StreamNativeとDatabricks、Pulsar-Sparkコネクターでリアルタイムデータ処理を強化

Apache PulsarベースのリアルタイムデータプラットフォームソリューションのリーディングプロバイダーであるStreamNativeと、データインテリジェンスプラットフォームであるDatabricksは、強化されたPulsar-Sparkコネクターを発表します。
リアルタイムデータ処理がビジネスにとって益々重要になっている今、このコラボレーションは、Apache Pulsar™ と Apache Spark™ という2つの強力なオープンソース技術の強みを組み合わせたものになります。
Apache Pulsar™
Apache Pulsar™はオープンソース、分散型メッセージングおよびイベントストリーミングプラットフォームであり、高い耐久性、スケーラビリティ、低レイテンシのメッセージングを提供します。 リアルタイムのデータストリーミングを処理するように設計されており、単純なpub/subメッセージングから複雑なイベント駆動型のマイクロサービスアーキテクチャまで、さまざまなアプリケーションに使用できます。
Apache Pulsarの主な特徴は以下の通りです:
- マルチプロトコルサポート:Pulsarには、Pulsar独自のバイナリプロトコル、MQTT、Apache Kafkaプロトコルといった標準メッセージングプロトコルのサポートが内蔵されています。 これらの内蔵プロトコルハンドラーは、様々なクライアントライブラリやメッセージングシステムとの相互運用性を促進し、開発者はPulsarを既存のインフラに簡単に統合することができます。
- データ保持と階層化ストレージ:Pulsarは柔軟なデータ保持と階層化ストレージオプションを提供し、ストレージコストを最適化します。
- マルチテナンシー:マルチテナンシーをサポートしているため、クラウド環境や共有インフラでの使用に適しています。
- 地理的レプリケーショ��ン:Pulsarは、複数の地理的地域にまたがるデータの複製を可能にし、ディザスターリカバリーとデータへの低遅延アクセスを実現します。
Apache Spark™
Apache Spark™は、ビッグデータ処理と分析のために設計されたオープンソースの分散コンピューティングシステムです。 年間10億ダウンロードを超えるSparkは、そのスピードと使いやすさで知られ、あらゆる大規模データ処理タスクに対応する統合分析エンジンを提供しています。
