
このブログポストでは、MosaicMLエンジニアリングチームが、人気のあるオープンソースの大規模言語モデル(LLM)を実運用に活用するためのベストプラクティスを紹介します。 また、これらのモデルを中心に構築された推論サービスを展開するためのガイドラインを提供し、ユーザーがモデルや展開ハードウェアを選択する際の助けとする。 これらのガイドラインは、FasterTransformers、vLLM、NVIDIAが間もなくリリースするTensorRT-LLMなどの経験から導き出されたものです。
LLMテキスト生成を理解する
大規模言語モデル(LLM)は2段階のプロセスでテキストを生成する。"プリフィル" では入力プロンプトのトークンが並列処理され、"デコーディング" ではテキストが自己回帰的に一度に1「トークン」ずつ生成される。 生成された各トークンは入力に追加され、次のトークンを生成するためにモデルにフィードバックされる。 LLMが特別な停止トークンを出力するか、ユーザー定義の条件が満たされたとき(たとえば、トークンの最大数が生成され�たとき)、生成は停止する。 LLMがどのようにデコーダー・ブロックを使うのか、もっと背景を知りたい方は、こちらのブログ記事をご覧ください。
テキストをトークンに分割する正確なルールはモデルによって異なる。 例えば、Llamaがどのようにテキストをトークン化するのか、OpenAIがどのようにテキストをトークン化するのかを比較することができる。 LLM推論プロバイダーは、トークン・ベースのメトリクス(トークン/秒など)で性能について語ることが多いが、このようなばらつきがある以上、これらの数値はモデルの種類によって必ずしも比較できるものではない。 具体的な例として、Anyscaleのチームは、Llama 2トークン化はChatGPTトークン化よりも19%時間がかかることを発見した(それでも全体的なコストははるかに低い)。 また、HuggingFaceの研究者は、Llama 2はGPT-4と同じ量のテキストを学習するのに20%以上のトークンを必要とすることも発見した。
LLMサーヴィスにおける重要な指標
では、具体的に推論スピードをど��う考えればいいのか。
私たちのチームは、LLMを提供するために4つの主要な指標を使用しています:
- Time To First Token (TTFT):ユーザがクエリを入力してから、どれだけ早くモデルの出力を見始めるか。 応答までの待ち時間が少ないことは、リアルタイムのインタラクションでは不可欠だが、オフラインのワークロードではそれほど重要ではない。 この指標は、プロンプトを処理し、最初の出力トークンを生成するのに必要な時間によって駆動される。
- Time Per Output Token (TPOT): システムを照会する各ユーザーに対して出力トークンを生成する時間。 この指標は、各ユーザーがモデルのスピード(")" をどのように認識するかに対応している。 例えば、TPOTが100ミリ秒/tokの場合、1ユーザーあたり1秒間に10トークン、1分間に〜450ワードとなり、これは一般的な人が読む速度よりも速い。
- 待ち時間:モデルがユーザーに対して完全な応答を生成するのにかかる全体的な時間。 全体的な応答待ち時間は、前の2つの測定基準を使用して計算できる:待ち時間 =(TTFT)+(TPOT)* (生成されるトークン数)。
