
汎用的な質問応答用の大規模言語モデルをどのようにファインチューニングすればよいのでしょうか?
興味深いアプローチの1つは、少数の高品質なサンプルに対する教師ありのファインチュー��ニングです。 最近のLIMA("Less Is More for Alignment") 研究では、1,000の多様で質の高い質問と回答のペアでトレーニングするだけで、汎用的な指示の追従が達成できると大胆に主張しました。同時期の他のいくつかの研究でも、この種の「スタイルアライメント」のファインチューニングは、少数の質の高いサンプルで達成できると主張しています(例えば 、Alpaca、 Vicuna、 Alpagasus、および Tülü 、しかし、 The False Promise of Imitating Proprietary LLMsも参照してください )
私たちは当初、このアプローチに懐疑的でした。 数千のサンプルで本当にLLMの質が向上するのでしょうか?
12月に開催されたNeurIPSワークショップで我々が発表した論文では、LIMAのスタイル・アライメント・アプローチを検討し、少量の高品質なファインチューニングサンプルが、MMLUやBIG-benchのような従来の複雑度ベースのNLPベンチマークと、オープンエンドのモデルベース評価(すなわち「LLM-as-a-judge」)の両方で性能を向上させることができるかどうかを調べました。
私たちは、わずか数千サンプルでファインチューニングを行うことで、モデルのパフォーマンスを向上させることができるこ��とを発見しました。
MPT-7Bと30Bのモデルを1,000のLIMAサンプルで最初にファインチューニングしたとき、LLM-as-a-judgeを使用するとモデルのパフォーマンスが向上することがわかり、大変驚きました。しかし、オープンソースの Eval Gauntletの伝統的なNLPベンチマークでは、特に良い結果は得られませんでした。
その後、最高のインストラクション・チューニング・データセットから1,000のランダム・サンプルを取り、その上でモデルをファインチューニングしました。 驚いたことに、これらのモデルは私たちの伝統的なNLP評価スイートで予想以上の結果を出しました。
そして、わずか数千サンプルのファインチューニングで、パープレキシティベースの評価パラダイムとモデルベースの評価パラダイムの両方で良い結果を 出すことが可能かどうかを問いました。我々の論文で示したように、データセットを混合するだけで、実際に可能です!
TLDR
では、LLMを効果的かつ安価に「インストラクション・チューニング」したい場合はどうすればいいのでしょうか?
- スタイルのアライメントのために、少数の多様で高品質なサンプルでファインチューニングを行います。LLMのファインチューニングを指示する際には、評価パラダイムにマッチした、異なるスタイルと異なるソースからの多様なサンプルを含めるようにしてください。例えば、トリビアのような多肢選択式のQAサンプル(MMLUのようなベンチマークに似たスタイル)と、より長く、よりオープンエンドな「AIアシスタント」スタイルのQAサンプル(LLMの「アズ-ア-ジャッジ」が好むスタイル)を組み合わせることが特に有効であることがわかりました。我々は、2,000~6,000のサンプルを混合することが、7Bと30Bのモデルスケールにおいて驚くほど効果的であることを発見しました。
- 複数の評価パラダイムを使いましょう。MMLUのような伝統的なNLP評価パラダイムと、LLM-as-a-judgeのような新しいパラダイムの両方を使用してモデルを評価するようにしてください。
この2つのことを行うことで、LLMを標準的なNLPベンチマークだけでなく、より流動的な「AIアシスタント」のような会話評価方法にも最適化することができます。
これはなぜですか?
