Unity Catalogを通じたデルタシェアリングで構造化ストリーミングを使う
Original : Using Structured Streaming with Delta Sharing in Unity Catalog
翻訳: junichi.maruyama
この度、Azure、AWS、GCPにおいて、Structured StreamingをDelta Sharingで使用するためのサポートが一般提供(GA)されたことをお知らせします!この新機能により、Databricks Lakehouse Platform上のデータ受信者は、Unity Catalogを通じて共有されたDelta Tableからの変更をストリーミングできるようになります。
データプロバイダーは、この機能を活用することで、Data-as-a-Service を容易に拡張し、大規模なデータセットを共有するための運用コストを削減し、新しいデータが到着すると即座にデータ検証や品質チェックを行い、データ品質を改善し、リアルタイムデータ配信で顧客サービスを向上することができます。同様に、データ受信者は、共有データセットから最新の変更をストリーミング配信することができ、大規模なバッチデータの処理にかかるインフラコストを削減し、�最先端のリアルタイムデータアプリケーションの基盤を構築することができます。この新機能は、例えば、様々な業種のデータ受信者が恩恵を受けることができます:
- Retail: データアナリストは、季節のファッションラインの最新の売上高をストリームし、BIレポートの形でビジネスの洞察を提示することができます。
- Health Life Sciences: 医療従事者は、心電図の測定値をMLモデルにストリーミングして、異常を特定することができます。
- Manufacturing: ビル管理チームは、スマートサーモスタットの測定値をストリーミングし、昼夜を問わず冷暖房機器の効率的なオン・オフを特定することができます。
データチームは、バッチ実行が堅牢で実装が容易であることから、データ処理にバッチ方式で実行されるデータパイプラインに依存することがよくあるようです。しかし、今日、企業はリアルタイムのビジネス上の意思決定を行うために、最新の到着データを必要としています。構造化ストリーミングは、リアルタイム処理を簡素化するだけでなく、バッチ処理のジョブ数を数個のストリーミングジョブに減らすことで、バッチ処理を簡素化することもできます。Structured Streamingは同じDataFrame APIをサポートしているので、バッチデータパイプラインをストリーミングに変換するのは簡単です。
