VulnWatch:AIによる脆弱性の優先順位付け
AI駆動の脆弱性優先順位付けが、Databricksのセキュリティを向上。脅威検出の自動化で手作業を削減し、重要リスクに集中できます!

Summary
- DatabricksがAIをどのように使用して、サードパーティライブラリの脆弱性を自動的に特定し、ランク付けするか。
- AIがセキュリティチームの手動労力を削減する影響。
- 重要度とDatabricksのインフラストラクチャへの関連性に基づいて脆弱性を優先順位付けすることの主な利点。
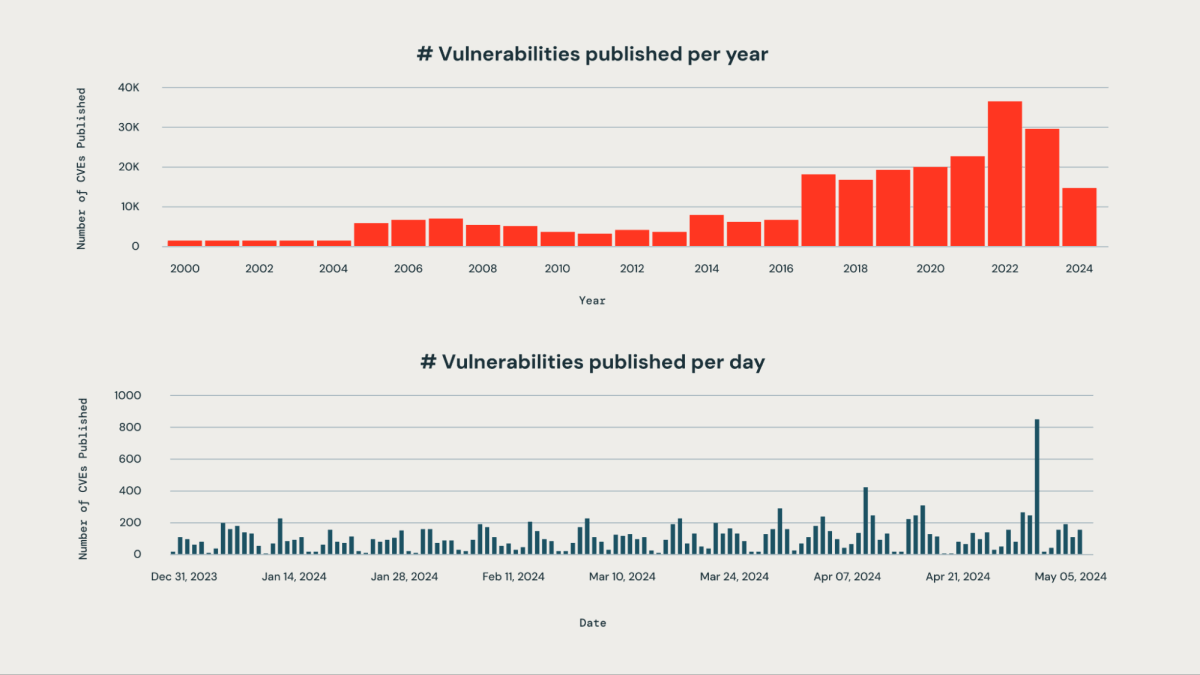
多くの組織は、自社で使用するサードパーティライブラリに影響を与える新たな脆弱性の優先順位を正しく付けることに課題を抱えています。日々発表される脆弱性の数が膨大で、手動で監視するのは現実的ではなく、リソースを大量に消費します。
Databricksでは、企業の目標の一つとして、データインテリジェンスプラットフォームのセキュリティを強化することがあります。弊社のエンジニアリングチームは、脆弱性が公開されると同時に、その深刻度、潜在的影響、およびDatabricksのインフラに対する関連性に基づいて、脆弱性を積極的に検出、分類、優先順位付けするAIベースのシステムを設計しました。このアプローチにより、重大な脆弱性が見逃されるリスクを効果的に軽減できます。弊社のシステムは、業務にとって重要な脆弱性を約85%の精度で識別できます。優先順位付けアルゴリズムを活用することで、セキュリティチームは手動作業を95%以上削減し、数百件の問題を確認するのではなく、即時対応が必要な脆弱性の5%に集中できるようになりました。