訓練を受けたLLMは、いきなり首尾一貫した対応をするのは得意ではありません。少なくとも 、 特定のスタイルで応答するためには、 ファインチューニングが必要です。
「ファインチューニング」とは、LIMAのような小規模なデータセットから 、FLANv2のような大規模なデータセットまでを含む包括的な用語 です。FLANv2には、従来のNLPデータセットから幅広く抽出された質問と回答のペアが1,500万例以上含まれており、1,836のタスクの指示テンプレートに整理されて います。
LLMに新しい事実知識を導入するためのファインチューニングのプロセスと、 LLMを質問応答形式に 合わせる ためのファインチューニングのプロセスを切り離すことは有益です。 モデルに新しい知識を導入する場合、「データは多い方が良い」という十分な証拠があります。しかし、ベースとなるLLMを特定の スタイルで 回答するようにファインチューニングするだけ であれば、 それほど多くのファインチューニングサンプルは必要 ないかもしれません。 LIMAの論文に従って、LLMが特定のスタイルに合うようにファインチューニングできるという一般的な考え方を指すために、私たちは「スタイル・アライメント」という用語を使用します。
一般的なユーザーは、LLMが汎用的な「AIアシスタント」のようなスタイルで、自由形式のクエリに対して丁寧な段落長で応答することを期待しています。 一方、 研究者や開発者は、MMLUやBIG-bigBenchのような学術的なベンチマークで良い結果を出すためにLLMを最適化することがよくあります 。
このような文体の違いは、異なる評価パラダイムにも反映されています。MMLUのような自然言語処理評価ベンチマークは短いアカデミックなスタイルの質問を含み、トークンの完全な一致を期待します。しかし、一般的な自由形式の質問に対するモデルの応答の品質とスタイルを評価することは、従来の難易度ベースのNLPベンチマークを使用する場合には困難です。