
量子化(クオンタイズ)とは、機械学習モデルをより小さく、より高速にするためのテクニックです。Llama2-70B-Chatを量子化し、1秒間に2.2倍のトークンを生成する同等の品質のモデルを作成しました。
言語モデルが大きくなればなるほど、クエリにかかる時間は遅くなり(コストも高くなり)、GPUはより多くのパラメータをメモリからロードし、より多くの計算を実行しなければなりません。私たちのチームは、LLMのパフォーマンスを最適化するために数多くのテクニックを開発し、採用してきました。このブログポストでは、メモリフットプリントを減らし、より高速に実行するためにモデルの数値精度を下げる一般的なテクニックである量子化について説明します。Llama2-70B-ChatのようなLLMに量子化を適用すると、完全な16ビット精度で実行した場合と比較して、1秒あたり2.2倍のトークンを生成するモデルになります。重要なことは、モデルの品質が維持されていることを保証するために、量子化されたモデルをGauntletモデル評価スイートの数十のベンチマークで厳密にテストすることです。
量子化についての入門書
最近のLLMは、主に16ビット精度で学習されます。モデルが訓練されると、実務家はモデルの重みを低精度に量子化し、モデルの保存や計算の実行に必要なビット数を減らして推論を高速化することがよくあります。モデルの構成要素の1つ以上を量子化することができます:
- モデルのパラメータ(重み)
- キー・バリュー(KV)キャッシュ:これはアテンション・キーと値に関連する状態であり、出力トークンを順次生成する際に繰り返しの計算を減らすために保存されます
- アクティベーション:これらはモデルの各層の出力で、次の層の入力として使用されます。 アクティブ度を量子化すると、実際の計算(行列の乗算など)を低精度で行うことになります
量子化は、より小さく高速なモデルを生成します。モデルのサイズを小さくすることで、GPUメモリの使用量を少なくしたり、最大バッチサイズを大きくしたりすることができます。モデルが小さければ、メモリから重みを移動するのに必要なバンド幅も小さくなります。これは、帯域幅が制限される低バッチサイズでは特に重要で す。低バッチ設定では、ロードされるモデルのバイトあたりの演算数が少ないため、モデルの重みのサイズがボトルネックとなります。さらに、アクティブ化を量子化すれば、高速な低精度演算のハードウェアサポートを利用できます:NVIDIA A100 および H100 Tensor Core GPU は、8ビット整数 (INT8) 演算を 16 ビット浮動小数点演算よりも 2 倍高速に実行できます。H100 Tensor Core GPUは、8ビット整数演算と同じ速度で 8ビット 浮動小数点 (FP8)演算を サポートするTransformer Engineを備えて います。 LLM推論の課題については 、 このトピックに関する以前のブログを参照してください 。
この研究では、2つの異なる量子化�セットアップについて説明します:
- INT8ウェイト+KVキャッシュ量子化:このセットアップでは、モデルの重みとKVキャッシュは減りますが、アクティベーションは16ビットのままです。
- FP8:重み、KVキャッシュ、アクティベーションはすべて8ビットの浮動小数点値になります。 8ビット浮動小数点演算は、NVIDIA H100 Tensor Core GPUでのみサポートされており、NVIDIA A100 Tensor Core GPUではサポートされていません。
整数と浮動小数点の量子化
INT8とFP8の違いは何ですか?