次のステップでは、AI駆動のアプローチがどのように脆弱性を識別、分類、ランク付けするかを詳しく見ていきます。
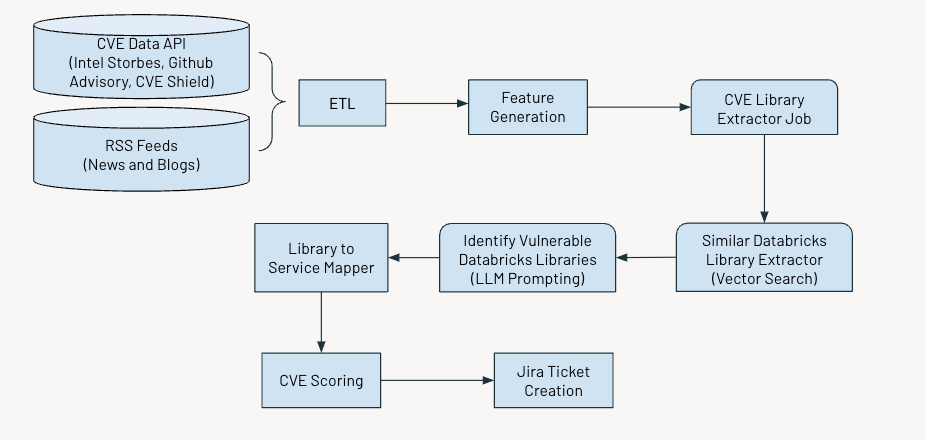
私たちのシステムがどのように継続的に脆弱性をフラグ付けするか
このシステムは定期的に運用され、重大な脆弱性を検出してフラグを立てます。プロセスは以下の主要なステップで構成されています:
- データの収集と処理
- 関連する特徴量の生成
- AIを活用して、共通脆弱性識別番号(CVE)に関する情報を抽出
- 脆弱性の深刻度に基づいて評価およびスコア付け
- さらなる対応のためにJiraチケットを生成
下の図は、全体のワークフローを示しています。
データの取り込み
私たちは、公に開示されたサイバーセキュリティの脆弱性を複数のソースから特定するCommon Vulnerabilities and Exposures (CVE)データを取り込みます。
- Intel Strobes API:これはソフトウェアパッケージとバージョンの情報と詳細を提供します。
- GitHub Advisory Database:ほとんどの場合、脆弱性がCVEとして記録されていない場合、それらはGithubのアドバイザリとして表示されます。
- CVE Shield:これは、最近のソーシャルメディアフィードからのトレンドの脆弱性データを提供します。
さらに、securityaffairsやhackernewsなどのソースからRSSフィードを収集し、サイ�バーセキュリティの脆弱性について言及している他のニュース記事やブログを収集します。
特徴生成
次に、各CVEについて以下の特徴を抽出します。
- 説明
- CVEの年齢
- CVSSスコア(Common Vulnerability Scoring System)