- スループット:推論サーバーがすべてのユーザーとリクエストに対して1秒間に生成できる出力トークンの数。
我々の目標は? 最初のトークンまでの最速時間、最高のスループット、出力トークンあたりの最速時間。 言い換えれば、私たちは、私たちがサポートできる限り多くのユーザーに対して、できるだけ速くテキストを生成するモデルを求めている。
注目すべきは、スループットと出力トーク�ンあたりの時間との間にトレードオフがあることです。16ユーザーのクエリーを同時に処理する場合、クエリーを順次実行するよりもスループットは高くなりますが、各ユーザーの出力トークンを生成するのに時間がかかります。
全体的な推論レイテンシの目標がある場合、モデルを評価するための有用なヒューリスティックをいくつか紹介しよう:
- 出力長は全体的な応答レイテンシを支配する:平均待ち時間については、通常、予想/最大出力トークン長をとり、それにモデルの出力トークンあたりの全体的な平均時間をかければよい。
- 入力トークンの長さは性能上重要ではないが、ハードウェア要件上重要である: 入力トークンを512個追加しても、MPTモデルで出力トークンを8個追加するよりもレイテンシの増加は少ない。 しかし、長時間のインプットをサポートする必要があるため、モデルの提供が難しくなる可能性がある。 例えば、MPT-7Bの最大コンテキスト長2048トークンを使用する場合は、A100-80GB(またはそれ以降)を使用することを推奨します。
- 全体的なレイテンシは、モデルの大きさによってサブリニアに変化する:同じハードウェア上では、より大きなモデルの方が遅いが、速度の比率は必ずしもパラメータ数の比率と一致しない。 MPT-30BのレイテンシはMPT-7Bのレイテンシの2.5倍である。 Llama2-70Bのレイテンシは、Llama2-13Bのレイテンシの2倍だ。
私たちはよく、見込み客から平均推論待ち時間を提示するよう求められる。 特定のレイテンシ・ターゲット("トークンあたり20ミリ秒以下が必要" )に固定する前に、予想される入力と希望する出力の長さの特徴づけに時間をかけることをお勧めします。
LLM推論における課題
LLM推論の最適化には、以下のような一般的なテクニックが有効である:
- オペレーター・フュージョン:隣接する異なる演算子を組み合わせることで、待ち時間が改善されることが多い。
- 量子化:アクティベーションと重みは、より少ないビット数を使用するために圧縮される。
- 圧縮:疎分散または蒸留。
- 並列化:複数のデバイスにまたがるテンソル並列または大規模モデルのパイプライン並列。
これらの方法以外にも、Transformer特有の重要な最適化がたくさんある。 その代表例がKV(キー・バリュー)キャッシングだ。 デコーダのみのTransformerベースのモデルにおけるAttentionメカニズムは、計算効率が悪い。 各トークンは、以前に見たすべてのトークンに対応するため、新しいトークンが生成されるたびに同じ値の多くを再計算する。 例えば、N番目のトークンを生成している間、(N-1)番目のトークンは(N-2)番目、(N-3)番目......1番目のトークンに対応する。 同様に、(N+1)番目のトークンを生成している間、N番目のトークンに対する注意は再び(N-1)番目、(N-2)番目、(N-3)番目、...1番目のトークンを見る必要がある。 KVキャッシング、すなわちアテンション・レイヤーの中間キー/値の保存は、それらの結果を後で再利用するために保存し、繰り返し計算を避けるために使用される�。