Apache Sparkの主な特徴は以下の通りです:
- インメモリ処理:Sparkはインメモリでデータ処理を行うため、従来のディスクベースの処理システムと比較してデータ分析が大幅に高速化されます。
- 使いやすさ:Java、Scala、Python、SQLで高レベルのAPIを提供しているため、多くのデータ専門家がアクセスできます。
- リアルタイムデータのサポート:Apache Sparkの構造化ストリーミングはリアルタイムデータ処理を可能にするため、企業はデータが到着した時点でデータを分析できます。
Apache Pulsar™ とApache Sparkの統合™
企業は、バッチ処理や静的なレポート以上のものを求めています。 彼らは、システムに流れ込んでくるデータに対して、リアルタイムの洞察と即座の対応を求めています。 Apache PulsarとApache Spark™ は、この変革において極めて重要な役割を果たしてきましたが、これら2つのテクノロジーのパワーを統合する必要性が高まってきました。
Pulsar-Sparkコネクター:リアルタイムデータの課題に対応
シームレスな統合
Pulsar-Sparkコネクター開発の動機は、Apache Pulsarの高速、低遅延データ取り込み機能と、Apache Sparkの高度なデータ処理および分析機能をシームレスに統合する必要性から生まれました。 この統合により、企業はエンドツーエンドのデータパイプラインを構築できるようになり、データの取り込みから分析まで、すべてがリアルタイムでスムーズに流れるようになります。
スケーラビリティと信頼性
リアルタイムのデータ処理には、スケーラビリティと信頼性が必要です。 この点においてApache Pulsarが本来持っている能力とApache Sparkの分散コンピューティングのパワーを組み合わせることで、これらの重要な課題に対応する比類なきソリューションが実現します。
統合分析
企業は、リアルタイムのデータを分析して意思決定を行うために、統合された分析プラットフォームを必要としています。 Pulsar-Sparkコネクターは、Apache PulsarとApache Sparkの長所を組み合わせたシームレスなソリューションを提供することで、迅速な洞察とデータ駆動型の意思決定を実現します。
オープンソースコラボレーション
さらに、Pulsar-Sparkコネクターをオープンソースプロジェクトとしてリリースすることは、透明性、コラボレーション、そしてユーザーと貢献者の活気あるコミュニティ作りへの私たちの取り組みを反映したものです。
