過去 1 年間、業界レベルのLLMテクノロジーの世界をフォローしてきた方なら、本番運用におけるフレームワークやツールの多さに気付いているでしょう。スタートアップ企業は、検索拡張生成(RAG)の自動化からカスタムファインチューニングまで、多様なLLM関連サービスを次々に開発しています。Langchainは、おそらくこれらすべての新しいフレームワークの中で最も有名で、2023 年春以降、連鎖言語モデル コンポーネントの簡単なプロトタイプ作成を可能にしています。ただし、最近の重要な開発は、スタートアップ企業からではなく、学術界から生まれました。
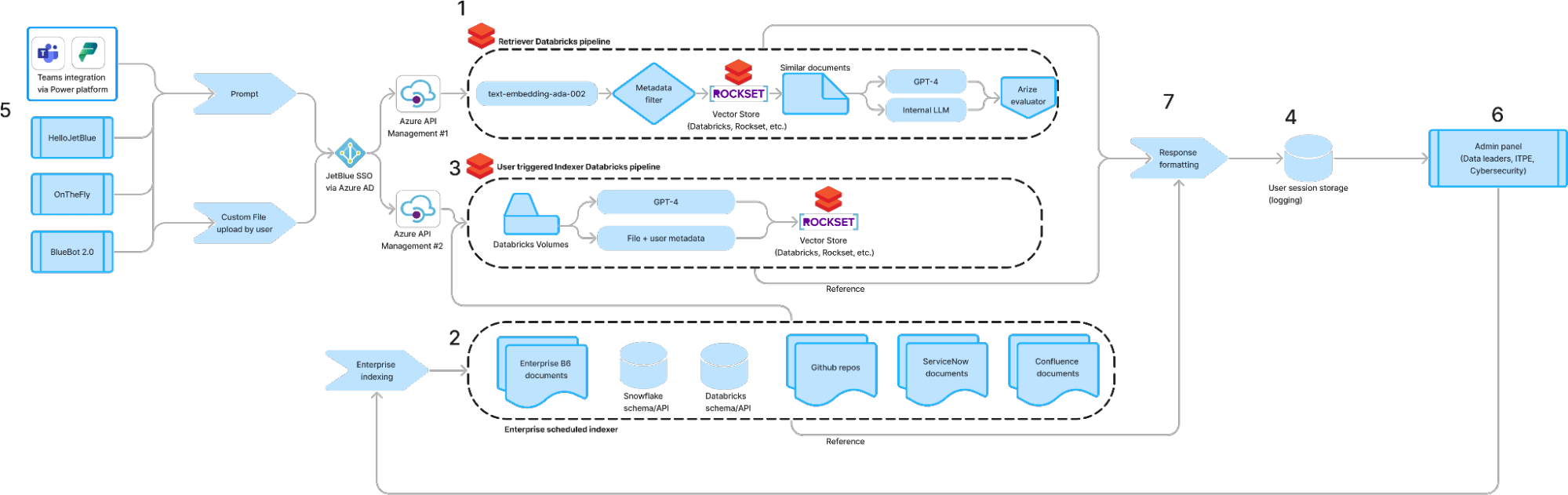
2023年10月、Databricksの共同創設者であるMatei Zahariaのスタンフォード研究室の研究者たちが、宣言型の言語モデルコールを自己改善型パイプラインにコンパイルするためのライブラリであるDSPyを発表しました。DSPyの主要な要素は自己改善型パイプラインです。例えば、ChatGPTは単一の入出力モデルに見えますが、実際は複数のツールと連携するマルチステップのパイプラインとして動作しています。代わりに、モデルはウェブブラウジングやカスタムドキュメントのアップロードからのRAG(Retrieval-Augmented Generation)などの外部ツールと連携し、複数段階のパイプラインで動作しています。これらのツールは中間出力を生成し、それを初期入力と組み合わせて最終的な答えを出します。データパイプラインや機械学習モデルがMLOpsの登場につながったように、LLMOpsはDSPyのLLMパイプラインとDBRXのような基盤モデルのフレームワークによって形作られています。
DSPyが真価を発揮するのは、これらのパイプラインの自己改善にあります。複雑で多段��階のLLMパイプラインでは、チューニングが必要な複数のプロンプトが存在することがよくあります。業界のLLM開発者たちは、プロンプト内の単語一つがデプロイの成否を左右することに非常に慣れています(図1)。しかし、DSPyを使用することで、JJetBlueは手動でのプロンプトチューニングを過去のものとしています。