メモリ帯域幅が鍵
LLMの計算は、主に行列と行列の乗算演算で占められており、次元が小さいこれらの演算は、ほとんどのハードウェアにおいて、一般的にメモリ帯域幅の制約を受ける。 トークンを自己回帰的に生成する場合、活性化行列の次元(バッチサイズとシーケンスのトークン数で定義される)の1つは、バッチサイズが小さいと小さくなる。 したがって、スピードは、ロードしたデータに対してどれだけ速く計算できるかよりも、GPUメモリーからローカル・キャッシュ/レジスタにモデル・パラメーターをどれだけ速くロードできるかに依存する。 推論ハードウェアで利用可能かつ達成可能なメモリ帯域幅は、ピーク演算性能よりもトークン生成速度の予測因子として優れている。
推論ハードウェアの利用率は、サービスコストの点で非常に重要である。 GPUは高価なので、できるだけ多くの仕事をしてもらう必要がある。 共有推論サービスは、多くのユーザーからのワークロードを組み合わせ、個々のギャップを埋め、重複するリクエストをバッチ処理することで、コストを低く抑えることを約束する。 Llama2-70Bのような大型モデルでは、バッチサイズが大きくなって初めてコスト・パフォーマンスが向上します。 大きなバッチサイズで動作する推論サービングシステムを持つことは、コスト効率にとって非常に重要である。 しかし、バッチが大きいとKVキャッシュのサイズも大きくなり、モデルの処理に必要なGPUの数も増える。 ここには綱引きがあり、シェアードサービス事業者はコストのトレードオフを行い、システムの最適化を実施する必要がある。
モデル帯域幅利用�率(MBU)
LLM推論サーバーはどの程度最適化されているのか?
先に簡単に説明したように、バッチサイズが小さいLLMの推論、特にデコード時の推論は、デバイスメモリからコンピュートユニットにモデルパラメータをどれだけ速くロードできるかがボトルネックになる。 メモリ帯域幅は、データ移動の速さを決定する。 基礎となるハードウェアの利用率を測定するために、モデル帯域幅利用率(MBU)と呼ばれる新しいメトリックを導入する。 MBUは、(達成メモリ帯域幅)/(ピークメモリ帯域幅)で定義され、達成メモリ帯域幅は、((全モデルパラメーターサイズ + KVキャッシュサイズ)/ TPOT)である。
例えば、16ビット精度で実行される7BのパラメーターのTPOTが14msに等しい場合、14msで14GBのパラメーターを動かすことになり、1TB/秒の帯域幅を使用することになる。 マシンのピーク帯域幅が2TB/秒の場合、MBUは50%で稼働している。 簡単のため、この例ではKVキャッシュサイズを無視している。KVキャッシュサイズは、バッチサイズが小さく、シーケンス長が短いほど小さくなる。 MBUの値が100%に近いということは、推論システムが利用可能なメモリ帯域幅を有効に活用していることを意味する。 MBUは、異なる推論システム(ハードウェア+ソフトウェア)を正規化された方法で比較するのにも便利です。 MBUはPaLM論文で紹介されたMFU(Model Flops Utilization)を補完するもので、計算に制約のある環境で重要な指標である。