要約すると、Pulsar-Sparkコネクター開発の動機は、Apache PulsarのスピードとスケーラビリティをDatabricksのSparkプラットフォームのデータ処理能力とシームレスに統合する、統合された高性能ソリューションを組織に提供することです。 これにより、企業はリアルタイムのデータ処理と分析に対する需要の高まりに対応できるようになります。
一般的なユースケース
リアルタイムデータ処理と分析:Apache Pulsarのpub-subメッセージングシステムは、多様なソースからの膨大なデータストリームをリアルタイムで取り込むことを可能にします。 Spark構造化ストリーミングは、これらのデータストリームを低レイテンシーで処理する機能を提供し、リアルタイム分析、モニタリング、アラートを可能にします。 PulsarとSparkを組み合わせることで、リアルタイムデータ処理パイプラインのバックボーンを形成することができ、企業はストリーミングデータから洞察を得て、即座に行動を起こすことができます。
継続的なETL(抽出、変換、ロード):最新のデータアーキテクチャでは、継続的なETLプロセスの必要性が��最も重要です。 Apache Pulsarは様々なソースからのデータ取り込みを容易にし、Apache Sparkはバッチおよびストリーミング処理エンジンを通じて強力な変換機能を提供します。 企業はPulsarを活用してデータストリームを取り込み、Sparkを活用してリアルタイム変換、エンリッチメント、集計を実行してから、下流システムやデータストアにロードすることができます。
複雑なイベント処理(CEP):複雑なイベント処理では、イベントやデータのストリームにおけるパターンや相関関係をリアルタイムで特定します。 Apache Pulsarの高スループットイベントストリーム処理能力と、Sparkの豊富なストリーム処理API群は、CEPアプリケーションの実装に最適な組み合わせです。 企業は、Pulsarを使用してイベントストリームを取り込み、Sparkを使用して複雑なパターン、異常、傾向をリアルタイムで分析・検出することで、先手を打った意思決定と重要なイベントへの迅速な対応を実現することができます。