- EPSSスコア(Exploit Prediction Scoring System)
- 影響スコア
- エクスプロイトの可用性
- パッチの可用性
- Xのトレンド状況
- アドバイザリーの数
CVSSとEPSSのスコアは、脆弱性の深刻度と悪用可能性について貴重な洞察を提供しますが、特定の文脈での優先順位付けに完全に適用されるわけではないかもしれません。
CVSSスコアは、組織の特定のコンテキストや環境を完全には捉えておらず、高いCVSSスコアを持つ脆弱性でも、影響を受けるコンポーネントが使用されていないか、他のセキュリティ対策によって適切に軽減されている場合、それほど重要ではない可能性があります。
同様に、EPSSスコアは悪用の可能性を推定しますが、組織の特定のインフラストラクチャやセキュリティ姿勢を考慮に入れません。したがって、EPSSスコアが高いと、一般的に悪用されやすい脆弱性を示す可能性があります。しかし、影響を受けるシステムが組織のインターネット上の攻撃面に含まれていない場合、それは無関係である可能性があります。
CVSSとEPSSスコアだけに依存すると、高優先度のアラートが大量に発生し、それらを管理し、優先順位をつけることが難しくなります。
ガートナー®: Databricks、クラウドデータベースのリーダー

脆弱性のスコアリング
上記の特徴に基づいたスコアのアンサンブルを開発しました - 重要度スコア、コンポーネントスコア、トピックスコア - これによりCVEsを優先順位付けし、その詳細は以下に示します。
重大性スコア