このブログでは、金融業界を例にとって、企業がStructured StreamingとDelta Sharingを活用して、データのビジネス価値をほぼリアルタイムで最大化する方法について説明します。また、Databricks Workflowsのような他の補完的な機能をDelta SharingやUnity Catalogと組み合わせて使用し、リアルタイムデータアプリケーションを構築する方法についても検証していきます。
構造化ストリーミングのサポート
ここ数ヶ月で最も期待されたDelta Sharing機能は、Structured Streamingのソースとして共有Delta Tableを使用するためのサポートが追加されたことでしょう。この新機能により、データ受信者は、Databricks Lakehouse Platform上のUnity Catalogを通じて共有されたDelta Tableを使用して、リアルタイムアプリケーションを構築することができるようになります。
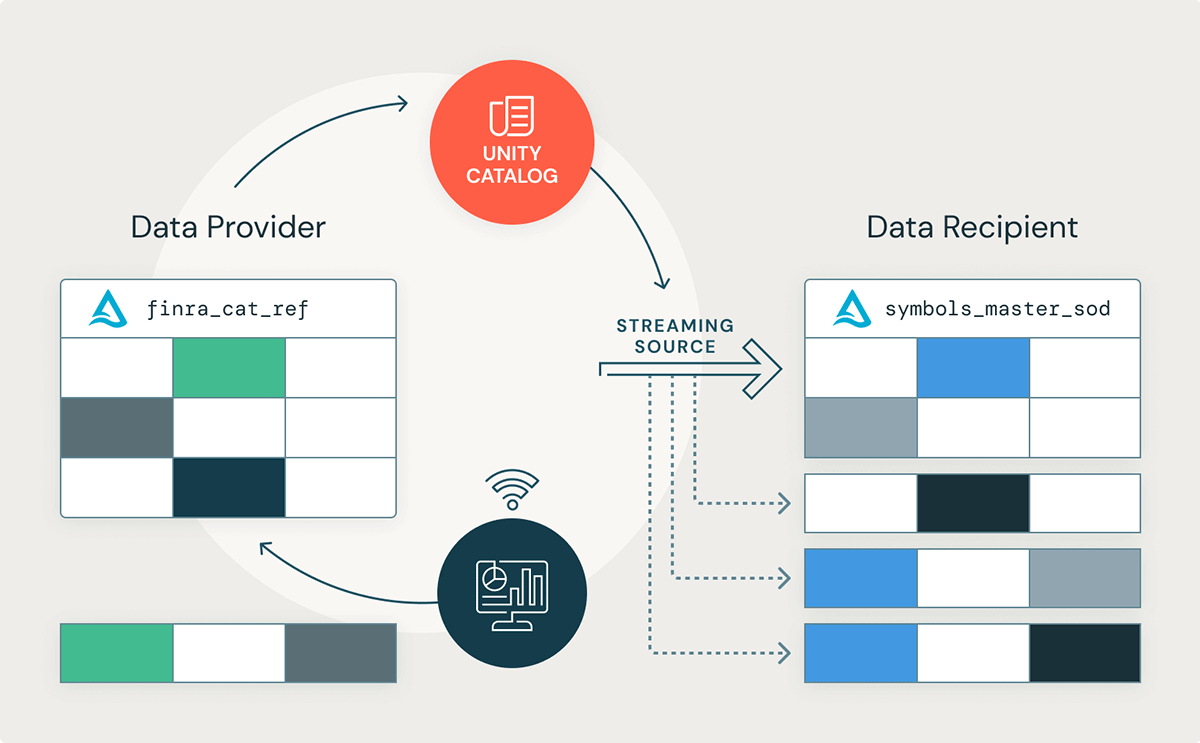
構造化ストリーミングでデルタシェアリングを使う方法
ここでは、データ受信者がリアルタイムの取引情報を得るために、公開されている株式シンボル情報をどのように配信するかについて詳しく見ていきましょう。この記事では、FINRA CAT Reportable Equity Securities Symbol Master データセットを使用します。このデータセットには、米国のNational Market System(NMS)で取引されるすべての株式や持分証券が掲載されています。構造化ストリーミングは、リアルタイムアプリケーションの構築に使用できますが、データの到着頻度が低いシナリオでも有用です。ここでは、取引開始日(SOD)に1回、日中の変更を反映するために日中に2回、取引終了日(EOD)に3回、1日に3回更新されるデータセットを使用します。週末および米国の祝祭日には、更新は行われません。
| Published File | Schedule |
|---|---|
| CAT Reportable Equity Securities Symbol Master – SOD | 6:00 a.m. EST |
| CAT Reportable Options Securities Symbol Master – SOD | 6:00 a.m. EST |
| Member ID (IMID) List | 6:00 a.m. EST |