ストリーミングデータ上での機械学習:リアルタイムでの意思決定のために機械学習技術を採用する企業が増えているため、Apache PulsarとApache Sparkの統合は重要な役割を果たします。 Pulsarは、センサー、IoTデバイス、アプリケーション・ログから生成される継続的なデータストリームの取り込みを可能にし、SparkのMLlibライブラリは、ストリーミングデータ上で動作するスケーラブルな機械学習アルゴリズムを提供します。 企業はこの組み合わせを活用して、異常検知、予知保全、パーソナライゼーションなどのタスクのためのリアルタイム機械学習モデルを構築し、展開することができます。
リアルタイムのモニタリングとアラート:モニタリングとアラートシステムには、大量のストリーミングデータをリアルタイムで処理・分析する能力が必要です。 Apache Pulsarは、様々なモニタリングソースからイベントストリームを収集し、配信するための信頼性の高いメッセージングバックボーンとして機能する一方、Apache Sparkを使用して、受信ストリームの分析、異常の検出、事前定義されたしきい値やパターンに基づくアラートのトリガーを行うことができます。 この共同ソリューションにより、企業はシステム、アプリケーション、インフラストラクチャをリアルタイムで監視できるようになり、潜在的な問題や障害をタイムリーに検出して対応できるようになります。
Pulsar-Sparkコネクターの主なハイライト:
- 超高速データ取り込み:Pulsar-Sparkコネクターにより、Apache PulsarからDatabricksのApache Sparkクラスタへの高速データ取り込みが可能になるため、企業はかつてないスピードでリアルタイムデータを処理することができます。
- エンドツーエンドのデータパイプライン:取り込みから処理、分析、可視化まで、データライフサイクル全体を網羅するエンドツーエンドのデータパイプラインをシームレスに構築します。
- 高いスケーラビリティと信頼性:Apache Pulsar固有のスケーラビリティと信頼性を、DatabricksのSparkプラットフォームの高度なデータ処理機能と組み合わせることで、その恩恵を受けることができます。
- ネイティブな統合:Pulsar-Sparkコネクターはシームレスな統合を実現するよう設計されているた�め、データエンジニアとサイエンティストが両プラットフォームの長所を活かしながら、より簡単に共同作業を行うことができます。
- 統合アナリティクス:Databricksの統合分析プラットフォームでリアルタイムのデータストリームを分析し、迅速な洞察とデータ主導の意思決定を可能にします。