このブログ記事では、DSPyで利用可能なDatabricks Marketplaceモデルを使用してカスタムのマルチツールLLMエージェントを構築し、結果として得られるチェーンをDatabricks Model Servingにデプロイする方法について説明します。このエンドツーエンドのフレームワークにより、JetBlueは収益を生み出す顧客フィードバックの分類から、RAGを活用した予測メンテナンスチャットボットによる運用効率の向上まで、最先端のLLMソリューションを迅速に開発できるようになりました。
図1: DSPy以前の一般的なプロンプトエンジニアリング手法
DSPy シグネチャとモジュール
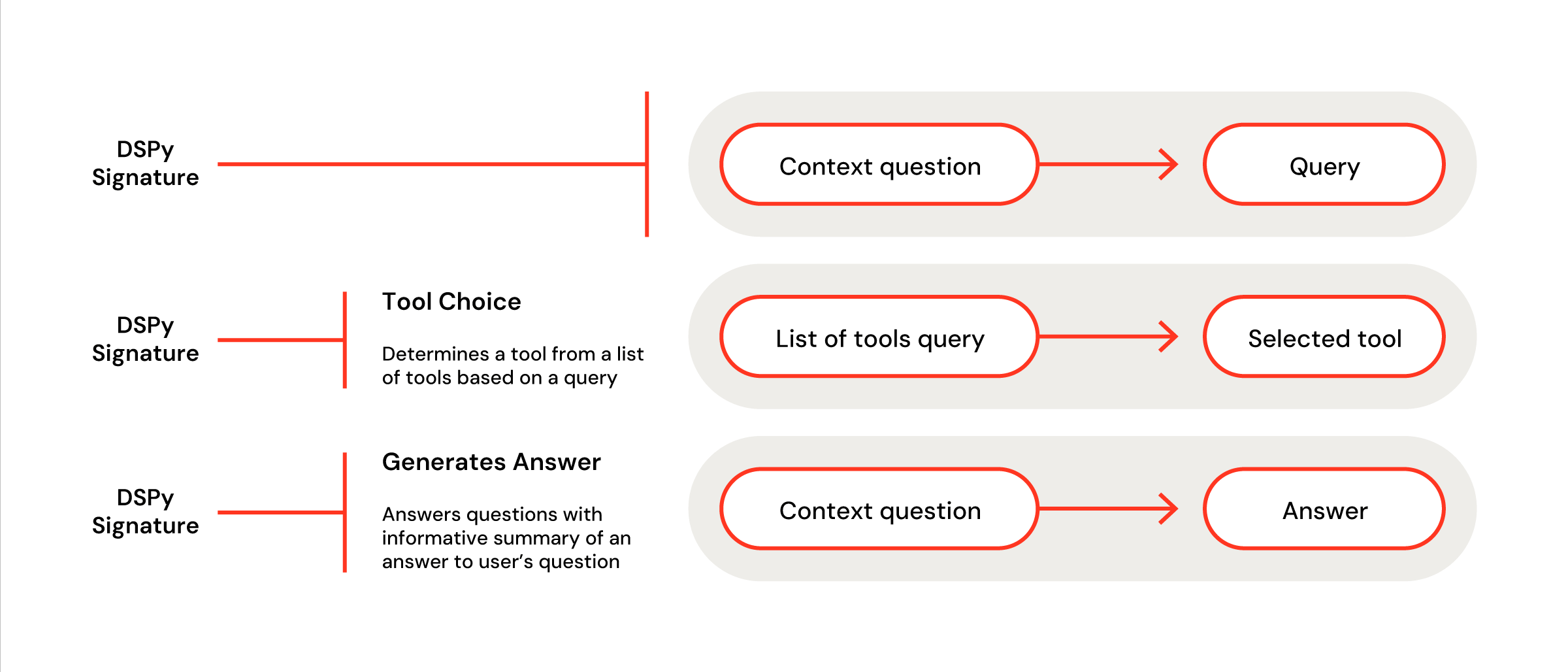
すべての特注DSPyモデルの背後には、カスタムシグネチャとモジュールがあります。ここでのシグネチャとは、パイプライン内のカスタマイズされた単一のLLMコールのことを指します。一般的な最初のシグネチャは、初期のユーザーの質問を事前定義されたコンテキストを使用してクエリに再フォーマットすることです。これは、次の一行で表現できます: dspy.ChainOfThought("context, question -> query")。もう少しコントロールが必要な場合、このコンポーネントをPython的なクラスとして定義することもできます(図2)。カスタムシグネチャの書き方に慣れてしまえば、柔軟に複雑なパイプラインを設計できます。
図3: DSPy パイプラインの開始時にツールを選択し、終了時に最終的な回答を生成するための説明付きのカスタム署名
これらのシグネチャは、PyTorchのようなモジュールに組み込まれます(図3)。各シグネチャはモデルのforwardメソッド内でアクセスされ、入力が一つのステップから次のステップへと順次渡されます。このプロセスには、LLMを呼び出さないメソッドや制御ロジックを挿入することもできます。DSPyモジュールにより、LLMOpsを最適化してより良いコントロール、動的な更新、そしてコストの改善が可能になります。不透明なエージェントに依存するのではなく、内部コンポーネントがモジュール化されているため、各ステップが明確で評価や修正が容易です。この場合、ユーザー入力から生成されたクエリを取り、必要に応じてベクトルストアを使用し、取得したコンテキストから回答を生成します。