| Member ID (IMID) Conflicts List | 6:00 a.m. EST |
| CAT Reportable Equity Securities Symbol Master – Intraday | 10:30 a.m. EST, and approximately every 2 hours until EOD file is published |
| CAT Reportable Options Securities Symbol Master – Intraday | 10:30 a.m. EST, and approximately every 2 hours until EOD file is published |
| CAT Reportable Equity Securities Symbol Master – EOD | 8 p.m. EST |
| CAT Reportable Options Securities Symbol Master – EOD | 8 p.m. EST |
Table 1.1 - FINRA CATシンボルおよび会員参照データは、営業日を通して公開されます。週末や米国の祝祭日には、更新情報の公開はありません
データプロバイダの立場から DatabricksワークフローによるCATデータの取り込み
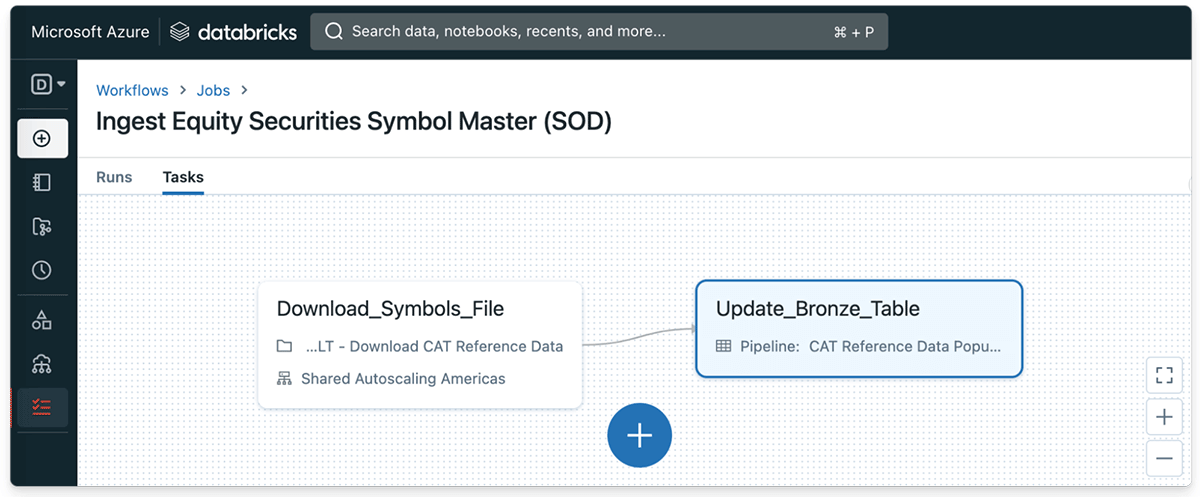
Databricks Lakehouse Platformの大きな利点の1つは、Delta Tableに継続的に変更をストリーミングすることが非常に簡単であることです。まず、取引日(SOD)の開始時にFINRA CATの株式シンボルファイルをダウンロードするシンプルなPythonタスクを定義することから始めましょう。その後、公開されたファイルを Databricks ファイルシステム上の一時ディレクトリに保存することにします。
Code 1.1. - 簡単なPythonタスクで、取引開始時にFINRA CATの株式シンボルファイルをダウンロードする
また、デモとして、生ファイルを取り込み、更新されたファイルが公開されるたびに、Delta Lakeのbronze tableを継続的に更新する機能を定義します。
Code. 1.2 - FINRA CAT の株式シンボルデータは、各取引日の開始時に Delta Table に取り込まれます
Databricksワークフローは、取引開始時にファイルが公開されるたびに、CAT株式シンボルデータセットへの入力を開始します。