- オープン・ソース:Pulsar-Sparkコネクターはオープンソースプロジェクトとしてリリースされ、透明性、コラボレーション、そしてユーザーと貢献者のコミュニティが繁栄することを保証します。
Databricks ランタイムでも利用可能
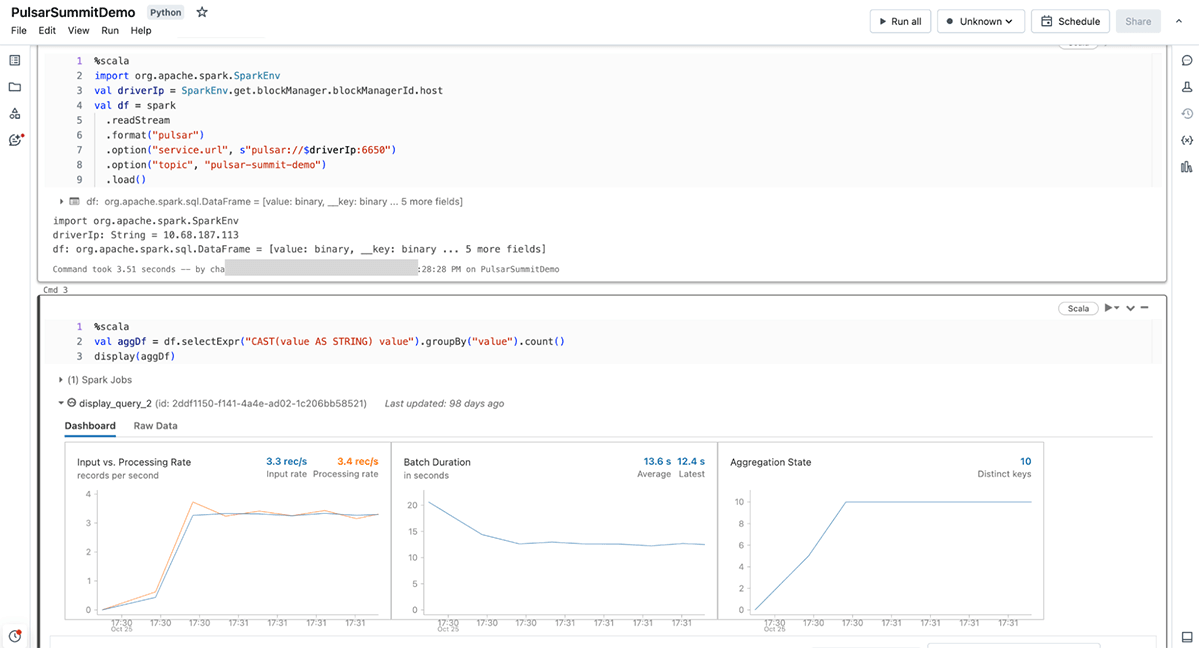
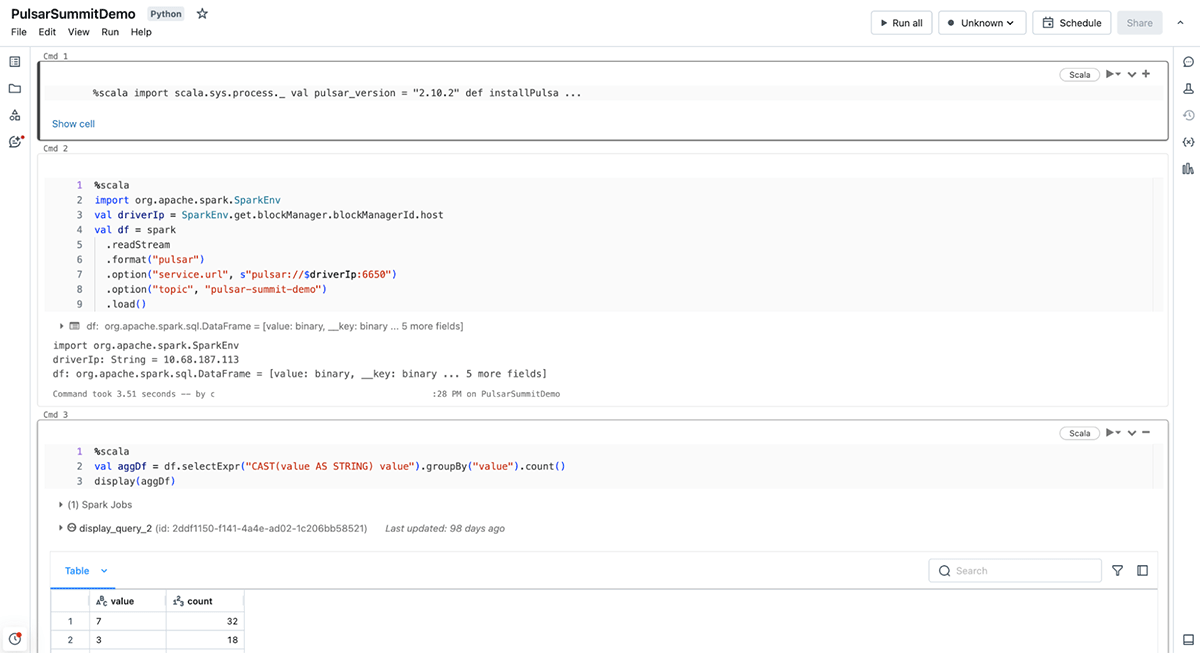
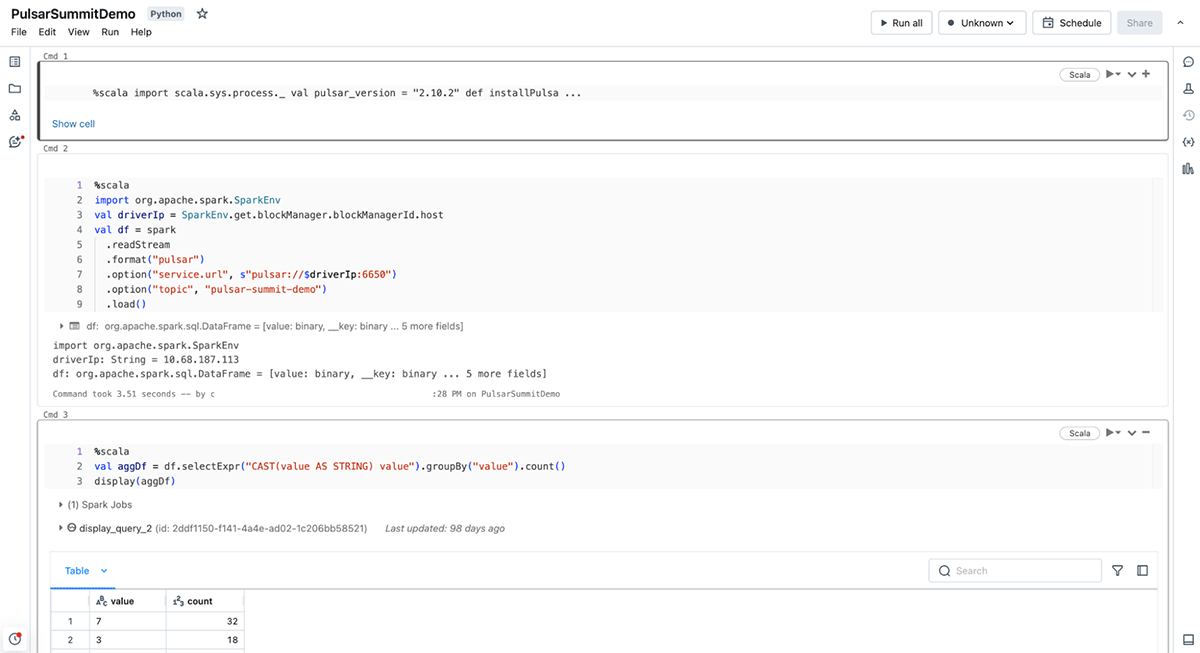
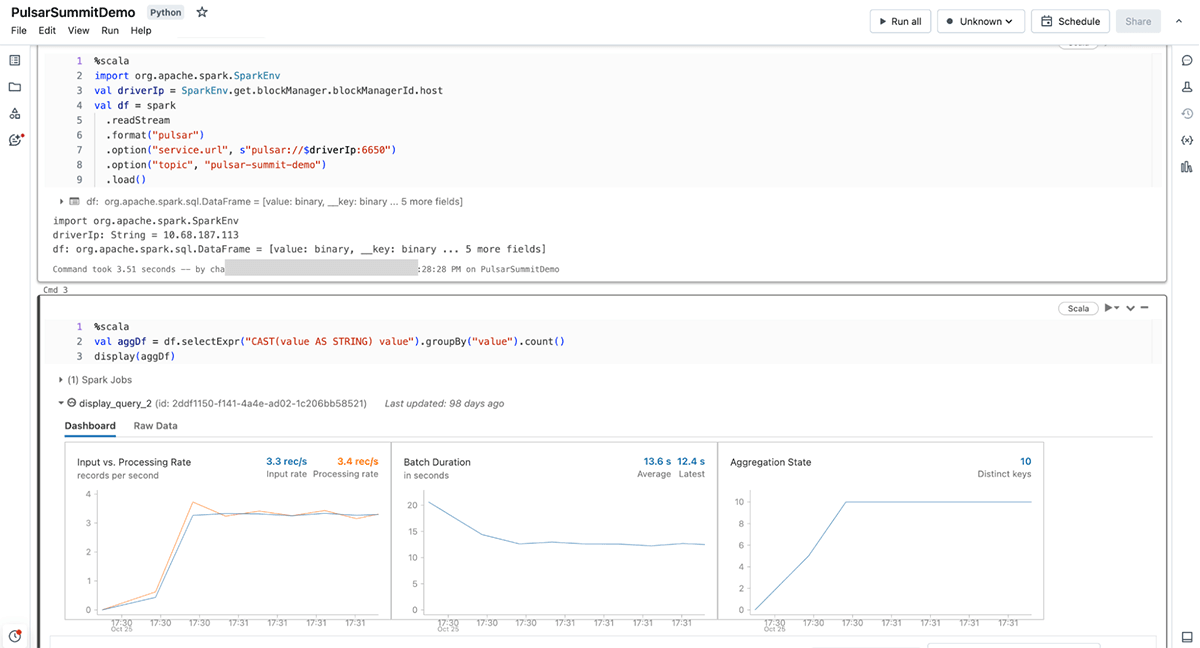
Databricksデータインテリジェンスプラットフォームは、Apache Sparkワークロードを実行するのに最適な場所です。 すべてのデータとガバナンスのためのオープンで統一された基盤を提供するレイクハウスアーキテクチャに基づいて構築されており、データの独自性を理解しながら、あらゆ�る種類のデータユーザーに高性能な計算とクエリを提供するデータインテリジェンスエンジンを搭載しています。 つまり、Pulsarから分析または機械学習プロセスへのデータ取り込みは、簡単かつ効率的に行えるということです。
Databricksは、コネクターに関する上記の利点に加え、Databricksプラットフォーム上でPulsarを使用する開発者の体験を向上させるため、いくつかの追加コンポーネントを加えました。 DBR 14.1(およびDelta Live Tablesプレビュー・チャネル)でのサポートを皮切りに、Databricksエンジニアリングチームは、Pulsarの使用をよりシンプルで簡単なものにする2つの重要な分野を追加しました。
- 拡張言語サポート:Databricksは、既にサポートされているScala/JavaおよびPython APIに加え、言語サポートを拡張し、
read_pulsarSQLコネクタを追加しました。 それぞれのフレーバーを使用することで、同様のオプションを提供し、Sparkの構造化ストリーミングのメソッドと整合しますが、SQL構文はDatabricksプラットフォーム独自のもので、STREAMオブジェクトと整合するように構文自体が異なります。 - 認証情報管理オプション:Databricksではパスワード認証について認証情報の漏洩を防ぐためにSecretsの使用を推奨しています。 TLS認証では、環境の設定に応じて、以下のロケーションタイプのいずれかを使用できます。
- 外部ロケーション
.option("tlsTrustStorePath","s3://<credential_path>/truststore.jks")