LLaMAやChatGPTのような簡単にアクセスできる高品質なLLMの出現により、別のLLMをジャッジとして使ってモデルの品質を評価することが可能になりました( AlpacaEvalや MTBenchなど ) 。 このモデルベースの評価パラダイムでは、LLMは命令を促され、対応する応答のペアを判定するよう求められます。
このように考えると、LLMが簡潔な多肢選択式で回答できるようにファインチューニングするのは、ほんの一握りのサンプルで済むかもしれません。 同様に、ChatGPTのようなサウンドを求めるのであれば、ほんの一握りのサンプルでファインチューニングを行えば十分です。
この研究はarXiv論文の LIMIT:Less Is More for Instruction Tuning Across Evaluation Paradigms (Jha et al. 2022)に詳しく述べられています。 私たちの実験の技術的な要約については、このまま読み進めてください!
テクニカル・ディープ・ダイブ
私たちは、Mosaic MPTファミリーの2つのオープンソースモデル、MPT-7BとMPT-30B、および3つのオープンソースの命令チューニングデータセットに注目しました: MPT-7B-InstructとMPT-30B-Instructに対応するインストラクション・チューニングデータセットで あるInstruct-v1 (59.3kサンプル、 dolly_hhrlhfとも 呼ばれる )と Instruct-v3 (56.2kサンプル)、および LIMAデータセット (1kサンプル)です。 (1)MMLUやBIG-benchのような伝統的なNLPベンチマークをベースと した、Mosaicの効率的なオープンソースEvalGauntletと、(2) GPT-4をジャッジとするAlpacaEvalの モデルベース評価スイートを用いて、モデルのパフォーマンスを評価します。