このスコアは、CVEが広範なコミュニティにとってどれほど重要かを定量化するのに役立ちます。スコアは、CVSS、EPSS、およびImpactスコアの加重平均として計算します。CVE Shieldと他のニュースフィードからのデータ入力により、セキュリティコミュニティや同業他社が任意のCVEの影響をどのように認識しているかを把握することができます。このスコアの高い値は、コミュニティと私たちの組織にとって重要と見なされるCVEに対応します。
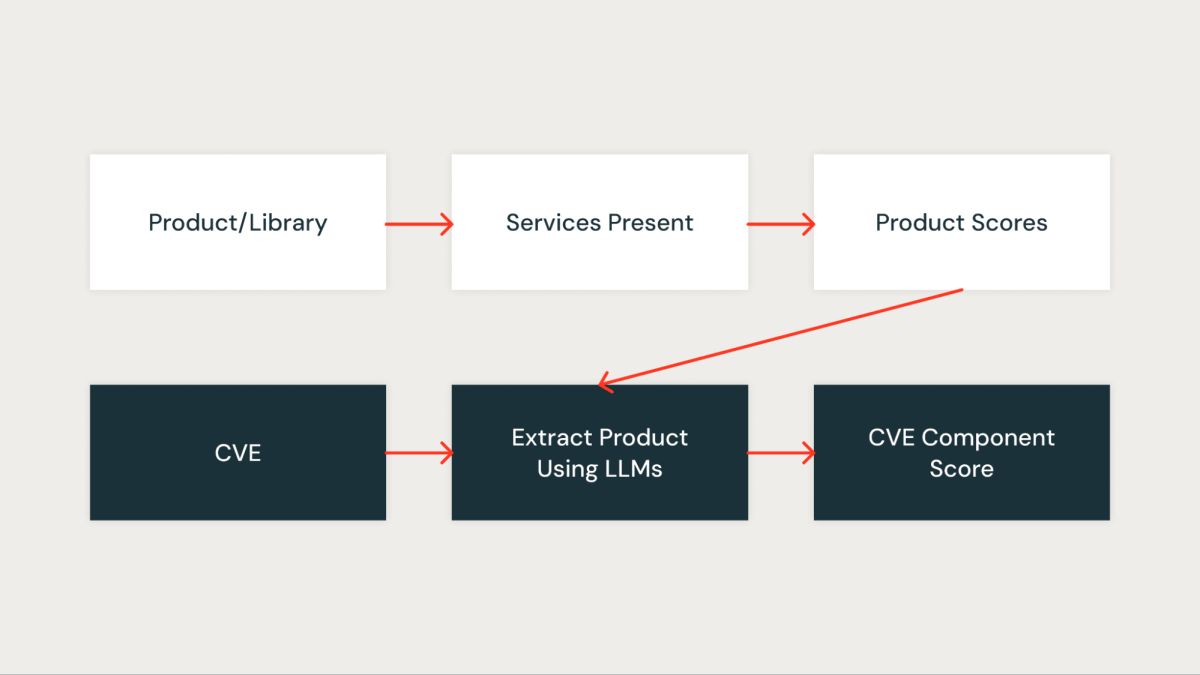
コンポーネントスコア
このスコアは、CVEが私たちの組織にとってどれほど重要かを定量的に測定します。組織内の各ライブラリは、最初にライブラリによって影響を受けるサービスに基づいてスコアが割り当てられます。重要なサービスに存在するライブラリは高いスコアを得る一方、非重要なサービスに存在するライブラリは低いスコアを得ます。
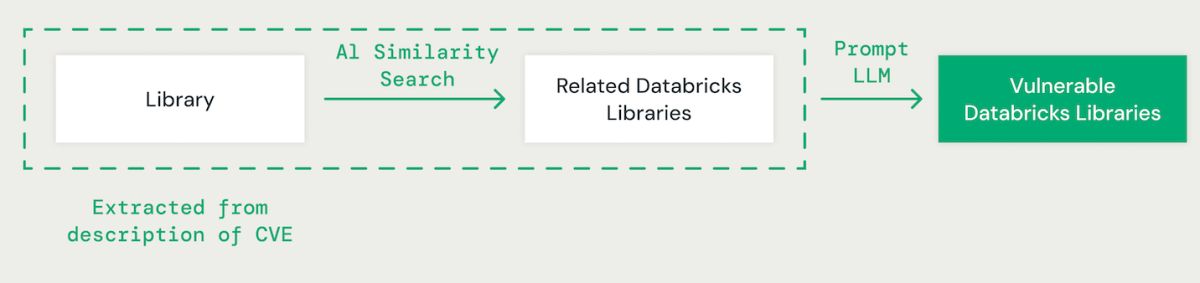
AIによるライブラリマッチング
大規模な言語モデル(LLM)を用いたフューショットプロンプトを利用して、各CVEの説明から関連するライブラリを抽出します。その後、AIベースのベクトル類似性アプローチを用いて、特定したライブラリを既存のDatabricksライブラリとマッチさせます。これには、ライブラリ名の各単語を比較のための埋め込みに変換する作業が含まれます。
CVEライブラリとDatabricksライブラリをマッチングする際には、異なるライブラリ間の依存関係を理解することが重要です。例えば、IPythonの脆弱性が直接CPythonに影響を与えないかもしれませんが、CPythonの問題はIPythonに影響を与える可能性があります。