
Databricksでは、あらゆる分野の世界最高の企業が、自社独自のデー�タに基づいてトレーニングされカスタマイズされたAI搭載システムを持つようになると考えています。 今日の企業は、独自のAIモデルをトレーニングすることで、競争上の優位性を最大限に高めることができます。
私たちは、企業が可能な限り迅速かつコスト効率よくAIを育成するための最良のプラットフォームを提供することをお約束します。 本日は、LLMスタックに施されたいくつかの大きな改良をご紹介します。これにより、お客様の事前トレーニングと微調整の効率が大幅に改善されました。 この投稿では、最新のスループット数値を紹介し、これらの結果を達成し、何千ものGPUに拡張するのに役立ったいくつかのテクニックについて説明します。
最新のベンチマーク結果
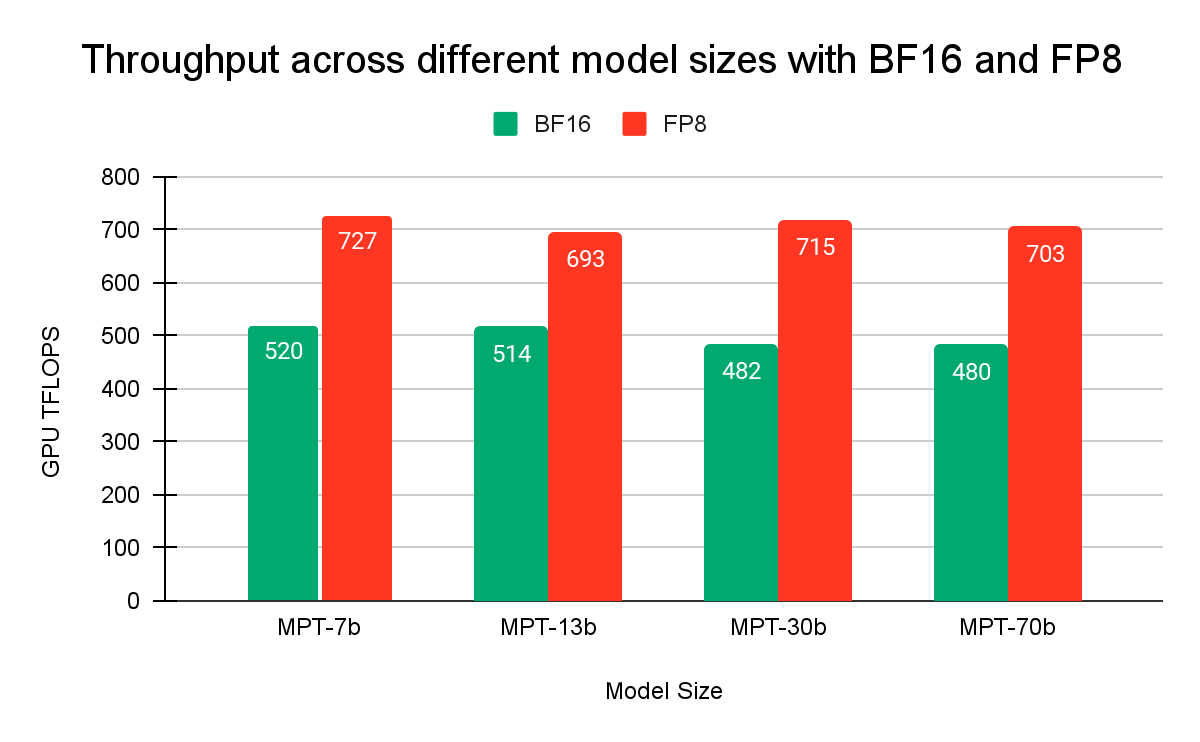
さっそく結果を見てみましょう。 図1は、BFloat16(BF16)とFP8(Float8)のデータ型を使用し、異なるモデルサイズでトレーニングを実行した場合に達成された1秒あたりの浮動小数点演算(FLOPS)を示しています。 FP8はBF16に比べて1.4倍から1.5倍のスピードアップを達成しました。
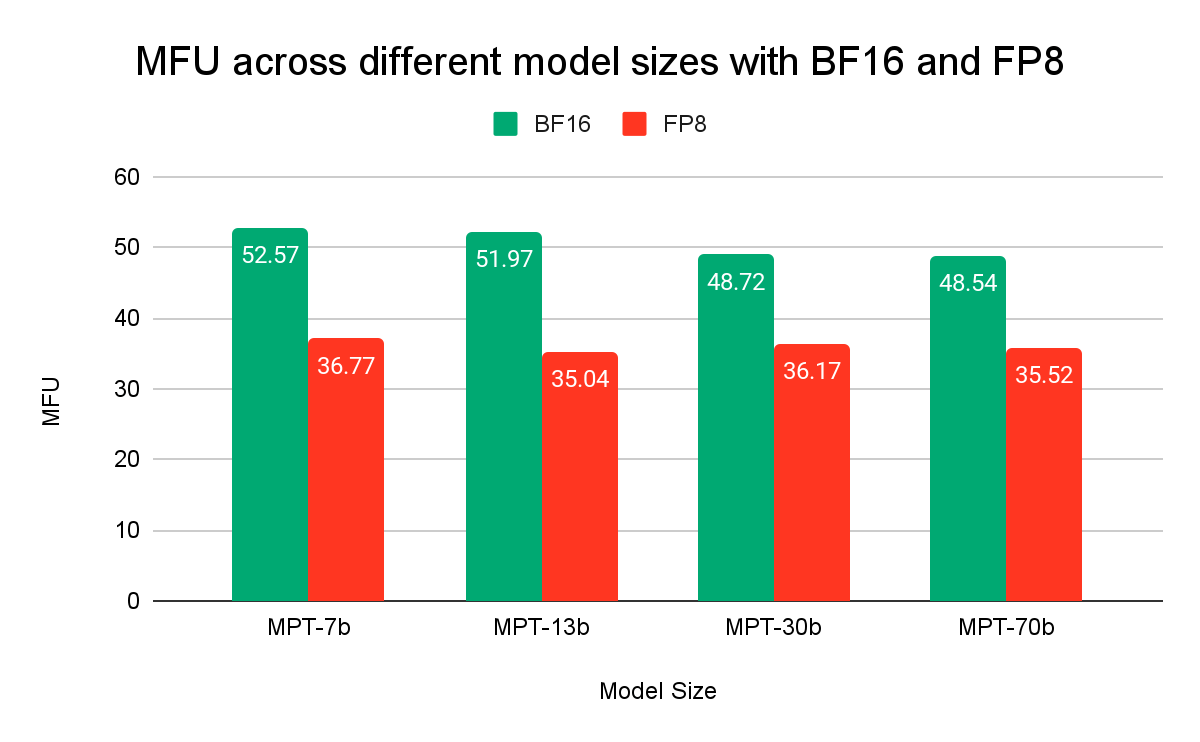
図2は、BF16とFP8を使用したモデルトレーニングにおいて、基礎となるハードウェアをいかに効率的に活用しているかを示しています。 モデルFLOPS利用率(MFU)は、他のLLMトレーニングフレームワークが公表している数値の中で最も高い、> 50%のスケールを達成しました。 FP8の使用率が低いのは、FP8が高速であるためです。