データプロバイダの立場から デルタテーブルをストリーミングソースとして共有する
シンボルファイルの更新を取引日ごとに取り込むストリーミングパイプラインを作成したので、Delta Sharing を利用して Delta Table をデータ受信者と共有することができます。Databricks Lakehouse PlatformでDelta Shareを作成するには、ボタンを数回クリックするか、SQL構文を使用する場合は1つのSQL statementで作成することができます。
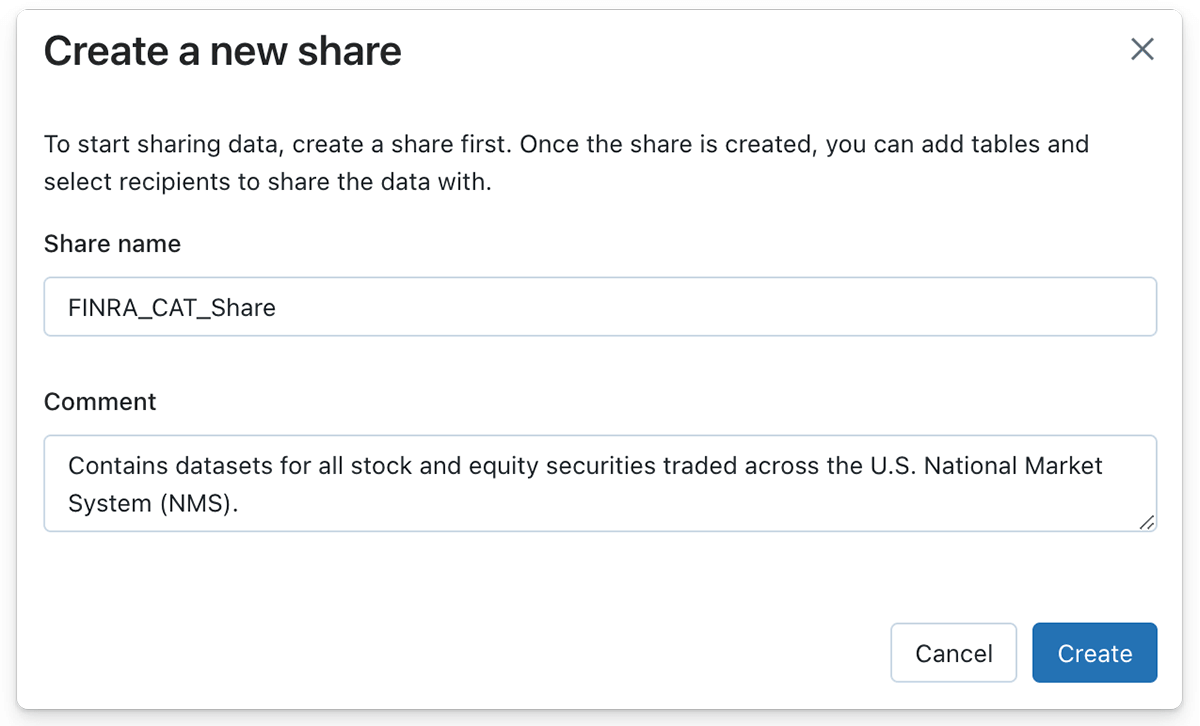
同様に、データプロバイダーは、'Manage assets' ボタンをクリックし、次に 'Edit tables' ボタンをクリックすることで、デルタシェアに 1 つまたは複数のテーブルを入力することができます。この場合、株式シンボルデータを含むブロンズデルタテーブルがシェアオブジェクトに追加されます。
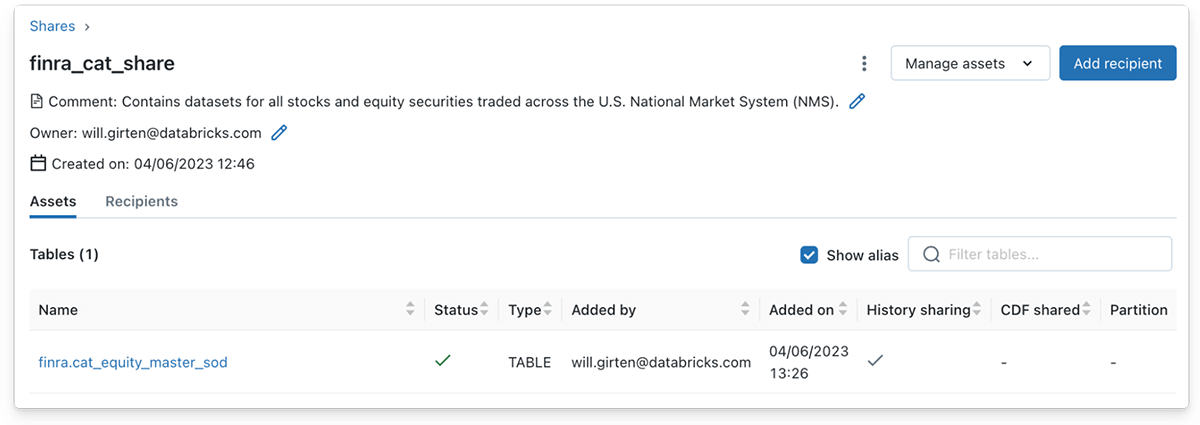
Structured Streamingを使用した読み込みをサポートするためには、Deltaテーブルの全履歴を共有する必要があることに注意してください。Databricks UI を使用して Delta テーブルを Share に追加すると、履歴の共有はデフォルトで有効になります。しかし、SQL構文を使用する場合は、履歴の共有を明示的に指定する必要があります。
Code 1.4 - SQL構文を使用する場合、Structured Streaming読み込みをサポートするために、Deltaテーブルの履歴は明示的に共有されなければなりません。
ガートナー®: Databricks、クラウドデータベースのリーダー

データ受信者の立場から: 共有デルタテーブルのストリーミング
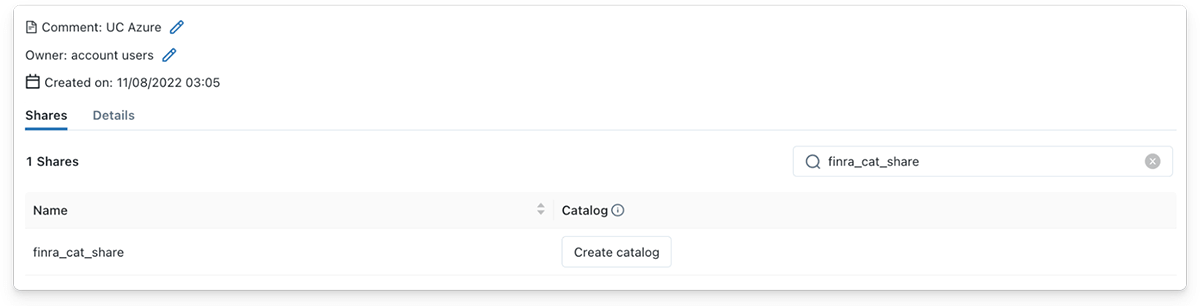
データ受信者として、共有されたDeltaテーブルからのストリーミングは、同様にシンプルです!Delta Shareがデータ受信者と共有されると、受信者はすぐにUnity Catalogのプロバイダ詳細の下にShareが表示されるのを確認します。その後、データ受信者は、「カタログの作成」ボタンをクリックして、Unityカタログで新しいカタログを作成し、意味のある名前を指定し、オプションのコメントを追加して、シェアの内容を説明することができます。