また、「scikit-learn」、「scikitlearn」、「sklearn」、「pysklearn」など、ライブラリの命名規則のバリエーションは、ライブラリの識別とマッチングにおいて考慮しなけ�ればなりません。さらに、バージョン固有の脆弱性も考慮に入れるべきです。例えば、OpenSSLのバージョン1.0.1から1.0.1fこれらは脆弱性がある可能性がありますが、1.0.1gから1.1.1などの後のバージョンのパッチは、これらのセキュリティリスクを解消する可能性があります。
LLMは、高度な推論と業界の専門知識を活用して、ライブラリのマッチングプロセスを強化します。私たちは、脆弱な依存パッケージを特定する精度を向上させるために、さまざまなモデルをグラウンドトゥルースのデータセットを使用して微調整しました。
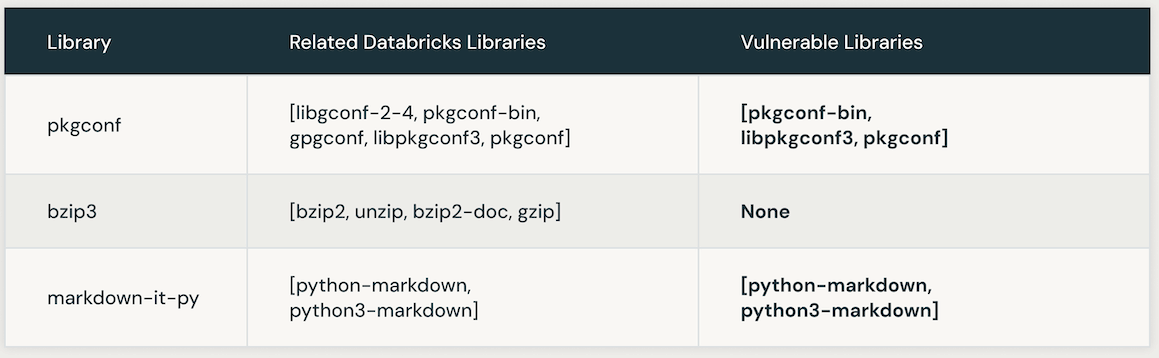
次の表は、特定のCVEにリンクされた脆弱なDatabricksライブラリのインスタンスを示しています。最初に、AIの類似性検索が利用されて、CVEライブラリと密接に関連するライブラリを特定します。その後、LLMが使用されて、Databricks内のそれらの類似ライブラリの脆弱性を確認します。
LLM指示最適化の自動化による精度と効率の向上
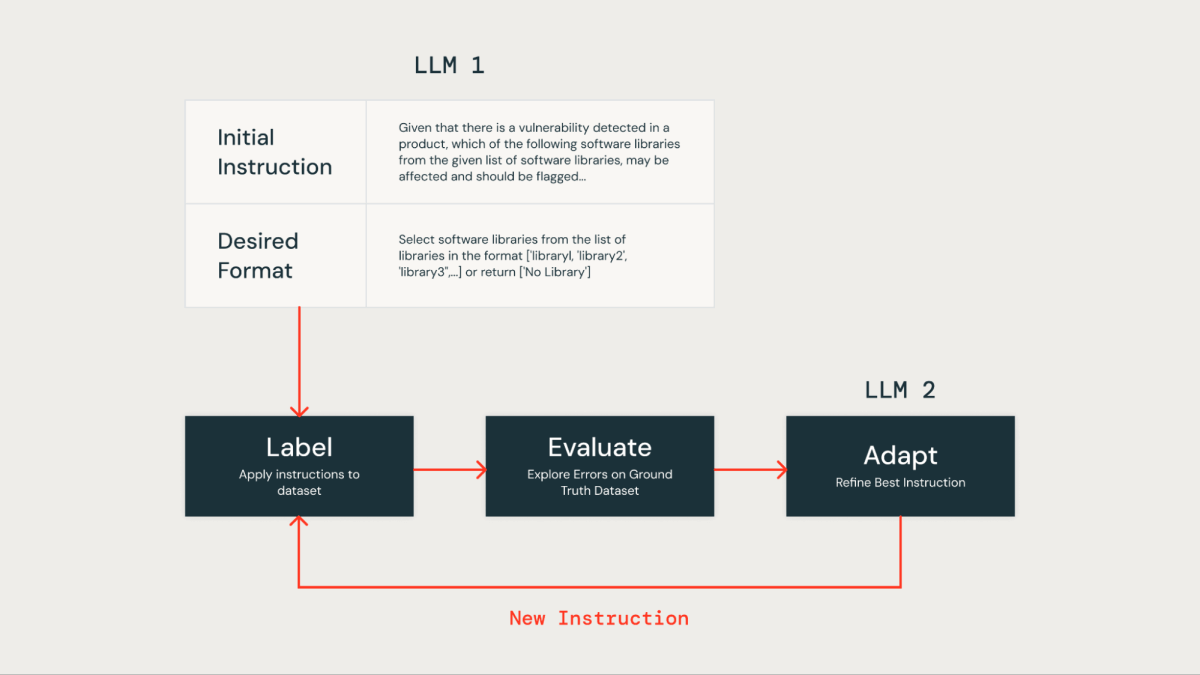
LLMプロンプトの手動最適化指示は、労力がかかり、エラーが発生しやすいです。より効率的なアプローチは、反復的な方法を使用して複数の指示セットを自動的に生成し、それらをグラウンドトゥルースデータセットでの優れたパフォーマンスに最適化することです。この方法は人間のエラーを最小限に抑え、時間の経過とともに指示の効果的かつ正確な強化を確保します。