図1 、MBUをルーフラインプロットと同様のプロットで図解している。 オレンジ色の斜線部分の実線は、メモリ帯域幅が100%で完全に飽和した場合に可能な最大スループットを示している。 しかし実際には、バッチサイズが小さい場合(白い点)、観測されたパフォーマンスは最大値よりも低くなる。 バッチサイズが大きい場合(黄色の領域)、システムはコンピュートバウンドされ、ピーク可能スループットに対する達成スループットの割合がモデルフロップス利用率(MFU)として測定される。
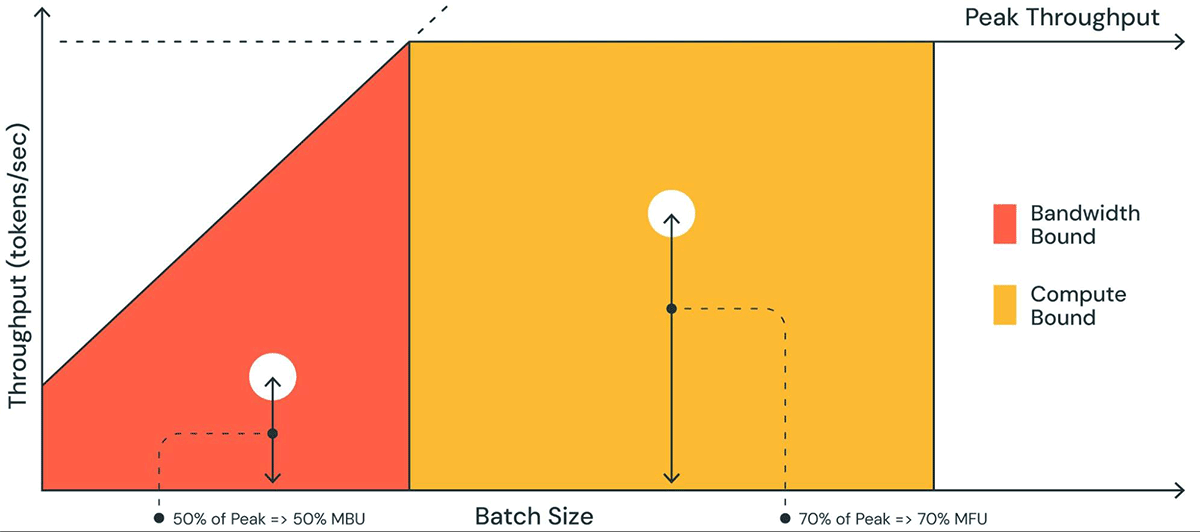
MBUとMFUは、与えられたハードウェア・セットアップにおいて、推論速度をさらに押し上げるためにどれだけの余裕があるかを決定する。 図2は、TensorRT-LLMベースの推論サーバで、テンソル並列度の異なるMBUを測定したものです。 メモリ帯域幅の使用率がピークに達するのは、連続した大きなメモリチャンクを転送するときである。 MPT-7Bのような小さなモデルが複数のGPUに分散されている場合、各GPUでより小さなメモリチャンクを移動しているため、MBUが低くなっていることがわかります。
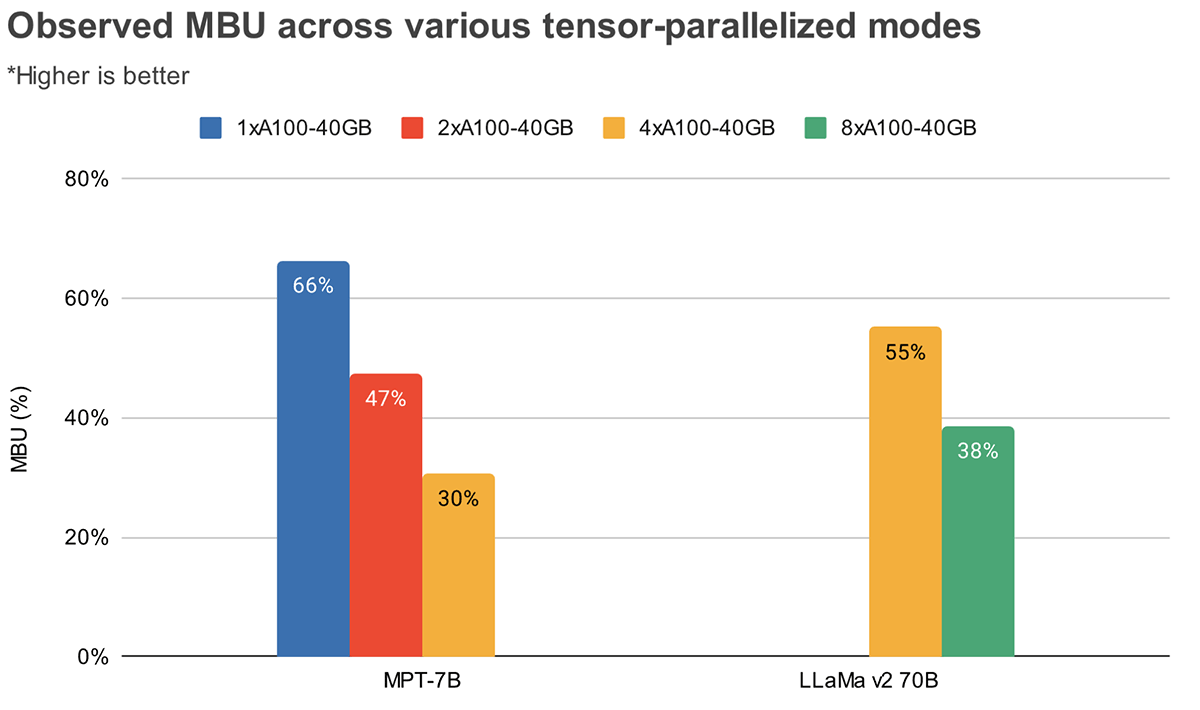
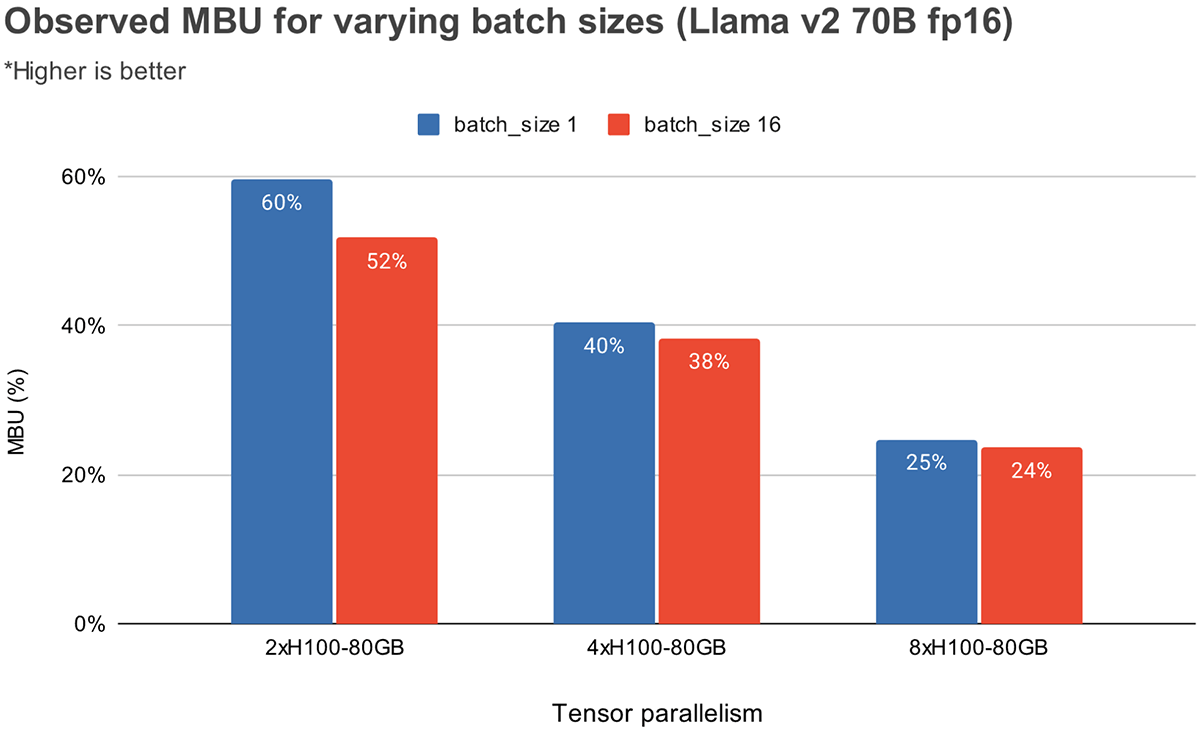
図 3 は、NVIDIA H100 GPU 上で、テンソル並列度とバッチサイズを変えて、経験的に観測された MBU を示しています。 MBUはバッチサイズが大きくなるにつれて減少する。 しかし、GPUの規模を拡大すると、MBUの相対的な減少はそれほど大きくなくなる。 また、より大きなメモリ帯域幅を持つハードウェアを選ぶことで、より少ないGPUでパフォーマンスを向上させることができることも注目に値する。 バッチサイズ1では、4xA100-40GB GPUでは55%であるのに対し、2xH100-80GB GPUでは60%という高いMBUを達成できます(図2)。
ベンチマーク結果
レイテンシー
MPT-7BとLlama2-70Bモデルについて、異なるテンソル並列度にわたって、最初のトークンまでの時間(TTFT)と出力トークンあたりの時間(TPOT)を測定した。 入力プロンプトが長くなるにつれて、最初のトークンを生成する時間が全体の待ち時間のかなりの部分を占めるようになる。 複数のGPUにまたがってテンソルを並列化することで、この待ち時間を短縮することができる。
モデルのトレーニングとは異なり、より多くのGPUにスケールアップすると、推論のレイテンシが大幅に減少します。 例えば、Llama2-70Bの場合、GPUを4倍から8倍にしても、小さいバッチサイズではレイテンシは0.7倍しか減少しない。 その理由のひとつは、並列度が高いほどMBUが低くなることだ(前述)。 もう1つの理由は、テンソル並列処理によってGPUノード間の通信オーバーヘッドが発生することだ。
| 最初のトークンまでの時間(ms) | ||||
|---|---|---|---|---|
| モデル | 1xA100-40GB | 2xA100-40GB | 4xA100-40GB | 8xA100-40GB |
| MPT-7B | 46 (1x) | 34 (0.73x) | 26 (0.56x) | - |
| ラマ2-70B | フィットしない | 154 (1x) | 114 (0.74x) |
Llama2 70Bのような大きなモデルは、メモリに収めるために少なくとも4xA100-40BのGPUを必要とする。