図4: DSPyシグネチャはPyTorchのようなモジュールを介してパイプラインに組み込まれます
エージェントのデプロイ
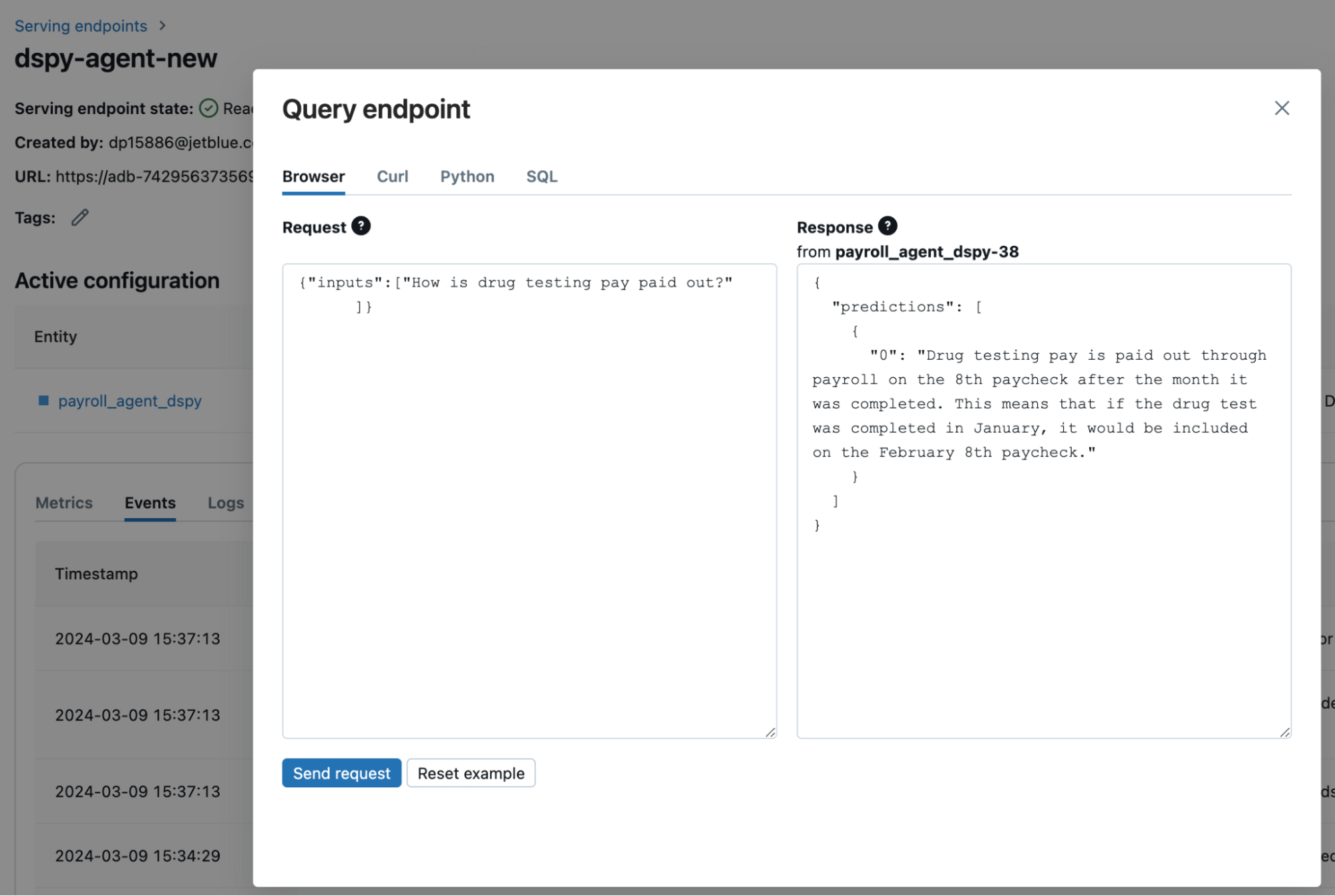
私たちは、作成したモジュールの上にPyFuncラッパーを使用することで、MLflow PyFuncモデルのログ作成とデプロイの標準手順に従うことができます。PyFuncモデル内で、DSPyを簡単に設定して、Databricks MarketplaceのLlama 2 70Bのようなモデルを使用することができます。Databricks Model ServingはDataFrame形式を期待する一方で、DSPyは文字列を扱っていることに注意が必要です。そのため、標準のpredictおよびrun関数を以下のように修正します:
図5: DSPyとMLflow間の変換に必要なPyFuncモデルサービング定義の変更
モデルは mlflow.pyfunc.log_model 関数を使用して作成され、Databricksのチュートリアルで説明されている手順に従ってJetBlueの内部サービングエンドポイントの1つにデプロイされます。エンドポイントへのクエリをDatabricks経由で行う方法(図5)や、APIを介してエンドポイントを呼び出す方法を見ることができます。私たちはチャットボットのためのアプリケーションレイヤーを通じてエンドポイントAPIを呼び出します。RAGチャットボットのデプロイ��は、Langchainのデプロイよりも2倍高速でした。
パイプラインの自己改善
JetBlueのRAGチャットボットのユースケースでは、検索品質と回答品質に関連するメトリクスがあります。DSPyを導入する前は、これらのメトリクスを改善するために手動でプロンプトを最適化していましたが、現在ではDSPyを使用してこれらのメトリクスを直接最適化し、品質を自動的に向上させることができます。これを理解する鍵は、パイプラインの自然言語コンポーネントを調整可能なパラメータと見なすことです。DSPyのオプティマイザーは、タスクの目標を最大化することでこれらの重みを調整し、定義されたメトリクス(例えば、毒性を評価するLLM-as-a-judge)やラベル付きまたはラベルなしのデータ、そして最適化のためのDSPyプログラムを使用するだけで済みます。