私たちはこの自動指示最適化技術を、自身のLLMベースのソリューションを改善するために適用しました。最初に、私たちはLLMに指示と希望する出力形式を提供し、データセットのラベリングを行いました。結果は、製品セキュリティチームが提供した人間がラベル付けしたデータを含むグラウンドトゥルースデータセットと比較されました。
その後、私たちは"Instruction Tuner"と呼ばれる2つ目のLLMを利用しました。それに初期のプロンプトと、グラウンドトゥルース評価から特定されたエラーをフィードしました。このLLMは、反復的に改善されたプロンプトを生成しました。オプションのレビューの後、最もパフォーマンスの良いプロンプトを選択して精度を最適化しました。
LLM指示最適化技術を適用した後、以下のような洗練されたプロンプトを開発しました:
適切なLLMの選択
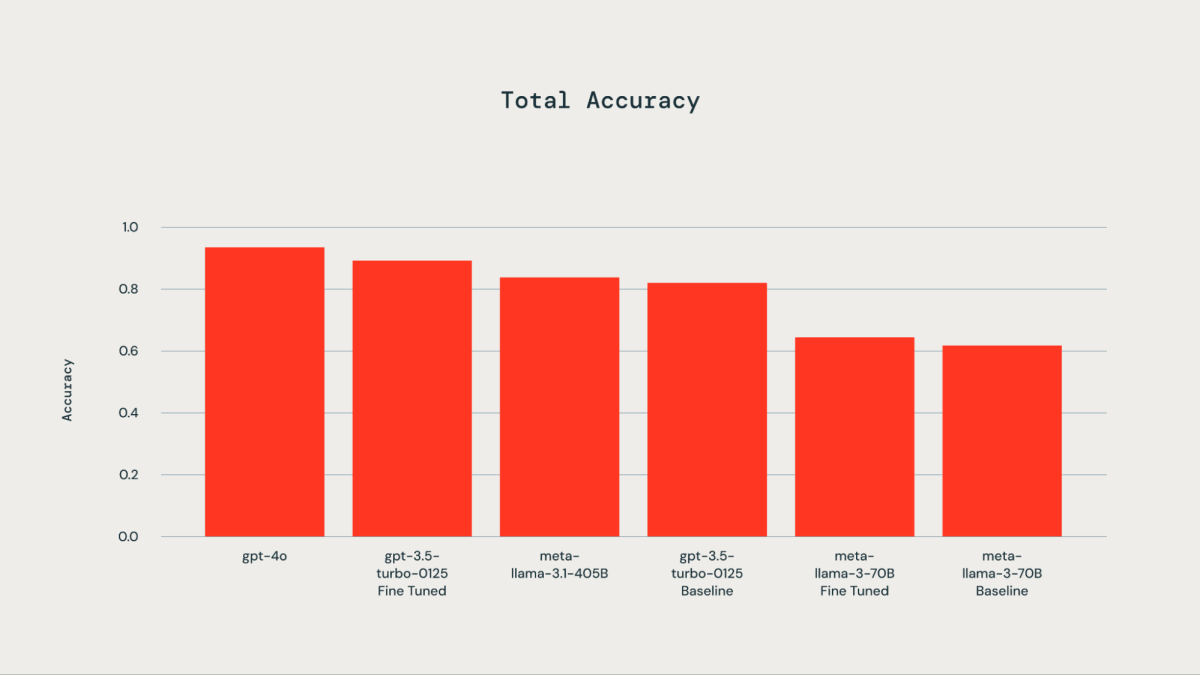
300件の手動ラベル付けされた例からなるグラウンドトゥルースデータセットを使用してファインチューニングを行いました。テストしたLLMには、gpt-4o、gpt-3.5-Turbo、llama3-70B、llama-3.1-405b-instructが含まれています。付随するグラフに示されているように、グラウンドトゥルースデータセットでのファインチューニングにより、gpt-3.5-turbo-0125はベースモデルに比べて精度が向上しました。DatabricksのファインチューニングAPIを使用してllama3-70Bをファインチューニングした結果、ベースモデルに対してわずかな改善が見られました。ファインチューニングしたgpt-3.5-turbo-0125の精度は、gpt-4oと同等か、それに若干劣るものでした。同様に、llama-3.1-405b-instructの精度も、ファインチューニングされたgpt-3.5-turbo-0125モデルと同等か、それより若干低い結果となりました。