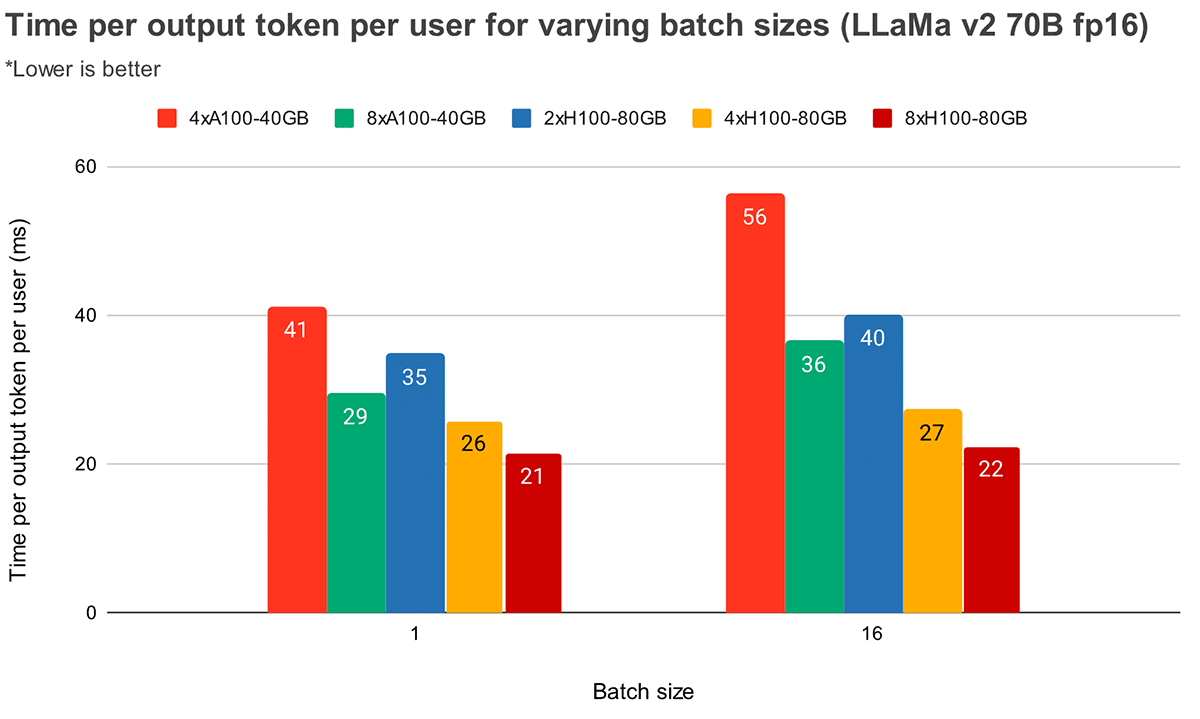
バッチサイズが大きくなると、テンソル並列度が高くなるため、トークン待ち時間が相対的に大きく減少する。 図4は、MPT-7Bにおける出力トークン1個あたりの時間の変化を示している。 バッチサイズ1では、2倍から4倍にすることでトークンのレイテンシは12%程度しか減少しない。 バッチサイズ16の場合、4xのレイテンシは2xのレイテンシより33%低い。 これは、バッチサイズ16のテンソル並列度が高いほど、バッチサイズ1に比べてMBUの相対的な減少が小さくなるという、先に述べた観測と一致する。
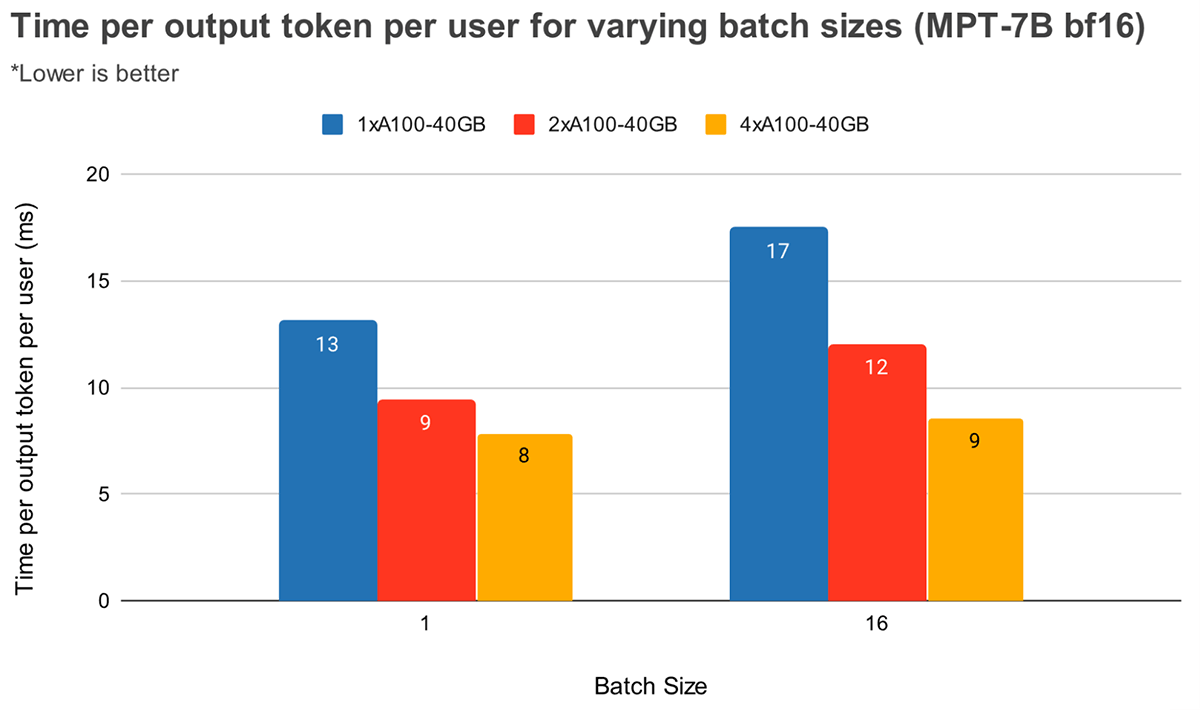
図5はLlama2-70Bの同様の結果を示しているが、4倍と8倍の間の相対的な改善はあまり顕著ではない。 また、2つの異なるハードウェアでGPUのスケーリングを比較した。 H100-80GBのGPUメモリ帯域幅はA100-40GBの2.15倍であるため、4xシステムではバッチサイズ1で36%、バッチサイズ16で52%レイテンシが低下していることがわかる。
スループット
リクエストをまとめてバッチ処理することで、スループットとトークンあたりの時間をトレードオフすることができる。 GPU評価中にクエリをグループ化すると、クエリを逐次処理するよりもスループットが向上しますが、各クエリの完了には(待ち行列の影響を無視して)時間がかかります。
推論要求をバッチ処理するための一般的なテクニックがいくつかある:
- 静的バッチ処理:クライアントが複数のプロンプトをリクエストにパックし、バッチ内のすべてのシーケンスが完了した後に応答が返される。 我々の推論サーバーはこれをサポートしているが、必須というわけではない。
- 動的バッチ処理:プロンプトはサーバー内でその場でバッチ処理される。 通常、この方法は静的バッチングよりも性能が悪いが、応答が短かったり、長さが均一であれば、最適に近い結果を得ることができる。 リクエストのパラメータが異なる場合はうまく動作しない。
- 連続バッチ処理:要求が到着したときにまとめてバッチ処理するというアイデアは、この優れた論文で紹介され、現在SOTAの手法となっている。 バッチ内のすべてのシーケンスが終了するのを待つ代わりに、反復レベルでシーケンスをグループ化する。 ダイナミックバッチングの10倍から20倍のスループットを達成できる。
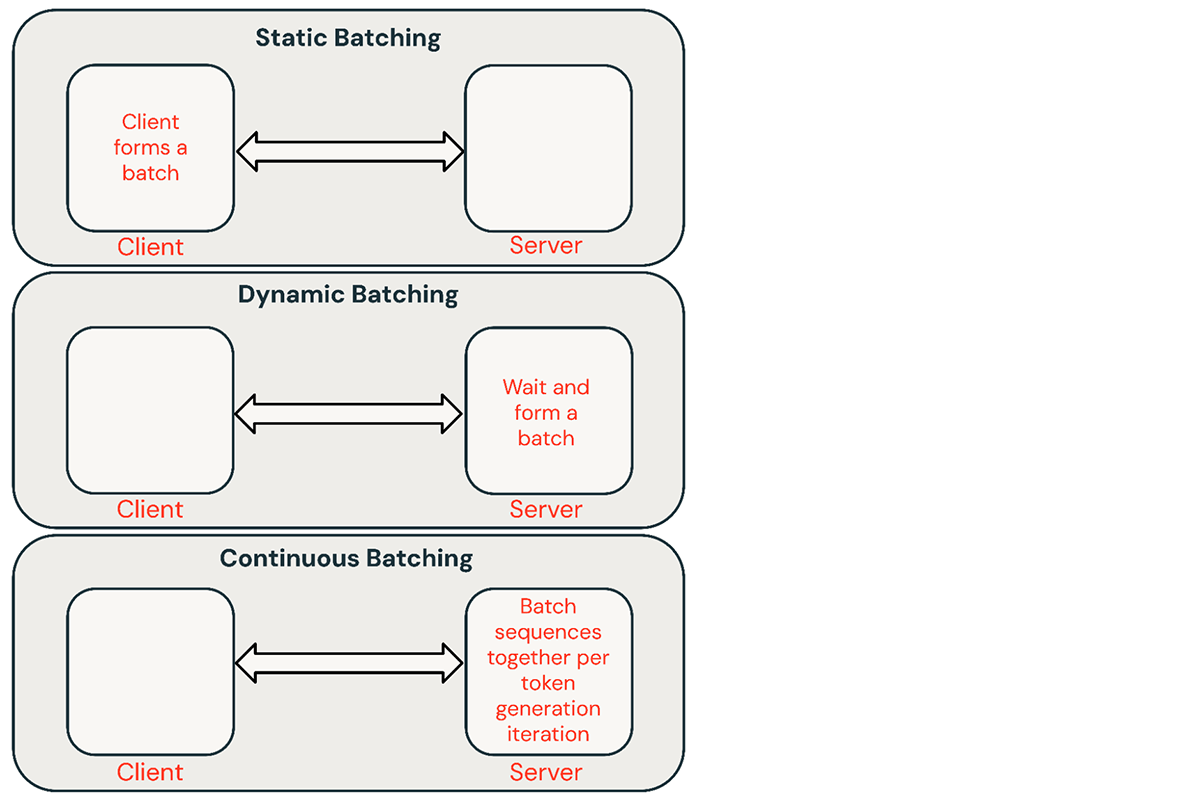
共有サービスでは通常、継続的バッチ処理が最適なアプローチだが、他の2つの方が良い場合もある。 低QPS環境では、ダイナミックバッチングは連続バッチングを上回ることができる。 より単純なバッチフレームワークで低レベルのGPU最適化を実装する方が簡単な場合もある。 オフラインのバッチ推論ワークロードの場合、静的バッチ処理によって大幅なオーバーヘッドを回避し、より優れたスループットを達成することができる。
バッチサイズ
バッチングがうまく機能するかどうかは、リクエストストリームに大きく依存する。 しかし、一様リクエストによる静的バッチングをベンチマークすることで、その性能の上限を知ることができる。
| バッチサイズ | |||||||
|---|---|---|---|---|---|---|---|
