Apache Kylin
Apache Kylin とは
Apache Kylin とは、ビッグデータの対話型分析のための分散型オープンソースのオンライン分析処理(OLAP)エンジンです。Apache Kylin は Hadoop や Spark でSQL インターフェイスと多次元分析(OLAP)を提供するよう設計されています。さらに、ODBC ドライバ、JDBC ドライバ、REST API を介して BI ツールと容易に統合します。2014年に eBay が構築した Apache Kylin は、わずか 1 年後の 2015年に Apache ソフトウェア財団(ASF)のトップレベルプロジェクトに進出し、「Best open Source Big Data Tool (最も優れたオープンソースのビッグデータツール)」を 2015 年から 2 年連続で受賞しています。現在、世界中の多くの企業でビッグデータ分析用途に利用されています。他のOLAPエンジンでは処理が難しい大規模データに対しても、Kylinはミリ秒単位の応答を実現し、ペタバイト規模までスケールします。Kylin は、Hive クエリ経由でさまざまな次元の組み合わせと集計測定値を事前計算し、HBase に結果を入力することで、高速化を実現しています。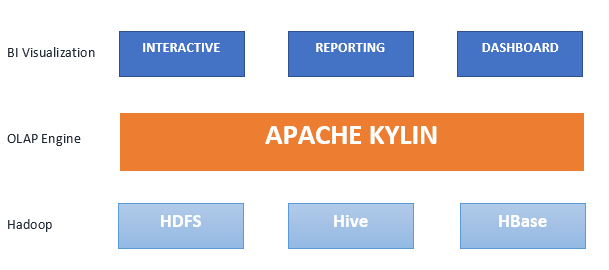
Apache Kylin の仕組み
Kylin の分かりやすい UI でアクセス可能な Kylin のクエリエンジンは、API または JDBC を介し、Apache Calcite のクエリプロセッサと HBase の機能を活用して迅速な検索を行います。Kylin が依存する Hadoop エコシステムは次のとおりです。
- Hive — 入力ソース、キューブ構築中のスタースキーマの事前統合
- MapReduce —キューブ構築時のメトリックの集約
- HDFS —キューブ構築中の中間ファイル�の保存
- HBase— データキューブの格納とクエリ
- Calcite— 組織の支援に有効な、SQL 解析、コード生成、最適化
- 大規模で高速な OLAP エンジン— Kylin は 100 億行以上のデータに対しても、Hadoop 上で数秒以内のクエリ応答
- Hadoop における ANSI SQL インターフェース— Hadoop で ANSI SQL を提供し、ANSI SQL クエリ関数の大部分をサポート。プログラミングが不要なため、アナリストとエンジニアが簡単に使用可能
- BI ツールとのシームレスな統合—Tableau、JDBC/ODBC/Rest API のような BI ツールとの統合機能を提供
- 対話型クエリ機能-Kylin を経由することで、ユーザーは 1 秒以内のレイテンシで Hadoop データの操作が可能
- 数十億行に対応する MOLAP キューブクエリ— 100 億を超える生データレコードに対応し、ユーザーによる Kylin でのデータモデルの定義、事前構築が可能
・オープンソースの ODBC ドライバ— Kylin の ODBC ドライバはゼロから構築されているため、Tableau とうまく動作します。
FAQ
1. Apache Kylinが高速な理由は何ですか?
クエリ時に計算するのではなく、あらかじめ集計結果をキューブとして事前計算・保存するためです。
2. Kylinはどのようなデータ規模に対応できますか?
数十億〜ペタバイト規模のデータに対して、秒未満のレイテンシで分析クエリを実行できます。
3. Kylinはどのようなツールと連携できますか?
JDBC/ODBCやREST APIを介して、TableauなどのBIツールとシームレスに連携できます。