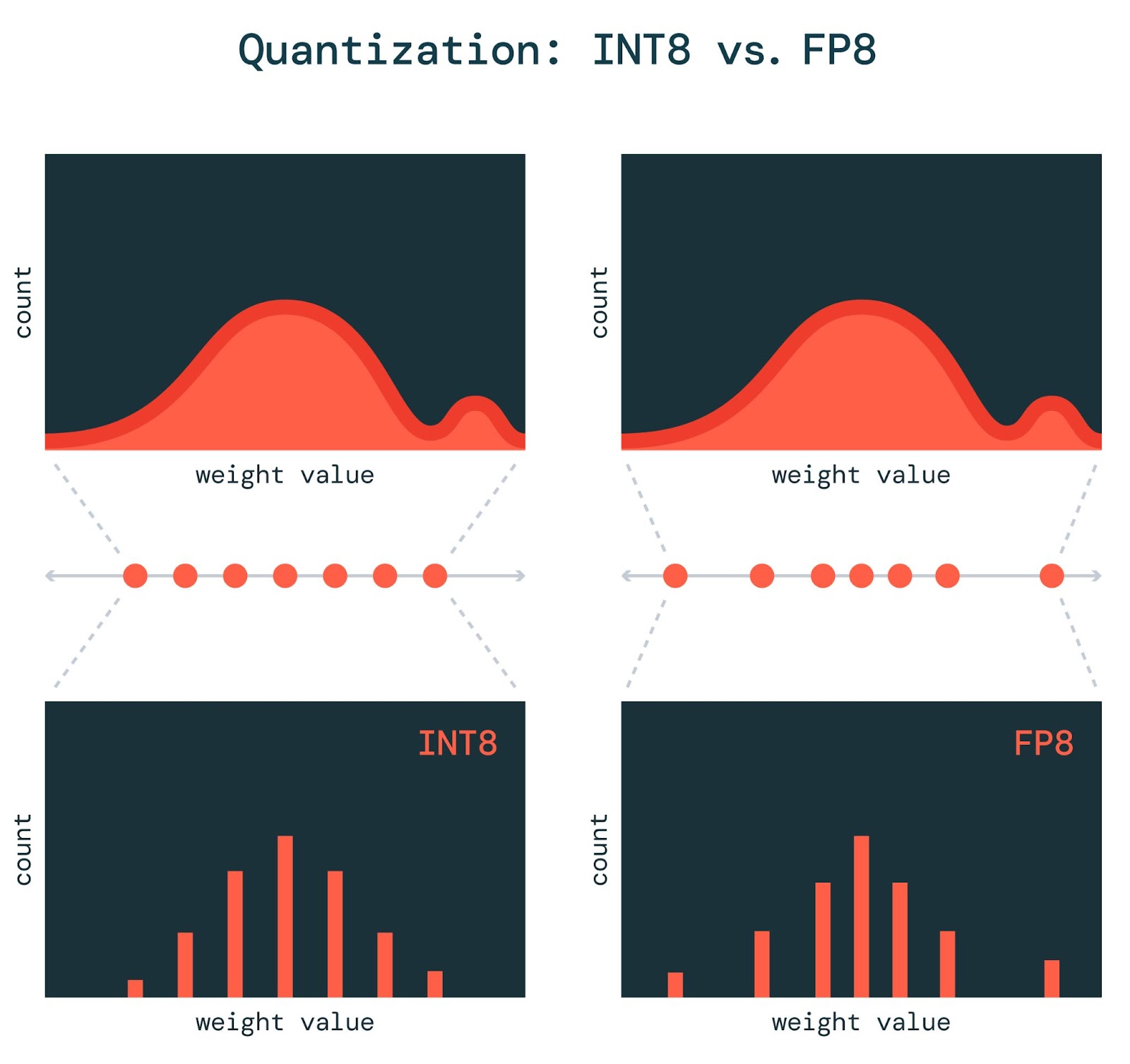
図1: 整数量子化と比較して、FP8量子化は分布の中央付近の重みに対してより小さな誤差を生成します。これは、整数数値フォーマットが数値の一様分布を表すのに対し、浮動小数点数値はべき乗則分布を表すためです。また、浮動小数点フォーマットはダイナミック・レンジが大きいため、外れ値の誤差も小さくなります。
INT8量子化では、モデルのパラメータにスケーリングファクタを乗じ、ゼロを中心に上下にシフトさせた後、これらの値をINT8フォーマットで表現可能な256個の整数のいずれかに丸めます。この丸めによって誤差が生じるため、パラメータを丸める回数が少なければ少ないほど、量子化モデルの品質は向上します。しかし、整数の分布は 一様 であるため、INT8量子化は、モデルのパラメータと活性度も一様に分布しているときに最もうまく機能 します。
残念ながら、重み��と活性度が一様に分布することはほとんどありません。そのため、FP8量子化の方がうまくいくかもしれません。浮動小数点数フォーマットは一様でない分布を表現することができます。 仮数にはいくつかのビットを 、指数にはいくつかのビットを使用するため 、 ゼロに近い数値を高精度で表現したい場合は、指数を負に設定することができます。