| ハードウェア | 1 | 4 | 8 | 16 時間 | 32 | 64 | 128 |
| 1 x A10 | 0.4 (1x) | 1.4 (3.5x) | 2.3 (6x) | 3.5 (9x) | OOM(メモリ不足)エラー | ||
| 2 x A10 | 0.8 | 2.5 | 4.0 | 7.0 | 8.0 | ||
| 1 x A100 | 0.9 (1x) | 3.2 (3.5x) | 5.3 (6x) | 8.0 (9x) | 10.5 (12x) | 12.5 (14x) | |
| 2 x A100 | 1.3 | 3.0 | 5.5 | 9.5 | 14.5 | 17.0 | 22.0 |
| 4 x A100 | 1.7 | 6.2 | 11.5 | 18.0 | 25.0 | 33.0 | 36.5 |
表2:静的バッチ処理とFasterTransformersベースのバックエンドを使用したMPT-7Bのピークスループット(req/sec)。 リクエスト:512の入力トークンと64の出力トークン。 より大きな入力の場合、OOMの境界はより小さなバッチサイズになる。
レイテンシーのトレードオフ
リクエストの待ち時間はバッチサイズとともに増加する。 例えば、NVIDIA A100 GPUを1つ使って、バッチサイズを64にしてスループットを最大化すると、スループットが14倍になる一方で、レイテンシは4倍になる。 共有推論サービスは通常、バランスのとれたバッチサイズを選ぶ。 独自のモデルをホスティングしているユーザーは、アプリケーションに適したレイテンシとスループットのトレードオフを決定する必要がある。 チャットボットのようなアプリケーションでは、高速応答のための低遅延が最優先される。 構造化されていないPDFのバッチ処理のような他のアプリケーションでは、個々のドキュメントを処理する待ち時間を犠牲にして、すべてのドキュメントを並列に高速処理したいと思うかもしれません。
図7は、7Bモデルのスループット対レイテンシ曲線を示している。 この曲線上の各線は、バッチサイズを1から256まで増加させることで得られる。 これは、さまざまな待ち時間の制約のもとで、どの程度のバッチサイズを作ることができるかを決定するのに役立つ。 上記のルーフラインプロットを思い起こすと、これらの測定値は我々が期待するものと一致していることがわかる。 あるバッチサイズを超えると、つまり、コンピュート・バウンド・レジーム(compute bound regime)を超えると、バッチサイズが2倍になるたびに、スループットは向上せずにレイテンシが増加するだけである。
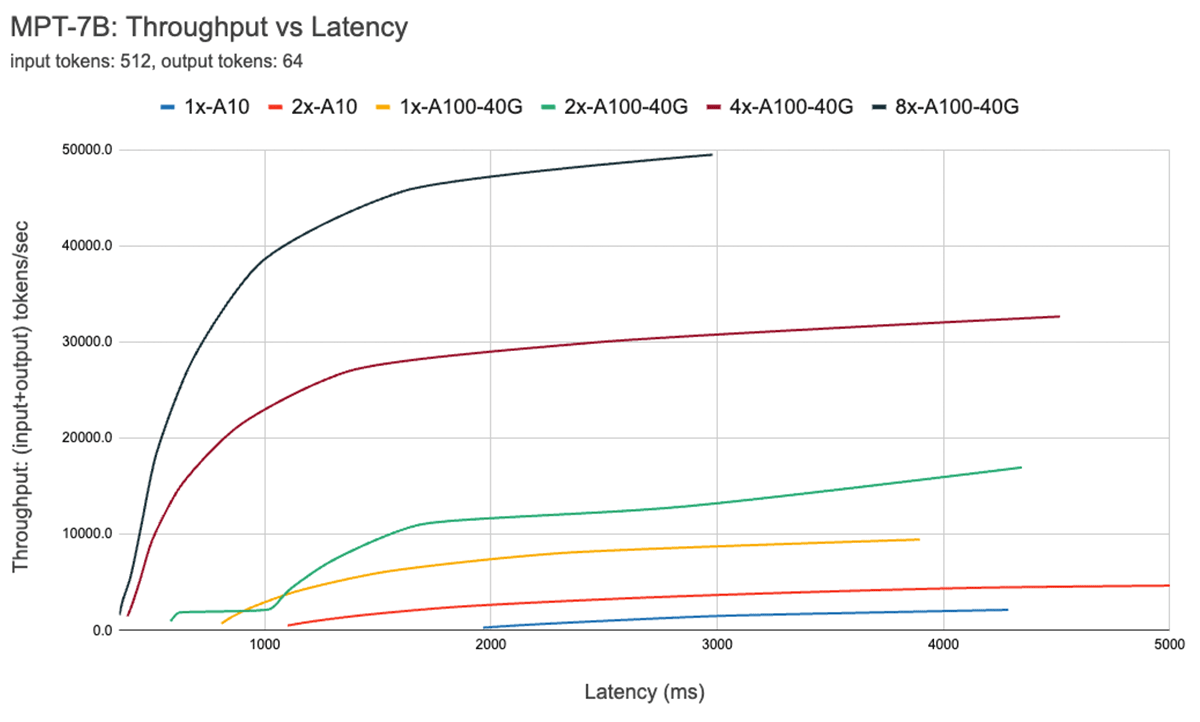
並列処理を使用する場合、低レベルのハードウェアの詳細を理解することが重要である。 例えば、すべての8xA100インスタンスが異なるクラウド間で同じとは限らない。 すべてのGPU間を高帯域幅で接続するサーバーもあれば、GPUをペアにしてペア間の接続を低帯域幅にするサーバーもあります。 これがボトルネックとなり、実際のパフォーマンスが上記の曲線から大きく乖離してしまう可能性がある。
最適化のケーススタディ量子化