インストラクション・ファインチューニングのデータセット詳細
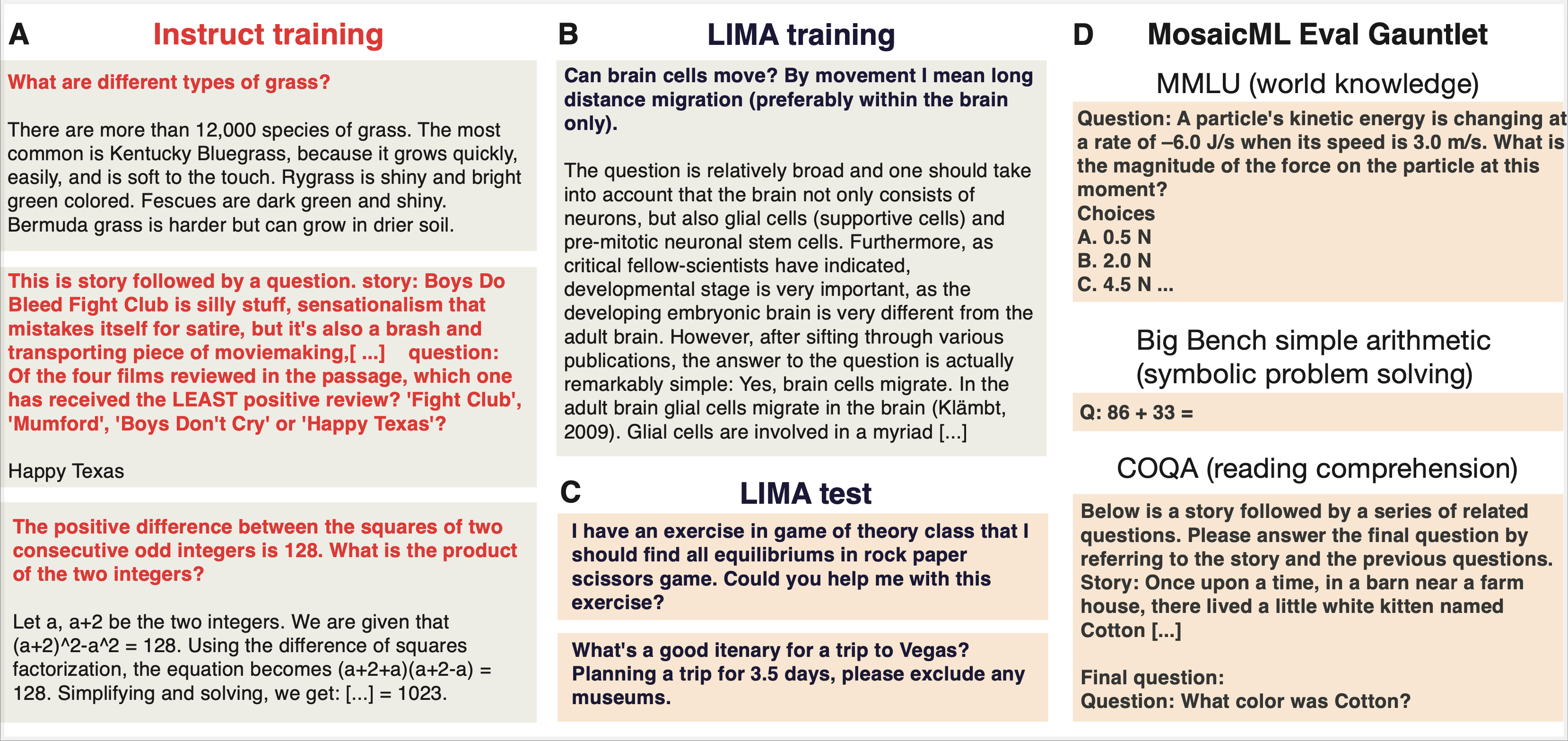
私たちは、一般に公開されている3つのファインチューニング・データセットを使用しました。 LIMAのトレーニングセットとテストセットには、汎用のAIアシスタントの口調で書かれた自由形式の質問と複数段落の回答の高品質なサンプルがあります。 MPT Instruct-v1およびMPT Instruct-v3のトレーニングセット(およびテストセット)には、トリビアのような質問と回答が含まれており、1段落よりも短い傾向があります。 私たちの論文では、これらのデータセットの違いを��詳しく調べました。
LIMA データセット: LIMA トレーニングセットには、Reddit、Stack Overflow、wikiHow、 Super-NaturalInstructions、および論文著者が手動で書いた例から キュレートした 1,000 サンプル(750,000 トークン)が含まれて います。例は、多様性と品質を確保するために厳密なフィルタリングを行った後に選択されました。LIMAの著者は、StackExchangeのさまざまなカテゴリ(プログラミング、数学、英語、料理など)から同数のプロンプトをサンプリングし、各プロンプトのトップアンサーを選択しました。この研究では、シングルターンの例のみを使用しました。
Lilac AIが管理するクラスター化されたバージョンを見ることで、このデータセットにどのような質問と回答が含まれているかを知ることができます。 このデータセットをブラウズすると、「犬の視点から詩を書いてください」といったクリエイティブなライティングのプロンプトや、「LinkedInのプロフィールを目立たせるには」といったマーケティングの質問、プログラミングの質問、人間関係のアドバイス、フィットネスやウェルネスのヒントなどが見つかります。ほとんどの回答は複数の段落にわたります。
