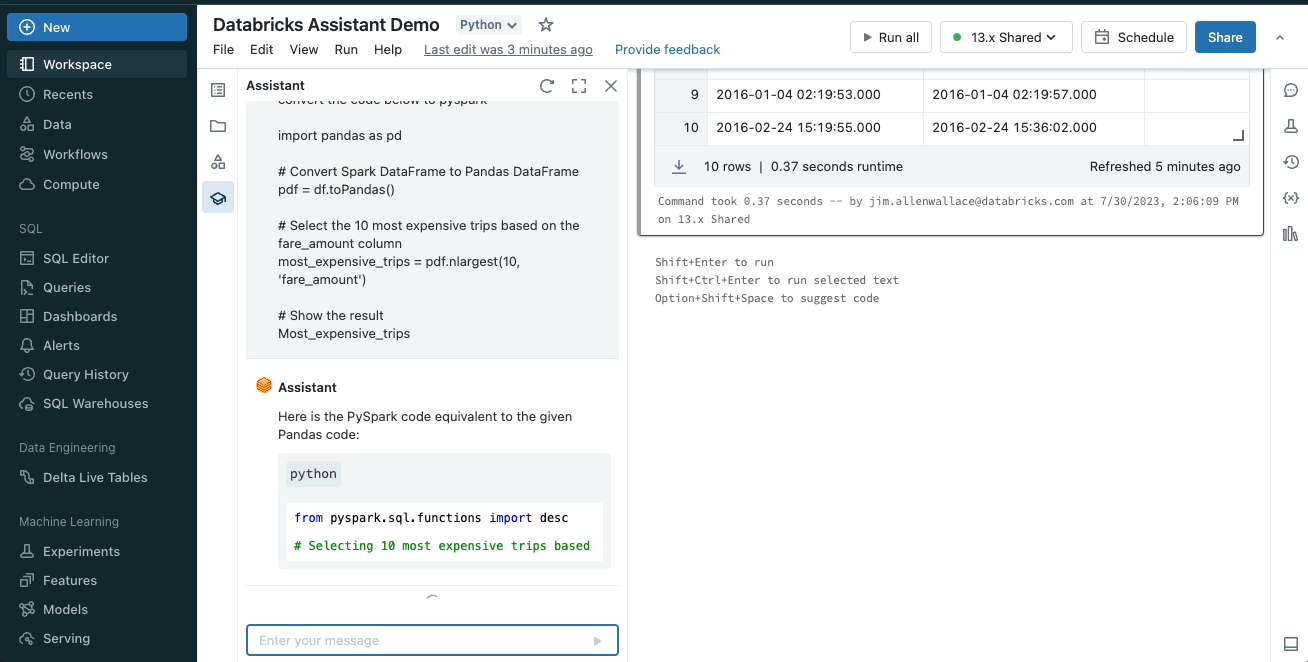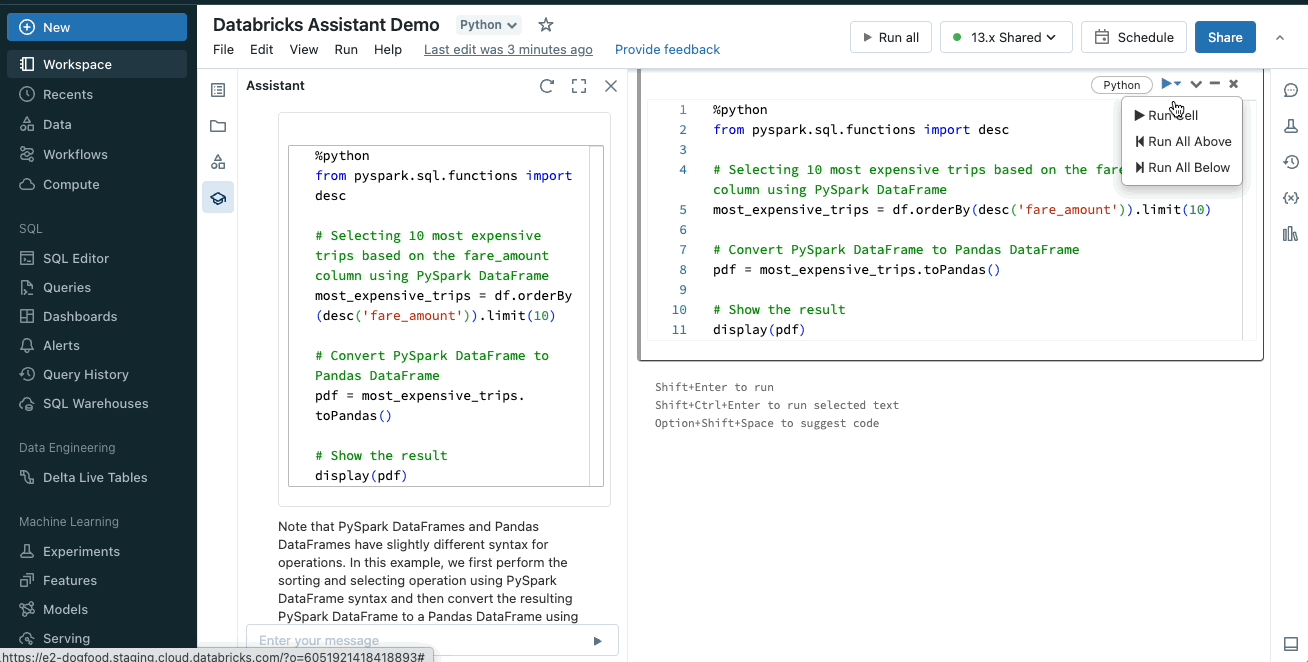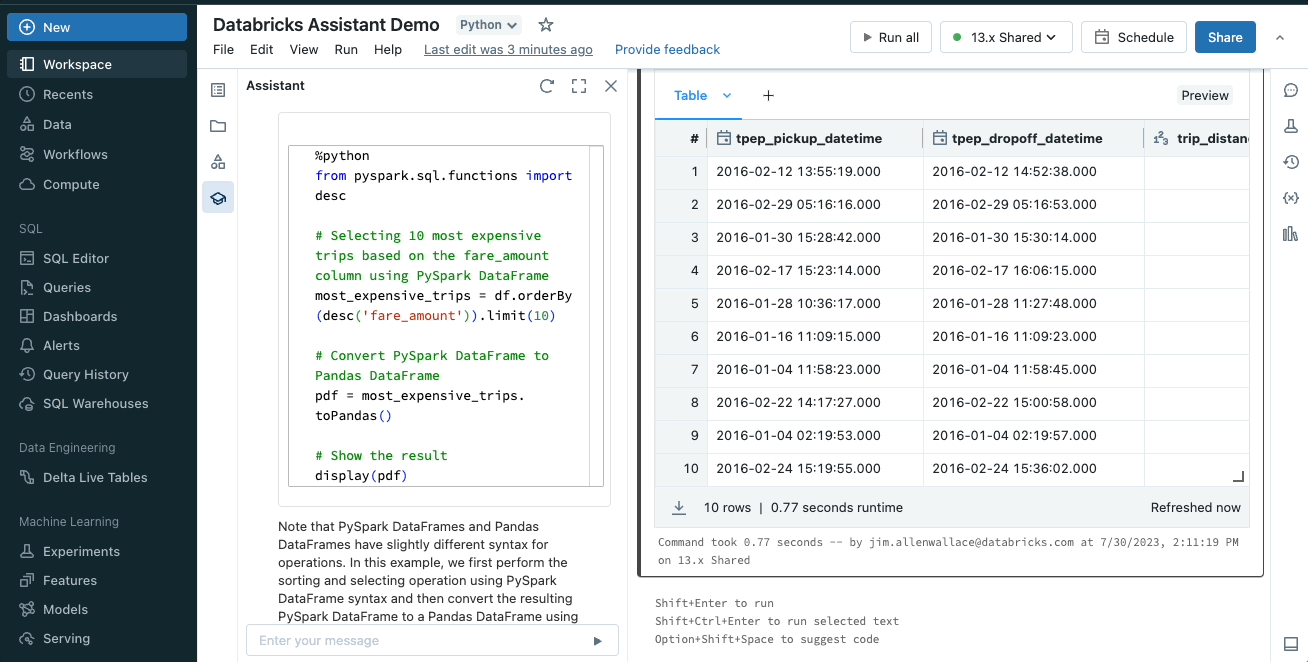
コードまたはクエリの説明