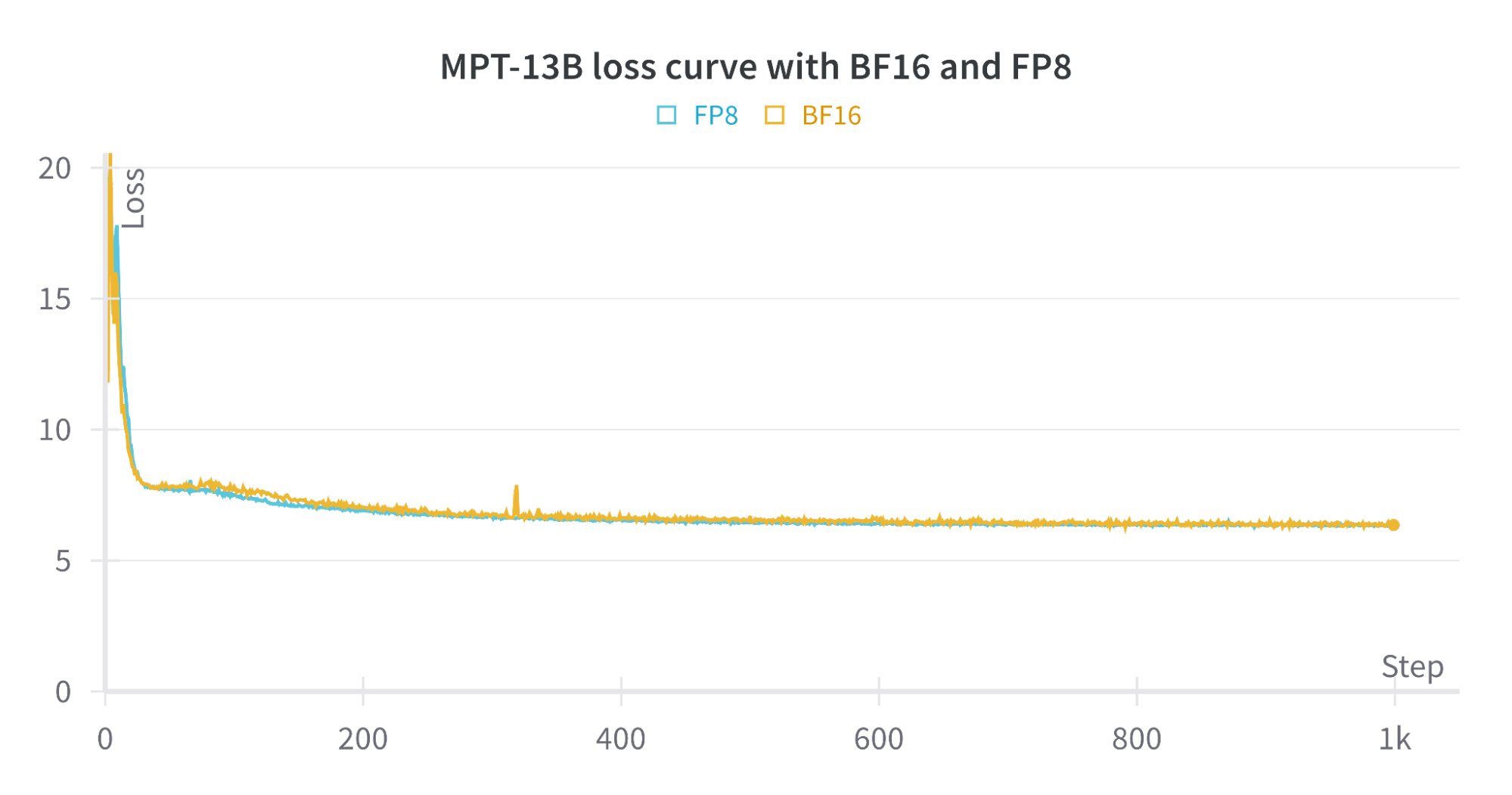
図3は、BF16トレーニングとFP8トレーニングの損失曲線を示しています。 BF16とFP8による損失曲線は互いに密接に追従しており、FP8の精度の低さがモデルの収束に与える影響は最小限であることを示しています。
トレーニングを加速させる方法
Transformer Engine FP8
NVIDIA H100 Tensor Core GPUは、ネイティブのFP8演算を提供し、より低い数値精度で実行することにより、トレーニングを高速化する新たな機会を提供します。 私たちはNVIDIAと緊密に協力し、FP8トレーニング用の人気ライブラリであるTransformer Engineをトレーニングスタックに活用し、PyTorch FSDPとの互換性を確保しました。 FP8は性能を大幅に向上させ、大規模な行列乗算を劇的に高速化します。
我々のトレーニングスタックでは、Zero-3 テクニックの実装であるPyTorch Fully Sharded Data Parallel (FSDP)を活用して、トレーニングを並列化し、数千のGPUにスケールします。FSDPとTransformer EngineおよびFP8トレーニングの互換性を確保するため、NVIDIAと緊密に協力し、初期化やアンシャードバッファによるメモリオーバーヘッドなどの主要なボトルネックを特定し、メモリ使用量を劇的に削減しました。 また、このスタックを拡張し、PyTorchのアクティベーション・チェックポイントと統合することで、さらに大規模なモデルの学習をサポートできるようにしました。
設定可能な起動チェックポイント
