ロールスロイスの画像生成に Databricks Mosaic AI のパワーを活用する
ロールス・ロイスは、様々なAIプロジェクトにおいてDatabricksデータインテリジェンスプラットフォームの変革的な力を目の当たりにしてきました。その一例として、ロールス・ロイスとDatabricksの協力プロジェクトがあります。このプロジェクトは条件付き敵対的生成ネットワーク(cGAN)の学習プロセスの最適化に焦点を当てており、Databricks Mosaic AIツールを使用することの多くの利点を実証しています。
このcGAN学習最適化の共同プロジェクトでは、チームは数値、テキスト、画像データの使用を検討しました。主な目標は、ロールス・ロイスの設計空間探索能力を向上させ、パラメトリックモデルの限界を克服することでした。これは、従来の形状モデリングとシミュレーションプロセスを必要とせずに、特定の設計条件を満たす革新的な設計コンセプトの識別と評価を推進するために、過去のシミュレーションデータを再利用できるようにすることで達成されました。
ビデオを見る:ロールスロイスがクラウドベースの生成AI を使用して予備的なエンジニアリング設計をサポートする方法
Databricksとロールス・ロイスの共同チームは、次元制限の考慮を含むモデル構成のベスト プラクティスを調査しました。 このアプローチには、ニューラル ネットワークが特定の領域を回避し、より迅速にソ��リューションを見つけられるように、失敗したソリューションの知識をトレーニング データセットに埋め込むことが含まれていました。 このプロジェクトのもう一つの側面は、設計プロセスにおける多目的制約の処理であり、このプロジェクトでは、例えば、モデルの重量を減らしながら効率を高めようとするなど、競合する可能性のある複数の要件に取り組んでいました。 目標は、設計の特定の側面に対して最適化するだけでなく、広範囲にわたって最適化されたソリューションを生み出すことでした。
MLOps のビッグブック

cGAN プロジェクトの概念アーキテクチャは、以下のとおりです。
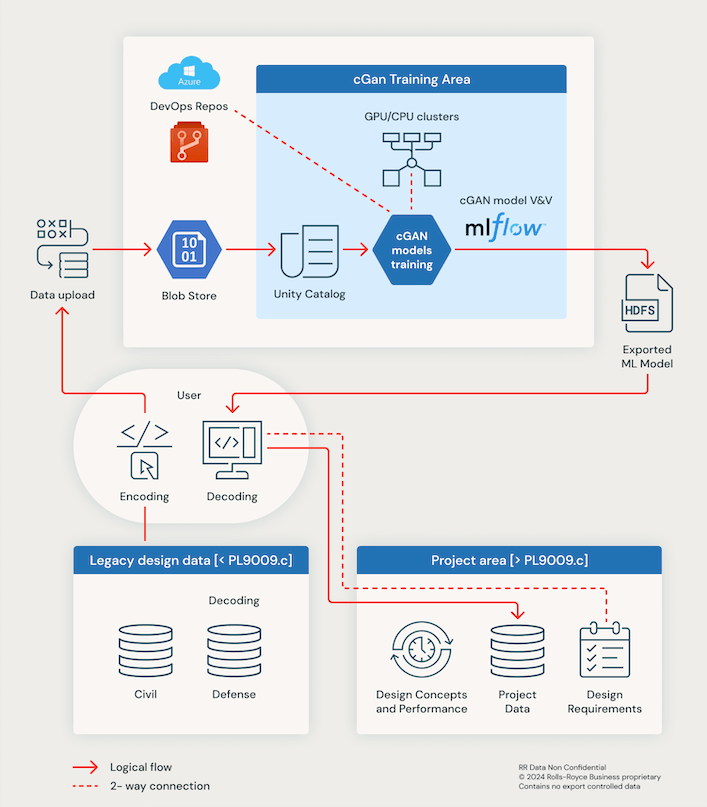
概念アーキテクチャの説明:
- データモデリング: データテーブルは、特定のユースケースに合わせて最適化されるように設定されます。 これには、ID 列の生成、テーブル プロパティの設定、一意のタプルの管理が含まれます。
- 3D モデルのトレーニング: 3D モデルは当社のデータ セットを使用してトレーニングされます。 これには、ニューラル ネットワークが特定の領域を回避し、より早くソリューションを見つけられるように、失敗したソリューションの知識を埋め込むことが含まれます。
- 実装:モデルとアルゴリズムを開発して最適化したら、それを製品設計プロセスに実装します。
- 最適化:現在の結果に基づいて、問題を調整し、データセットを改良し、最終的には多目的制約を処理するアプローチを変更することで、モデルとアルゴリズムを継続的に最適化する予定です。
- 次のステップ:今後、多目的制約を処理するメカニズムを組み込む予定です。互いに矛盾する可能性のある複数の要件を処理する必要があります。これには、これらの相反する目的のバランスをとり、最適なソリューションに到達するためのアルゴリズムまたは方法の開発が含まれます。
このプロジェクトで Databricks データ インテリジェンス プラットフォームと Databricks Mosaic AI ツールを活用したことで、ロールス ロイスには多くのメリットがもたらされました。
- 総所有コスト (TCO): Databricks 、コストを大幅に削減しながらイノベーションを加速する統合レイクハウス プラットフォームを提供します。データのニーズが急激に増加する中、 Databricksデータ処理のためのコスト効率の高いソリューションです。これは、ロールスロイスのような企業の大規模プロジェクトに特に有益です。
- モデル化までの時間の短縮: Databricks Mosaic AI ツールは、モデルのトレーニングと展開の複雑さを軽減し、モデル化までの時間を短縮します。これは、ML 開発を自動化し、ML モデルのライフサイクル全体を管理するAutoMLやManaged MLflowなどの機能によって実現されます。
- 実験からデプロイへ: Databricks 、実験からデプロイへのシームレスな移行を提供します。エクスペリメントから本番運用のデプロイメントに移行するのは困難な場合があるため、これは非常に重要です。
- モデル精度の向上: Databricksの使用により、並列ハイパーメトリック チューニングの分散コンピューティングによって、約 30 分の 1 という大幅な時間短縮が実現しました。これにより、プロセスが高速化されるだけでなく、モデルの精度も向上します。
- データ管理 / ガバナンスの利点: Databricksデータ インテリジェンス プラットフォームは、モデルとデータの両方を完全に制御します。このレベルの制御は、航空宇宙などのコンプライアンス中心の業界にとって非常に重要です。 Unity Catalogの実装により、重要なガバナンス フレームワークが確立され、すべてのデータ資産の統合ビューが提供され、機密データへのアクセスの管理と制御が容易になります。
- モデルから得られる知識: MLflowへのDatabricks AIの統合により、あらゆる プロジェクトの重要な要素である透明性と再現性が確保されます。これにより、効率的なエクスペリメントの追跡、結果の共有、および共同モデルのチューニングが可能になります。これらの知識は、ビジネスの革新を推進し、生産性を向上させる上で非常に貴重です。
結論として、Databricks は、イメージ genAI プロジェクトを実装するための堅牢で効率的かつ安全なプラットフォームを提供します。 ロールス・ロイス社とDatabricksのコラボレーションは、この新しいテクノロジーの変革力を実証しました。 今後の作業には、エンジンの3次元性を考慮した2Dモデルから3Dモデルへの移行を探ることが含まれます。