最近の 研究では、 典型的な値からかけ離れた数値である 異常値の 重みと活性度が、モデルの品質にとって特に重要 であることが 示されて います。 FP8は指数成分を持つため、INT8よりも少ない誤差で非常に大きな数値を表現できます。 そのため 、FP8に量子化することで、INT8よりも精度の高いモデルが生成される傾向があります。
アクティブ化には重みよりも外れ値が多く含まれる傾向があります。そこで、INT8でモデルの品質を保つために、重みとKVキャッシュのみをINT8に量子化し、アクティベーションはFP16のままにします。 SmoothQuantのような他の手法は 、INT8量子化で外れ値の問題を回避 します。
量子化Llama2-70B-チャット
Llama2-70B-Chatは現在、私たちの Foundation Model APIで提供されているモデルの中で最大かつ最高品質のものです。残念ながら、それはまた、より小さなモデルよりも遅く、より限られた並行性を提供することを意味します。量子化が役立つかどうか見てみましょう!
NVIDIA TensorRT-LLMライブラリを使用して、最適化されたLlama2-70B-Chatモデルを量子化し、提供します。我々は、Llama2-70B-Chatを量子化し、達成できることを発見しました:
(a) 50%小型化した モデル。GPUのメモリ要件が下がり、同じハードウェアで2倍のバッチサイズに対応できるようになりました。
(b) 最大 30 高速化 出力トークン生成。
(c) Llama2-70B-Chatのオリジナルモデルと平均して同じ品質。
まとめると、FP8量子化を使用することで、モデル全体のスループットを 2.2倍向上さ せることができます!
スピード
量子化の最大のメリットは、より高い同時実行性を実現できることです。同じハードウェアで同じレイテンシ・バジェットを維持しながら、最大バッチ・サイズを2倍にできるため です。H100でFP8を使用したバッチサイズ64の 場合、 FP16を使用したバッチサイズ32と比較して、ユーザーあたりの出力トークンあたりの時間(TPOT)が10%短縮されるため 、1秒あたり2.2倍のトークンを生成 できます。
並行性を高めることがオプションでない場合でも、量子化にはいくつかの利点があります。 バッチサイズ< 8、量子化されたモデルのTPOTとスループットは~30%向上 します。