Databricks Assistant は、複雑なコードやクエリをわかりやすく簡潔に説明します。不慣れなプロジェクトの理解を深めるのに役立ちます。
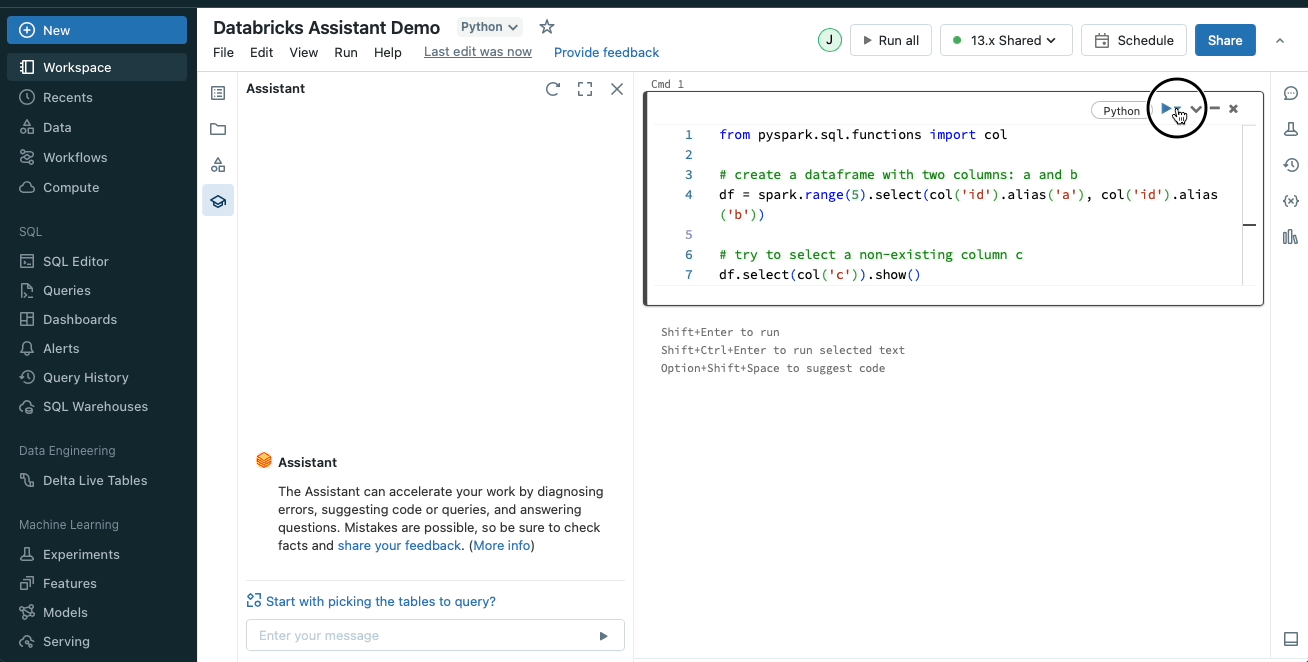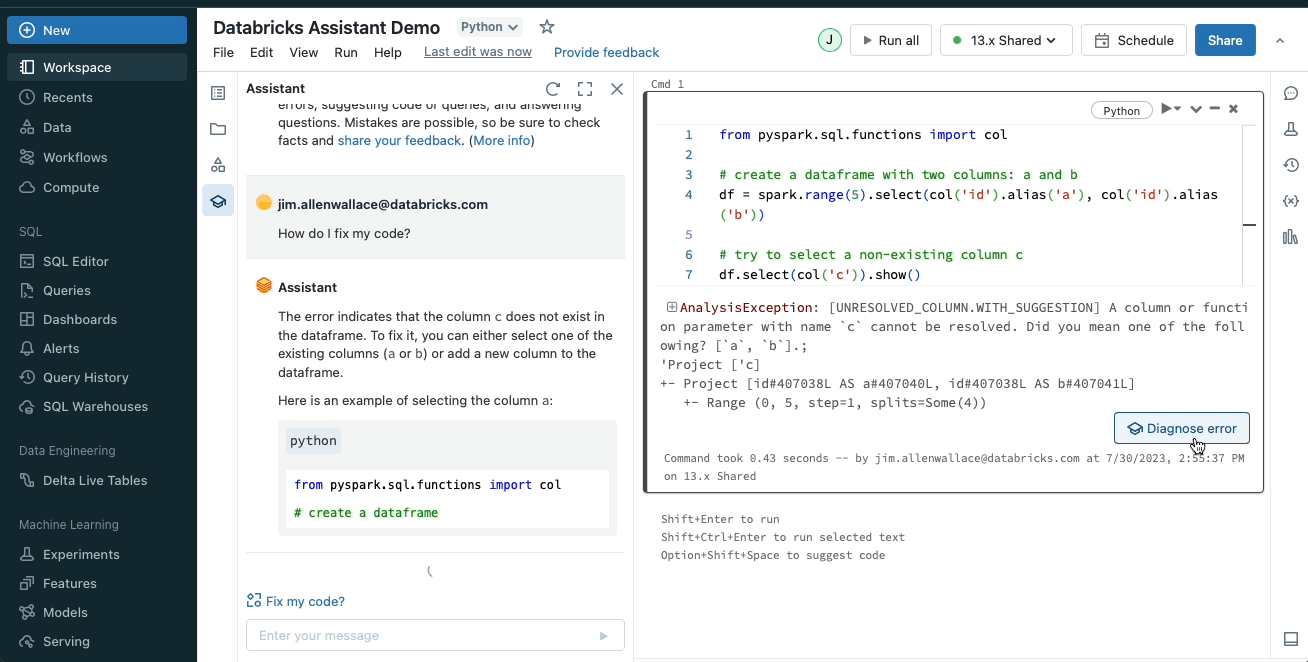