一度DatabricksのライブラリがCVEで特定されると、そのライブラリの対応スコア(上記で説明したlibrary_score)がCVEのコンポーネントスコアとして割り当てられます。
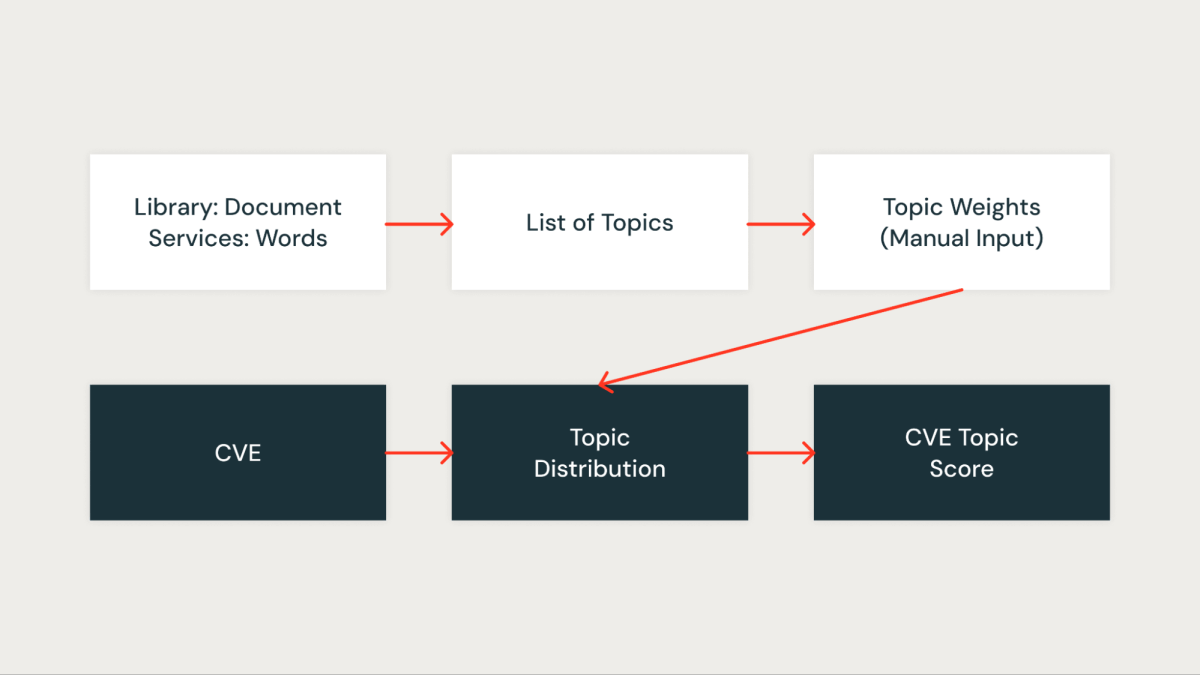
トピックスコア
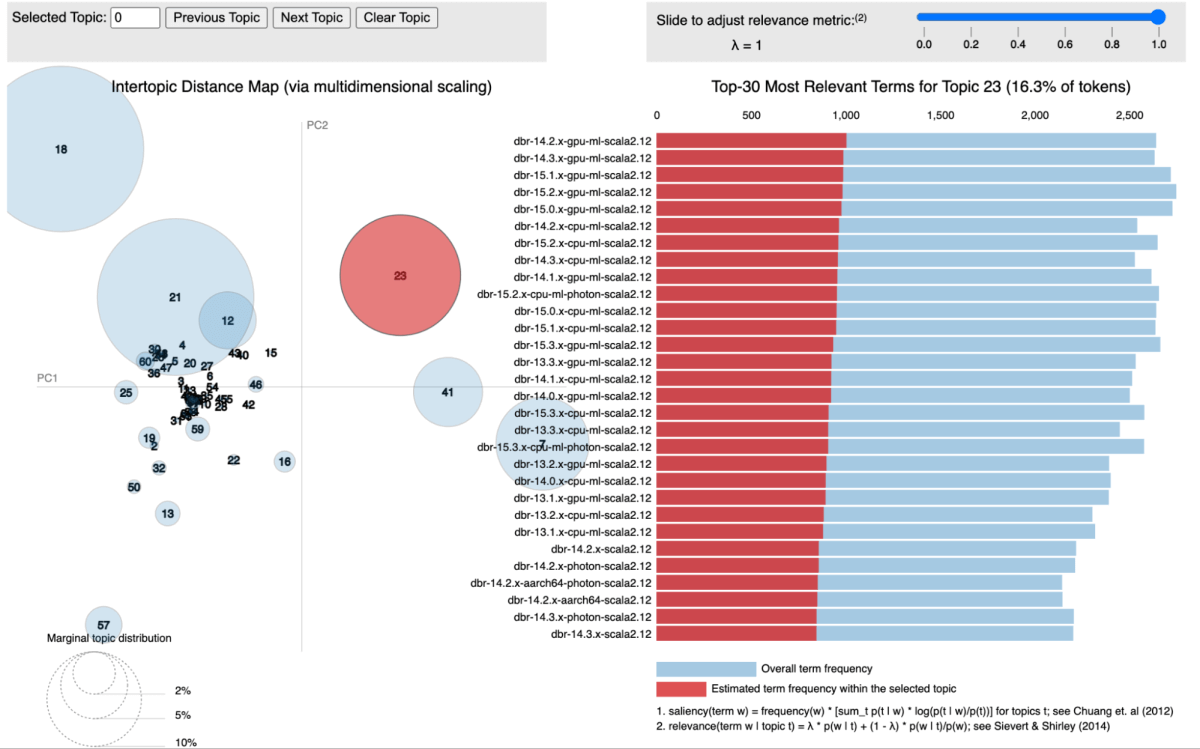
私たちのアプローチでは、特にLatent Dirichlet Allocation(LDA)というトピックモデリングを利用して、ライブラリをそれらが関連するサービスによってクラスタリングしました。各ライブラリはドキュメントとして扱われ、その中に現れるサービスはそのドキュメント内の単語として扱われます。この方法により、私たちは効果的にライブラリを共有サービスコンテキストを表すトピックにグループ化することができます。
下の図は、すべてのDatabricks Runtime(DBR)サービスが一緒にクラスタリングされ、pyLDAvisを使用して視覚化されている特定のトピックを示しています。
各特定されたトピックに対して、私たちのインフラ内でのその重要性を反映するスコアを割り当てます。このスコアリングにより、各CVEを関連するライブラリのトピックスコアと関連付けることで、脆弱性をより正確に優先順位付けすることができます。例えば、あるライブラリが複数の重要なサービスに存在するとします。その場合、そのライブラリのトピックスコアは高くなり、その結果、それに影響を与えるCVEはより高い優先度を得ることになります。