大規模なモデルをトレーニングする場合、GPUのメモリはモデルの重み、オプティマイザ、勾配、アクティブ化によって消費されます。 PyTorch FSDPはモデルの重み、オプティマイザ、勾配をシャードします。 しかし、アクティベーションは、特にバッチサイズの�大きなモデルの場合、GPUのメモリをすべて消費する可能性があります。 GPUに十分なメモリがない場合、アクティブ化チェックポイントと呼ばれるテクニックを使うことで、トレーニングを確実に進めることができます。 アクティブ化チェックポイントは、フォワードパスでアクティブ化の一部のみを保存し、バックワードパスで不足するアクティブ化を再計算します。 これはトレードオフの関係にあります。メモリは節約できますが、後方パスでの計算量が増えます。
活性化チェックポイントを実装する標準的な方法は、注意層、MLP層、正規化層で構成される変換ブロック全体に対して行うことです。 しかし、モデルの一部では、必要な計算量に比べてかなり多くのメモリを使用します。 活性化チェックポイントの実装を刷新し、任意のレイヤーを対象とし、活性化のサブセットのみをチェックポイントできるようにしました。 これにより、ユーザーは、メモリ内の実行に必要なだけのアクティブ化をチェックポイントすることができ、そのための計算オーバーヘッドを最小限に抑えることができます。
DTensor
モデルを大規模にトレーニングする場合、パフォーマンスを最大化するためにカスタム並列構成を記述したいと思うことがよくあります。 PyTorch DTensorは、テンソルとモデルがどのようにシャードされ、マルチGPUクラスタ間で複製されるかを指定するための、柔軟で使いやすいインタフェースを提供します。 私たちは最近、DTensorにいくつかの新機能をアップストリームし、さまざまな並列化戦略を迅速に実験できるようにしました。