データ受信者は、Databricks Runtime 12.1以上を使用して、Unity Catalogを通じて共有されたDelta Tableからストリーミングできます。この例では、Databricks 12.2 LTS Runtime がインストールされたDatabricksクラスタを使用しています。データ受信者は、DeltaSharingデータソースを使用して、共有テーブルの名前を供給するSpark Structured Streamとして共有Deltaテーブルを読むことができます。
Code 1.4 - データ受信者は、deltaSharingデータソースを使用して、共有されたDeltaテーブルからストリーミングすることができます
さらなる例として、共有されたCATの株式シンボルマスターデータセットと、データ受信者のUnityカタログにローカルに存在する株価履歴データセットを組み合わせてみましょう。まず、指定した銘柄のティッカーシンボルの週次株価履歴を取得するための効用関数を定義することから始めます。
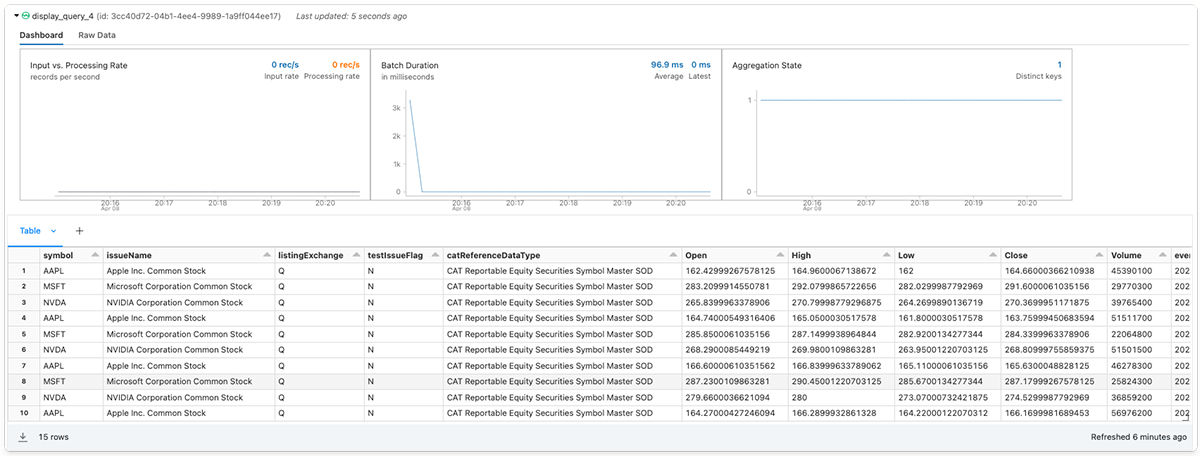
次にApple Inc.(AAPL) ,Microsoft Corporation(MSFT), Invidia Corporation(NVDA)の3つの大型ハイテク銘柄のローカル株価履歴と株式マスターデータストリームを結合させます
最後にデータ受信者はオプションのデスティネーションシンクを追加して、ストリーミングクエリーを開始することができます
DatabricksでDelta Sharingを始める
Delta Sharingを活用して、組織がほぼリアルタイムでデータのビジネス価値を最大化する方法を紹介しましたが、いかがでしたでしょうか?
Delta Sharingを始めたいが、何から始めたらいいかわからないという方。すでにDatabricksのお客様であれば、ガイドに従ってDelta Sharing (AWS | Azure | GCP)を使い始めてください。ドキュメントを読んで、この機能に含まれる設定オプションの詳細を確認してください。Databricksのお客様でない場合は、PremiumまたはEnterpriseワークスペースの無料トライアルにサインアップしてください。
Credits
We'd like to extend special thanks for all of the contributions to this release, including Abhijit Chakankar, Lin Zhou, and Shixiong Zhu.