MPT Instruct-v1データセット (別名「Dolly-HHRLHF」): このトレーニングセット��はMPT-7BInstructモデルのトレーニングに使用されました。MPT Instruct-v1 データセットには 、Databricks Dolly-15k データセットと Anthropic's Helpful and Harmless (HH-RLHF) データセットの キュレーションサブセット が 含まれて います。MosaicのMPT-7B-Instructモデルはこのデータセットを使ってファインチューニングされました。このデータセットには59.3kの例が含まれており、15kはDolly-15kから、残りはAnthropicのHH-RLHFデータセットから得られたものです。Dolly-15kには、分類、クローズドブック質問応答、生成、情報抽出、オープンQA、要約を含むいくつかのクラスのプロンプトが含まれています。AnthropicのHH-RLHFデータセットには、AnthropicのLLMを持つ労働者のクラウドソース化された会話が含まれています。 複数ターンの会話の最初のターンのみを使用し、選ばれたサンプルは、(有害なものとは対照的に)本質的に役に立ち、指示に従うものに限定されました。
MPT Instruct-v3 データセット:この訓練セットは、MPT-30B-Instructモデルの訓練に使用されました。このデータセットには、MPT Instruct-v1のフィルタリングされたサブセットと、他の一般に利用可能なデータセットが含まれています:Competition Math、DuoRC、CoT GSM8k、Qasper、SQuALITY、Summ Screen FD、Spider。