量子化は、LLM推論に必要なハードウェアを減らすためによく使われる手法だ。 推論中のモデルの�重みとアクティベーションの精度を下げることで、ハードウェアの要件を劇的に減らすことができる。 例えば、16ビットのウェイトを8ビットのウェイトに切り替えることで、メモリに制約のある環境(例えば、以下のような環境)で必要なGPUの数を半減させることができる。 A100sのLlama2-70B)。 重みを4ビットに落とすことで、民生用ハードウェアで推論を実行することが可能になる(例. MacbookではLlama2-70B)。
私たちの経験では、量子化は慎重に行うべきである。 ナイーブな量子化技術は、モデルの質を大幅に低下させる可能性がある。 量子化の影響もモデル・アーキテクチャによって異なる(例えば、以下のような)。 MPT対ラマ)とサイズ。 これについては、今後のブログ記事で詳しく紹介する予定だ。
量子化のようなテクニックを試す際には、モデル単体の品質だけでなく、 推論システムの 品質を評価するために、 Mosaic Eval Gauntletの ようなLLM品質ベンチマークを使用することをお勧めします。さらに、システムの最適化をより深く追求することも重要だ。 特に、量子化はKVキャッシュをより効率的にすることができる。
前述したように、自己回帰的トークン生成では、注意層からの過去のキー/値(KV)は、ステップごとに再計算する代わりにキャッシュされる。 KVキャッシュのサイズは、一度に処理されるシーケンス数とシーケンスの長さによって変化する。 さらに、次のトークン生成��の各反復中に、新しいKVアイテムが既存のキャッシュに追加され、新しいトークンが生成されるにつれてキャッシュが大きくなる。 したがって、これらの新しい値を追加する際の効果的なKVキャッシュメモリ管理は、優れた推論パフォーマンスにとって非常に重要である。 Llama2のモデルは、Grouped Query Attention (GQA)と呼ばれるアテンションの変種を使用している。 なお、KVヘッド数が1の場合、GQAはマルチクエリーアテンション(MQA)と同じである。 GQAは、キー/バリューを共有することで、KVキャッシュのサイズを抑えるのに役立つ。 KVキャッシュ・サイズの計算式は以下の通り。
batch_size * seqlen * (d_model/n_heads) * n_layers * 2 (KおよびV) * 2 (Float16あたりのバイト数) * n_kv_heads
表3は、1024トークンのシーケンス長で、異なるバッチサイズで計算されたGQA KVキャッシュサイズを示している。 これに対してLlama2モデルのパラメータサイズは、70Bモデルで140GB(Float16)。 KVキャッシュの量子化は、(GQA/MQAに加えて)KVキャッシュのサイズを縮小するもう一つの技術であり、我々はその生成品質への影響を積極的に評価している。
| バッチサイズ | GQA KVキャッシュメモリ(FP16) | GQA KVキャッシュメモリ(Int8) |
|---|---|---|
| 1 | .312ギガバイト | 156ギガバイト |
| 16 時間 | 5ギガバイト | 2.5ギガバイト |
| 32 | 10ギガバイト | 5ギガバイト |
| 64 | 20ギガバイト | 10ギガバイト |
表3:Llama-2-70BのKVキャッシュサイズ(シーケンス長1024の場合