インパクトと結果
私たちは、上記のスコアを統合するためにさまざまな集計手法を活用しました。モデルは3か月分のCVEデータを使用してテストされ、その結果、ビジネスに関連するCVEを識別する際に約85%の優れた真陽性率を達成しました。このモデル�は、公開されたその日に(0日目)、重要な脆弱性を特定し、また、セキュリティ調査が必要な脆弱性を浮き彫りにしました。
モデルによる偽陰性を評価するため、外部ソースまたはセキュリティチームによって手動で特定されたがモデルが検出できなかった脆弱性を比較しました。これにより、見逃された重要な脆弱性の割合を計算することができました。注目すべきは、バックテストデータにおいて偽陰性は一切発生しなかったことです。しかし、この分野での継続的な監視と評価の必要性を認識しています。
私たちのシステムは、脆弱性管理のワークフローを効率化し、セキュリティトリアージのステップをより効率的かつ焦点を絞ったものに変革しました。このシステムにより、顧客に直接影響を与えるCVEを見逃すリスクが大幅に軽減され、手作業の負担が95%以上削減されました。この効率化により、セキュリティチームは毎日公開される数百件の脆弱性をチェックするのではなく、限られた重要な脆弱性に集中できるようになりました。
謝辞
この作業は、データサイエンスチームと製品セキュリティチームの間の共同作業です。製品セキュリティチームのMrityunjay Gautam、Aaron Kobayashi、Anurag Srivastava、Ricardo Ungureanu、そしてセキ��ュリティデータサイエンスチームのAnirudh Kondaveeti、Benjamin Ebanks、Jeremy Stober、Chenda Zhangに感謝します。