その結果、Instruct-v3には、長い文章の後に文章に関連した問題(DuoRC、Qasper、Summ Screen FD、SQuALITYから�派生)が続く読解の例題が数多く含まれています。また、CompetitionMathやCoT GSM8Kから派生した数学の問題や、Spiderから派生したテキストからSQLへのプロンプトも含まれています。Instruct-v3には合計56.2kのサンプルがあります。Instruct-v1もInstruct-v3も、従来のNLPベンチマークの性能を向上させることを目的に作られました。
また、トピックのクラスターを見ることで、instructor-v3とLIMAデータセットとの違いを知ることができます。 このデータセットには、"Solve for x: 100^3 = 10^x "のような数学の問題や、筋書きの要約に関する問題、スポーツやエンターテイメントの雑学、"What year did the first cold war start? "のような歴史の雑学など、何千もの問題が含まれています。例題にざっと目を通すと、複数の例題が指示の中に含まれていることが多く(つまり、インコンテクスト学習の一形態)、正解はたいてい一文よりも短いことがわかります。
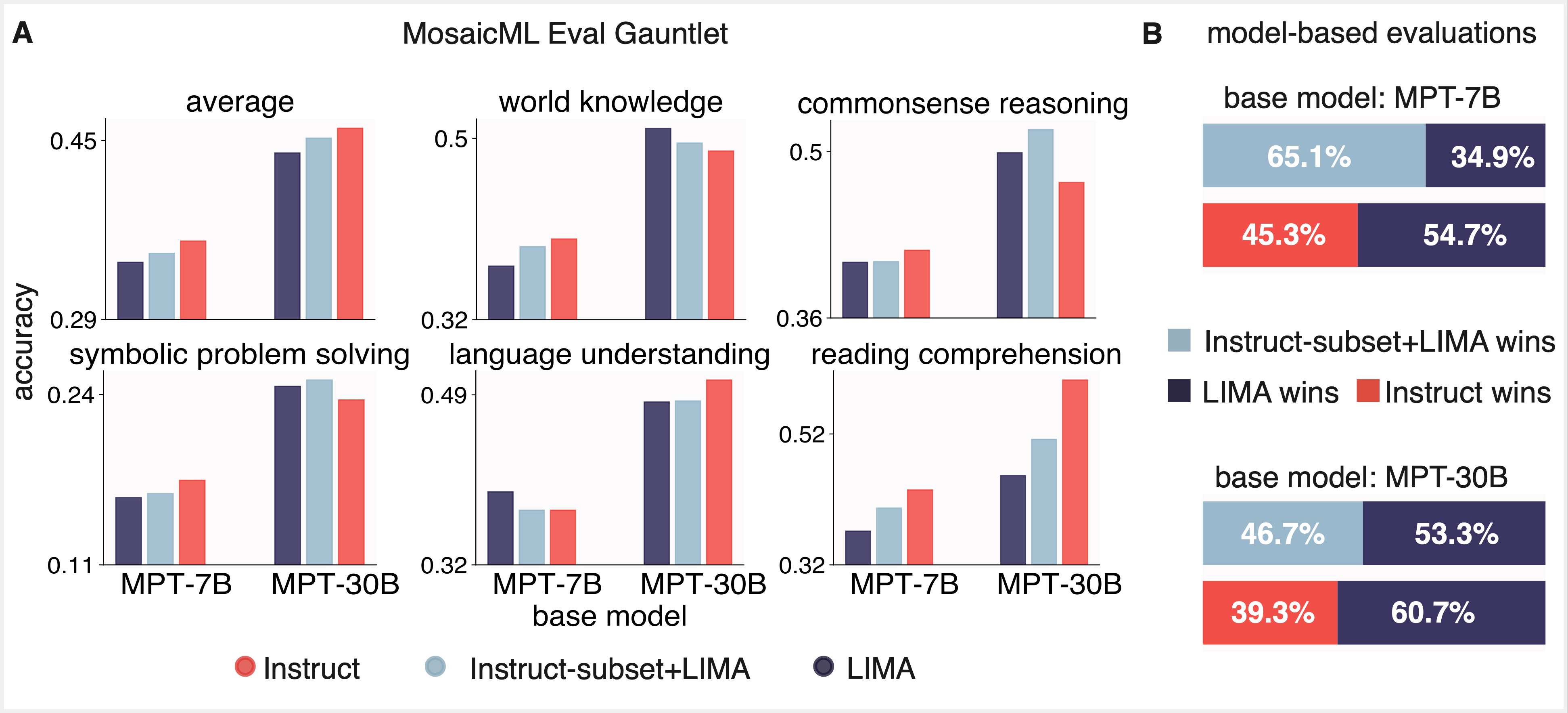
LIMAのファインチューニングは、複雑度ベースのNLPベンチマークではうまくいきません。
私たちはまず、LIMAの1,000サンプル・データセットがその約束を果たせるかどうかを問いました。LIMA上のMPTベース・モデルをファインチューニングして、従来のNLPベンチマークで最適なパフォーマンスを実現し、LLMで評価したときに良好な結果を出せるかどうか。 MPT-7BとMPT-30BのベースモデルをLIMA上でファインチューニングし、得られたモデルをMosaicのEval GauntletとAlpacaEvalのモデルベース評価スイートを用いて評価しました。 