それ以上では、INT8ウェイトのみの量子化では、計算がFP16のままであるため、ほとんど速度が向上しません。しかし、H100はTransformer Engineを使用してFP8計算を高速に実行するため、高いバッチサイズでもFP16に対して10%のTPOT向上を維持します。
プロンプトの処理についてはどうですか?プリフィルの間、コンテキスト全体を一度に処理するため、通常 コンピュート・バインドされます。H100でFP8演算を高速化すると、FP16に比べてtime-to-first-token(TTFT)が30%向上します。しかし、INT8ウェイトのみの量子化は、計算がFP16のままであり、データ型間の変換のオーバーヘッドが追加されるため、量子化しない場合よりも実際には遅くなります。
最後に、GPUタイプを比較します。 同じバッチサイズ、同じ精度(つまり、INT8またはFP16を実行)の場合、TPOTはH100対A100で25-30%優れて いることがわかります 。 H100の最速モードであるFP8とA100の最速モードであるINT8(重みとKVキャッシュ)を比較すると、バッチサイズが大きい場合、この差は80%に拡大します。しかし、H100はA100よりもバンド幅が67%広く、計算能力が3倍高いため、H100用のソフトウェアやカーネルがより最適化されるにつれて、この差は将来拡大する可能性があります。現時点では、H100の方がA100よりも性能に余裕があるように見えます。我々の結果によると、出力トークン生成時のモデル帯域幅利用率(メモリからコンピュートエレメントへのデータ移動の効率性を示す指標)は、A100とH100では、A100の方が2%~7%高くなっています。
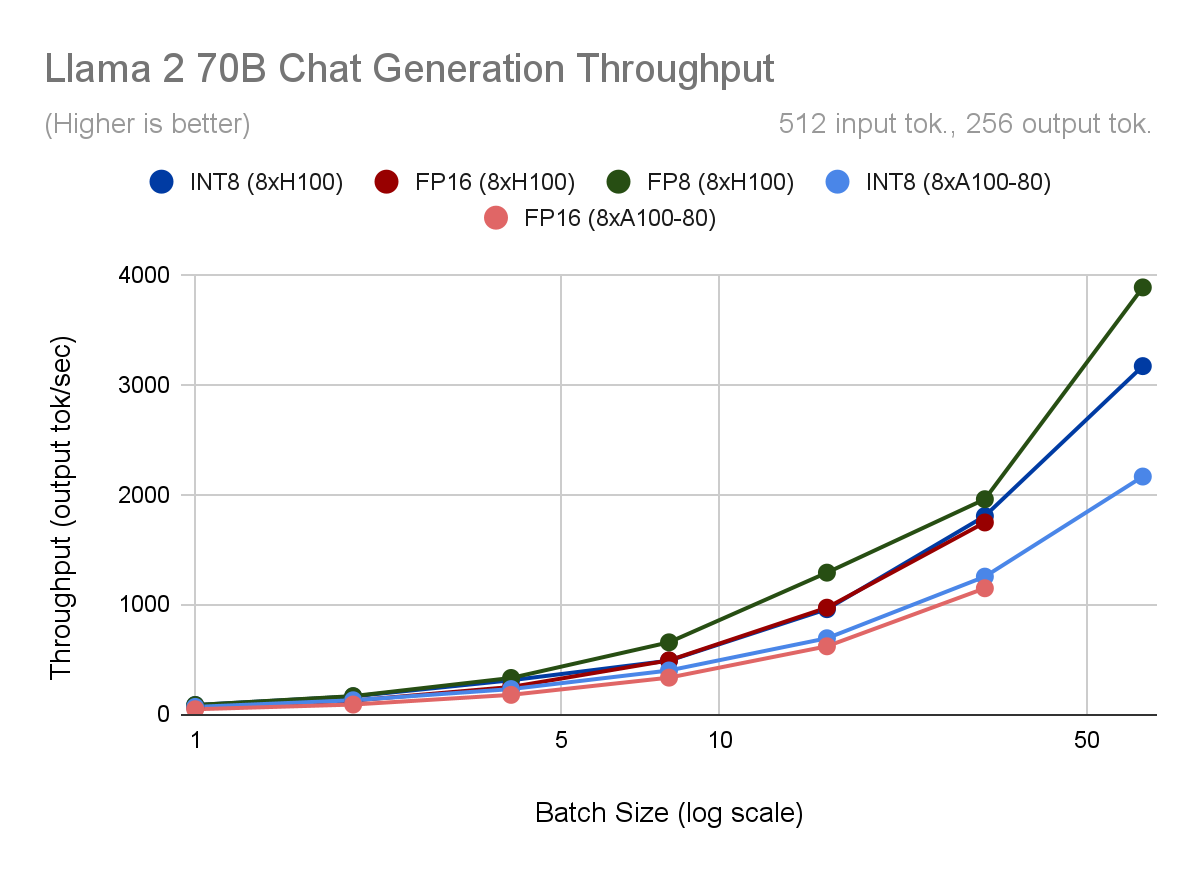
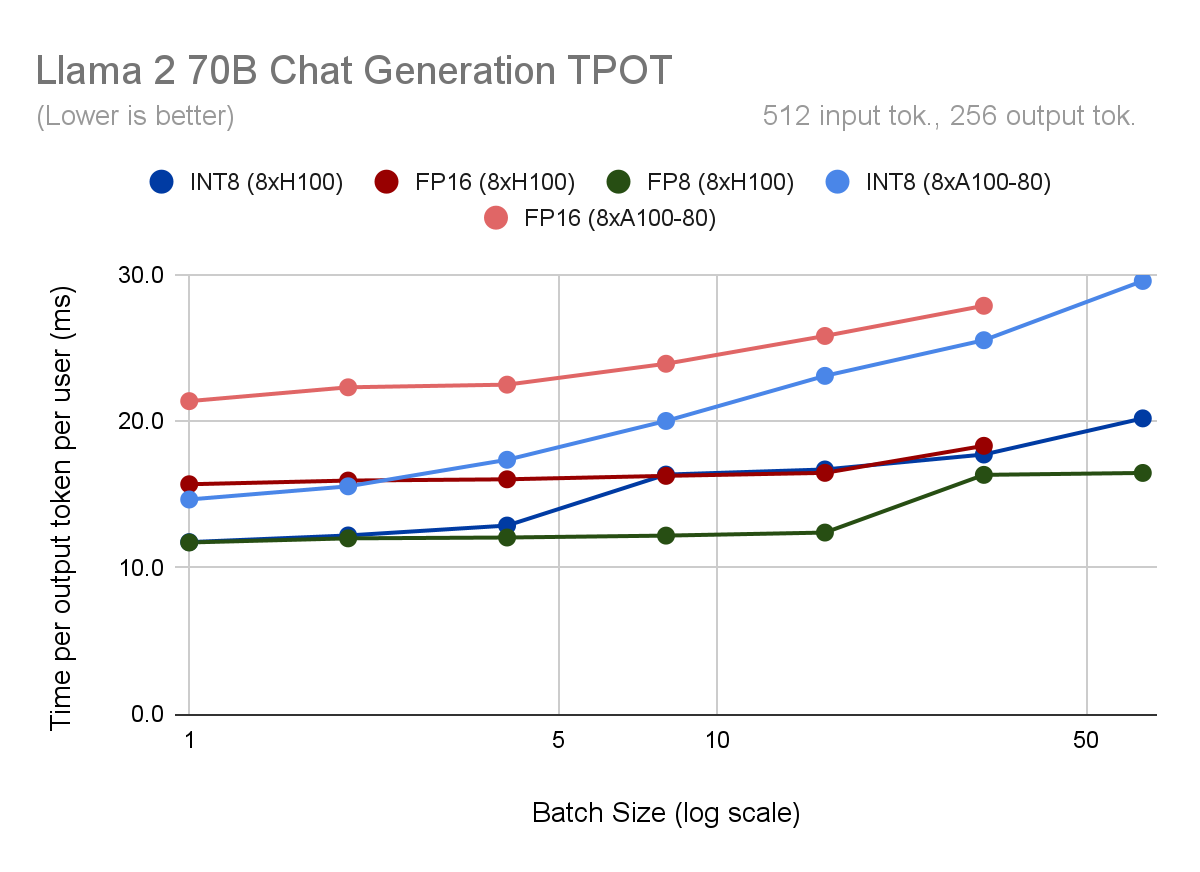
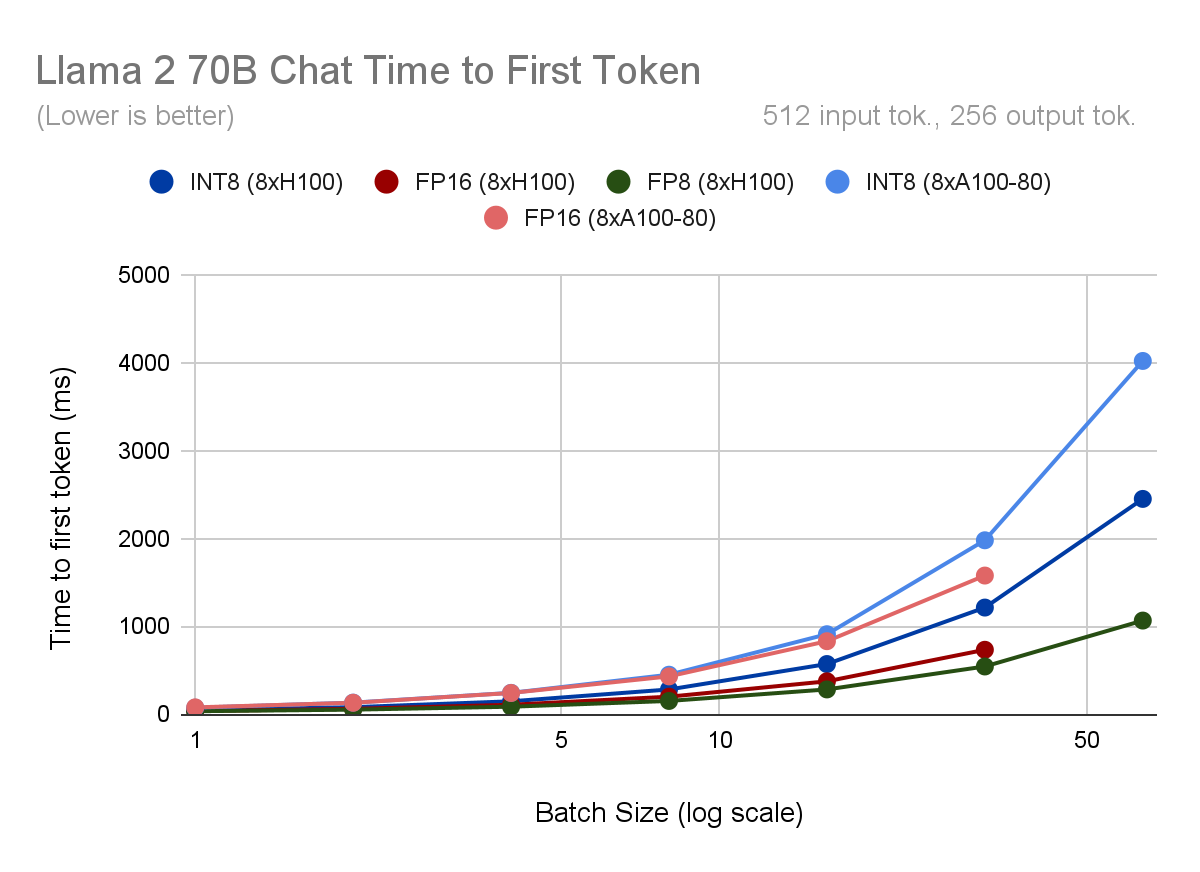
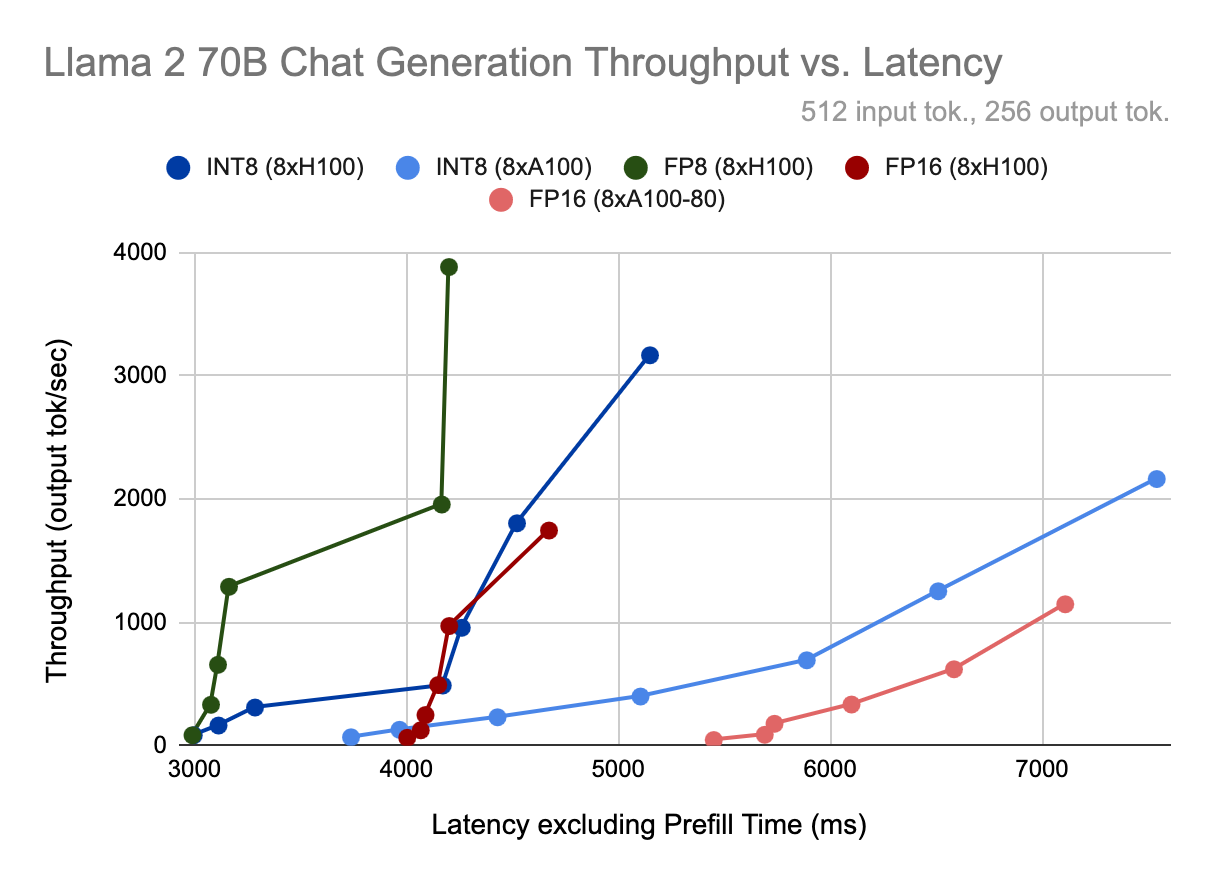
図2. 各Llama2-70B-Chat量子化モードとハードウェア構成について、(上)モデルのスループット(1秒あたりの出力トークン数で測定)、(2)1ユーザーあたりの出力トークンあたりの時間(TPOT)、(3)最初のトークンまでの時間、(下)出力スループットとレイテンシの関係をプロットします。
品質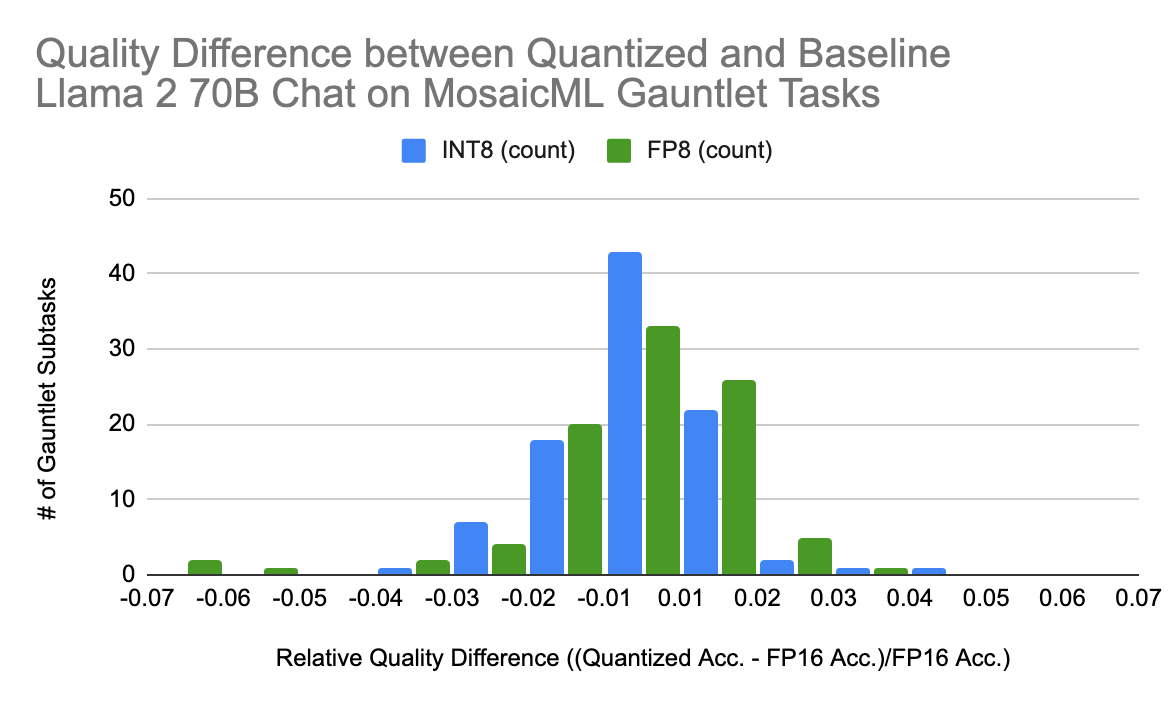