- DBFS
.option("tlsTrustStorePath","dbfs:/<credential_path>/truststore.jks")
- Unity Catalogボリューム
.option("tlsTrustStorePath","/Volumes/<catalog>/<schema>/<volume>/truststore.jks")
Unity Catalogを使用するDatabricks環境では、ストリーム読み込み時の権限エラーを避けるため、Pulsarコンシューマーが資格情報ファイルにアクセスできるようにすることが重要です。
- 外部ロケーション
GRANT READ FILES ON EXTERNAL LOCATION s3://<credential_path> TO<user>
- Unity Catalogボリューム
GRANT READ VOLUME ON VOLUME<catalog.schema.credentials> <user>
構文の例
ここでは、サポートされている各APIの構文の例を示します。 ScalaとPythonのAPIはどちらもreadStream入力として直接使用され、SQL APIはSTREAMオブジェクトを使用することに注意してください。
Scala
Python
SQL
その他の設定オプションについては、Databricksのドキュメントを参照してください。 オープンソースのApache Sparkでの使用方法については、StreamNativeのドキュメントを参照してください。
まとめ
リアルタイムデータによって推進される世界において、StreamNativeとDatabricksが協力してPulsar-Sparkコネクターを�開発したことは、大きな飛躍を意味します。 この画期的なコネクターは、リアルタイムデータ処理における重要な課題に対応し、企業がエンドツーエンドのデータパイプラインを構築し、スケーラビリティと信頼性の恩恵を受け、圧倒的なスピードでデータ主導の意思決定を行うことを可能にします。
この旅に乗り出すにあたり、私たちは継続的な改善、革新、そしてユーザーの進化するニーズへの対応に全力を尽くします。 Pulsar-Sparkコネクターが、皆様のリアルタイムデータ処理と分析に良い影響をもたらすことを楽しみにしています。
皆様とともにリアルタイムデータ処理の未来を切り開いていきたいと思います。


{kind=link}
{kind=link}