その結果、GPT-4では良好な結果が得られましたが、MPT-7BやMPT-30Bと比較すると、より大きなインストラクション・ファインチューニング・データセット(それぞれInstruct-v1、Instruct-v3)で学習したMPT-7BやMPT-30Bと同等の結果は得られませんでした。
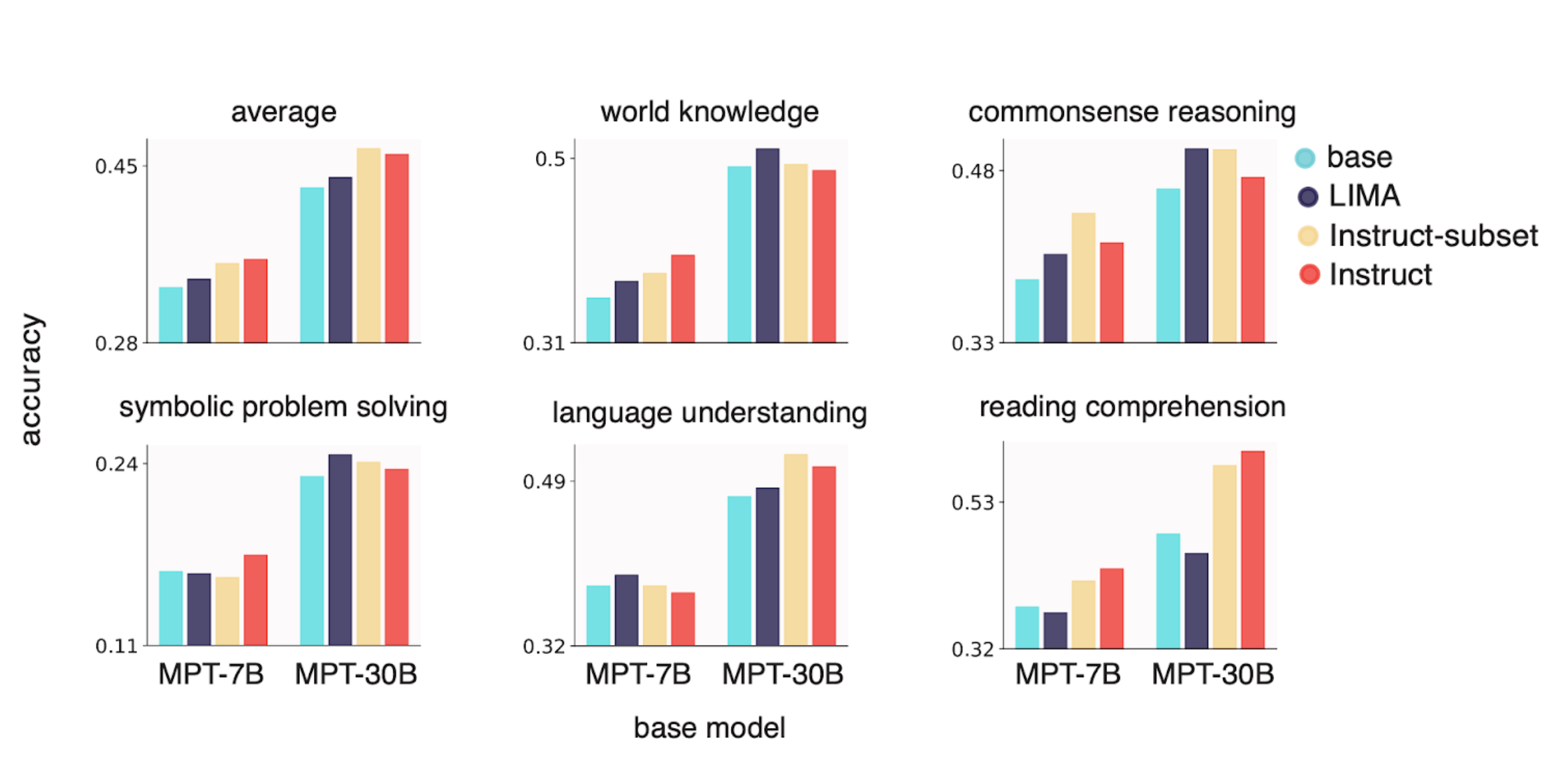
perplexityベースのNLPベンチマークで良い結果を出すには、数千の「ドメイン内」サンプルで十分です。
そこで、Instruct-v1とInstruct-v3から無作為に抽出した1,000~5,000個の「ドメイン内」サンプルを用いて、Eval Gauntletで全データセットと同等の結果が得られるかどうかを調査しました。 ファインチューニングデータのこの小さなサブセットが、LIMAの一般的な小サンプル・アプローチ(図3)を裏付けるように、Eval Gauntletで同様のパフォーマンスを示したことに、私たちは大変驚きました。 しかし、GPT-4で評価した場合、これらの同じモデルの成績は芳しくありませんでした(図4)。
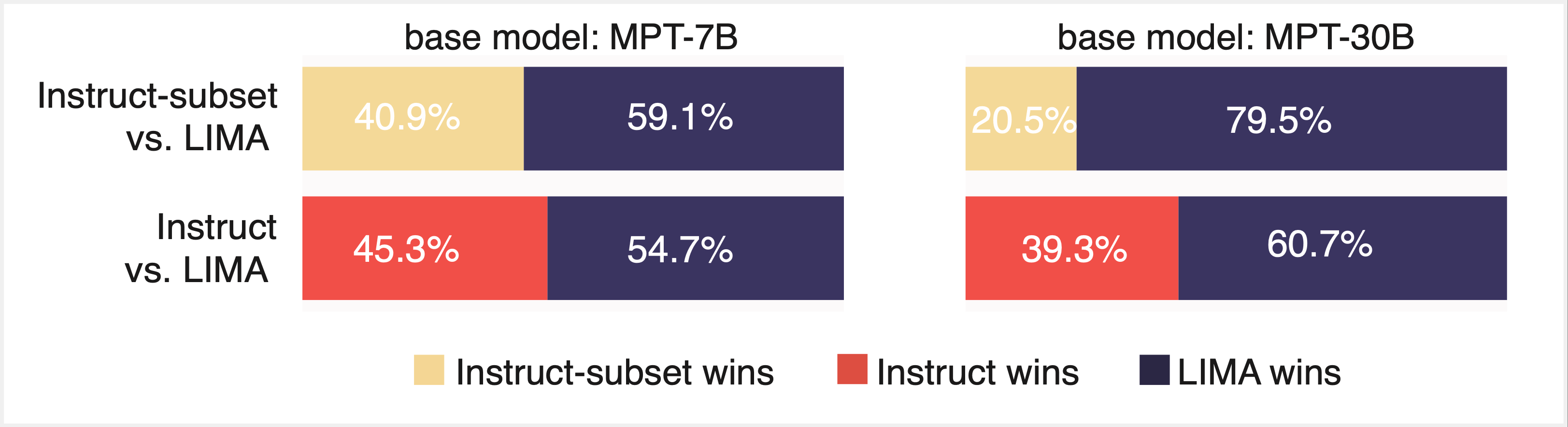
両方の長所:InstructとLIMAのデータセットを混合することで、両方の評価パラダイムで性能が向上
最後に、数千のInstructとLIMAのサンプルのサブセットでファインチューニングを行うことで、両方の良いところ、つまり両方の評価パラダイムで良いパフォーマンスが得られるかどうかを検討しました(図5)。この結果、両方のパラダイムで良好なパフォーマンスが得られることがわかりました。私たちは当初、1,000 サンプル未満で効果的なファインチューニングが達成できるのか懐疑的でしたが、私たちの結果は LIMA を再現 し、スタイル・アライメントへの「より少ないことはより多い」アプローチを構築しました。
次の目標は?