オプティマイザーはプログラムをシミュレートし、LMの重みを調整して下流のメトリクスのパフォーマンス品質を向上させるための「最適な」例を特定します。DSPyはシグネチャオプティマイザーと、最適化された例をプロンプトの一部としてモデルに提供する複数のコンテキスト内学習オプティマイザーを提供します。DSPyは、コンテキスト内で使用�する例を効果的に選択し、LLMの応答の信頼性と品質を向上させます。
DSPyは、Databricks Model Serving Foundation Model APIおよびDatabricks Vector Searchと統合されており、ユーザーはDatabricksのワークフロー内でDSPyプロンプティングシステムを作成し、データとタスクを最適化することができます。
さらに、これらの機能はDatabricksのLLM-as-a-judgeオファリングを補完します。カスタムメトリクスはLLM-as-a-judgeを使用して設計され、DSPyのオプティマイザーを使用して直接改善することができます。例えば、顧客フィードバックの分類といったユースケースでは、LLMが生成したフィードバックを使用してDatabricks内でマルチステージのDSPyパイプラインを微調整することを期待しています。これにより、すべてのLLMアプリケーションの反復開発プロセスが劇的に簡素化され、プロンプトの手動反復が不要になります。
プロンプティングの終焉、複合システムの始まり
より多くの企業がLLMを活用するにつれて、汎用的なチャットボットインターフェースの限界がますます明らかになっています。これらの市販プラットフォームは、エンドユーザーや管理者のコントロール外のパラメータに大きく依存しています。LLMコールと従来のソフトウェア開発を組み合わせた複合システムを構築することで、企業は簡単にこれらのソリューションをユースケースに適応させ、最適化することができます。DSPyは、任意のメトリクスに対して最適化できるモジュール化された信頼性の高いLLMシステムへのパラダイムシフトを促進しています。DatabricksとDSPyの力を借りて、JetBlueはより優れたLLMソリューションを大規模に展開し、可能性の限界��を押し広げることができます。