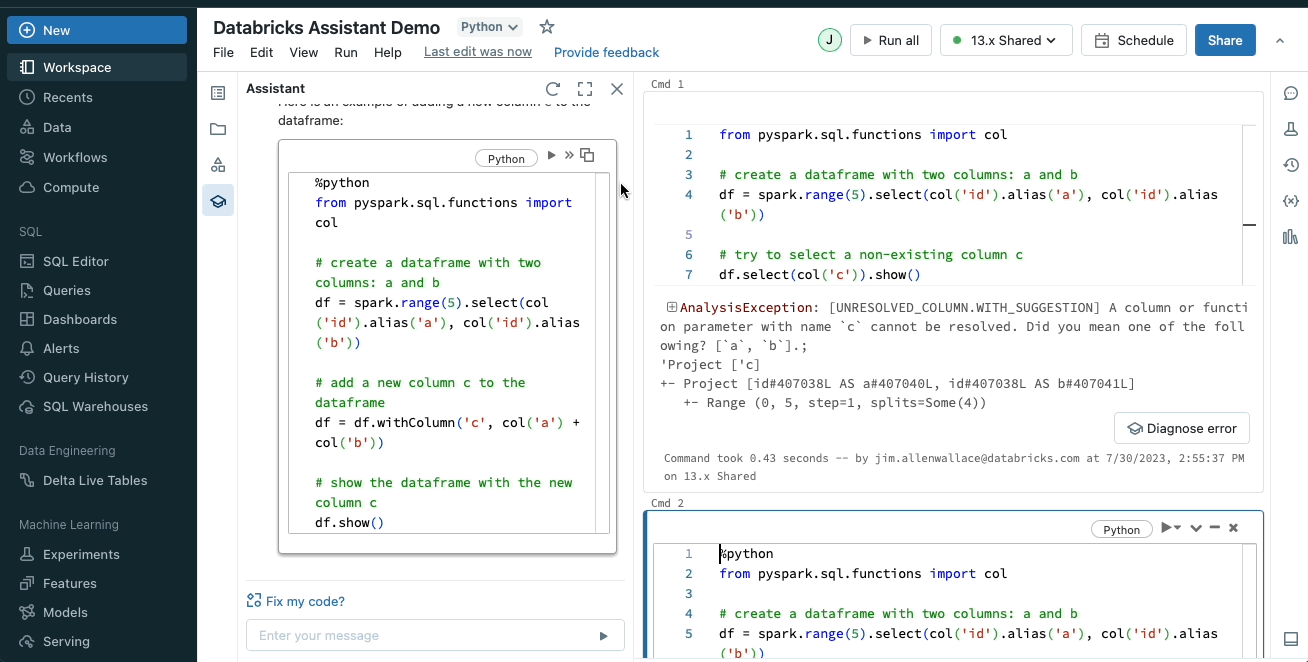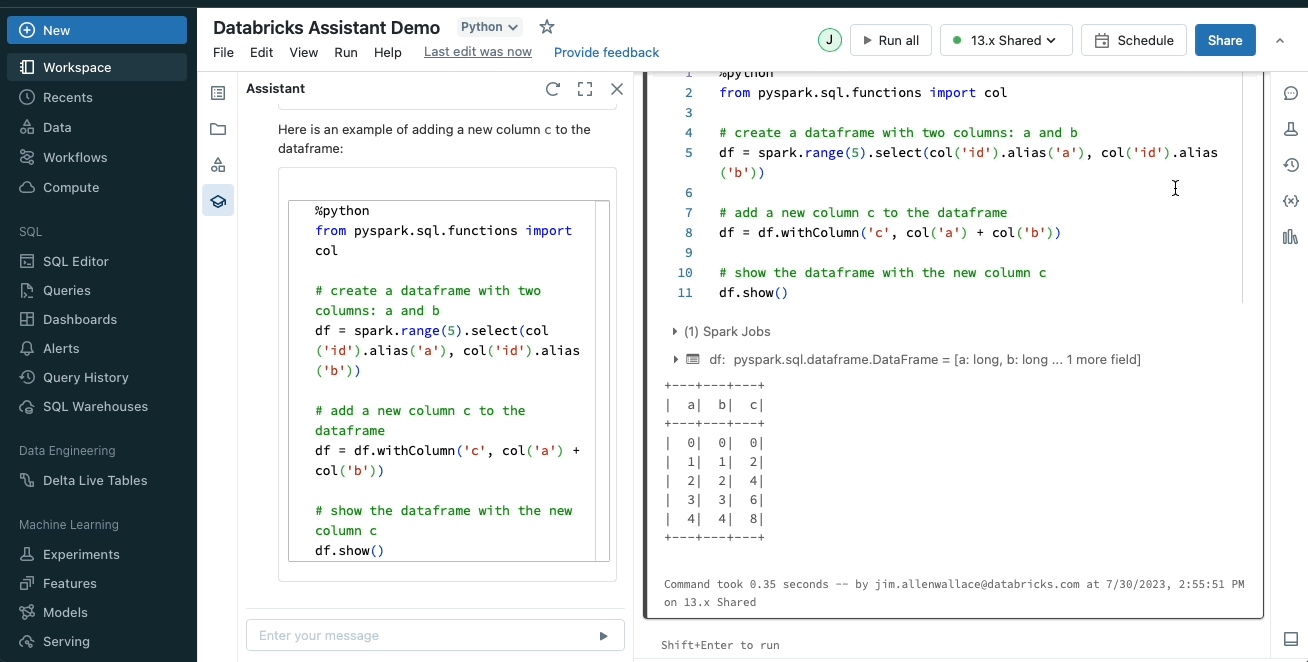
問題の修正
Databricks Assistant はコード内のエラーを特定し、修正を推奨します。構文エラーのような問題が発生すると、アシスタントは問題を説明し、修正案を含むコードスニペットを作成します。
お客様のためにパーソナライズされた、文脈に即した回答を得る
Databricks Assistantは、より正確で適切な結果を提供するために多くのシグナルを使用します。コードセル、ライブラリ、一般的なテーブル、Unity Catalogスキーマ、タグなどのコンテキストを使用して、自然言語による質問をクエリやコードにマッピングします。
将来的には、LakehouseIQとの統合を追加し、リクエストに対してさらに多くのコンテキストを提供する予定です。