LLaMAモデルのオープンソースリリースと、GPT-3とchatGPTのクローズドソースのローンチによって、より大規模なデータセットでのインストラクション・ファインチューニングからのシフトが促進されました。 AI研究者たちは、LLaMA-7BのようなオープンソースのLLMが、最先端のGPTモデルによって生成された高品質のインストラクションフォローデータ上で効果的にファインチューニングできることにすぐに気づきました。
例えば、Alpacaは70億パラメータのLLaMaモデルで、GPT-3(text-davinci-003)によって生成された56,000例の質問応答サンプルに基づいてファインチューニングされています。この研究の著者は、Alpacaがはるかに大きなGPT-3モデルと同様のスタイルで応答することを発見しました。 アルパカ研究で用いられた方法にはやや疑問が残りますが(人間の嗜好性評価は5人の著者自身によって行われました)、Vicuna、 MPT-7B-chat、 Tülü、 Baize、 Falcon-40B などのさらなるファインチューニング研究でも同様の結論に達しました。 残念ながら、これらの論文の多くは異なる評価パラダイムに基づいているため、結果を並べて比較することは困難です。
幸いなことに、さらなる調査によ�って全貌が明らかになりつつあります。Tülüの論文「How Far Can Camels Go?Exploring the State of Instruction Tuning on Open Resources" (Wang et al. 2023)は、ファインチューニングされたLLMは、モデルベースの評価(GPT-4を使用)やクラウドソーシングによる人間の評価とともに、MMLUのようなベンチマークを使用した従来の事実想起能力を使用してテストされるべきであると主張 しました。Tülüと Tülü 2の両論文は、 異なるデータセットでLLaMAモデルをファインチューニングすることで、特定のスキルが促進され、すべての評価パラダイムで性能が向上するデータセットはないことを発見 しました。
The false promise of imitating proprietary LLMs" (Gudibande et al. 2023)では、ChatGPTの会話から得られた "模倣 "データで小さなLLMをファインチューニングすることで、会話スタイルを改善することができますが、この方法はMMLUやNatural Questionsのような伝統的なファクトベースのベンチマークでのパフォーマンス改善にはつながらないことを示しました。しかし、GPT-4由来の「模倣」データで訓練することで、Natural Questionsのようなクエリのドメインで、Natural Questionsベンチマークのパフォーマンスが向上することがわかりました。 最後に、「AlpaGasus:Training A Better Alpaca with Fewer Data" (Chen et al. 2023)と "Becoming self-instruct: introducing early stopping criteria for minimal instruct tuning" (AlShikh et al. 2023)は、下流で良いパフォーマンスを発揮するために必要なファインチューニングの例数がどれくらいかという問題に直接取り組みました。私たちの結果は上記の研究とうまく一致しています。
謝辞とコード
この研究は、LIMAやAI2のTulu論文(How Far Can Camels Go?Open Resources and Camels in a Changing Climate(オープン・ リソースと ラクダに関する指導調整の現状を探る):Enhancing LM Adaptation with Tulu 2)。
すべての実験は MosaicのComposer ライブラリと llm-foundryリポジトリを使い 、PyTorch 1.13でLLMトレーニングを 行いました。 詳細は プロジェクトのウェブサイトをご覧ください。
データセットのファインチューニング
- モザイク インストラクト-v1 (別名「ドリーHHRLHF)
- モザイ�クインストラクター-v3
- リマ
- Instruct-v1サブセット(5kサンプル)
- Instruct-v3サブセット(1kサンプル)
LLMモデルの重み
この研究は、アレックス・トロットの助言を得て、アディティ・ジャーとジェイコブ・ポルテスが主導しました。 サム・ヘイブンズがInstruct-v1とInstruct-v3データセットの開発を主導し、ジェレミー・ドーマンがMosaic評価ハーネスを開発しました。
免責事項
このブログで詳述されている作業は研究目的で行われたものであり、Databricksの製品開発のために行われたものではありません。