前述したように、低バッチサイズでのLLMによるトークン生成は、GPUメモリの帯域幅に縛られる問題です。つまり、生成速度は、モデルパラメータをGPUメモリからオンチップキャッシュにどれだけ速く移動できるかに依存します。 モデルの重みをFP16(2バイト)からINT8(1バイト)またはINT4(0.5バイト)に変換すると、移動するデータが少なくて済むため、トークン生成を高速化できる。 しかし、量子化はモデル生成の品質に悪影響を与える可能性がある。 現在、Model Gauntletを使ってモデル品質への影響を評価しており、近日中にフォローアップのブログ記事を発表する予定です。
結論と主な結果
上記で説明した各要因は、モデルの構築と展開の方法に影響を与えます。 私たちは、ハードウェアの種類、ソフトウェアスタック、モデルアーキテクチャ、典型的な使用パターンを考慮したデータ駆動型の決定を下すために、これらの結果を使用しています。 以下は、私たちの経験から導き出された推奨事項である。
最適化のターゲットを特定する:インタラクティブなパフォーマンスを重視しますか? スループットの最大化? コストの最小化? ここには予想できるトレードオフがある。
レイテンシの構成要素に注意を払うこと:インタラクティブなアプリケーションでは、time-to-first-tokenがサービスの応答性を決定し、time-per-output-tokenがサービスの速さを決定します。
メモリ帯域幅が鍵となる:最初のトークンの生成は通常、計算バウンドであり、その後のデコードはメモ�リバウンドオペレーションである。 LLM推論はメモリに制約のある環境で動作することが多いため、MBUは最適化するのに有効な指標であり、推論システムの効率を比較するのに用いることができる。
バッチ処理が重要複数のリクエストを同時に処理することは、高いスループットを達成し、高価なGPUを効果的に利用するために不可欠です。 一方、オフラインのバッチ推論ワークロードは、より単純なバッチ技術で高いスループットを達成することができる。
深い最適化:標準的な推論最適化テクニックは重要である(例. 演算子の融合、重みの量子化)をLLMに適用しているが、より深いシステム最適化、特にメモリ使用率を向上させる最適化を探求することが重要である。 その一例がKVキャッシュの量子化だ。
ハードウェア構成:モデルの種類と予想される作業負荷から、導入ハードウェアを決定する。 例えば、複数のGPUにスケーリングする場合、MBUはMPT-7Bのような小さなモデルの方が、Llama2-70Bのような大きなモデルよりもはるかに急速に低下する。 また、テンソル並列度が高いほど、性能はサブリニアにスケールする傾向がある。 とはいえ、トラフィックが多い場合や、ユーザーが低レイテンシーに割増料金を支払ってもいいと考える場合には、小規模なモデルでも高度なテンソル並列処理が意味を持つかもしれない。
データ主導の意思決定理論を理解することは重要ですが、常にエンド・ツー・エンドのサーバー・パフォーマンスを測定することをお勧めします。 推論展開のパフォーマンスが予想以上に悪くなる理由はたくさんある�。 ソフトウェアの非効率性により、MBUが予想外に低くなる可能性がある。 あるいは、クラウドプロバイダー間のハードウェアの違いが、驚きにつながる可能性もある(2つのクラウドプロバイダーの8xA100サーバー間で、2倍のレイテンシの違いがあることが確認されている)。
LLM推論を始めるには、Databricks Model Servingをお試しください。 詳しくはドキュメントをご覧ください。