例として、私たちは数千のGPUにスケールするためにDTensorに大きく依存しています。 AllGatherのような分散コレクティブを大規模なクラスタで実行する場合、利用可能なネットワーク帯域幅の使用率が低いことがよくあります。 これは、AllGathersの実装に通常使用されるリングアルゴリズムによるもので、GPUの数が増えるにつれてレイテンシがリニアにスケールします。 DTensorでは、クラスタ全体でモデルをシャーディングする代わりに、より小さなブロック内でモデルをシャーディングし、その構成をクラスタ全体で複数回並行して複製することができます。 この最適化によってスケーラビリティが劇的に向上し、クラスタサイズを大きくしてもほぼ直線的な改善が見られます。
コミュニケーションとアクティベーションの圧縮
既存のライブラリは低精度の行列乗算を非常によくサポートしていますが、通信や活性化テンソルはまだ高精度の形式が中心です。 通信のボトルネックを緩和し、メモリへの負荷を軽減するために、テンソルを圧縮するためのカスタムカーネルを活用しています。 このテクニックにより、GPUあたりのトークンを増やし、行列乗算のサイズを大きくすることができます。 これは、より大きな行列の乗算がより高いハードウェア使用率を達成するため、より高い性能を提供します。
一緒にトレーニングしましょう!
私たちのトレーニング・プラットフォームの次世代にパートナーを迎えることができ、とても嬉しく思っています。 ゼロからトレーニングする場合でも、基盤モデルをファインチューニングする場合でも、当社のスタックの効率性とパフォーマンスにより、��データを活用して組織の競争優位性を引き出すことができます。 まずはお気軽にお問い合わせください!