図 3. INT8モデル、FP8 Llamaモデルともに 、LLM評価ガントレットサブタスクにおけるベースラインモデルとの精度差は、ゼロに近い値を中心としたほぼ正規分布となっています。
モデルの量子化はモデルの品質に影響を与えます。 私たちは MosaicML Gauntlet評価スイートを開発し 、さまざまな タスクでモデルの品質をテストしています。 MosaicMLガントレットには、MMLU、BigBench、Arc、HellaSwagなどの業界標準ベンチマークが含ま�れています。これらのベンチマークは、世界知識、常識的推論、言語理解、記号的問題解決、読解など、さまざまな種類の問題で構成されています。
量子化されたLlama2-70B-ChatモデルをGauntletで徹底的に評価した結果、 いずれの量子化モードでもベースラインモデルとの間に 有意な精度の差は 見られませんでした 。 図3では、Gauntletサブタスクにおける各量子化タイプとベースラインLlama2-70B-Chatの品質差を示しています。平均して、量子化モデルとベースラインモデルの間に品質差はなく、量子化モデルは大部分のタスクでベースラインパフォーマンスの±2%以内に収まっています。
まとめ
量子化は、モデルのスピードとスループットを大幅に向上させる強力なテクニックです。 低バッチサイズでは、INT8-weight-onlyもFP8も同様の利点を提供します。 しかし、高スループットのユースケースでは、NVIDIA の H100s の FP8 量子化が最大のメリットをもたらします。
私たちのエンジニアリング・チームは、スピードアップを導入する際には常にモデルの品質を維持するよう注意を払っており、量子化も同様です。 私たちのGauntlet評価スイートによると、平均してLlama2-70B-ChatはFP8またはINT8量子化後も元の品質を維持しています。
私たちは間もなく、Foundation Model APIを通じて量子化されたLlama2-70B-Chatを提供する予定です。また、本番ワークロードの並行性保証が必要な場合は、Provisioned Throughputを使用してFoundation Model APIをデプロイすることができます。 詳細はこちらをご覧ください。
私たちは、質の高い結果を維持しながら、サービスを提供するモデルをより速くするために常に努力しています。 さらなる最適化にご期待ください!